
Recommendation
This article introduces the book “Generative AI in Action“, published by O’Reilly in 2024, authored by Amit Bahree from Microsoft.

The book mainly covers knowledge related to generative AI, including LLMs, prompt engineering, model fine-tuning, RAG, vector databases, etc. The author provides numerous code examples, guiding readers into the world of generative AI through practical experience.
The field of generative AI is developing rapidly. Although this book is set to be published in November 2024, the technologies discussed within may already seem somewhat “outdated”. However, following the author’s insights, readers can quickly clarify the technical context of generative AI, aiding in deeper understanding later on.
Overview of Generative AI
With the popularity of large language models (LLMs), generative AI (GenAI) has gained increasing attention and adoption in recent years. As shown in the figure below, generative AI is a subfield of AI, evolving from deep learning.
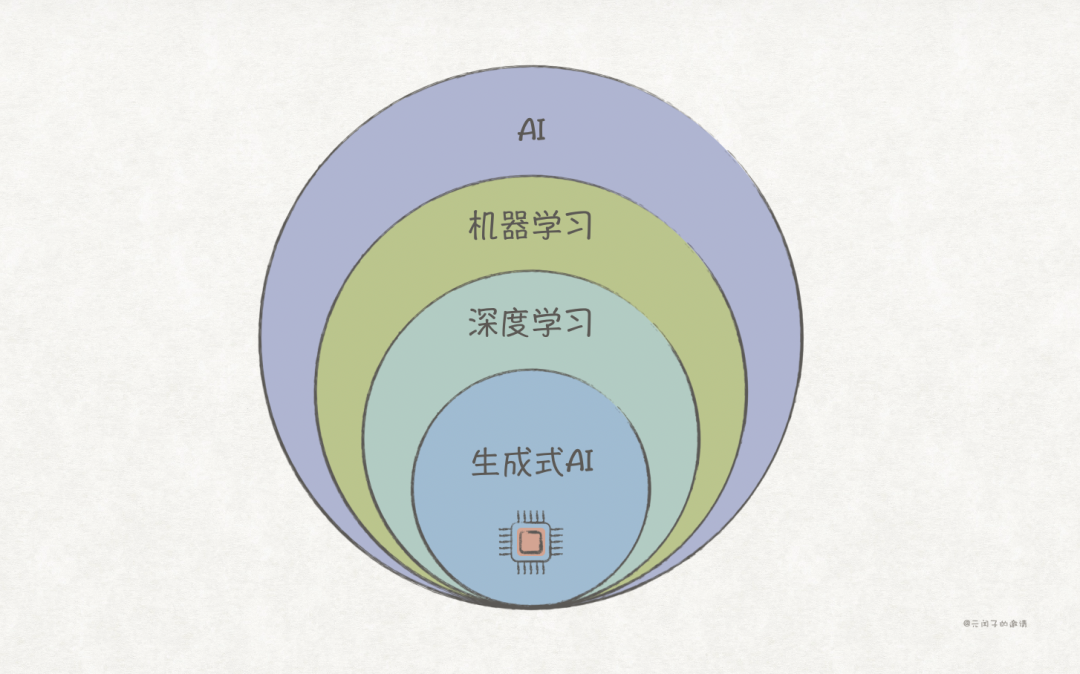
Traditional machine learning predicts data based on statistics;
deep learning simulates human brain behavior through neural networks to perform complex tasks;
while generative AI can create from data, just like humans do.
The following lists some differences between generative AI and traditional AI:
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Many people mistakenly equate ChatGPT with generative AI; in reality, ChatGPT is just the simplest application of generative AI. Generative AI can do much more, including generating text, images, videos, code, and music on a personal level; on a corporate level, it can be used for personalized marketing, customer service, risk management, contract management, etc.
In summary, generative AI can compensate for the limitations of traditional AI, helping users and businesses build more intelligent applications.
In the field of generative AI, large language models (LLMs) act as the brain, capable of generating content that meets user needs. The following sections will briefly introduce their principles.
