


Click the blue text above to follow us
1. Introduction
1. Introduction
In the wave of artificial intelligence, Retrieval-Augmented Generation (RAG) technology has become a hot topic in research and application due to its unique advantages. RAG technology combines the powerful generative capabilities of large language models (LLMs) with efficient information retrieval systems, providing users with a new interactive experience. However, with the deepening application of technology, a series of challenges have gradually emerged.
First, existing RAG systems face dual pressures of efficiency and accuracy when handling massive amounts of data. Although LLMs can generate fluent text, they often struggle to accurately grasp and recall key information when dealing with complex, unstructured data. Additionally, RAG systems have limitations in data management and understanding, leading to the so-called “garbage in, garbage out” (GIGOut) problem, meaning that if the input data quality is low, the generated answers are also unlikely to meet expected accuracy.
It is against this backdrop that RAGFlow was born. As an end-to-end RAG solution, RAGFlow aims to address the challenges of existing RAG technology in data processing and answer generation through deep document understanding technology. It not only handles various document formats but also intelligently identifies the structure and content within documents to ensure high-quality data input. RAGFlow’s design philosophy is “quality in, quality out,” providing interpretable and controllable generation results that enable users to trust and rely on the answers provided by the system.
On April 1, 2024, RAGFlow announced its official open-source release, which caused a sensation in the tech community. On the day of the open source, RAGFlow quickly gained thousands of followers on GitHub, and within a week, it had attracted 2900 stars, reflecting the community’s high recognition of RAGFlow and the enthusiasm for this new technology.
With the open-sourcing of RAGFlow, it not only brings new vitality to the tech community but also provides new ideas and tools for solving the difficulties faced by RAG technology. The emergence of RAGFlow marks a solid step forward in building smarter, more efficient, and reliable RAG systems.
2. Core Features of RAGFlow
-
Deep Document Understanding: “Quality in, quality out,” RAGFlow is based on deep document understanding, capable of extracting insights from various complex formats of unstructured data. It quickly completes needle-in-a-haystack testing in an infinite context (token) scenario. For user-uploaded documents, it automatically recognizes the layout of the document, including titles, paragraphs, line breaks, and also handles complex elements like images and tables. For tables, it not only identifies the existence of tables in the document but also further recognizes the layout of the table, including each cell, whether multi-line text needs to be merged into one cell, etc. Additionally, the content of the table will be processed in conjunction with the header information to ensure it is delivered to the database in an appropriate format, thus completing RAG’s “needle-in-a-haystack” for these detailed numbers.
-
Controllable and Interpretable Text Slicing: RAGFlow provides various text templates, allowing users to choose the appropriate template based on their needs, ensuring the controllability and interpretability of the results. Thus, RAGFlow provides many options when processing documents: Q&A, Resume, Paper, Manual, Table, Book, Law, General…. Of course, these categories are continuously expanding, and the processing process is still being improved. More common elements will be abstracted out in the future to make various customized processing easier.
-
Reducing Hallucination: RAGFlow is a complete RAG system, while most currently open-source RAGs overlook one of RAG’s biggest advantages: allowing LLMs to answer questions in a controllable manner, or in other words: providing reasoning and eliminating hallucination. We all know that with varying model capabilities, LLMs are bound to occasionally hallucinate. In such cases, a RAG product should always provide references for users, allowing them to see which original texts the LLM generated answers from. This requires generating citation links for the original texts simultaneously and allowing users to hover their mouse over them to display the original content, including charts. If they still cannot be sure, they can click to locate the original text. The text slicing process of RAGFlow is visualized, supporting manual adjustments, and the answers provide key citations snapshots and support traceability, thereby reducing the risk of hallucination.
