

Source: Smart Things
This article is approximately 6000 words, and it is recommended to read for 10+ minutes.
This article comprehensively analyzes the principles of face recognition technology, the situation of talent in the field, application areas, and development trends.

Since the second half of the 20th century, computer vision technology has gradually developed and grown. Meanwhile, with the widespread use of digital image-related software and hardware technologies in people’s lives, digital images have become an important component of information sources in contemporary society, and the demand and applications for various image processing and analysis continue to promote innovations in this technology. The applications of computer vision technology are very extensive. There are applications in fields such as digital image retrieval management, medical image analysis, intelligent security checks, and human-computer interaction. This technology is an important component of artificial intelligence technology and is also at the forefront of current computer science research. After continuous development in recent years, a comprehensive technology has gradually formed, combining digital signal processing technology, computer graphics and images, information theory, and semantics, and has strong edge and interdisciplinary characteristics. Among them, face detection and recognition is currently a popular research topic within image processing, pattern recognition, and computer vision, and is also a branch of biometric recognition that attracts the most attention.
Face recognition is a biometric recognition technology based on the facial feature information of individuals for identity recognition. It typically uses cameras or video streams to collect images or video containing faces, automatically detecting and tracking faces within the images. According to data, in 2017, the global market size of biometric technology rose to 17.2 billion USD, and by 2020, the global biometric market size is expected to reach 24 billion USD. From 2015 to 2020, the market size of face recognition grew by 166.6%, ranking first among various biometric technologies, and it is expected that by 2020, the market size of face recognition technology will rise to 2.4 billion USD.
To obtain this report, please reply with“1103”.
1. Overview of Face Recognition Technology
1. Basic Concepts
The unique charm of the human visual system drives researchers to attempt to simulate human capabilities in capturing, processing, analyzing, and learning images of the three-dimensional world through visual sensors and computer software and hardware, so that computer and robotic systems can possess intelligent visual functions. Over the past 30 years, scientists from various fields have continuously tried to understand the mysteries of biological vision and the nervous system from multiple perspectives, in order to benefit humanity with their research results. Since the second half of the 20th century, computer vision technology has gradually developed in this context. Meanwhile, with the widespread use of digital image-related software and hardware technologies in people’s lives, digital images have become an important component of information sources in contemporary society, and the demand and applications for various image processing and analysis continue to promote innovations in this technology.
Computer vision technology has very broad applications. Digital image retrieval management, medical image analysis, intelligent security checks, and human-computer interaction are all fields that involve computer vision technology. This technology is an important component of artificial intelligence technology and is also at the forefront of current computer science research. After continuous development in recent years, a comprehensive technology has gradually formed, combining digital signal processing technology, computer graphics and images, information theory, and semantics, and has strong edge and interdisciplinary characteristics. Among them, face detection and recognition is currently a popular research topic within image processing, pattern recognition, and computer vision, and is also a branch of biometric recognition that attracts the most attention.
Face recognition is a biometric recognition technology based on the facial feature information of individuals for identity recognition. It typically uses cameras or video streams to collect images or video containing faces, automatically detecting and tracking faces within the images. According to a report published by the China Report Network titled “2018 China Biometric Market Analysis Report – In-depth Industry Analysis and Development Prospects Prediction”, in 2017, the global market size of biometric technology rose to 17.2 billion USD, and by 2020, the global biometric market size is expected to reach 24 billion USD. From 2015 to 2020, the market size of face recognition grew by 166.6%, ranking first among various biometric technologies, and it is expected that by 2020, the market size of face recognition technology will rise to 2.4 billion USD.
Among various biometric recognition methods, face recognition has its unique advantages, thus holding an important position in biometric recognition. The five advantages of face recognition are:
-
Non-invasiveness. Face recognition can achieve good recognition effects without interfering with people’s normal behavior, and there is no need to worry about whether the person being recognized is willing to place their hand on a fingerprint collection device or whether their eyes can align with an iris scanning device, etc. As long as the user naturally stays in front of the camera for a moment, their identity will be correctly recognized.
-
Convenience. The collection device is simple and quick to use. Generally speaking, a common camera can be used to collect face images without the need for particularly complex dedicated equipment. Image collection can be completed within seconds.
-
Friendliness. The method of identity recognition through face recognition is consistent with human habits, and both humans and machines can use facial images for recognition. However, methods like fingerprints and irises do not have this characteristic; a person without special training cannot use fingerprint and iris images to identify others.
-
Non-contact. The collection of facial image information differs from the collection of fingerprint information, as fingerprint collection requires the finger to contact the collection device, which is not hygienic and can easily cause discomfort to the user, whereas facial image collection does not require direct contact with the device.
-
Scalability. After face recognition, the subsequent data processing and application determine the actual applications of face recognition devices, such as applications in access control, facial image search, clocking in and out, terrorist identification, and other fields, demonstrating strong scalability.
It is precisely because face recognition possesses these good characteristics that it has a very broad application prospect, which has also attracted increasing attention from both academia and the business world. Face recognition has been widely applied in scenarios such as identity recognition, liveness detection, lip reading, creative cameras, facial beautification, and social platforms.
2. Development History
As early as the 1950s, cognitive scientists began researching face recognition. In the 1960s, the engineering application research of face recognition officially started. The methods at that time mainly utilized the geometric structure of the face, identifying faces by analyzing the feature points of facial organs and their topological relationships. This method is simple and intuitive, but once the facial posture or expression changes, the accuracy severely decreases.
1990s: In 1991, the famous “Eigenface” method first introduced principal component analysis and statistical feature techniques into face recognition, achieving significant practical progress. This idea was further developed in subsequent research, for example, Belhumeur successfully applied the Fisher discriminant criterion to face classification, proposing the Fisherface method based on linear discriminant analysis.
2000-2012: In the first decade of the 21st century, with the development of machine learning theory, scholars successively explored face recognition based on genetic algorithms, support vector machines (SVM), boosting, manifold learning, and kernel methods. From 2009 to 2012, sparse representation became a research hotspot due to its elegant theory and robustness against occlusion factors. Meanwhile, the industry reached a consensus: feature extraction based on artificially designed local descriptors and feature selection using subspace methods could achieve the best recognition results.
Gabor and LBP feature descriptors are the two most successful artificially designed local descriptors in the field of face recognition to date. During this period, targeted processing of various factors affecting face recognition was also a research hotspot, such as face illumination normalization, face posture correction, face super-resolution, and occlusion handling.
It was also during this period that researchers shifted their focus from face recognition in constrained scenarios to face recognition in unconstrained environments. The LFW face recognition public competition (LFW is a publicly available face dataset released and maintained by the University of Massachusetts, with a test data scale of ten thousand) became popular in this context. At that time, the best recognition systems, although achieving over 99% recognition accuracy on the constrained FRGC test set, only achieved a maximum accuracy of around 80% on LFW, appearing quite far from practical application.
2013: Researchers at Microsoft Research Asia first attempted large-scale training data of 100,000, and based on high-dimensional LBP features and Joint Bayesian methods, achieved 95.17% accuracy on LFW. This result indicated that large training datasets are crucial for effectively improving face recognition in unconstrained environments. However, all these classic methods struggled to handle training scenarios with large-scale datasets.
2014: Around 2014, with the development of big data and deep learning, neural networks regained attention and achieved results far exceeding classical methods in applications such as image classification, handwriting recognition, and speech recognition. Sun Yi and others from the Chinese University of Hong Kong proposed applying convolutional neural networks to face recognition, achieving recognition accuracy exceeding human levels on LFW with 200,000 training data, marking a milestone in the history of face recognition development. Since then, researchers have continuously improved network structures while expanding the training sample size, pushing the recognition accuracy on LFW above 99.5%. Some classic methods in the development of face recognition and their accuracy on LFW show a basic trend: the training data scale is getting larger, and recognition accuracy is getting higher.
