
Today is January 22, 2025, Wednesday, Beijing, sunny.
Today is the Little New Year in the North, and the Spring Festival is approaching.
This article continues to explore the progress of GraphRAG, specifically looking at the RAG scheme that directly uses KG, which is KG-RAG, provided that the KG is established.
Some ideas are worth reading.
Specialization and systematization will lead to deeper thinking. Let’s all work hard together.
1. Starting from the Tasks and Existing Solutions of KG-RAG
KG-RAG retrieves the k most relevant inference paths related to the query, providing concise and accurate contextual information for LLMs reasoning. Let’s first review the execution phase of KG-RAG, which involves two main stages: retrieval and generation.
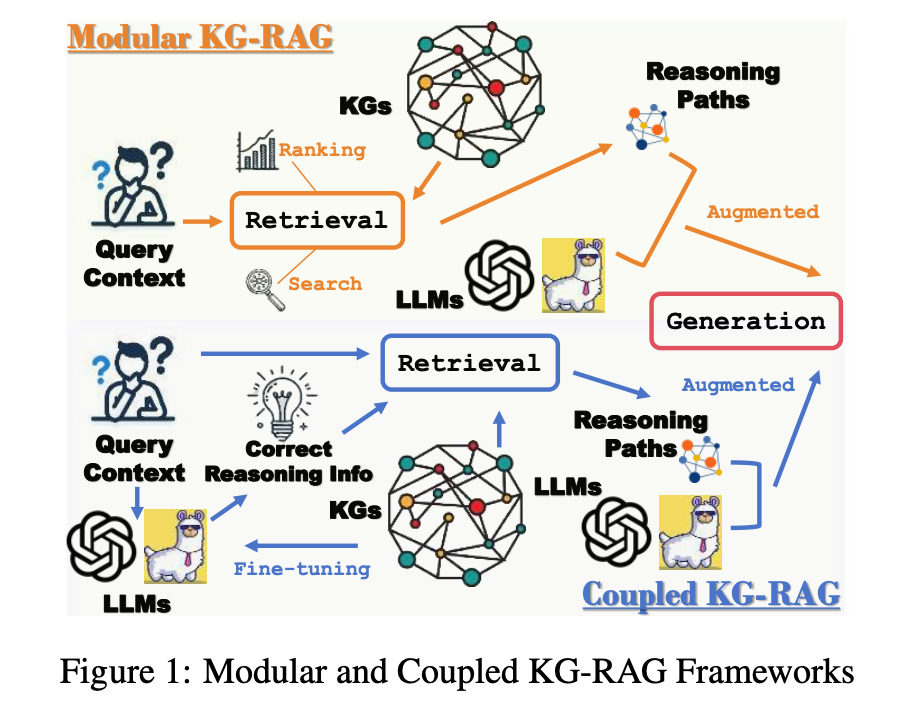
In the retrieval phase, given a query q, the first stage constructs a set of candidate “inference paths” by matching q with entities and relationships in the knowledge graph, accomplished by searching for relevant triples (s, r, e) from the knowledge graph (G), retrieving (q, G) → {P}, and then ranking the retrieved inference path set {P} based on their relevance to q.
The inference path Pi can be formally defined as: Pi=(s,r1,m1,r2,…,rk−1,mk−1,rl,e), where s is the starting entity, e is the answer entity, mj is the intermediate entity, and rj is the relationship connecting these entities. The number of hops in the path, equal to the number of relationships, determines the length l of the path. For a given query q, the correct inference path includes the correct answer entity corresponding to q.
In the inference phase, the top k paths enhance the query, forming a rich query q′. This q′ is then input into a large language model (LLM) to generate the final output: Generate(q′, LLM) → output.
Next, let’s look at what specific solutions currently exist.
The KG-RAG framework is classified as modular or coupled based on whether the knowledge graph (KG) information is fine-tuned into large models (LLMs).
