
1. RAG (Retrieval Augmented Generation)
RAG technology is a method that combines retrieval and generation. It typically relies on two core components: a large language model (such as GPT-3) and a retrieval system (such as a vector database). RAG first uses the retrieval system to extract relevant information from a vast amount of data, then provides this information to the language model to generate answers or text. In this way, RAG can leverage the powerful generative capabilities of the language model along with the specific information provided by the retrieval system.
The RAG method integrates the capability of retrieval (or search) into the LLM. It combines a retrieval system and a large model, where the former retrieves relevant document fragments from a large corpus, and the latter uses the information from these fragments to generate answers. Essentially, RAG helps the model “find” external information to improve its responses.
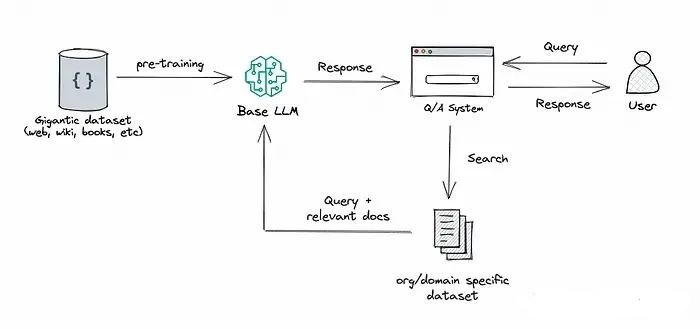
Features of RAG
-
Knowledge Dimension: RAG can quickly update its knowledge base by simply updating its database to reflect the latest information without the need to retrain the model.
-
Effectiveness Dimension: RAG performs well in terms of stability and interpretability, as the answers it generates are based on retrieved specific facts.
-
Cost Dimension: During inference, RAG requires an additional retrieval step, which may increase the cost of real-time processing.
Advantages of RAG
-
Fast Knowledge Updates: Knowledge can be updated quickly by simply updating the database, without needing to retrain the model.
-
Good Stability: Fact-based retrieval results can enhance the accuracy of the answers.
-
Interpretability: Retrieved information can serve as the basis for generating answers.
Disadvantages of RAG
-
Retrieval Dependency: The quality of the retrieval system directly impacts the final outcome.
-
Increased Real-Time Costs: The retrieval process requires additional time and computational resources.
2. Fine-Tuning
Fine-tuning is the process of further training a pre-trained large model using a smaller dataset specific to a certain domain. Through this process, the model can learn domain-specific knowledge and improve its performance on specific tasks.
Fine-tuning takes a pre-trained LLM and further trains it on a smaller, specific dataset to adapt it to specific tasks or improve its performance. By fine-tuning, we adjust the weights of the model based on the data, making it more suitable for the unique needs of our application.
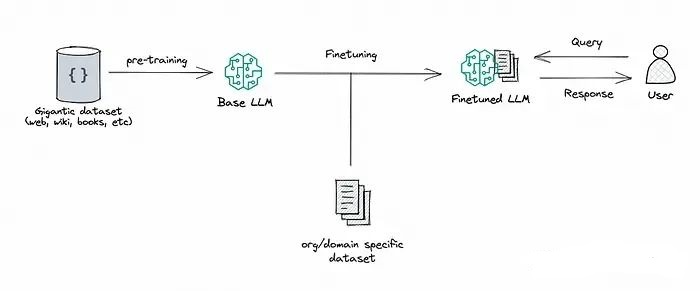
Features of Fine-Tuning
-
Knowledge Dimension: Fine-tuning allows the model to acquire new domain knowledge through training, requiring a relatively sufficient amount of domain data.
-
Effectiveness Dimension: For simple tasks, fine-tuning may achieve a higher performance ceiling, as it can specifically adjust model parameters.
-
Cost Dimension: Fine-tuning requires a significant amount of computational resources (such as GPUs) and has a longer training time.
Advantages of Fine-Tuning
-
Domain Adaptability: It can learn in-depth knowledge specific to a domain.
-
Performance Potential: For simple tasks, it may achieve better performance than RAG.
Disadvantages of Fine-Tuning
-
High Resource Consumption: It requires a lot of computational resources and time for training.
-
Knowledge Forgetting: The model is prone to forgetting knowledge that does not appear in the training data.
3. Adaptation Scenarios for RAG and Fine-Tuning
-
Knowledge Updates: RAG updates knowledge by updating the database, while fine-tuning absorbs new knowledge through retraining.
-
Effectiveness Stability: RAG is generally more stable when generating answers, while fine-tuning may achieve a higher performance ceiling.
-
Resource Consumption: Fine-tuning consumes more resources during training, while RAG incurs additional retrieval costs during inference.
Applicable Scenarios for RAG
-
Fields requiring rapid knowledge updates.
-
Application scenarios where real-time requirements are not particularly high.
-
Scenarios requiring high interpretability or accuracy.
Applicable Scenarios for Fine-Tuning
-
Fields with a small but high-quality dataset.
-
Scenarios with high requirements for model performance, where the corresponding computational resource consumption can be afforded.
-
Scenarios requiring deep learning of unique domain knowledge.
4. RAG + Fine-Tuning
Both RAG and fine-tuning have their advantages, and in certain scenarios, using them in combination can leverage their strengths to enhance overall effectiveness and efficiency. Here are some suggestions on when to combine RAG and fine-tuning:
-
Complex and Knowledge-Intensive Tasks: For problems that require in-depth domain knowledge and extensive background information, using RAG alone may not cover all details, while fine-tuning can help the model better understand these details.
