Source: DeepHub IMBA
This article is approximately 3100 words long and is recommended for a 6-minute read.
This article introduces the latest research and advancements in the field of computer vision, covering various topics including diffusion models, vision-language models, image editing and generation, video processing and generation, and image recognition.
Today, we summarize the most important papers published in May 2024, focusing on the latest research and advancements in the field of computer vision, including diffusion models, vision-language models, image editing and generation, video processing and generation, and image recognition.
Diffusion Models
1. Dual3D: Efficient and Consistent Text-to-3D Generation with Dual-mode Multi-view Latent Diffusion
Dual3D is a new text-to-3D generation framework that can generate high-quality 3D images from text in under one minute.
To overcome the high rendering costs during the inference process, Dual3D proposes a dual-mode switching inference strategy, using only 1/10 of the denoising steps in 3D mode, successfully generating 3D images in just 10 seconds without sacrificing quality.
Then, through an efficient texture refinement process, the texture of the 3D assets can be further enhanced in a short time. Extensive experiments show that the method presented in the paper provides state-of-the-art performance while significantly reducing generation time.
https://dual3d.github.io/
2. CAT3D: Create Anything in 3D with Multi-View Diffusion Models
Advancements in 3D reconstruction have made high-quality 3D capture possible, but they require users to collect hundreds to thousands of images to create 3D scenes.
CAT3D can create anything in 3D by simulating the real-world capture process through multi-view diffusion models. Given any number of input images and a set of target viewpoints, the model can generate highly consistent scenes.
These generated views can serve as input for powerful 3D reconstruction techniques to produce 3D representations that can be rendered in real-time from any viewpoint. CAT3D can create entire 3D scenes in just one minute and outperforms existing single-image and few-shot 3D scene creation methods.
3. Hunyuan-DiT: A Powerful Multi-Resolution Diffusion Transformer with Fine-Grained Chinese Understanding
Hunyuan-DiT is a text-to-image diffusion transformer with fine-grained understanding of both English and Chinese. It features a carefully designed transformer structure, text encoder, and positional encoding.
The paper also builds a complete data pipeline from scratch to update and evaluate data for iterative model optimization. For fine-grained language understanding, a multimodal large language model has been trained to improve the captions for images.
Finally, Hunyuan-DiT can engage in multi-turn multimodal dialogues with users, generating and refining images based on context. Compared to other open-source models, Hunyuan-DiT achieves new levels in Chinese-to-image generation through a comprehensive manual evaluation protocol with over 50 professional evaluators.
https://arxiv.org/abs/2405.08748
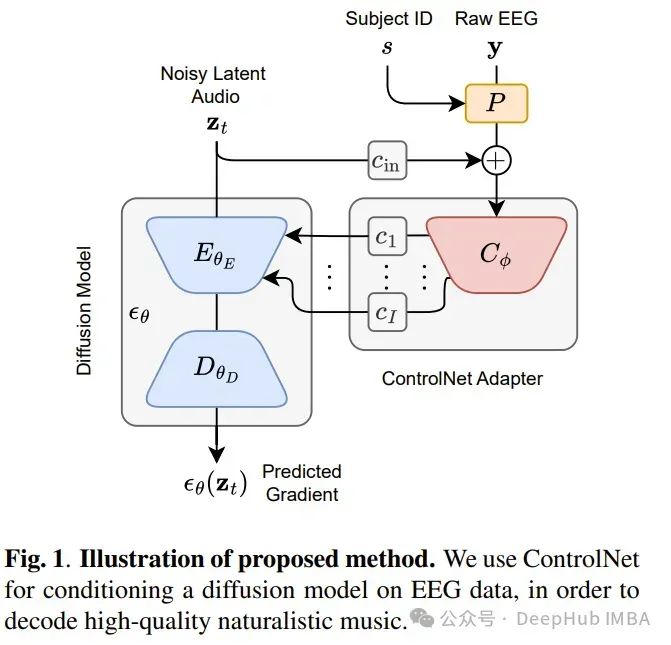
4. Naturalistic Music Decoding from EEG Data via Latent Diffusion Models
The paper addresses the task of reconstructing naturalistic music from EEG recordings, which sounds somewhat bizarre.
This research is the first attempt to achieve high-quality general music reconstruction using non-invasive EEG data, employing an end-to-end training approach directly on the raw data without manual preprocessing and channel selection.
Unlike simple music with limited timbre, such as melodies generated by MIDI or monophonic works, the focus here is on complex music with multiple instruments, vocals, and effects, rich harmonics, and timbres. The model is trained on the public NMED-T dataset and proposes a neural embedding-based metric for quantitative evaluation.