-
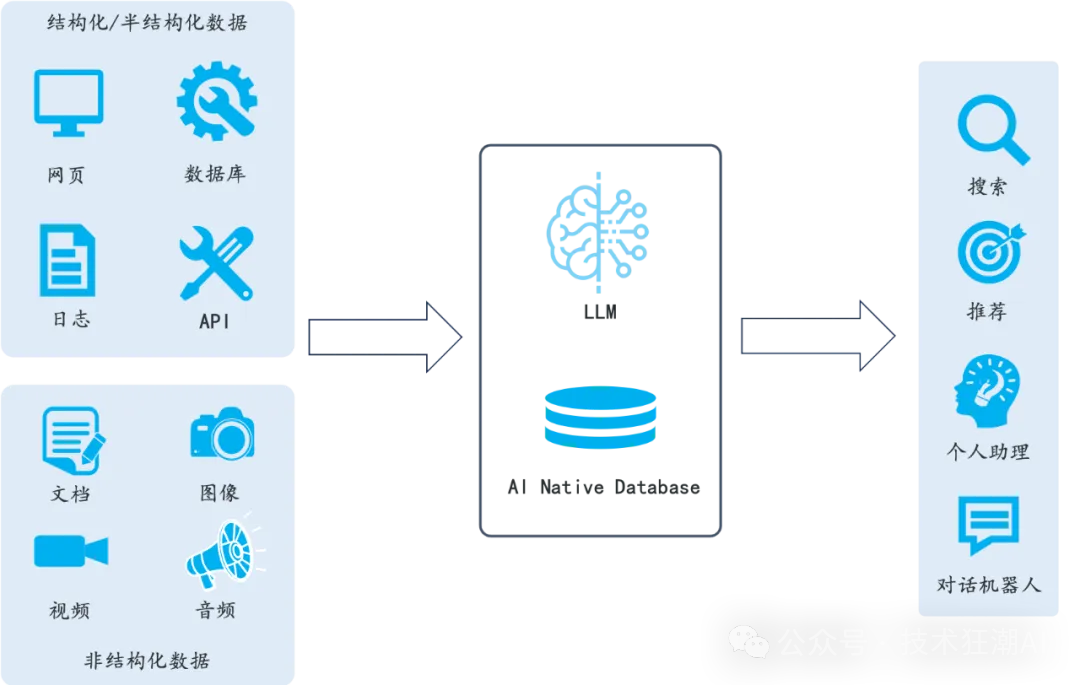
Compatibility with Various Heterogeneous Data Sources: RAGFlow supports a rich variety of file types, including Word documents, PPT, Excel spreadsheets, txt files, images, PDFs, photocopies, structured data, web pages, etc. For unordered text data, RAGFlow can automatically extract key information and convert it into structured representations; for structured data, it can flexibly delve into and explore the inherent semantic relationships. Ultimately, it unifies indexing and retrieval of these two different sources of data, providing users with a one-stop data processing and Q&A experience.
-
Automated RAG Workflow: RAGFlow supports a fully optimized RAG workflow that can support various ecosystems from personal applications to large enterprises; both large language models (LLMs) and vector models are configurable, allowing users to choose based on actual needs; based on multi-route recall and fusion reordering, it can weigh both contextual semantics and keyword matching dimensions to achieve efficient relevance calculation; it provides easy-to-use APIs for seamless integration into various enterprise systems, greatly facilitating secondary development and system integration work for both individual users and enterprise developers.
3. Technical Architecture
3.1. RAGFlow System Architecture

3.1. RAGFlow System Architecture
RAGFlow system is an efficient and intelligent information processing platform that achieves rapid response and precise handling of complex queries through a series of meticulously designed components. The core components of this system include:
-
Document Parser: This is the “brain” of the RAGFlow system, responsible for parsing various formats of documents to extract key content such as text, images, and tables. Whether it’s a PDF, Word document, or Excel spreadsheet, the document parser can accurately capture information, laying the groundwork for subsequent processing.
-
Query Analyzer: This component is the “nervous system” of the RAGFlow system, deeply analyzing user queries to identify and extract key information. Through this analysis, the system can better understand user needs and provide precise guidance for retrieval work.
-
Retrieval: This is the “search engine” of the RAGFlow system, using the key information provided by the query analyzer to quickly retrieve relevant information from a vast array of documents. The powerful capabilities of the retrieval component ensure that users can obtain the data they need in a timely manner.
-
Reordering: This component acts as the “filter” of the RAGFlow system, sorting and filtering the retrieved information to ensure that the information presented to users is the most relevant and valuable. In this way, the system can eliminate redundant and irrelevant data, improving the accuracy and usability of the information.
-
LLM: As the “language generator” of the RAGFlow system, the LLM (large language model) is responsible for integrating the sorted information and generating the final answers or outputs. The powerful generative capabilities of the LLM not only ensure the accuracy of the answers but also allow them to be expressed more naturally and fluently.
These components together constitute the powerful architecture of the RAGFlow system, enabling it to efficiently handle user queries, quickly retrieve information from documents, and generate accurate and useful answers. This system not only improves the efficiency of information processing but also greatly enhances the user experience.