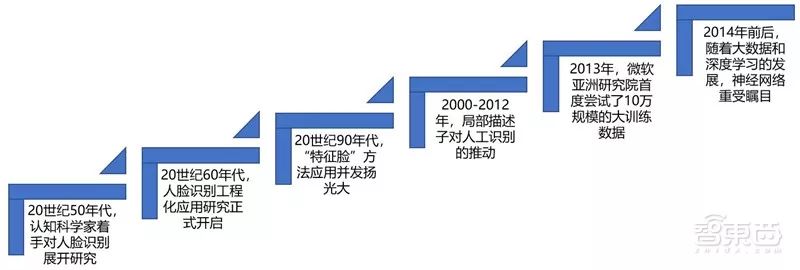 Development History of Face Recognition Technology
Development History of Face Recognition Technology
3. Policy Support in China
Since 2015, the state has issued a series of policies including “Guiding Opinions on the Remote Opening of RMB Accounts by Banking Financial Institutions (Draft for Comment)”, which opened the door for the popularization of face recognition; subsequently, legal regulations such as “Technical Requirements for Security Prevention Video Surveillance Face Recognition Systems” and “Information Security Technology Network Face Recognition Authentication System Security Technical Requirements” laid a solid foundation for the popularization of face recognition in finance, security, and healthcare, clearing policy obstacles. At the same time, in 2017, artificial intelligence was first included in the national government report. As an important subfield of artificial intelligence, the state is continuously increasing its policy support for face recognition. The “Three-Year Action Plan for Promoting the Development of a New Generation of Artificial Intelligence Industry (2018-2020)” released in December 2017 plans that by 2020, the effective detection rate of face recognition in complex dynamic scenes will exceed 97%, and the correct identification rate will exceed 90%.
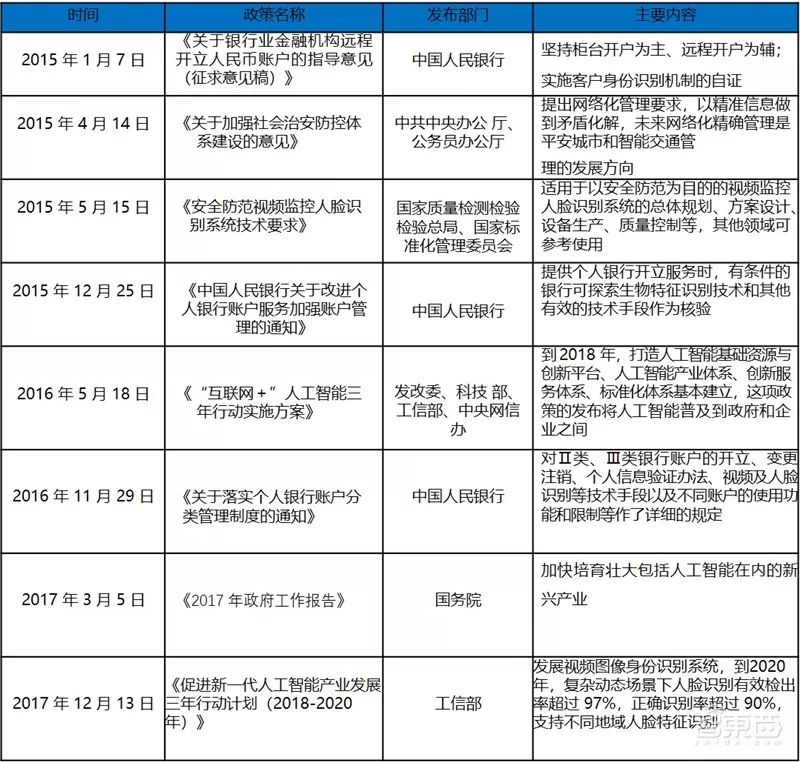 Policies Related to Face Recognition
Policies Related to Face Recognition
4. Development Hotspots
Research through the mining of previous papers in the field of face recognition summarizes that the main research keywords in the field of face recognition are concentrated in face recognition, feature extraction, sparse representation, image classification, neural networks, object detection, face images, face detection, image representation, computer vision, posture estimation, and face confirmation.
The following figure is an analysis of research trends in face recognition, aiming to study the sources, popularity, and even development trends of technology based on historical scientific research data. In Figure 2, each colored branch represents a keyword field, with its width indicating the research popularity of that keyword. The position of each keyword in each year is sorted according to the height of all keywords’ popularity during that time. Initially, Computer Vision was the research hotspot, and at the end of the 20th century, Feature Extraction surpassed CV to become the new hotspot, which was then surpassed by Face Recognition in the early 21st century, and has remained in second place ever since.
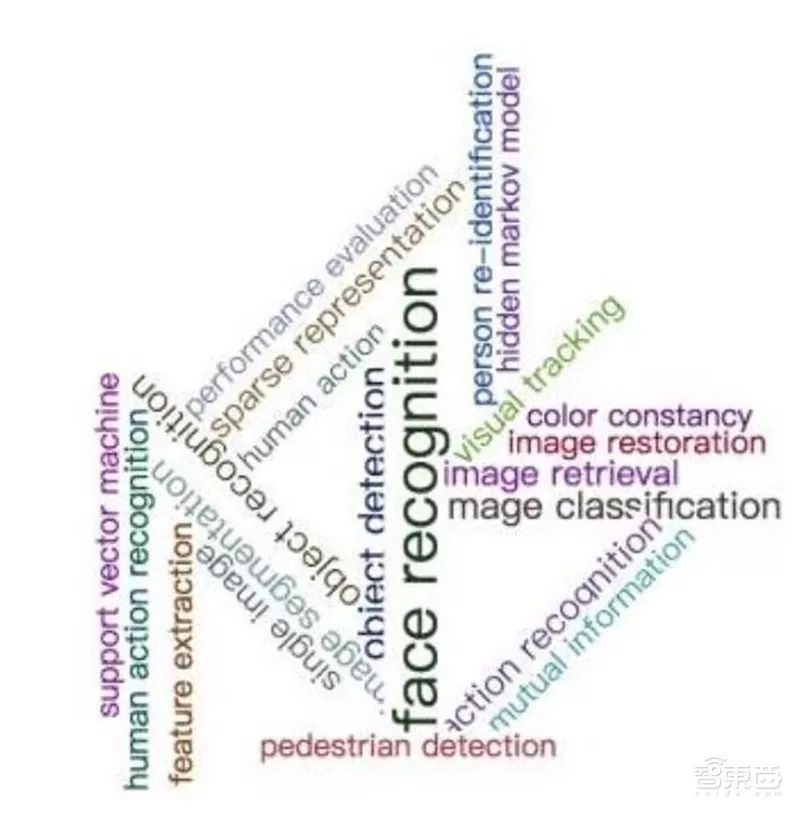 Hotspots Related to Face Recognition
Hotspots Related to Face Recognition
In addition, research based on keywords extracted from papers published in the last two years at FG (International Conference on Automatic Face and Gesture Recognition) found that Face Recognition appeared most frequently, with 118 occurrences, followed by Object Detection with 41 occurrences, and Image Classification and Object Recognition tied for third place with 36 occurrences each. Other terms appearing more than ten times include Image Segmentation (32), Action Recognition (32), Sparse Representation (28), Image Retrieval (27), Visual Tracking (24), and Single Image (23). The word cloud is as follows:
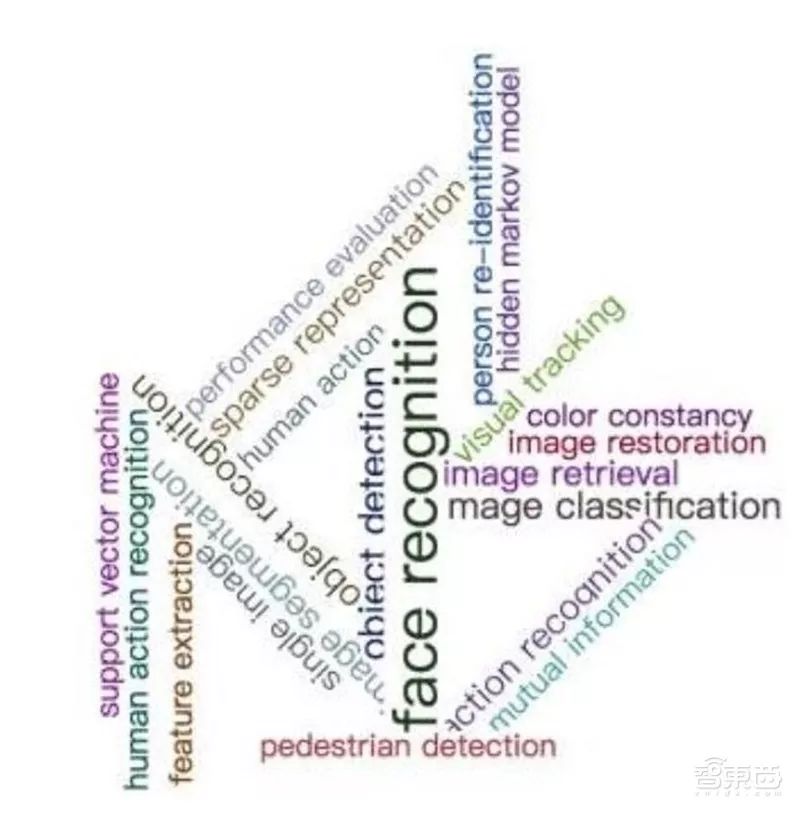 Word Cloud Analysis of Face Recognition
Word Cloud Analysis of Face Recognition
5. Conferences Related to Face Recognition
The three top international conferences in the field of computer vision (CV):
ICCV: IEEE International Conference on Computer Vision
This conference is hosted by the Institute of Electrical and Electronics Engineers (IEEE) and is mainly held in some countries with strong research capabilities in Europe, Asia, and America. As one of the world’s top academic conferences, the first International Conference on Computer Vision was held in London in 1987, and it has been held every two years since then. ICCV is the highest-level conference in the field of computer vision, and the conference proceedings represent the latest development directions and levels in the field of computer vision. The acceptance rate for papers is around 20%. The directions include computer vision, pattern recognition, multimedia computing, etc.
