

Debris flow susceptibility evaluation is an important part of debris flow prevention and control work. Reliable evaluation results can provide important basis for formulating scientific disaster prevention and reduction plans in related areas. Thanks to the development of remote sensing technology, geographic information systems, global positioning systems, and computer technology, debris flow susceptibility evaluation technology has become increasingly mature and refined. Machine learning methods have powerful nonlinear processing capabilities and robustness, and have been widely applied in recent years. Most existing related studies are based on modeling and analysis of a single research area, and there are still some problems that need to be solved in practical applications. For example, when the sample size of debris flow in a single research area is small, the presence of a few defective data can severely affect the model’s performance and the representativeness of the samples. In addition, when researchers face multiple research areas, models established based on a single research area often lack generalization ability to the remaining research areas. The purpose of debris flow susceptibility evaluation is to provide a unified decision basis for land planning and disaster prevention and reduction work in all research areas. Conducting independent susceptibility evaluations for multiple research areas can also lead to inconsistent evaluation standards, thereby affecting the rationality of the final decision.
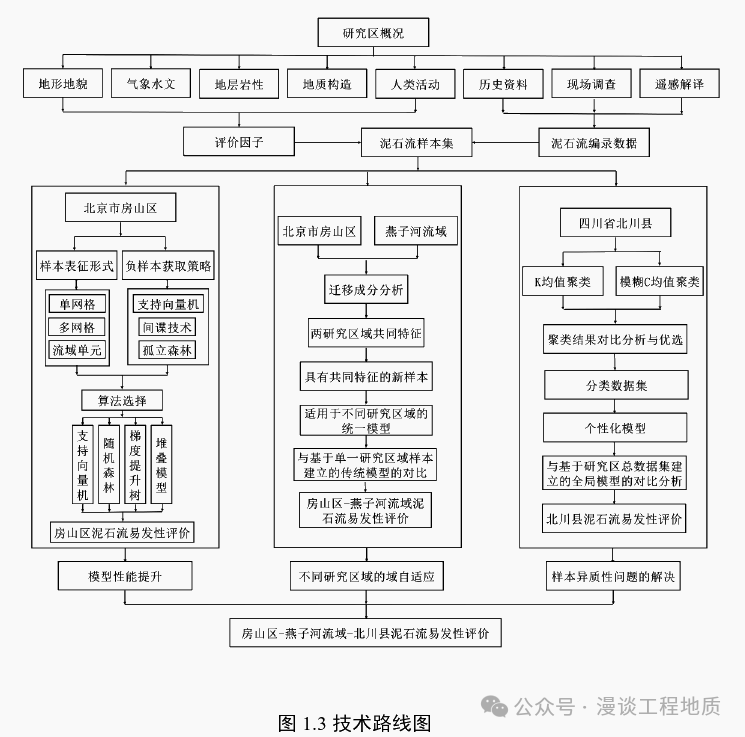
This paper first aims to improve model performance, selecting Fangshan District of Beijing as the case study area to optimize the negative sample acquisition strategy and machine learning algorithms in the debris flow susceptibility evaluation process. Then, it introduces domain adaptation theory, using transfer component analysis to extract common features of the Yanhe River Basin in Fangshan District and Longnan area for joint evaluation, providing a theoretical approach for the application of machine learning in multi-region debris flow susceptibility evaluation. To reduce the impact of sample heterogeneity on the model, this paper takes Beichuan County in Sichuan Province as the case study area to explore the application of unsupervised clustering methods in solving sample heterogeneity issues. The improvement of model performance, domain adaptation across different research areas, and the resolution of sample heterogeneity issues enable the machine learning model to be promoted to multiple research areas. Finally, this paper combines the above research results to complete the multi-region debris flow susceptibility evaluation. The main work and results of the paper are as follows:
1. A systematic review of the development history of debris flow susceptibility evaluation, domain adaptation methods for different research areas, and solutions to sample heterogeneity has been conducted, detailing the data collection and processing methods and the establishment and evaluation methods of models in the debris flow susceptibility evaluation process.