Large Language Models
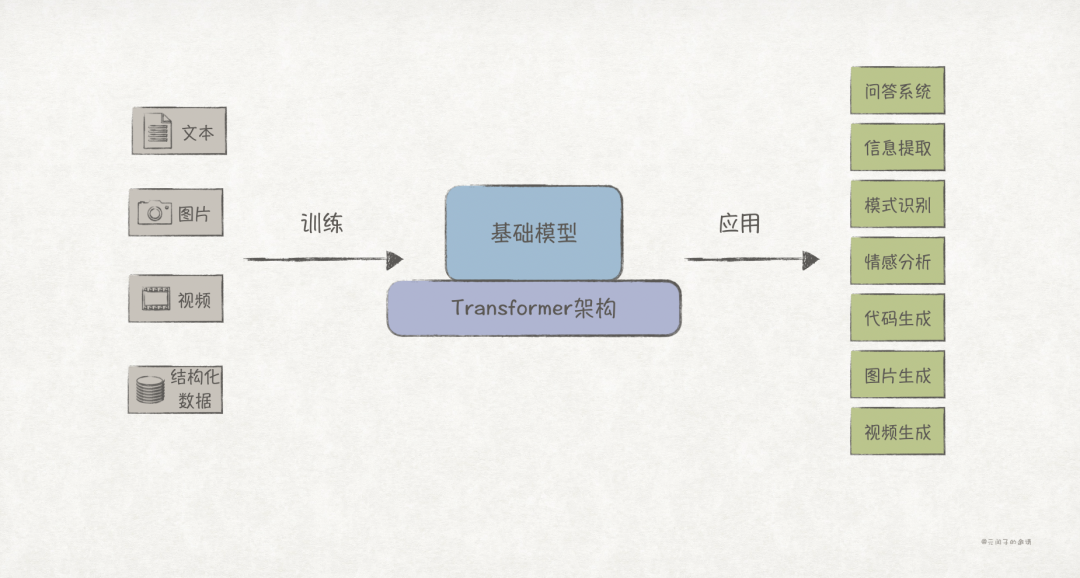
Large language models (LLMs) are the foundation of generative AI, developed from foundational models (FM), which were first proposed in 2021.
Previous AI models could typically only be applied to specific tasks, while FMs generalized optimization through training on large datasets, achieving greater adaptability.
The most representative early FM was Google’s BERT model, widely used in natural language understanding (NLU) tasks such as text classification and named entity recognition.
LLMs serve as foundational models for natural language processing (NLP) and generation (NLG) tasks, characterized by larger model sizes, including parameter count, training dataset size, and computing resources.
Typically, LLMs include their parameter scale in their names, such as Meta’s Llama 2-70B, where 7B indicates a parameter scale of 70 billion.
Generally, the more parameters a model has, the better its performance. Recently, the domestic large model DeepSeek V3 has even reached a scale of 671B.
Of course, the larger the model scale, the more computing resources are consumed, which translates to higher economic costs. Therefore, in scenarios where tasks are relatively simple or clear, users may prefer to use cost-effective small language models (SLMs), such as Microsoft’s recently released Phi-4 model, which has only 14B parameters but excels in mathematical reasoning due to various technological advancements.
The essence of LLMs is to use the current context to predict the next content, but they do not comprehend natural language as humans do. Therefore, input text (prompt) must first be tokenized to achieve better generalization, then converted into a format that can be understood (embedding), and finally predicted using a specific algorithm (transformer).