In recent years, the global academic community has paid increasing attention to the scientific achievements of Chinese individuals in the field of computer vision, as research led by Chinese individuals has made significant progress—over 30 papers from mainland China, Hong Kong, and Taiwan were selected from over 1200 papers submitted to the 2007 conference, accounting for over 12% of the total selected papers. As one of the earliest Chinese teams to invest in deep learning technology research, the team led by Professor Tang Xiaowu from the Chinese University of Hong Kong achieved rapid breakthroughs based on the key technologies laid out over many years. In the 2012 International Conference on Computer Vision and Pattern Recognition (CVPR), the only two deep learning papers were both from Tang Xiaowu’s laboratory, and among the eight deep learning papers published globally at the 2013 International Conference on Computer Vision (ICCV), six were from Tang Xiaowu’s laboratory.
CVPR: IEEE Conference on Computer Vision and Pattern Recognition
This conference is the top conference in the fields of computer vision and pattern recognition, held annually with an acceptance rate of around 25%. The directions include computer vision, pattern recognition, multimedia computing, etc.
Professor Tang Xiaowu’s team from the Chinese University of Hong Kong has made numerous original breakthroughs in deep learning technology globally: the only two deep learning papers presented at the 2012 International Conference on Computer Vision and Pattern Recognition (CVPR) were from his laboratory; between 2011 and 2013, 14 deep learning papers were published at the two top conferences in the field of computer vision, ICCV and CVPR, accounting for nearly half of the total number of deep learning papers at these two conferences (29 papers). He won the best paper award at CVPR, one of the two top international conferences in the field of computer vision, in 2009, marking the first time a paper from Asia won this award in CVPR’s history.
ECCV: European Conference on Computer Vision
ECCV is a European conference that accepts around 300 papers globally at each meeting, with most accepted papers coming from top laboratories and research institutes in the United States and Europe, while the number of papers from mainland China typically ranges from 10 to 20. The acceptance rate for papers at ECCV 2010 was 27%. It is held every two years, with an acceptance rate of around 20%. The directions include computer vision, pattern recognition, multimedia computing, etc. The 2018 ECCV was held from September 8-14, 2018, in Munich, Germany.
Asian Conference on Computer Vision:
ACCV: Asian Conference on Computer Vision
ACCV, or the Asian Conference on Computer Vision, is a biennial conference officially organized by the AFCV (Asian Federation of Computer Vision) since 1993, aiming to provide a good platform for researchers, developers, and participants to showcase and discuss new problems, solutions, and technologies in the field of computer vision and related fields. The 14th Asian Conference on Computer Vision will be held from December 4-6, 2018, in Australia.
Conferences specifically focused on face and gesture recognition:
FG: IEEE International Conference on Automatic Face and Gesture Recognition
The “International Conference on Automatic Face and Gesture Recognition” is an authoritative academic conference in the global field of face and gesture recognition. The conference focuses on face detection, face recognition, expression recognition, posture analysis, psychological behavior analysis, etc.
II. Detailed Explanation of Face Recognition Technology
1. Face Recognition Process
The principles of face recognition technology can be summarized in three main steps:
-
First, establish a database containing a large number of face images,
-
Second, obtain the target face image to be recognized through various means,
-
Third, compare and filter the target face image with existing face images in the database.
The specific technical process for implementing the principles of face recognition mainly includes the following four parts: the acquisition and preprocessing of facial images, face detection, face feature extraction, and face recognition and liveness detection.
 Face Recognition Technology Process
Face Recognition Technology Process
Acquisition and Preprocessing of Facial Images
The acquisition and detection of facial images can be divided into two parts: the acquisition of facial images and the detection of facial images.
Acquisition of Facial Images: There are typically two ways to acquire facial images: batch import of existing facial images and real-time acquisition of facial images. Some advanced face recognition systems can even conditionally filter out facial images that do not meet recognition quality requirements or have low clarity, aiming for clear and precise acquisition. Batch import of existing facial images means importing a large number of previously collected facial images into the face recognition system, which will automatically complete the acquisition of each individual facial image. Real-time acquisition of facial images refers to using a camera or webcam to automatically capture facial images within the device’s shooting range.
Preprocessing of Facial Images: The purpose of preprocessing facial images is to further process the detected facial images to facilitate feature extraction. Specifically, preprocessing refers to a series of complex processing steps such as adjusting lighting, rotation, cropping, filtering, denoising, and resizing to ensure that the facial image meets the standard requirements for feature extraction in terms of lighting, angle, distance, size, etc. In real-world environments, due to factors such as varying lighting conditions, facial expression changes, and shadow occlusions, the quality of captured images may not be ideal, necessitating preprocessing. If preprocessing is not done well, it can severely affect subsequent face detection and recognition. The research introduces three image preprocessing techniques, namely grayscale adjustment, image filtering, and image size normalization.
Grayscale Adjustment: Since the final processed image for facial image processing is generally a binary image, and due to differences in location, equipment, and lighting, the quality of captured color images may vary, it is necessary to perform uniform grayscale processing to smooth out these differences. Common methods for grayscale adjustment include the average method, histogram transformation, power transformation, and logarithmic transformation.
Image Filtering: In the actual process of capturing facial images, the quality of facial images may be affected by various noise sources, such as electromagnetic signals in the surrounding environment or interference during digital image transmission. To ensure image quality and reduce the impact of noise on subsequent processing, it is essential to perform noise reduction. There are many principles and methods for noise reduction, with common ones including mean filtering and median filtering. Currently, the median filtering algorithm is commonly used for preprocessing facial images.
Image Size Normalization: When conducting simple face training, if the pixel sizes of images in the face database differ, it is necessary to perform size normalization before the face comparison and recognition on the upper computer. Common normalization algorithms include bilinear interpolation, nearest neighbor interpolation, and cubic convolution algorithms.