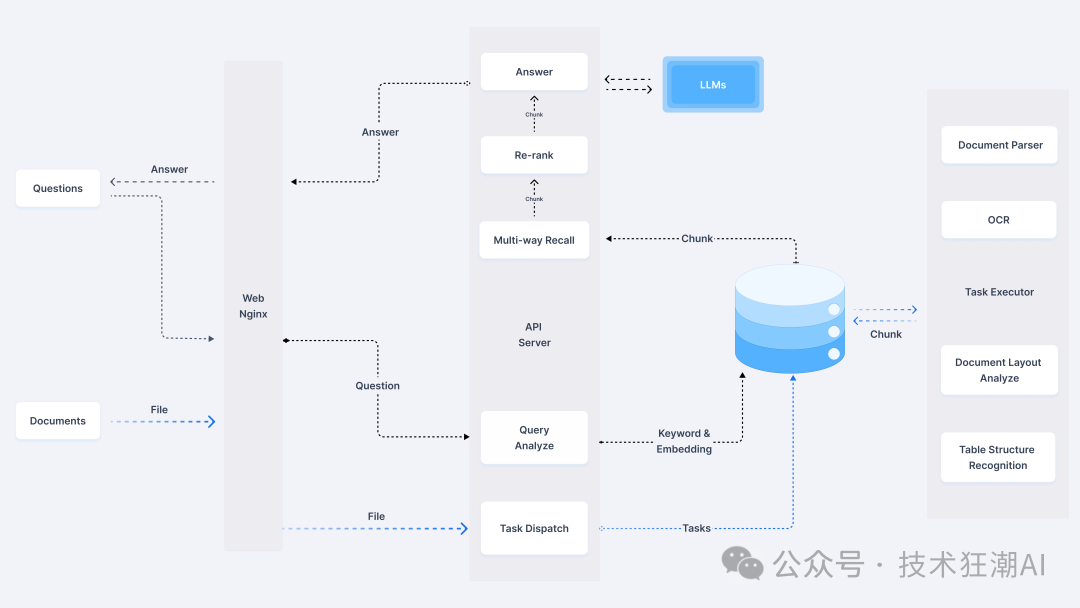
The architecture of the RAG system is a precise and efficient workflow that ensures accurate processing of user queries and high-quality answer generation through a series of meticulously designed components. The workflow of this system can be summarized in the following steps:
-
First, when a user inputs a query, the query analyzer begins its work. It deeply analyzes the user’s query, extracting key information that serves as the foundation for subsequent retrieval work.
-
Next, the retrieval module searches for relevant data in a vast array of document resources based on the key information provided by the query analyzer. This step is crucial in the entire system as it directly determines the relevance and accuracy of the subsequent answers.
-
Then, the reordering module further sorts and filters the retrieved information. This step ensures that the information ultimately presented to users is optimized, eliminating irrelevant or redundant content, making the answers more precise and valuable.
-
Finally, the LLM (large language model) generates the final answer or output based on the information provided by the reordering module. The powerful generative capabilities of the LLM ensure that the answers are not only accurate but also expressed fluently and naturally, like a knowledgeable assistant answering the user’s questions.
Through this workflow, the RAG system architecture can efficiently process user queries, extract valuable information from documents, and generate accurate and useful answers. This system not only improves the efficiency of information retrieval but also greatly enhances the user experience.
3.2. DeepDoc: The Cornerstone of Deep Document Understanding

3.2. DeepDoc: The Cornerstone of Deep Document Understanding
DeepDoc is the core component of RAGFlow, leveraging visual information and parsing technology to deeply understand documents and extract information such as text, tables, and images. The functional modules of DeepDoc include:
-
OCR Technology: Supports multiple languages and fonts, and can handle complex document layouts and image quality.
-
Layout Recognition (Layout Analysis Recognition) Technology: RAGFlow uses Yolov8 for OCR/layout recognition/TSR (Table Structure Recognition), recognizing the layout structure of documents, such as titles, paragraphs, tables, images, etc.
-
Table Structure Recognition (TSR): Recognizes the structure of tables, such as rows, columns, headers, cell merging, etc., and converts it into natural language sentences.
-
Document Parsing: Supports parsing various document formats such as PDF, DOCX, EXCEL, and PPT, extracting text blocks, tables, and images.
-
Resume Parsing: Parses unstructured text in resumes into structured data, such as name, contact information, work experience, education background, etc.