-
Frequent Data Updates: In cases where data changes frequently, using RAG can quickly update the knowledge base, while fine-tuning can help the model adapt to new data distributions.
-
High Real-Time Requirements: If RAG is used alone, the retrieval step may introduce delays. Optimizing the model through fine-tuning can reduce reliance on the retrieval system and improve response speed.
-
Resource-Constrained Scenarios: In resource-limited situations, RAG can first be used to reduce the amount of data needed for fine-tuning, followed by fine-tuning on key or difficult-to-retrieve information.
Concentrated Combination Methods of RAG and Fine-Tuning:
-
Staged Training:
-
Initial Use of RAG: First, use RAG to handle tasks, leveraging its retrieval capability to quickly obtain relevant information.
-
Identifying Shortcomings: Analyze RAG’s shortcomings in handling tasks and identify situations where the model struggles or frequently makes errors.
-
Targeted Fine-Tuning: Collect data on the identified issues, then use this data to fine-tune the model, improving its performance in these specific scenarios.
-
Joint Training:
-
Simultaneously Train Retrieval and Generation: During fine-tuning, both the retrieval component and the language model can be trained together, allowing for better synergy between the two.
-
Using Pseudo-Labels: Pseudo-labels generated by the model can be used to train the retrieval component, and vice versa.
-
Iterative Optimization:
-
Cyclic Iteration: First, use RAG to generate answers, then fine-tune the model using these answers, and subsequently optimize the retrieval component with the fine-tuned model, forming an iterative optimization loop.
-
Domain Adaptation:
-
First Fine-Tune Then RAG: In scenarios requiring high domain adaptability, first fine-tune the model to adapt to a specific domain, then use RAG to supplement knowledge not covered by fine-tuning.
By using RAG and fine-tuning in this way, we can fully utilize RAG’s rapid knowledge retrieval capabilities and fine-tuning’s deep knowledge learning abilities, enhancing the model’s performance on complex tasks. At the same time, this combination can help balance the demands of real-time processing, accuracy, and resource consumption.
5. Project Case Based on Fine-Tuning + RAG: Domain-Specific Q&A System
Here is a simplified project case where we will combine RAG and fine-tuning to build a Q&A system aimed at answering questions about a specific topic. This case will demonstrate how to leverage RAG to quickly obtain information and use fine-tuning to improve the accuracy and adaptability of the answers.
Assuming we have a large language model (like GPT-2) and a vector database, we want to create a system capable of answering questions about the topic of “space exploration.” The main implementation steps include:
-
Prepare Dataset
-
Collect a dataset containing questions and answers related to the topic of “space exploration.”
-
Divide the dataset into training and validation sets.
-
Configure RAG Retrieval Component
-
Use a vector database to store documents related to the topic of “space exploration.”
-
Configure the retrieval system to retrieve documents relevant to the input questions from the database.
-
Initial Fine-Tuning
-
Use the training set to perform initial fine-tuning of the large language model to adapt it to the topic of “space exploration.”
-
Combine RAG and Fine-Tuning
-
Use RAG and fine-tuning together to build the Q&A system.
# Import necessary libraries
from transformers import GPT2LMHeadModel, GPT2Tokenizer
from retriever import VectorDBRetriever # Hypothetical retriever library
import torch
# Initialize model and tokenizer
model = GPT2LMHeadModel.from_pretrained('gpt2')
tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
# Initialize vector database retriever
retriever = VectorDBRetriever('space_exploration') # Hypothetical database
# Fine-tune model
def fine_tune(model, tokenizer, train_dataset):
# Fine-tuning code omitted, typically includes data loading, model training, etc.
# RAG process
def rag_process(question):
# Retrieve relevant information
relevant_docs = retriever.retrieve(question)
# Generate answer using retrieved documents
context = ' '.join(relevant_docs)
input_ids = tokenizer.encode(f'{question}{context}', return_tensors='pt')
output = model.generate(input_ids, max_length=100, num_return_sequences=1)
answer = tokenizer.decode(output[0], skip_special_tokens=True)
return answer
# Fine-tuned RAG process
def fine_tuned_rag_process(question):
# Fine-tune model
fine_tune(model, tokenizer, train_dataset)
# Use fine-tuned model for RAG process
return rag_process(question)
# Example question
question = "What is the Hubble Space Telescope?"
answer = fine_tuned_rag_process(question)
print(answer)Please note that the above code is pseudocode and is intended to illustrate the concept. Actual implementation would involve detailed model fine-tuning processes, data preprocessing, integration of the vector database, and other steps.
-
Data Preparation: Ensure the quality and coverage of the dataset, which is crucial for the effectiveness of fine-tuning.
-
Fine-Tuning Strategy: Choose an appropriate fine-tuning strategy, such as learning rate, batch size, number of training epochs, etc.
-
Retrieval Component: Build an efficient retrieval system based on the questions to ensure that relevant documents can be retrieved quickly and accurately.
By combining RAG and fine-tuning, we can build a Q&A system that has a broad knowledge background and can conduct deep learning for specific domains.
References:
[1] https://mp.weixin.qq.com/s?__biz=MzIwNDY1NTU5Mg==&mid=2247486811&idx=1&sn=2587b058e6ef8c749d01658299a29124&scene=21#wechat_redirect
[2] https://zhuanlan.zhihu.com/p/676364423