With the development of society, the pace of life is constantly accelerating. How to help users quickly find valuable information in the vast sea of archives is an urgent problem that archive managers need to solve. A Knowledge Graph is a semantic network knowledge base, represented as a graphical network containing various structured knowledge that has been intelligently processed. Converting archive data into a knowledge graph for storage and display can reduce the workload of archive managers and improve users’ efficiency in searching archives. However, due to the multi-domain and various forms of archive data, it is difficult to construct an archive knowledge graph using a unified method. This paper proposes a method for constructing an archive knowledge graph based on global deep learning, which integrates and converts massive archive data, including video, audio, images, and text, into a structured knowledge graph, effectively solving the multi-source heterogeneous problem in the process of knowledge graph construction.
The Introduction of Deep Learning in Archive Knowledge Graph Construction
The construction of a knowledge graph generally includes named entity recognition, relation extraction, entity alignment, and knowledge reasoning. Traditional named entity recognition often uses dictionary-based and domain knowledge methods; however, due to the incompleteness of dictionaries and domain knowledge, these methods have a low recall rate. Although the BiLSTM (Bidirectional Long Short-Term Memory) + CRF (Conditional Random Field) neural network model performs excellently in named entity recognition tasks, the BiLSTM + CRF model requires a large amount of labeled data for self-supervised training. In relation extraction, a segment of archive text usually contains not only the relationships between entities but also many unrelated words, leading to noise issues in the relation extraction task. Entity alignment is used to solve the entity conflict problem in knowledge fusion from multi-source heterogeneous data, which requires extracting entity features, but single entity features have limitations in large-scale entity alignment tasks. Although there are many methods for knowledge reasoning, each method has its own advantages and disadvantages.
Deep learning learns sample features through deep neural networks, enabling automatic analysis and recognition of text, images, and audio, including various technologies such as Bert (Bidirectional Encoder Representation from Transformers), BiLSTM, and reinforcement learning. In recent years, deep learning has performed excellently in fields such as natural language processing, image processing, speech recognition, and video recognition. In October 2018, the Bert language model proposed by Google AI Research achieved state-of-the-art performance in 11 NLP (Natural Language Processing) tests, marking a milestone breakthrough in the development of NLP and greatly enhancing the practical application capabilities of deep learning models. BiLSTM can capture long-distance semantic dependencies, allowing the model to better understand the context of the text. Reinforcement learning transforms problems into decision-making problems, considering both short-term benefits and long-term returns to achieve better model performance. Applying deep learning technologies such as Bert, BiLSTM, and reinforcement learning to the global construction of archive data knowledge graphs can fully utilize various types of archive data, improve data analysis efficiency and quality, and significantly reduce the labor costs of archive data analysis.
The method of constructing archive knowledge graphs based on deep learning can simultaneously analyze various types of data such as documents, videos, and images, and extract the information obtained from the analysis as knowledge for unified fusion. In this technology, data preprocessing is first performed to convert video information, image information, and text information into structured data such as full text, summaries, topics, keywords, time, source, and type. Named entity recognition is performed on the full text data to identify entities such as personal names, place names, organization names, and proper nouns present in the text, and then establish relationships between entities based on the extracted entities and the full text. Entities with the same meaning often have different names in sample data; therefore, features of the entities are extracted based on the full text, summaries, and attributes such as topics, keywords, sources, and types to calculate the similarity of entities for merging and unifying them. Finally, reasoning, expansion, and completion of existing entities and their relationships are performed to complete the construction of the knowledge graph. The specific process is shown in the figure.