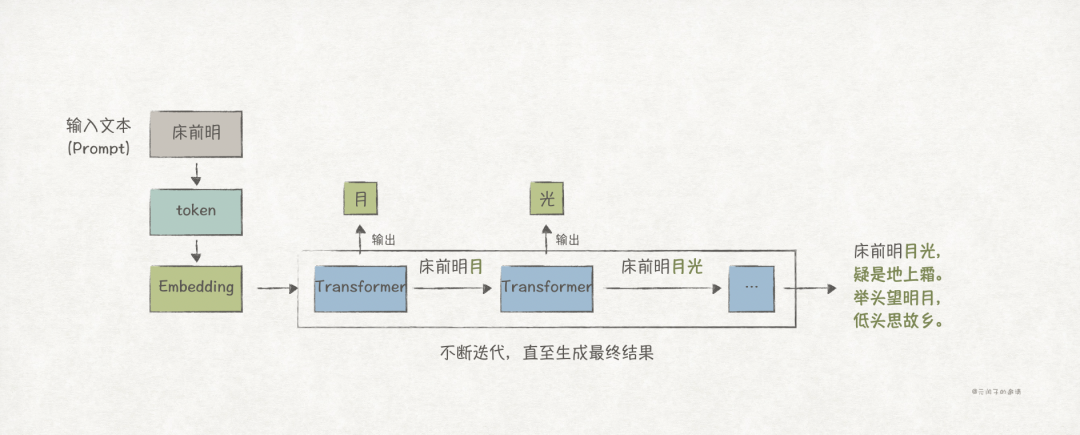
Token Sequence
Currently, almost all LLMs are based on a token architecture, which is the basic unit for processing text.
There are various methods to segment text into token sequences, commonly including character-based, word-based, and sentence-based segmentation.
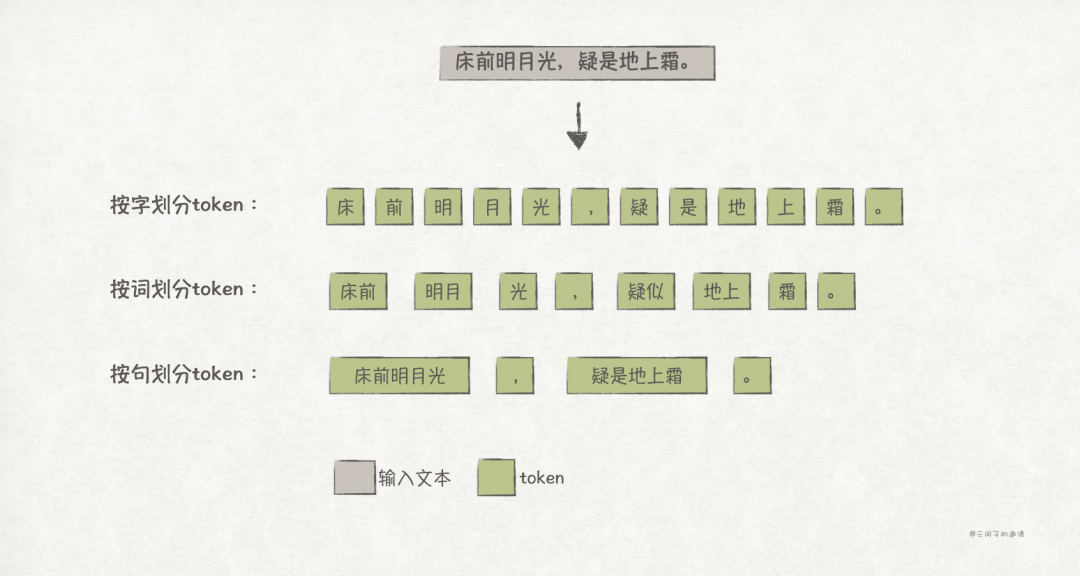
The finer the segmentation granularity, the better the model’s generalization, but the number of tokens will be greater, requiring more computational resources;
the coarser the granularity, the more semantic and contextual information is retained, but the number will be fewer, potentially unable to handle unfamiliar words or polysemous words, relying on a pre-built dictionary.
Since the number of tokens is linked to computational resources, the maximum token number that a model can process at once is limited. For example, the maximum token count supported by GPT-4o is 128K, while Llama 2 is 4K.
Embedding Vectors
After token segmentation, they must be converted into a vector format that LLMs can recognize and process, known as embedding.
The idea behind embedding is that tokens with similar meanings should have similar vector representations, and their similarity can be measured by the distance between vectors.