This work contributes to ongoing research in neural decoding and brain-machine interfaces, providing insights into the feasibility of reconstructing complex auditory information using EEG data.
https://arxiv.org/abs/2405.09062
Vision-Language Models (VLMs)
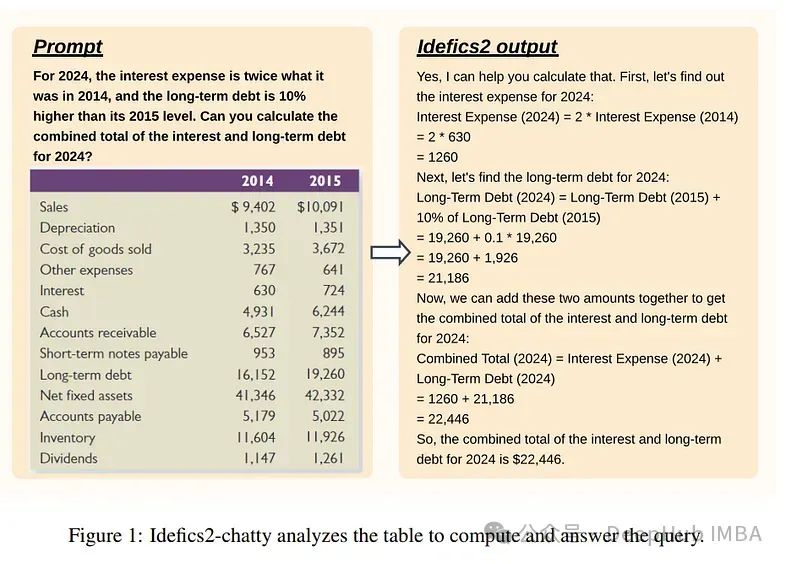
1. What Matters When Building Vision-Language Models?
The growing research on vision-language models (VLM) is driven by improvements in large language models and VIT. Despite the vast literature on this topic, the paper observes that key decisions regarding VLM design are often unreasonable.
These unsupported decisions hinder progress in the field, as it becomes difficult to determine which choices can enhance model performance. To address this issue, the paper conducts extensive experiments surrounding pre-training models, architecture selection, data, and training methods.
The research results include the development of Idefics2, an efficient foundational VLM with 8 billion parameters. Idefics2 achieves state-of-the-art performance in its size category across various multimodal benchmarks and generally matches models four times its size.
https://arxiv.org/abs/2405.02246
2. Xmodel-VLM: A Simple Baseline for Multimodal Vision Language Model
Xmodel-VLM is a cutting-edge multimodal vision-language model. It is designed for efficient deployment on consumer-grade GPU servers.
Through rigorous training, a 1B-level language model is developed from scratch, using the LLaVA paradigm for modality alignment, resulting in a lightweight yet powerful multimodal vision-language model.
Extensive testing conducted on many classic multimodal benchmarks shows that although Xmodel-VLM is smaller and faster, its performance is comparable to larger models.
https://arxiv.org/abs/2405.09215
Image Generation and Editing
1. Compositional Text-to-Image Generation with Dense Blob Representations
Existing text-to-image models struggle to follow complex text prompts, necessitating additional grounded inputs for better controllability. The paper proposes decomposing scenes into visual primitives: represented as dense blob representations—containing fine-grained details of the scene while being modular, human-interpretable, and easy to construct.
Based on blob representations, a blob-based text-to-image diffusion model called BlobGEN is developed for synthesis generation, introducing a new masked cross-attention module to address the fusion issue between blob representations and visual features.
To leverage the compositionality of large language models (LLMs), a new context learning method is introduced to generate blob representations from text prompts.
Extensive experiments show that BlobGEN achieves superior zero-shot generation quality and better layout-guided controllability on MS-COCO. When enhanced by LLMs, our method demonstrates superior numerical and spatial correctness on synthesis image generation benchmarks.
https://blobgen-2d.github.io/
Object Detection
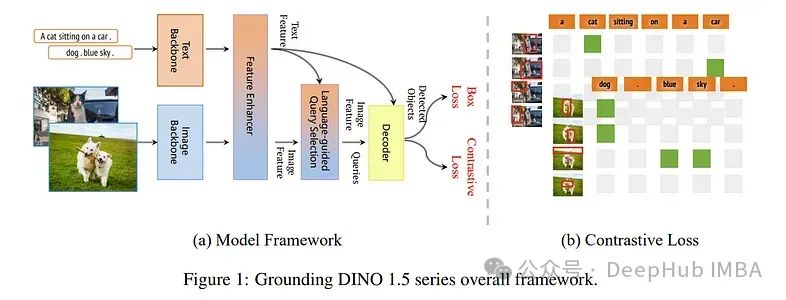
1. Grounding DINO 1.5: Advance the “Edge” of Open-Set Object Detection
The paper introduces a set of advanced open-set object detection models developed by IDEA Research—Grounding DINO 1.5, aimed at advancing the “edge” of open-set object detection.
This suite includes two models: Grounding DINO 1.5 Pro, a high-performance model with stronger generalization capabilities across a wide range of scenarios; and Grounding DINO 1.5 Edge, an efficient model optimized for faster speeds required for many edge deployment applications.
The Grounding DINO 1.5 Pro model improves upon its predecessor by expanding the model architecture, integrating enhanced visual backbones, and extending the training dataset to over 20 million annotated images, achieving richer semantic understanding.
Although the Grounding DINO 1.5 Edge model is designed for efficiency in reducing feature scale, it maintains strong detection capabilities by training on the same comprehensive dataset.
Experimental results demonstrate the effectiveness of DINO 1.5, with the DINO 1.5 Pro model achieving 54.3 AP on the COCO detection benchmark and 55.7 AP on the LVIS-minival zero-shot benchmark, setting new records in object detection.
The Grounding DINO 1.5 Edge model, after optimization using TensorRT, achieved a speed of 75.2 FPS on the LVIS-minival benchmark while achieving 36.2 AP in zero-shot performance, making it more suitable for edge computing scenarios.
Editor: Wang Jing