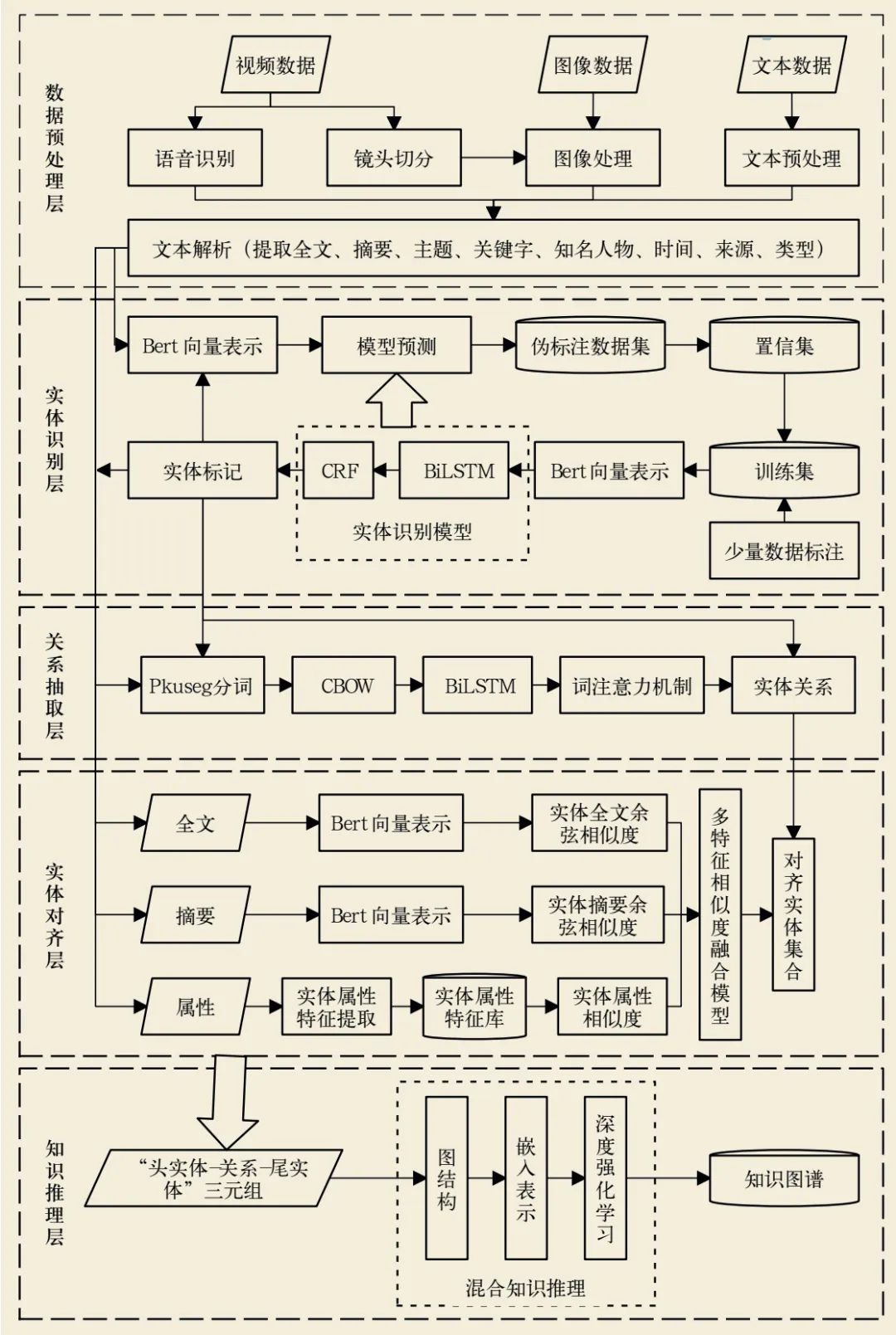
Figure 1: Workflow of Archive Knowledge Graph Construction
The Application of Deep Learning in Archive Knowledge Graph Construction
1. Data Preprocessing Layer
Archive data includes various types of data such as video, images, and text. For video data, speech recognition is performed on the audio to convert speech into text data. At the same time, video is segmented into image data using a hash-aware algorithm. For image data, OCR (Optical Character Recognition) and facial recognition of well-known individuals are performed. If both speech recognition and OCR produce text data from the video data, a language model is used to compare and merge the two text data. Text data undergoes preprocessing to remove special symbols and other noise information. At this point, full text data as well as information about well-known individuals, time, source, and type are obtained from various types of data including video, images, and text. Text parsing is then performed using TextRank (Text Ranking Algorithm) and LDA (Latent Dirichlet Allocation) to extract summaries, topics, and keywords from the full text data.
2. Entity Recognition Layer
In the entity recognition layer, entities present in the full text data are extracted. Entity recognition is a fundamental task for knowledge graphs, and good entity recognition results can greatly enhance the quality of the knowledge graph. To address the issue of requiring a large amount of manual labeling for deep learning-based entity recognition models, this paper proposes a self-supervised deep learning model training method. First, a small amount of manually labeled data is constructed as the training set, and the training set is used to output semantic sentence vector representations through Bert, which is then used to train the BiLSTM + CRF entity recognition model.