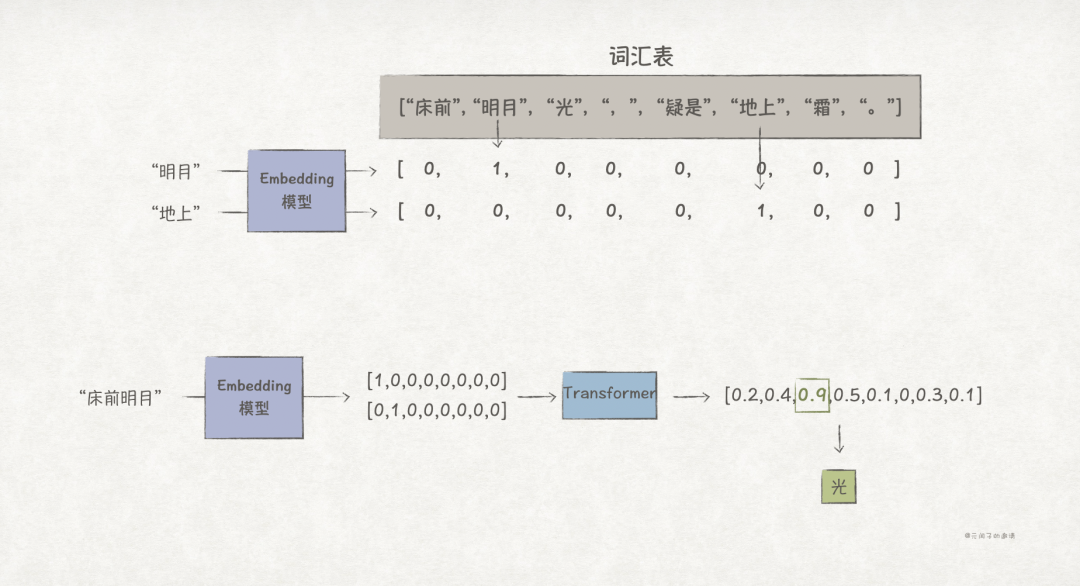
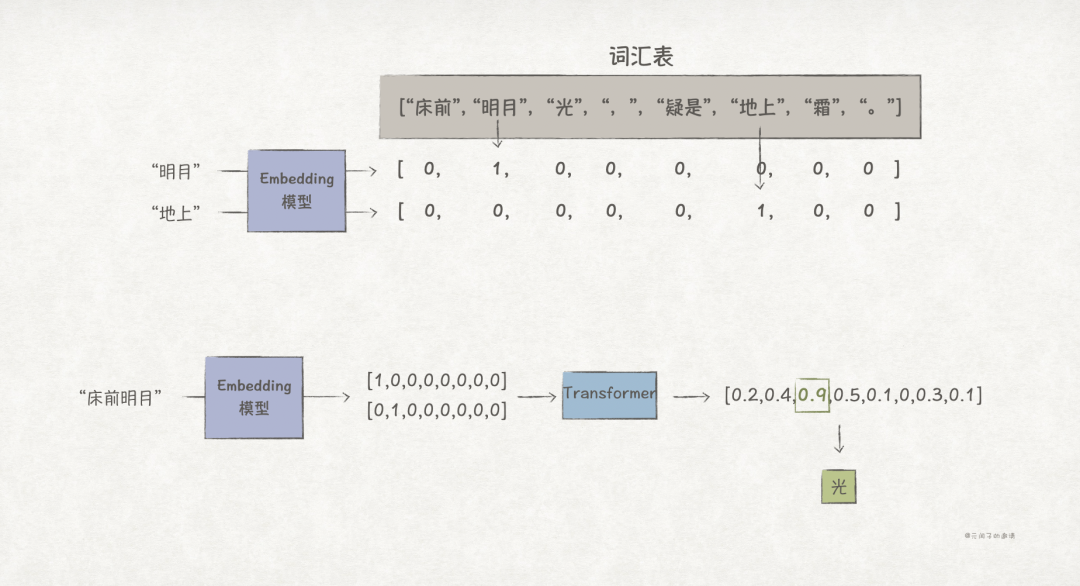
The embedding model is responsible for converting tokens into embeddings, and constructing the embedding model requires a series of processes including data collection, preprocessing, feature extraction, and training.