Face Detection
An image containing a face may also contain other content; therefore, face detection is necessary. This means that within an image containing a face, the system will accurately locate the position and size of the face, while automatically filtering out other extraneous image information to ensure the precise acquisition of facial images.
Face detection is an important part of face recognition. Face detection refers to the process of applying certain strategies to search the given images or videos to determine whether a face exists. If it does, it locates the position, size, and posture of each face. Face detection is a challenging object detection problem, mainly reflected in two aspects:
Intrinsic Variations of Face Targets:
-
Faces have quite complex detail variations and different expressions (such as the opening and closing of eyes and mouth), and different faces have different appearances, such as face shape and skin color;
-
Face occlusions, such as glasses, hair, and head accessories.
Extrinsic Condition Variations:
-
Different imaging angles can cause various postures of the face, such as rotation in the plane, depth rotation, and up-and-down rotation, with depth rotation having a significant impact;
-
The impact of lighting, such as changes in brightness and contrast in the image and shadows;
-
The imaging conditions of the image, such as the focal length and imaging distance of the camera device.
The role of face detection is to accurately locate the position and size of the face within an image, while automatically filtering out other extraneous image information to further ensure the precise acquisition of facial images. Face detection focuses on the following metrics:
Detection Rate: Correctly recognized faces / all faces in the image. The higher the detection rate, the better the detection model’s performance;
False Detection Rate: Incorrectly recognized faces / recognized faces. The lower the false detection rate, the better the detection model’s performance;
Miss Detection Rate: Unrecognized faces / all faces in the image. The lower the miss detection rate, the better the detection model’s performance; Speed: The time from the completion of image capture to the completion of face detection. The shorter the time, the better the detection model’s performance.
Currently, face detection methods can be divided into three categories: detection based on skin color models, detection based on edge features, and detection based on statistical theoretical methods. Below is a brief introduction to each:
-
Detection Based on Skin Color Models: When using skin color for face detection, various modeling methods can be employed, mainly including Gaussian models, Gaussian mixture models, and non-parametric estimations. By using Gaussian models and Gaussian mixture models, skin color models can be established in different color spaces for face detection. The method of extracting facial regions from color images to achieve face detection can handle various lighting situations; however, this algorithm is only effective under fixed camera parameters. Comaniciu and others utilized a non-parametric kernel function probability density estimation method to establish skin color models and used the mean-shift method for local search to achieve face detection and tracking. This method improved the speed of face detection and has certain robustness against occlusion and lighting. However, this method’s limitations include low compatibility with other methods, and it faces difficulties when dealing with complex backgrounds and multiple faces. To address lighting issues in face detection, compensations for different lighting conditions can be applied before detecting the skin color regions in the image. This can resolve issues with polarized colors, complex backgrounds, and multiple face detections in color images, but it is insensitive to facial color, position, scale, rotation, posture, and expression.
-
Detection Based on Edge Features: When using edge features to detect faces, the computational load is relatively small, allowing for real-time detection. Most algorithms using edge features are based on the contour characteristics of the face, utilizing established templates (such as elliptical templates) for matching. Some researchers have also adopted elliptical ring models and edge direction features to achieve face detection in simple backgrounds. Fröba and others used edge-orientation matching (EOM) methods to detect faces in edge direction maps. This algorithm has a high false detection rate in complex backgrounds; however, it can achieve good results when combined with other features.
-
Statistical Theoretical Methods: This article focuses on the Adaboost face detection algorithm based on statistical theoretical methods. The Adaboost algorithm seeks the optimal classifier through numerous iterations. By placing any feature from the weak classifiers (Haar features) on the face samples, the facial feature values are calculated. By cascading more classifiers, the quantized features of the face are obtained, distinguishing faces from non-faces. Haar features consist of simple black and white rectangles oriented horizontally, vertically, or at 45° angles. Generally, the Haar features can be broadly classified into three categories: edge features, line features, and center features.
This algorithm was proposed by scholars Paul Viola and Michael Jones from Cambridge University. Its advantages include not only fast computation speed but also comparable performance to other algorithms, making it widely used in face detection; however, it also has a high false detection rate. During the learning process of the Adaboost algorithm, some face and non-face patterns are difficult to distinguish, and the detection results may include windows that do not resemble face patterns.
Face Feature Extraction
Currently, mainstream face recognition systems support features typically divided into facial visual features and pixel statistical features of facial images, while feature extraction for facial images targets specific features on the face. Simple features allow for simple matching algorithms, suitable for large-scale databases; conversely, they are suitable for smaller databases. Feature extraction methods generally include knowledge-based extraction methods or algebraic feature-based extraction methods.
Taking one of the knowledge-based facial recognition extraction methods as an example, since a face is primarily composed of eyes, forehead, nose, ears, chin, mouth, and other parts, the structural relationships between these parts can be described using geometric shape features. In other words, each person’s facial image can correspond to a geometric shape feature that helps us as an important distinguishing feature for recognizing faces, which is also one of the knowledge-based extraction methods.
Face Recognition
We can set a similarity threshold for facial recognition systems, and compare the corresponding facial images with all facial images in the system database. If the similarity exceeds the preset threshold, the system will output those facial images one by one. At this point, we need to perform precise filtering based on the degree of similarity and the identity information of the face itself. This precise filtering process can be divided into two categories: one-to-one filtering, which is the process of confirming the identity of the face; and one-to-many filtering, which is the process of matching and comparing based on facial similarity.
Liveness Detection
One common problem in biometric recognition is distinguishing whether the signal originates from a real biological entity. For example, fingerprint recognition systems need to determine whether the fingerprint being recognized comes from a human finger or a fingerprint glove. In face recognition systems, the captured facial image needs to be verified to determine whether it comes from a real face or a photo containing a face. Therefore, practical face recognition systems generally need to include a liveness detection step, such as requiring the person to turn their head, blink, or say something.
2. Main Methods of Face Recognition
The research on face recognition technology spans multiple disciplines, including knowledge from image processing, physiology, psychology, pattern recognition, and more. Currently, there are several main research directions in the field of face recognition: one is recognition methods based on statistical features of facial characteristics, mainly including feature face methods and hidden Markov models (HMM); another face recognition method involves connection mechanisms, mainly including artificial neural networks (ANN) and support vector machine (SVM) methods; and there is also a method that integrates various recognition methods.
Feature Face Method
The feature face method is a relatively classic and widely applied face recognition method. Its main principle is to apply dimensionality reduction algorithms to make data processing easier while achieving relatively fast speeds. The feature face method for face recognition essentially performs a Karhunen-Loeve transformation on the images, converting a high-dimensional vector into a low-dimensional vector, thereby eliminating correlations between each component, resulting in a transformation that has good translational invariance and stability. Thus, the feature face method for face recognition is convenient to implement, can achieve faster speeds, and has a relatively high recognition rate for frontal face images. However, this method also has shortcomings, as it is relatively susceptible to factors such as facial expressions, postures, and lighting changes, leading to lower recognition rates.
Geometric Feature-Based Method
The geometric feature-based recognition method is a face recognition method based on the features and geometric shapes of facial organs, which is one of the earliest researched and used recognition methods. It primarily matches and recognizes based on different features of various faces. This algorithm has a relatively fast recognition speed, and its memory usage is also relatively small; however, its recognition rate is not particularly high. The main approach of this method is to first detect the positions and sizes of major facial features such as the mouth, nose, and eyes, and then match based on the geometric distribution relationships and proportions of these organs, achieving face recognition.
The process of recognizing geometric features is roughly as follows:
-
First, detect the positions of various feature points of the face, such as the positions of the nose, mouth, and eyes, and then calculate the distances between these features to obtain vector feature information that can represent each feature face, such as the position of the eyes and the length of the eyebrows;
-
Second, calculate the corresponding relationships of each feature and compare them with the known facial feature information in the face database;
-
Finally, obtain the best-matching face. The geometric feature-based method aligns with people’s understanding of facial features. Moreover, each face only stores one feature, so it occupies less space; simultaneously, this method does not reduce its recognition rate due to variations caused by lighting, and the matching and recognition rates of feature templates are relatively high. However, the geometric feature-based method also has weaknesses in robustness; once expressions and postures change slightly, the recognition effect will significantly decline.