For example, modular approaches, such as ToG, improve retrieval accuracy by replacing traditional ranking models with LLMs. However, due to the lack of prior KG knowledge and the frequent demand for LLMs, ToG is challenging to implement;
Another example is the coupled framework, RoG, which fine-tunes LLMs with KG information, enabling them to generate “relationship paths” as query templates and directly retrieve the correct inference paths from KGs. There are also GNN-RAGs that utilize Graph Neural Networks (GNN) to extract useful inference paths.
2. Introducing the Classification Concept in the FFRAG-KGRAG Scheme
A recent work titled “FRAGRAG: A Flexible Modular Framework for Retrieval-Augmented Generation based on Knowledge Graphs” (https://arxiv.org/pdf/2501.09957) has the core idea of dynamically adjusting the retrieval process to adapt to the complexity of the query, employing the classification approach. Although the code is not open source, it’s worth exploring some ideas.
The core includes two main points: inference awareness and retrieval.
1. Inference Awareness
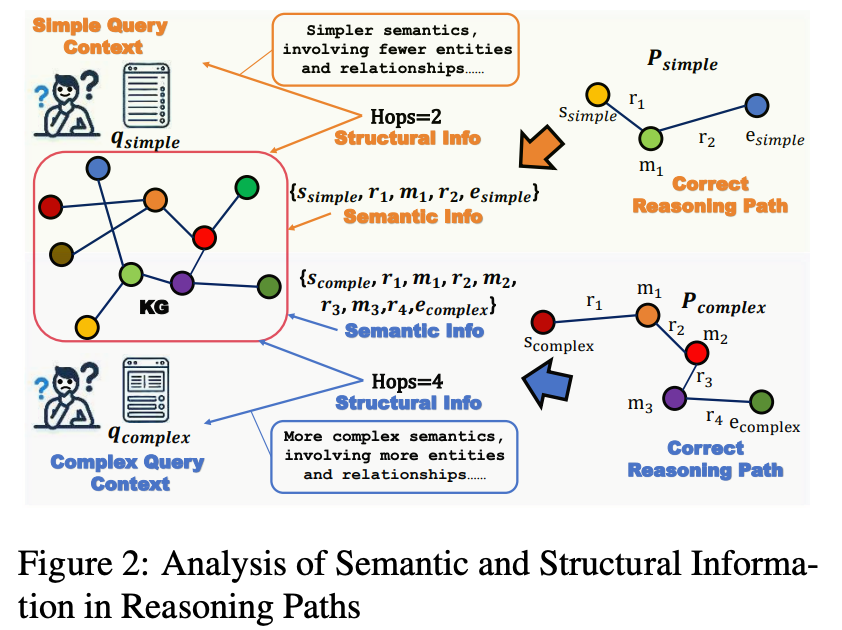
Inference awareness classifies reasoning tasks as simple or complex based on the complexity of the query. The number of hops in the correct inference path is closely related to specific statistics in the query, such as the number of entities, the number of relationships, and the number of clauses. Therefore, by predicting the range of hops in the inference path, a binary classifier can classify the query.
An inference path P contains two types of information: semantic (i.e., entities and relationships) and structural (i.e., number of hops). Semantic information primarily comes from the knowledge graph, which is difficult to perceive and utilize in advance, while structural information is associated with both the knowledge graph and q. The more complex the query context q, the more hops in path P (indicating a more challenging reasoning task).
Thus, within a tolerable margin of error, we can predict the number of hops in path P based solely on the query context q. The predicted number of hops can be a key factor for enhancing non-specific retrieval processes. For example, setting the hop threshold to 2, if the minimum number of hops in the inference path is less than or equal to 2, the task is classified as simple; otherwise, it is classified as complex.
Let’s look at the specific details:
Using a set of common knowledge graph question-answering datasets (such as Freebase and Wiki-Movies) to train a binary classifier, each dataset includes a foundational knowledge graph and a large number of paired queries Q and their corresponding answers A.
Before training, for each query q∈Q, identify all shortest inference paths from the query entity Entq to the answer entity Enta∈A. The minimum number of hops H among all inference paths for that query determines the query label Y: Y=1 (complex) if H≥δ; Y=0 (simple) if H<δ, with the threshold δ set to 2.