2. Multiple negative sample acquisition strategies for debris flows have been proposed to enhance the reliability of negative samples. Taking Fangshan District as the case study area, under conditions of single grid, multi-grid, and watershed unit as the basic sample representation forms, negative samples of debris flows were obtained based on the Support Vector Machine (SVM) algorithm, SPY technology, and Isolation Forest (IF) algorithm, respectively, forming 9 groups of modeling datasets when combined with corresponding positive samples. Evaluation factor analysis and modeling predictions were conducted based on each dataset to compare the advantages and disadvantages of different negative sample acquisition strategies. The results show that the negative sample acquisition strategy based on the SVM algorithm is relatively dependent on classifier performance, with overall performance being less stable. The negative sample acquisition strategy based on SPY technology has lower requirements for the dataset and does not have significant dependence on the algorithm, improving the quality of multiple datasets. The negative sample acquisition strategy based on the IF algorithm fits well with the assumption conditions and watershed unit dataset, which can be used to improve the quality of the corresponding dataset.
3. Combining the 9 groups of datasets formed by different sample representation forms and negative sample acquisition strategies, 36 groups of machine learning models were trained and evaluated based on SVM, Random Forest (RF), Gradient Boosting Decision Tree (GBDT), and Stacking algorithms. The results indicate that the Stacking model has high prediction accuracy, but its model complexity is significantly greater than that of the other models, and the training prediction efficiency is lower. The RF model performs relatively balanced in terms of prediction accuracy, model complexity, and training prediction efficiency, making it a high-quality algorithm that is easy to promote.
4. By introducing domain adaptation theory and employing transfer component analysis, common features from different research areas were extracted to achieve joint evaluation. The paper takes Fangshan District and the Yanhe River Basin as case study areas, projecting the feature matrices of the two research areas into a common feature space based on transfer component analysis. The RF algorithm was selected for modeling, establishing a unified model based on samples from both research areas and comparing it with traditional models established based on samples from a single research area. The results show that although the prediction accuracy of the unified model is not as high as that of the traditional model, establishing the unified model can effectively alleviate the sample shortage problem of a single research area and improve modeling efficiency. On the other hand, the sensitivity, specificity, accuracy, and AUC of the unified model reached 82.2%, 79.6%, 80.6%, and 0.84, respectively, indicating that the model’s performance is still satisfactory.
5. A solution to the sample heterogeneity of debris flow was proposed based on unsupervised clustering methods. Using Beichuan County as the case study area, the fuzzy C-means clustering algorithm was optimized to classify the samples in the study area into 4 categories. Evaluation factor analysis was conducted on each category of datasets, and personalized models were established, which were compared with the evaluation factors and global models obtained based on the total dataset. The results indicate that the predictive capabilities of the same evaluation factors vary significantly across different categories of datasets, demonstrating strong heterogeneity among debris flow samples in this area. On the other hand, most evaluation factors exhibited stronger predictive capabilities in each category of datasets than in the total dataset, and the overall performance of the personalized models also surpassed that of the global model. Therefore, the fuzzy C-means clustering algorithm shows good application prospects in addressing sample heterogeneity issues.
6. Multi-region debris flow susceptibility evaluation was conducted. Using watershed units as sample representation forms, common features from three research areas were extracted based on transfer component analysis. The three research areas were treated as a whole, and all samples were uniformly classified using the fuzzy C-means clustering algorithm to reduce the impact of sample heterogeneity on the model. Common feature analysis and personalized models were established based on samples from each type, with negative samples obtained based on the IF algorithm, and the RF algorithm was chosen for modeling due to its balanced performance. Finally, a comparative analysis was conducted with traditional global models established based on single research areas. The results show that the comprehensive performance of the multi-region personalized models outperforms that of the traditional global models established based on single research areas. This further validates the rationality and effectiveness of the multi-region debris flow evaluation method proposed in this paper and promotes the application of machine learning in the field of debris flow susceptibility evaluation.
Innovations of the Paper