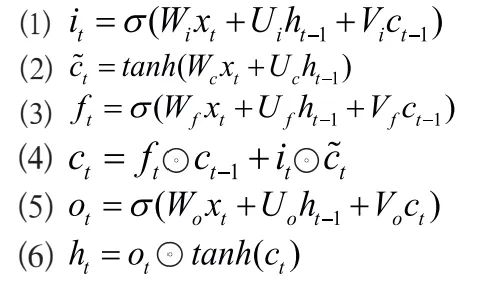
Formulas (1-6) show the calculation method of the cell unit in BiLSTM. The cell unit in BiLSTM introduces a “gate” mechanism, allowing the neural network to remember important information and forget less important information, thereby enhancing the overall semantic understanding of longer texts. CRF adds constraints and limitations to the model’s output labels to avoid unreasonable entity labels. After fitting the entity recognition model, the unlabeled full text data is transformed into sentence vectors using Bert, and the existing model is used to predict labels. The predicted data undergoes confidence judgment, and a confidence threshold is set. Samples with confidence above the threshold are added to the existing training set, and the entity recognition model is retrained using the new training set. This cycle continues until the model performance no longer improves, completing the training of the entity recognition model, and then the full text data is input into the trained entity recognition model to output entity labels.
3. Relation Extraction Layer
Based on the already recognized entities and full text data, relationships between entities are extracted. All entities are added to the user dictionary of Pkuseg (Peking University Segmentation Tool) to ensure the accuracy of entity segmentation. The full text data is segmented using Pkuseg and input into COBW (Continuous Bag of Words) to convert it into word vectors. Then, BiLSTM is used to obtain the semantic encoding of the entire full text data. Due to the presence of a large amount of noise information in the full text data, in the relation extraction model, an attention mechanism is introduced. The attention mechanism can automatically adjust the weights based on sample data, allowing the model to focus more on the relationships between entities and less on noise information.
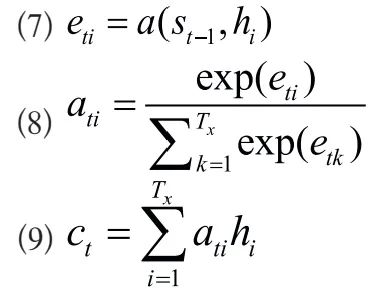
Formulas (7-9) show the calculation method of the attention mechanism. To align the model, it represents the degree of influence of the state at the BiLSTM layer at a given time on the output layer at the subsequent time, calculated based on the state of the output layer at that time. In formula (8), softmax normalization is performed to obtain attention weights. The semantic vector at the output layer at a given time is obtained by multiplying and summing multiple hidden states with their corresponding attention weights. The attention mechanism not only improves the accuracy of relation extraction but also reduces the computational complexity of the model, enhancing the model’s operational efficiency. Finally, the results of entity recognition are used to correct the predictions of entity relation extraction.
4. Entity Alignment Layer
To improve the accuracy of entity alignment, a multi-feature similarity-based archive entity alignment method is proposed. The full text data, summaries, topics, keywords, well-known individuals, time, sources, and types generated in the data preprocessing layer are fully utilized. The full text data contains the majority of information from the entire archive sample data, the summary data contains key information from the archive data, and the attribute data provides supplementary explanations for the archive data. The full text data and summary data are converted into vector representations using Bert. The cosine similarity of entity full text and entity summary is calculated between archive sample data, and these two similarities are combined to assess the semantic similarity between archive sample data. Since attribute data contains various data types, the similarity calculations also differ. Topics and keywords belong to text information, using CBOW to generate corresponding vector representations. Well-known individuals, sources, and types are converted into One-Hot encoding. Time is converted into numerical data using timestamps. The vectors of all attribute data are concatenated to calculate the cosine similarity of the attribute data. Formula (10) shows the calculation method of cosine similarity, where a and b represent the vectors for which similarity needs to be calculated.
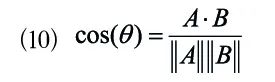
Multiple similarity indicators are input into a multi-feature fusion model constructed by SE block to output the results of entity alignment. After all archive data is predicted by the entity alignment model, an aligned entity set is generated. Finally, the entities and their relationships output by the relation extraction layer are aligned using the aligned entity set.