Deep Learning-Based Method
The emergence of deep learning has led to breakthrough progress in face recognition technology. Recent research results in face recognition indicate that face feature representations obtained through deep learning possess important characteristics that handcrafted feature representations do not have, such as being moderately sparse, having strong selectivity for face identity and attributes, and good robustness against local occlusions. These characteristics are naturally obtained through training with large data sets, without adding explicit constraints or post-processing to the model, which is also the main reason for the successful application of deep learning in face recognition.
Deep learning has seven typical applications in face recognition: methods based on convolutional neural networks (CNN), deep nonlinear face shape extraction methods, robust modeling of face posture based on deep learning, fully automatic face recognition in constrained environments, face recognition under video surveillance based on deep learning, low-resolution face recognition based on deep learning, and other face-related information recognition based on deep learning.
Among these, convolutional neural networks (CNN) are the first learning algorithm to successfully train multi-layer network structures, and methods based on convolutional neural networks for face recognition are a machine learning model under deep supervised learning that can mine local features from data, extract global training features, and classify. Its weight-sharing structure makes it more similar to biological neural networks, and it has been successfully applied in various fields of pattern recognition. CNN fully utilizes the locality contained in the data by combining local perceptive regions of face images, shared weights, and spatial or temporal down-sampling to optimize model structures and ensure a certain degree of translational invariance.
Using the CNN model, the Deep ID project from the Chinese University of Hong Kong and Facebook’s Deep Face project achieved recognition accuracies of 97.45% and 97.35% on the LFW database, respectively, only slightly lower than the human visual recognition accuracy of 97.5%. After achieving breakthrough results, the DeepID2 project from the Chinese University of Hong Kong improved the recognition rate to 99.15%. Deep ID2 minimizes within-class variations through learning nonlinear feature transformations while keeping the distances between face images of different identities constant, exceeding the recognition rates of all leading deep learning and non-deep learning algorithms on the LFW database as well as the recognition rate of humans on that database. Deep learning has become a research hotspot in computer vision, with new algorithms and directions constantly emerging, and the performance of deep learning algorithms gradually surpassing that of shallow learning algorithms in some major international evaluation competitions.
Support Vector Machine-Based Method
The application of support vector machine (SVM) methods in face recognition originated from statistical theory, focusing on how to construct effective learning machines to solve pattern classification problems. Its characteristics include transforming the image into a different space for classification.
Support vector machine structures are relatively simple and can achieve global optimal solutions, making SVM widely applied in the current field of face recognition. However, this method also shares the same shortcomings as neural network methods, requiring large storage space and having relatively slow training speeds.
Other Comprehensive Methods
From the various commonly used face recognition methods, it is evident that each recognition method cannot achieve perfect recognition rates and faster recognition speeds, each having its own advantages and disadvantages. Therefore, many researchers prefer to combine multiple recognition methods to leverage the strengths of various recognition methods, achieving higher recognition rates and effects.
Three Classic Algorithms for Face Recognition
-
Eigenface Method
The Eigenface technique is a method that has recently developed for face or general rigid body recognition and other processes involving face processing. The method of using Eigenfaces for face recognition was first proposed by Sirovich and Kirby (1987) in “Low-dimensional procedure for the characterization of human faces” and was used for face classification by Matthew Turk and Alex Pentland in “Eigenfaces for recognition.” The process begins by transforming a batch of face images into a set of feature vectors called “Eigenfaces,” which are the fundamental components of the initial training image set. The recognition process projects a new image into the Eigenface subspace and determines recognition based on its projection point’s location in the subspace and the length of the projection line.
After transforming the images into another space, images of the same category tend to cluster together, while images of different categories are spaced further apart. In the original pixel space, it is challenging to separate different categories of images using simple lines or planes; however, transforming to another space allows for better separation. The method chosen for transforming the Eigenfaces space is PCA (Principal Component Analysis), which utilizes PCA to obtain the main components of the face distribution, specifically implementing eigenvalue decomposition of the covariance matrix of all face images in the training set to obtain the corresponding eigenvectors, which are the “Eigenfaces.” Each eigenvector or Eigenface captures or describes a variation or characteristic among faces. This means that each face can be represented as a linear combination of these Eigenfaces.
-
Local Binary Patterns (LBP)
Local Binary Patterns (LBP) is a visual operator used for classification in the field of computer vision. LBP is an operator used to describe image texture features, proposed by T. Ojala et al. from the University of Oulu, Finland, in 1996 in “A comparative study of texture measures with classification based on featured distributions.” In 2002, T. Ojala and others published another article on LBP in PAMI titled “Multiresolution gray-scale and rotation invariant texture classification with local binary patterns.” This article clearly explains the improvements of multi-resolution, gray-scale invariance, rotation invariance, and equivalent patterns in LBP features. The core idea of LBP is to use the gray value of the central pixel as a threshold, comparing it with its neighborhood to obtain corresponding binary codes representing local texture features.
LBP extracts local features as the basis for discrimination. The significant advantage of the LBP method is its insensitivity to lighting, but it still does not solve the issues of posture and expression. However, compared to the Eigenface method, LBP has seen a significant improvement in recognition rates.
-
Fisherface
Linear discriminant analysis considers class information while performing dimensionality reduction, invented by statistician Sir R. A. Fisher in 1936 in “The use of multiple measurements in taxonomic problems.” The goal is to find a way to combine features to achieve maximum inter-class dispersion and minimum intra-class dispersion. The idea is simple: in a low-dimensional representation, the same class should cluster closely together while different classes should be as far apart as possible. In 1997, Belhumeur successfully applied the Fisher discriminant criterion to face classification, proposing the Fisherface method based on linear discriminant analysis in “Eigenfaces vs. Fisherfaces: Recognition using class specific linear projection.”
Classic Papers
Sirovich, L., & Kirby, M. (1987). Low-dimensional procedure for the characterization of human faces. Josa a, 4(3), 519-524. The study proved that any specific face can be represented by a coordinate system called Eigenpictures. Eigenpictures are the eigenfunctions of the average covariance of the face set.
Turk, M., & Pentland, A. (1991). Eigenfaces for recognition. Journal of cognitive neuroscience, 3(1), 71-86. The study developed a near real-time computer system that can locate and track a person’s head, recognizing the individual by comparing facial features with known individuals. This method treats the face recognition problem as a two-dimensional recognition problem. The recognition process involves projecting a new image into the Eigenface subspace, where the feature space captures significant variations among known facial images. Important features are called Eigenfaces because they are the feature vectors of the face set.
Ojala, T., Pietikäinen, M., & Harwood, D. (1996). A comparative study of texture measures with classification based on featured distributions. Pattern recognition, 29(1), 51-59. The study compares different graphic textures and proposes the LBP operator used to describe image texture features.
Ojala, T., Pietikainen, M., & Maenpaa, T. (2002). Multiresolution gray-scale and rotation invariant texture classification with local binary patterns. IEEE Transactions on pattern analysis and machine intelligence, 24(7), 971-987. The study proposes a theoretically simple yet effective gray-scale and rotation invariant texture classification method based on local binary patterns and non-parametric discrimination of sample and prototype distributions. This method is robust against gray-scale variations and computationally simple.
Fisher, R. A. (1936). The use of multiple measurements in taxonomic problems. Annals of eugenics, 7(2), 179-188. The study finds a way to combine features to achieve maximum inter-class dispersion and minimum intra-class dispersion. The solution is that in a low-dimensional representation, the same class should cluster closely together while different classes should be as far apart as possible.