3.3. The Role of LLM and Embedding Models in RAGFlow

3.3. The Role of LLM and Embedding Models in RAGFlow
In RAGFlow, LLM (Large Language Models) and embedding models play a crucial role, working together to achieve efficient information retrieval and generation tasks.
LLM is one of the core components in RAGFlow, responsible for understanding and generating natural language. The main roles of LLM in RAGFlow include:
-
Understanding User Queries: LLM can understand users’ natural language queries and convert them into executable instructions or questions.
-
Generating Answers: Based on user queries and retrieved information, LLM can generate fluent, coherent, and highly relevant answers.
-
Providing Controllability: LLM can generate answers in specific styles or formats based on user instructions, ensuring the controllability and accuracy of the generated content.
-
Cross-Language Capability: For RAG tasks in multilingual environments, LLM needs to have cross-language understanding and generation capabilities to effectively retrieve and transform information between different languages.
Embedding models in RAGFlow are primarily used to convert text data into vector representations, which are crucial for information retrieval and similarity comparison. The main roles of embedding models include:
-
Text Vectorization: Embedding models convert text (such as documents, paragraphs, sentences, etc.) into numerical vectors that can represent the semantic information of the text.
-
Similarity Comparison: By calculating the similarity between vectors, embedding models can help RAGFlow quickly find the information most relevant to user queries.
-
Data Retrieval: Embedding models enable RAGFlow to efficiently perform retrieval tasks on large-scale datasets, especially when dealing with unstructured data such as documents and images.
-
Multimodal Capability: For documents containing non-text elements such as charts and images, embedding models can assist in extracting and understanding the semantic information of these elements, enhancing RAGFlow’s multimodal processing capabilities.
The combined use of LLM and embedding models in RAGFlow enables the system to not only understand complex natural language queries but also quickly and accurately retrieve relevant information from massive data and generate high-quality answers. This collaborative working mechanism greatly enhances RAGFlow’s application potential and efficiency in scenarios such as knowledge base Q&A, enterprise data integration, and multimodal information processing.
3.4. Visualization and Manual Intervention in the Text Slicing Process

3.4. Visualization and Manual Intervention in the Text Slicing Process
RAGFlow emphasizes the visualization and interpretability of intelligent document processing when handling documents. This means that users can not only obtain the results processed by the system but also clearly see how the document has been sliced and parsed. This design allows users to verify and intervene in the AI’s processing results, ensuring the accuracy and reliability of the final output.
In the text slicing process, RAGFlow first performs structural recognition on the user-uploaded document, including but not limited to titles, paragraphs, line breaks, etc. For more complex elements such as images and tables, RAGFlow will also conduct detailed layout recognition and structural analysis. For example, when processing tables, the system not only recognizes the existence of tables but also further identifies each cell within the table and whether multi-line text needs to be merged into one cell. This information will be reasonably processed and combined with the header information to ensure data correctness and completeness.
RAGFlow’s visualization feature allows users to view the specific results of document parsing. Users can see how many pieces the document has been split into and how various charts are processed. If the system’s recognition results deviate from the user’s expectations, users can make appropriate interventions. This intervention may include adjusting the slicing method, merging or splitting certain parts, and modifying the recognition results of tables. RAGFlow provides an intuitive user interface that makes it easy for users to perform these operations.