However, when modeling, encoding is needed:
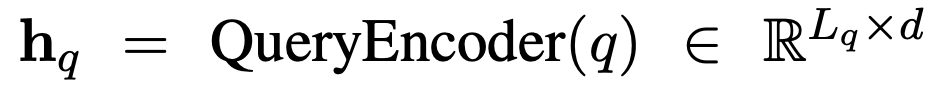
Here, the query encoder can be any encoding mechanism, such as the language model BERT, word embeddings Word2Vec, or TF-IDF. Thus, during training, the classification loss for the binary classifier is:
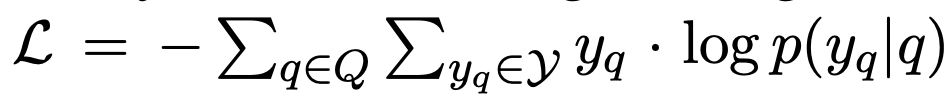
Here, p(yq∣q)=decoder(hq) represents the probability of q being classified as simple or complex.
2. Retrieval Generation
The retrieval generation module aims to accurately identify inference paths related to the query, refining the KG-RAG retrieval process into a “preprocessing-retrieval-postprocessing” pipeline, and finally handing it over to the LLM for result generation.
First is the preprocessing phase, where subgraphs containing important entities and relationships are extracted from the original KG, aiming to narrow the retrieval scope and improve retrieval efficiency.
Common approaches are used here, such as removing less relevant entities and edges based on importance assessment. For instance, in entity-based subgraph pruning, a generalized ranking mechanism (GRM) is employed, such as random walk with restart (RWR), personalized PageRank (PPR), and PageRank fine-tuning (PRN), followed by selecting the top n entities. In edge-based subgraph pruning, an edge ranking model (ERM) is applied as a retriever (e.g., BM25, SentenceTransformer) to compute their semantic similarity with the query q.
Then comes the retrieval phase, where different retrieval strategies are employed based on the complexity of the query.
For simple reasoning tasks, involving shorter inference paths for simple queries, using broader retrieval methods is crucial to minimize information loss. Thus, the breadth-first search (BFS) algorithm is employed, allowing efficient traversal of all inference paths between the query entity and the entity set.
For complex reasoning tasks, where complex queries have longer inference paths, increasing retrieval paths not only exponentially increases computational costs but also introduces a lot of redundant information. Therefore, the shortest path retrieval algorithm (such as Dijkstra’s algorithm) is used to minimize computational overhead and reduce noise.
Finally, the postprocessing phase focuses primarily on finding paths from the query entity to potential answer entities, ignoring the semantics of intermediate entities and their relevance to the query. This may lead to the collection of inference paths being unordered and redundant, which presents several obvious issues: paths containing irrelevant or rare intermediate entities may mislead the reasoning of large language models (LLMs); paths increase the length of prompts, which not only raises reasoning costs but also risks exceeding contextual length limits; the performance can be affected by the position of these paths in the prompt, with paths at the beginning having a more significant impact.
Thus, using a path ranking model (such as DPR, ColBERT, etc.) filters redundant inference paths, ensuring that the inference paths input to LLMs are the most relevant and beneficial.
Finally, design a prompt template that enhances the question q using the filtered inference paths P.

Conclusion
This article mainly introduces a progress work on KGRAG, focusing on optimizing the path pruning approach, dividing and conquering. Each process is actually commonly used in previous schemes.
References
1. https://arxiv.org/pdf/2501.09957
About Us
Old Liu, an NLP open-source enthusiast and practitioner, homepage: https://liuhuanyong.github.io.
If you’re interested in large models, knowledge graphs, RAG, document understanding, and wish to join our community for daily newsletters, online sharing about the history of NLP, and exchange of insights, you are welcome to join the community, which is continuously recruiting.
To join, follow the official account, click on the membership community in the backend menu -> join the group.