Belhumeur, P. N., Hespanha, J. P., & Kriegman, D. J. (1997). Eigenfaces vs. fisherfaces: Recognition using class specific linear projection. Yale University New Haven United States. The study projects faces based on Fisher’s linear discriminant, generating well-separated classes in a low-dimensional subspace, even under significant variations in lighting and facial expressions. Extensive experimental results indicate that the proposed “Fisherface” method has a lower error rate than the Eigenface technique tested on the Harvard and Yale face databases.
Commonly Used Face Databases
The following are some commonly used face databases:
FERET Face Database
http://www.nist.gov/itl/iad/ig/colorferet.cfm
Created by the FERET project, this image set contains a large number of face images, with only one face in each image. The collection includes variations in expression, lighting, posture, and age for the same person. It contains over 10,000 multi-posture and lighting face images, making it one of the most widely used face databases in the field of face recognition. Most individuals in the collection are Westerners, and the variations of facial images for each person are relatively singular.
CMU Multi-PIE Face Database
http://www.flintbox.com/public/project/4742/
Established by Carnegie Mellon University in the USA. “PIE” stands for Pose, Illumination, and Expression. The CMU Multi-PIE face database is developed based on the CMU-PIE face database. It contains over 75,000 facial images of 337 volunteers, capturing multi-posture, lighting, and expression variations under strictly controlled conditions, and has gradually become an important test set in the field of face recognition.
YALE Face Database (USA, Yale University)
http://cvc.cs.yale.edu/cvc/projects/yalefaces/yalefaces.html
Created by the Yale University Center for Computer Vision and Control, it contains 165 images of 15 volunteers, including variations in lighting, expression, and posture.
Each volunteer in the Yale face database has 10 sample images, which contain more pronounced variations in lighting, expression, and posture compared to the ORL face database.
YALE Face Database B
https://computervisiononline.com/dataset/1105138686
Contains images of 10 individuals under 9 postures and 64 lighting conditions, totaling 5,850 images. The posture and lighting variations are collected under strictly controlled conditions, mainly used for modeling and analyzing lighting and posture issues. Due to the small number of individuals captured, further applications of this database are significantly limited.
MIT Face Database
Created by the Massachusetts Institute of Technology Media Lab, it contains 2,592 images of 16 volunteers with different postures (27 images per person), lighting, and sizes of facial images.
ORL Face Database
https://www.cl.cam.ac.uk/research/dtg/attarchive/facedatabase.html
Created by the AT&T Laboratory in Cambridge, UK, it contains 400 facial images of 40 individuals, with some images including variations in posture, expression, and facial accessories. This face database was frequently used in the early stages of face recognition research; however, due to limited variation patterns, most systems achieved recognition rates above 90%, making its further utilization less valuable.
In the ORL face database, each individual has a complete sample library containing 10 normalized grayscale images, all with a size of 92×112, and a black background. The facial expressions and details of the captured individuals vary, such as smiling or not, eyes open or closed, and wearing or not wearing glasses, with variations in posture also present, with depth rotation and planar rotation reaching up to 20 degrees.
BioID Face Database
https://www.bioid.com/facedb/
Contains 1,521 grayscale facial images captured under various lighting and complex backgrounds, with eye positions manually annotated.
UMIST Image Set
Established by the University of Manchester in the UK, it includes 564 images of 20 individuals, each with multiple images at different angles and postures.
Age Recognition Dataset IMDB-WIKI
https://data.vision.ee.ethz.ch/cvl/rrothe/imdb-wiki/
Contains 524,230 celebrity data images crawled from IMDB and Wikipedia. A novel regression algorithm for age classification is applied, which essentially involves classifying into 101 categories between 0-100, multiplying the obtained score by 0-100, and summing the final result to obtain the recognized age.
III. Technical Talent
1. Overview of Scholars
AMiner has conducted computational analysis of the top 1000 scholars in the field of face recognition based on academic papers published in international journals and conferences, creating a global distribution map of scholars in this field. From a global perspective, the USA has the highest concentration of scholars in face recognition research, holding an absolute advantage in this field; the UK follows closely in second place; China ranks third globally; and countries such as Canada, Germany, and Japan also have gathered some talent.
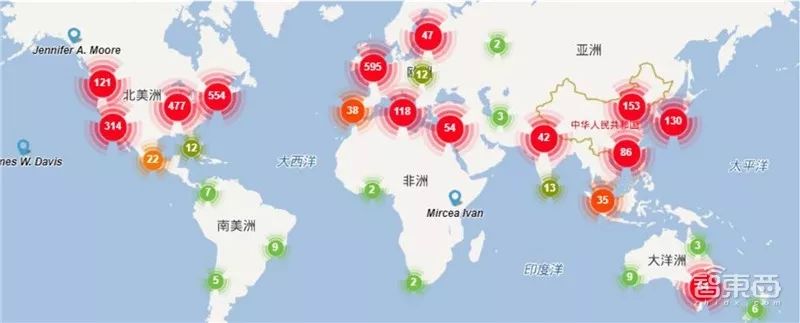 Global Distribution Map of Face Recognition Scholars TOP1000
Global Distribution Map of Face Recognition Scholars TOP1000
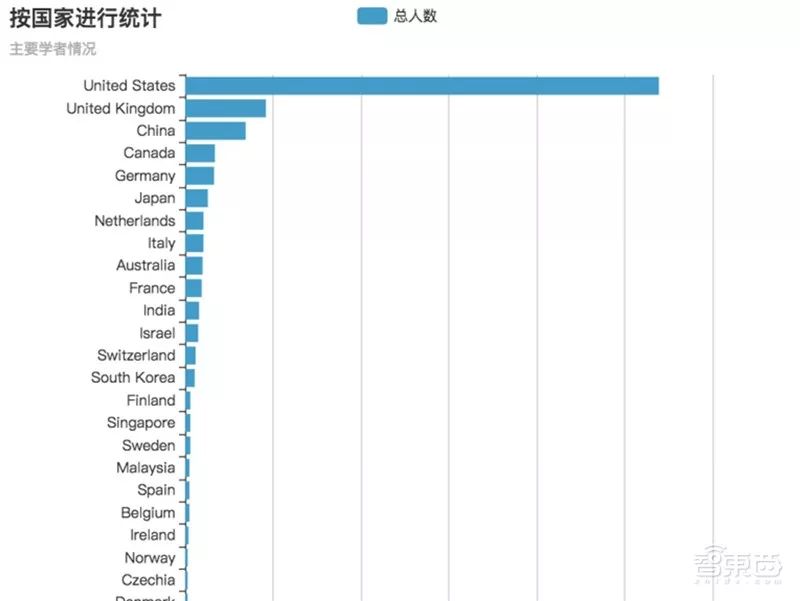 Ranking of Countries with Face Recognition Experts
Ranking of Countries with Face Recognition Experts
 Global Scholar h-index Statistics in Face Recognition
Global Scholar h-index Statistics in Face Recognition
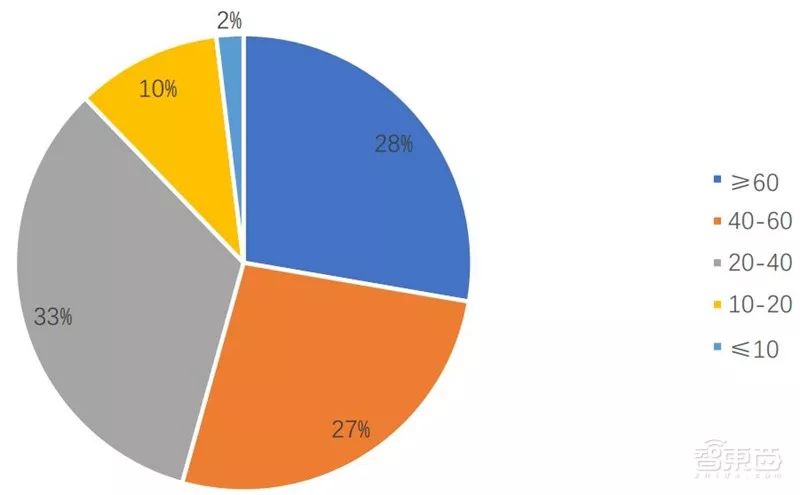
h-index: An internationally recognized index that accurately reflects a scholar’s academic achievements. The calculation method is that the scholar has at most h papers cited at least h times.