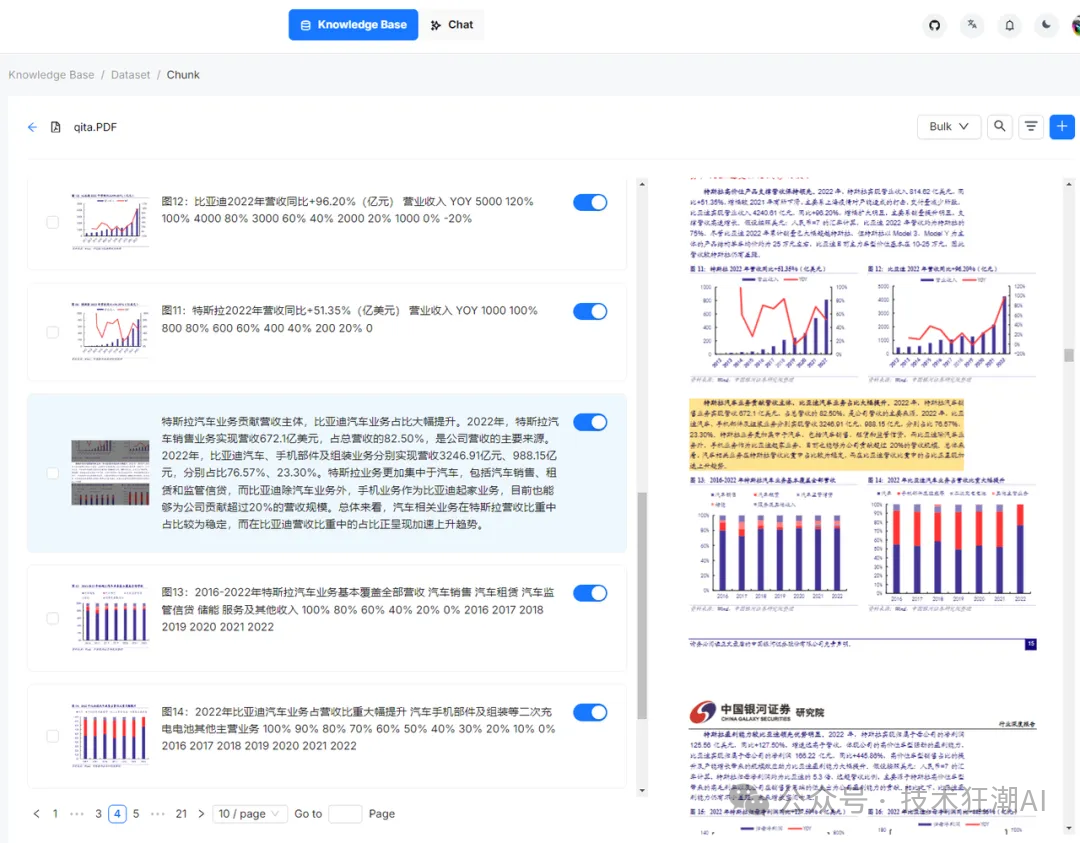
Additionally, RAGFlow provides a mechanism that allows users to click to locate the original text, comparing the differences between the processing results and the original text. This comparison feature not only helps users confirm whether the AI’s processing is accurate but also gives users more understanding and control over the processing. This design of visualization and interpretability greatly enhances user trust in AI processing results, making RAGFlow a more powerful and flexible tool.
4. Setting Up and Running RAGFlow
RAGFlow is an open-source RAG (Retrieval-Augmented Generation) engine based on deep document understanding, aiming to provide enterprises with a simplified RAG workflow. Below is a detailed guide for setting up and running RAGFlow:
4.1. System Requirements

Before starting the installation of RAGFlow, please ensure your system meets the following basic requirements:
-
CPU Cores: At least 2 cores
-
Memory Size: At least 8 GB
4.2. Install Docker

4.2. Install Docker
RAGFlow requires Docker to run. If your local machine (Windows, Mac, or Linux) does not have Docker installed, please visit the Docker official website for installation.
4.3. Start RAGFlow Server

-
Adjust System Settings: Ensure that <span>vm.</span><span>max_map_count</span> is set to a value greater than or equal to 262144. You can check and set this value by running the following commands:
# To check the value of vm.max_map_count:
sysctl vm.max_map_count
# If not, reset vm.max_map_count to at least 262144.
sudo sysctl -w vm.max_map_count=262144
To make the change permanent, add or update vm.max_map_count=262144 in the /etc/sysctl.conf file.
-
Clone the RAGFlow Repository:
git clone https://github.com/infiniflow/ragflow.git
-
Build Docker Image and Start Server:
cd ragflow/docker
docker compose up -d
The core image size is approximately 9 GB, and loading may take some time.
-
Check Server Status:
docker logs -f ragflow-server
If the system starts successfully, you will see a confirmation message.