5. Knowledge Reasoning Layer
After processing through the previous four layers of models, a prototype of the knowledge graph has been constructed, generating “head entity – relation – tail entity” triples. However, there is a problem of sparse relationships between entities. Knowledge reasoning can enrich the relationships between entities, fulfilling the purpose of supplementing the knowledge graph. Knowledge reasoning based on graph structures has high interpretability but high computational complexity, making it difficult to apply in large knowledge graphs. Knowledge reasoning based on embedding representations has high computational performance but weak interpretability. Knowledge reasoning based on deep reinforcement learning performs excellently but also lacks interpretability. A hybrid knowledge reasoning method is proposed that combines graph structures, embedding representations, and deep reinforcement learning. On one hand, graph structure methods give the model strong interpretability; on the other hand, embedding representations and deep reinforcement learning provide high computational efficiency and reasoning performance. First, a path is constructed using graph structures; second, embedding representations are used to vectorize the path; third, the knowledge reasoning task is transformed into a decision-making problem, with entities and relations constructed as state space and action space, respectively. By performing entity walks, the model discovers correct entities and relations and provides rewards for the model, training and optimizing it. The vectors are input into the trained deep reinforcement learning model for knowledge reasoning, completing the relationships in the knowledge graph. Finally, the constructed knowledge graph is output.
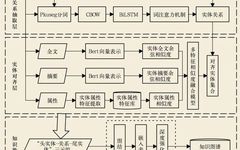
For example, the knowledge graph of various types of archive data for a person “***” from 2019 to 2022 is established as follows: the archive data is input into the trained deep learning-based knowledge graph construction model, and the automatically generated knowledge graph is shown in Figure 2. The data in the figure has been desensitized using “*” and English letters. The figure also shows the main events that this person experienced from 2019 to 2022, including the time, place, individuals involved in the events, the relationships between the individuals and this person, and the organization to which this person belongs and their position.
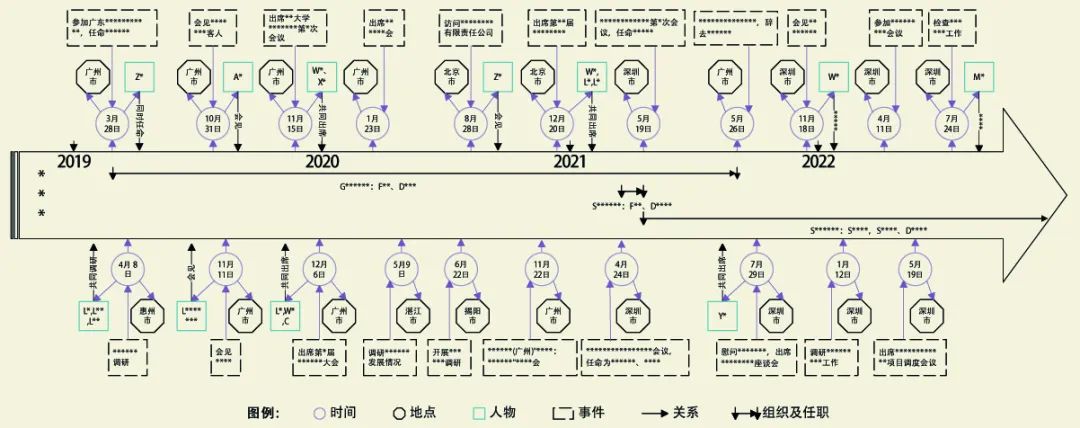
Figure 2: Example of Knowledge Graph
Conclusion
Using deep learning technology to automatically construct knowledge graphs can convert global archive data into structured data, solving the storage difficulties of video, audio, and image data. It can also extract entities from global archive data and establish connections, breaking down information barriers between different types of archive data and achieving knowledge fusion of global archive data. Furthermore, this entire process requires only a small amount of manual input to complete the construction of the knowledge graph, greatly saving labor costs compared to traditional archive data analysis methods. Archive personnel can further mine deeper knowledge from the data based on the knowledge graph constructed using deep learning technology, thereby making better use of the value of archive data resources.
Author Affiliation: Nanjing Fenghuo Xingkong Communication Development Co., Ltd., Shenzhen Archives
Source: “China Archives” Magazine, Issue 11, 2022

Scan to follow us