The average h-index of global face recognition scholars is 48. The majority of scholars have h-index values between 20 and 40, accounting for 33%; those with h-index values between 40 and 60 and greater than 60 are nearly equal, with the former at 27% and the latter at 28%; scholars with h-index values less than or equal to 10 are the least, accounting for only 2%.
 Global Talent Migration Map in Face Recognition
Global Talent Migration Map in Face Recognition
AMiner selected the top 1000 influential experts and scholars in the field of face recognition and analyzed their migration paths. As shown in the above image, there are slight differences in the outflow and inflow of talent in the field of face recognition among various countries. The USA is a major country for talent flow in the field of face recognition, with significant inflows and outflows, and data indicates that the inflow slightly exceeds the outflow. The UK, China, Germany, Canada, and Australia follow closely, with slight talent outflows observed in the UK, China, and Australia.
Research based on citation and h-index rankings of face recognition experts from the authoritative academic conference (IEEE International Conference on Automatic Face and Gesture Recognition, FG) in the last five years has calculated the top ten face recognition experts based on citation and h-index.
The following are the top ten related scholars ranked by citation:
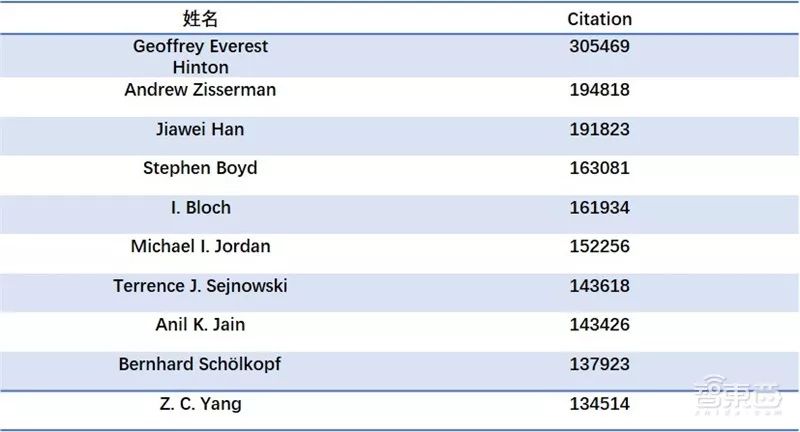 Top Ten Face Recognition Experts by Citation
Top Ten Face Recognition Experts by Citation
The following are the top twelve related scholars ranked by h-index:
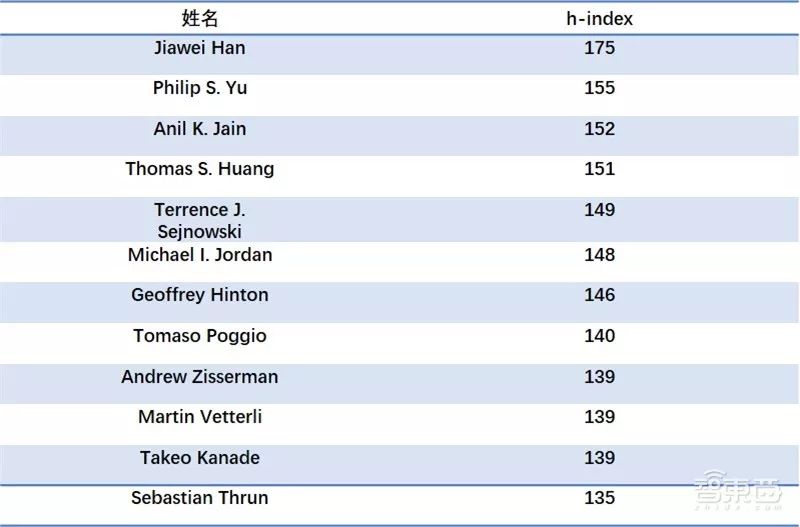 Top Ten Face Recognition Experts by h-index
Top Ten Face Recognition Experts by h-index
2. Domestic and International Talent
The report lists six global experts and five domestic experts, as detailed in the appendix of this reference.
IV. Application Fields
From an application perspective, face recognition is widely applicable, including automatic access control systems, identification of identity documents, bank ATM withdrawals, and home security, among others. Specifically, the main applications include:
-
Public Safety: Criminal investigation and pursuit, criminal identification, border security checks;
-
Information Security: Computer and network logins, file encryption and decryption;
-
Government Functions: E-government, household registration management, social welfare, and insurance;
-
Commercial Enterprises: E-commerce, electronic currency and payments, attendance, marketing;
-
Access Control: Access control and management in military sensitive departments and financial institutions.
Access Control Face Recognition
As people’s living standards improve, they pay more attention to the safety of their home environments, and security awareness continues to strengthen. Along with this increased demand, intelligent access control systems have emerged, and more and more enterprises, shops, and homes are installing various access control systems.
Currently, commonly used access control systems include video access control, password access control, radio frequency access control, and fingerprint access control. Among them, video access control simply transmits video information to users without much intelligence, essentially relying on “human defense”; when users are not present, it cannot ensure home security absolutely; password access control has the major flaw of being easy to forget and easily cracked; radio frequency access control has the disadvantage of “recognizing cards but not people”; radio frequency cards are easy to lose and can be stolen by others; additionally, fingerprint access control has security risks as fingerprints can be easily copied. Therefore, the existing access control systems provided by current technology all have low security issues corresponding to these reasons. With a face recognition system installed, users can easily enter and exit the community by simply showing their face to the camera, truly realizing “face card” access. Biometric access control systems do not require carrying verification media, and the verification features are unique, ensuring high security. They are currently widely used in highly classified locations, such as research institutes and banks.
Marketing
Facial recognition technology has two main applications in marketing: first, it can identify a person’s basic personal information, such as gender, approximate age, and what they have looked at and for how long. Outdoor advertising companies, such as Val Morgan Outdoor (VMO), have begun using facial recognition technology to collect consumer data. Second, this technology can be used to recognize known individuals, such as thieves or members already in the system. This aspect of application has attracted the attention of some service providers and retailers.
In addition, facial recognition technology can enhance the effectiveness of advertisements and allow advertisers to respond promptly to consumer behavior. VMO has launched a measurement tool called DART that can show in real-time the direction and duration of consumers’ eye attention, thus determining their level of interest in an advertisement. The next generation of DART will incorporate more demographic information, in addition to age, including the emotions of consumers when viewing a digital sign.
Commercial Banks
Using facial recognition technology to prevent network risks: For the magnetic stripe bank cards widely used in China, although the technology is mature and standardized, the production technology is not complex, and the standards for bank magnetic stripe card tracks have become an open secret. With just a computer and a magnetic stripe reader, one can easily “clone” bank cards. Additionally, the management of card production machines is not strict. Cases of bank card fraud using cloned cards occur frequently, mainly by various means of “cloning” or stealing bank cards. Currently, various commercial banks have adopted some technical measures to prevent counterfeiting and cloning, such as using CVV (Check Value Verify) technology, which generates a verification value associated with each card’s characteristics during the generation of card magnetic stripe information, thus achieving the function of making copies invalid. Although various measures have been taken, the inherent flaws of magnetic stripe cards have severely threatened customers’ interests. For these banking network security issues, we can use facial recognition technology to prevent network risks. Facial recognition technology captures the facial area using imaging devices and matches the captured face with the faces in the database to complete the identity recognition task. By accurately identifying the true identity of the cardholder using facial recognition technology, the security of the cardholder’s funds is ensured. Additionally, facial recognition technology can further lock in criminals, aiding law enforcement in quickly solving cases.