____ ______ __
/ __ \ ____ _ ____ _ / ____// /____ _ __
/ /_/ // __ `// __ `// /_ / // __ \| | /| / /
/ _, _// /_/ // /_/ // __/ / // /_/ /| |/ |/ /
/_/ |_| \__,_/ \__, //_/ /_/ \____/ |__/|__/
/____/
* Running on all addresses (0.0.0.0)
* Running on http://127.0.0.1:9380
* Running on http://172.22.0.5:9380
INFO:werkzeug:Press CTRL+C to quit
4.4. Configuration Options

-
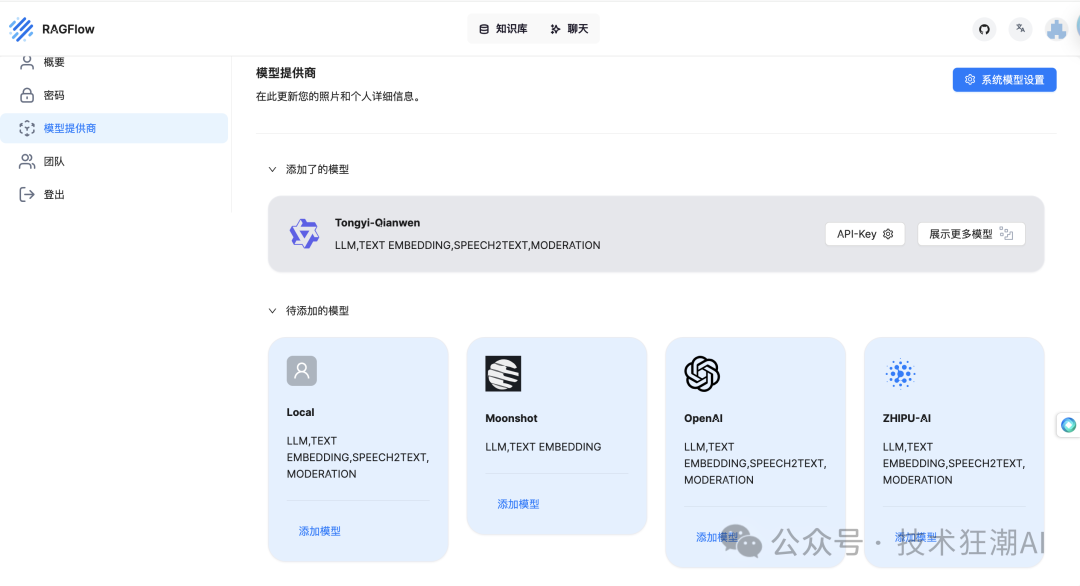
Select LLM Factory: In the <span>service_conf.yaml</span> file, choose the desired LLM factory in the <span>user_default_llm</span> section.
-
API Key Settings: Update the <span>API_KEY</span> field in the <span>service_conf.yaml</span> file with the corresponding API key. For more information, refer to <span>/docs/llm_api_key_setup.md</span>.
-
To update the default HTTP server port (80), go to docker-compose.yml and change <span>80:80</span> to <span><YOUR_SERVING_PORT>:80</span>.
All system configuration updates require a system restart to take effect:<span>docker-compose up -d</span>
4.5. Accessing the RAGFlow Interface

4.3. Start RAGFlow Server
<span>vm.</span><span>max_map_count</span> is set to a value greater than or equal to 262144. You can check and set this value by running the following commands:# To check the value of vm.max_map_count:
sysctl vm.max_map_count
# If not, reset vm.max_map_count to at least 262144.
sudo sysctl -w vm.max_map_count=262144vm.max_map_count=262144 in the /etc/sysctl.conf file.git clone https://github.com/infiniflow/ragflow.gitcd ragflow/docker
docker compose up -dThe core image size is approximately 9 GB, and loading may take some time.docker logs -f ragflow-serverIf the system starts successfully, you will see a confirmation message. ____ ______ __
/ __ \ ____ _ ____ _ / ____// /____ _ __
/ /_/ // __ `// __ `// /_ / // __ \| | /| / /
/ _, _// /_/ // /_/ // __/ / // /_/ /| |/ |/ /
/_/ |_| \__,_/ \__, //_/ /_/ \____/ |__/|__/
/____/
* Running on all addresses (0.0.0.0)
* Running on http://127.0.0.1:9380
* Running on http://172.22.0.5:9380
INFO:werkzeug:Press CTRL+C to quit4.4. Configuration Options
Select LLM Factory: In the <span>service_conf.yaml</span> file, choose the desired LLM factory in the <span>user_default_llm</span> section.
API Key Settings: Update the <span>API_KEY</span> field in the <span>service_conf.yaml</span> file with the corresponding API key. For more information, refer to <span>/docs/llm_api_key_setup.md</span>.
To update the default HTTP server port (80), go to docker-compose.yml and change <span>80:80</span> to <span><YOUR_SERVING_PORT>:80</span>.
All system configuration updates require a system restart to take effect:<span>docker-compose up -d</span>
4.5. Accessing the RAGFlow Interface
Once the server is up and running, you can access the RAGFlow interface through your browser. Under the default configuration, you can omit the default HTTP server port 80. Just enter the IP address of the RAGFlow server in your browser.
By following the steps above, you can successfully set up and run RAGFlow. Ensure to follow all configuration guidelines, and check the server status after starting it to confirm everything is working properly. By selecting the appropriate LLM factory and setting the API key, you can ensure that RAGFlow seamlessly integrates with your business needs. Finally, through simple browser operations, you can start using RAGFlow’s powerful document understanding and Q&A capabilities.
5. Future Plans for RAGFlow
As an advanced retrieval-augmented generation engine, RAGFlow’s future development plans mainly focus on the following core directions:
-
Enhancing Multilingual Support Capabilities:
-
RAGFlow will strive to improve its support for different languages to better serve the global market. This means that RAGFlow will develop and integrate more document structure recognition models for various languages, allowing it to accurately understand and process unstructured data in various languages. This will include not only common languages like English and Chinese but will also expand to other languages to meet the needs of users in different regions.
-
Improving Local Large Language Model (LLM) Performance:
-
To enhance RAGFlow’s accuracy and efficiency in processing unstructured data, future optimizations and upgrades will be made to local large language models. This may include improving the training data of the models, adjusting model structures, and adopting new algorithms and techniques to enhance the understanding and generation capabilities of the models. Through these improvements, RAGFlow will be able to understand and generate complex language content more accurately, providing users with richer and more precise information.
-
Expanding Web Crawling Functionality:
-
RAGFlow plans to expand its web crawling capabilities to gather data from a broader range of sources. This includes connecting to various enterprise data sources, such as MySQL’s binlog, data lake’s ETL, and external crawlers. By integrating these data sources, RAGFlow will be able to collect and analyze information more comprehensively, providing users with a more complete knowledge base and more accurate retrieval results.
-
Adapting to More Complex Scenarios:
-
One of RAGFlow’s design goals is to adapt to more complex scenarios, especially enterprise-level (B-end) application scenarios. To this end, RAGFlow will develop more customized templates and processing workflows to meet the specific needs of different industries and roles regarding document processing and information retrieval. This may involve understanding specific industry terminology and handling complex document structures.
-
Providing More Flexible Enterprise Data Access:
-
RAGFlow will launch a low-code platform for enterprise-level data access, making it easier for enterprises to integrate internal data and documents into the RAGFlow system. This will greatly enhance the convenience and efficiency of enterprises using RAGFlow, while also providing more flexibility and autonomy.
-
Advanced Content Generation:
-
In addition to Q&A dialogues, RAGFlow will also offer advanced content generation features, such as long-form content generation. This will enable RAGFlow to not only answer user questions but also create articles, reports, and other content, providing users with more comprehensive services.
Through these future plans, RAGFlow aims to become a more powerful, flexible, and user-friendly system that can meet the needs of different users in various scenarios, especially playing an important role in enterprise-level applications.
6. Summary
In exploring RAGFlow, we can clearly see its important position and significant advantages in the field of RAG (Retrieval-Augmented Generation). As a next-generation open-source RAG engine, RAGFlow not only excels in Q&A dialogues but also possesses advanced content generation capabilities, such as long-form content generation. This enables RAGFlow to provide users with more comprehensive and in-depth services, meeting the needs of different scenarios, especially playing an important role in enterprise-level applications.
The core functions and technical architecture of RAGFlow, including its system architecture, DeepDoc deep document understanding module, the application of LLM and embedding models, and the visualization and manual intervention in the text slicing process, together constitute a powerful, flexible, and easy-to-use system. These features not only enhance the user experience but also provide developers with more room for innovation.
Open-source projects like RAGFlow play a crucial role in driving technological innovation. They promote knowledge sharing and the democratization of technology, providing a platform for the global developer community to grow and collaborate together. Through open source, RAGFlow encourages more developers to participate in the project, solving problems together and sharing best practices, thereby accelerating the pace of innovation.
Ultimately, the success of RAGFlow is reflected not only in its technical achievements but also in its contributions to the entire RAG field and even the development of artificial intelligence technology. It not only promotes the innovation and application of related technologies but also lays a solid foundation for future technological progress and industrial development. As RAGFlow continues to evolve and improve, we have reason to believe that it will continue to play an important role in advancing artificial intelligence technology and promoting the digital transformation of society.
7. References