Applications of facial recognition technology in combating counterfeit currency: Currently, there are several main issues with self-service devices in commercial banks:
-
First, some self-service devices are not installed according to requirements. Some self-service devices in commercial banks have not been installed according to the requirements of public security departments for ground reinforcement connections; some electrical environments do not meet the requirements; some have not set up 110 linkage alarms or visual monitoring alarms, and some monitoring recordings are not clear, with recording retention times not meeting regulatory requirements, and there is significant human damage to the equipment.
-
Second, there are software design flaws in the self-service device terminals. Particularly, some domestic devices have unreasonable software design, with significant variability in software changes, leading to vulnerabilities and increasing the likelihood of errors.
-
Third, ATMs in banks do not have counterfeit currency detection devices. Due to the issues with self-service devices in commercial banks, counterfeit currency has emerged frequently. As ATMs in banks do not have counterfeit currency detection devices, they only perform detection before cash is added by clearing personnel, making such measures inadequate and easily leading to disputes between banks and cardholders. Even though cash deposit machines (CRS) have counterfeit currency detection functions, they are often exploited by criminals due to delays in feature extraction for counterfeit detection. Criminals first deposit counterfeit currency and then immediately withdraw real currency at the counter or other self-service devices, thereby profiting unlawfully.
V. Future Trends
Overall, the trends in face recognition include the following aspects.
1. Combination of Machine Recognition and Human Recognition
Currently, some mainstream face recognition companies achieve recognition accuracy generally exceeding 95% when using well-known domestic and international face image databases for testing, and the speed of accurate face recognition is also very fast, providing strong practical proof for the practical application of face recognition technology.
However, in real life, each person’s face is not stationary relative to the camera; rather, it is in a high-speed motion state, and the face images captured by the camera may appear completely different due to variations in face posture, expression, lighting, and decorations, and it is very likely that the captured face images will be unclear, incomplete, or lack prominent key features. At this point, the face recognition system may not be able to achieve fast and accurate face recognition.
Therefore, after setting a certain similarity threshold for face images, the face recognition company’s system will prompt for face images that exceed this similarity threshold, and then human reviewers will perform individual filtering, combining machine recognition with human recognition to maximize the accuracy of face image recognition.
2. Widespread Application of 3D Face Recognition Technology
Whether from the mainstream face image databases that have stored face images or from face images captured in real-time by cameras at street corners, the vast majority are actually 2D face images. 2D face images inherently have the defect that they cannot deeply express face image information and are particularly susceptible to factors such as lighting, posture, and expression. For faces, key areas such as the eyes, nose, ears, and chin are not situated on a single plane, and faces inherently have a three-dimensional effect. Capturing 2D face images cannot fully reflect all the key features of the face.
In 2017, the iPhone X, equipped with many cutting-edge technologies, drew significant attention from the industry. Among its most eye-catching features was a black technology: the 3D facial unlocking function, known as Face ID, a new method of identity authentication. While unlocking, users only need to gaze at the phone, and Face ID can achieve facial recognition and unlock the device.
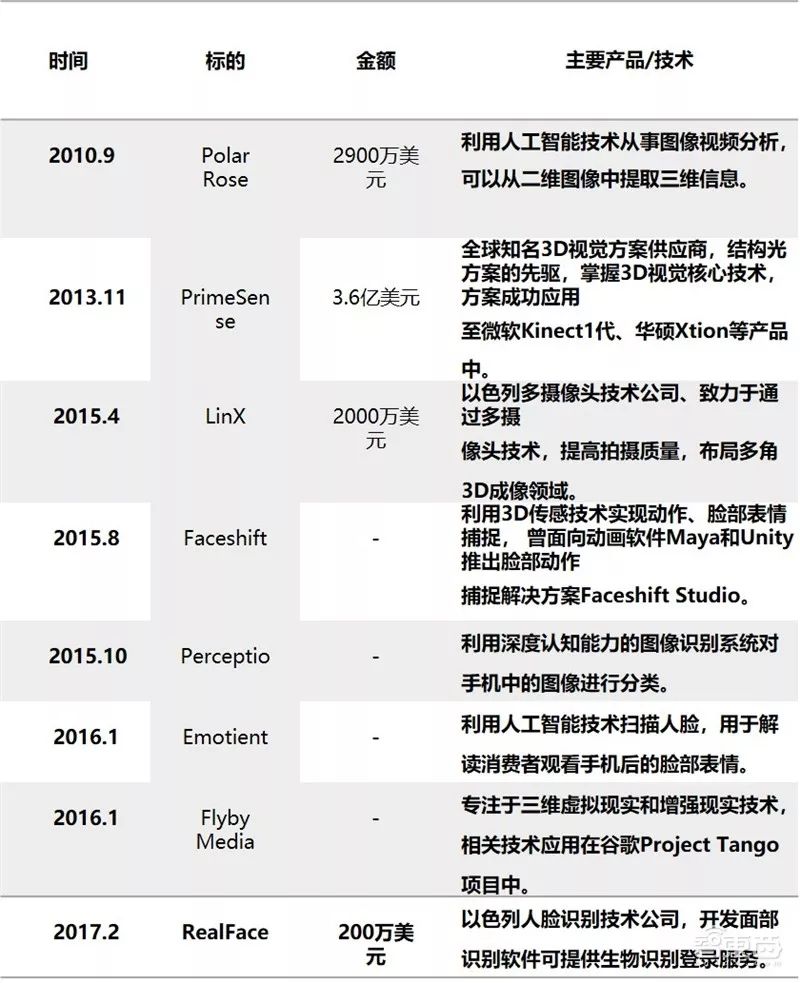 Apple’s Layout in the 3D Vision Field
Apple’s Layout in the 3D Vision Field
Apple’s incorporation of 3D facial recognition functionality into the iPhone X was not a spur-of-the-moment decision, as the company began laying the groundwork for 3D vision as early as 2010. Particularly in 2013, Apple acquired the Israeli 3D vision company PrimeSense for $345 million, marking one of the largest acquisitions in Apple’s history. Since then, Apple has also invested in a series of 3D vision technology and face recognition technology companies.
Additionally, Face ID can be used for Apple Pay and third-party applications. For example, Apple has upgraded the emoji function using Face ID, allowing users to create 3D expressions through their facial expressions, which can be expressed using animations. However, this feature is currently only available within Apple’s iMessage. This direct “face-scan” method provides users with a more authentic human-computer interaction experience.
3. Widespread Application of Deep Learning-Based Face Recognition Technology
Currently, mainstream face recognition technologies are mostly targeted at lightweight face image databases, and the future establishment of a nationwide unified face image database covering billions of images is not yet mature, necessitating focused research on deep learning-based face recognition technologies.
In simple terms, given that there are over 1.3 billion people in the country, it is foreseeable that a strong face recognition company will lead the establishment of a nationwide unified face image database in the near future, potentially storing tens of billions or even hundreds of billions of face images. At that point, there may be a large number of faces with similar representations and key feature points. Without deep learning-based face recognition technology and more complex and diverse face models, achieving accurate and rapid face recognition will be challenging.
4. Substantial Improvement of Face Image Databases
Establishing a face image database with excellent diversity and generality is also inevitable. Compared to the databases currently used by mainstream face recognition companies, the substantial improvements will mainly be reflected in the following aspects: first, the scale of face image databases will increase from the current hundreds of thousands to billions or even hundreds of billions in the future; second, the quality will improve, transitioning from mainstream 2D face images to 3D face images with more distinct and clear key feature points; third, the types of face images will enhance, capturing images of each person under various postures, expressions, lighting, and decorations to enrich each person’s facial representation for achieving accurate face recognition.
We believe that face recognition is a rapidly developing and widely applied area of AI technology, with a broad range of applications. At this year’s security expo, face recognition and dynamic capture technology have almost become standard for every exhibitor. With the research and development investments from national research institutions, the technical exploration by enterprises, and market promotion, face recognition will usher in a better wave of development. In the future, face recognition may become the mainstream method for effective identity recognition, at which point, face recognition will no longer be a novel term.
To obtain this report, please reply with“1103”.