For example, in the phrase “Moonlight before the bed, suspecting it is frost on the ground.”, if we segment based on words and pre-build a vocabulary<span>["床前","明月","光",",","疑是","地上","霜","。"]</span>, then “明月” can be simply represented as<span>[0,1,0,0,0,0,0,0]</span>, similarly, “地上” can be represented as<span>[0,0,0,0,0,1,0,0]</span>.
If we input “床前明月” into the transformer, we might get an output embedding like<span>[0.2, 0.4, 0.9, 0.5, 0.1, 0, 0.3, 0.1]</span>, where “光” has the highest probability, thus the next token is “光”.
Transformer Architecture
The transformer architecture is the cornerstone of LLMs. It uses a mechanism called multi-head attention (MHA) to consider the entire prompt (collectively referred to as prompts) context, effectively capturing dependencies between tokens, thus possessing excellent language understanding capabilities.
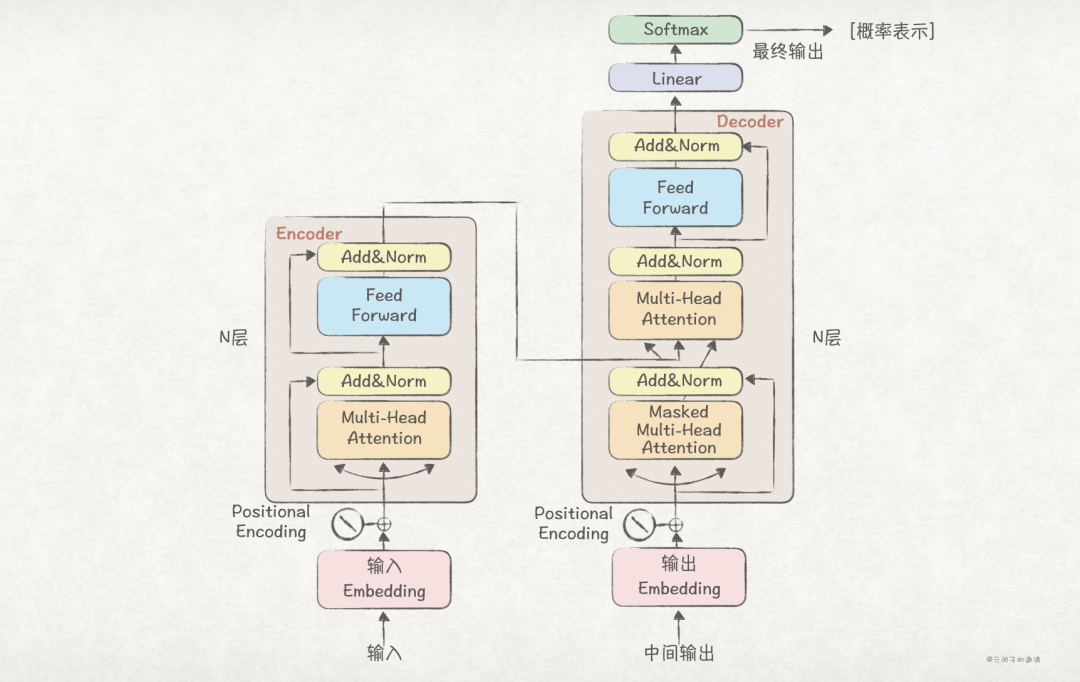
The principle diagram of the transformer architecture is shown above, divided into encoder and decoder parts. The diagram is complex. For simplicity, we will ignore Add&Norm, Feed Forward, Linear, Softmax, considering them all as standardization and dimension alignment modules.
The encoder’s input is the embeddings of the prompt (represented by<span>Ei</span>), which after the MHA mechanism finds the hidden state of<span>E</span>, then predicts the next token’s embedding (represented by<span>Eo1</span>), and then uses<span>Ei+Eo1</span> to predict the next token (<span>Eo2</span>), iterating continuously.
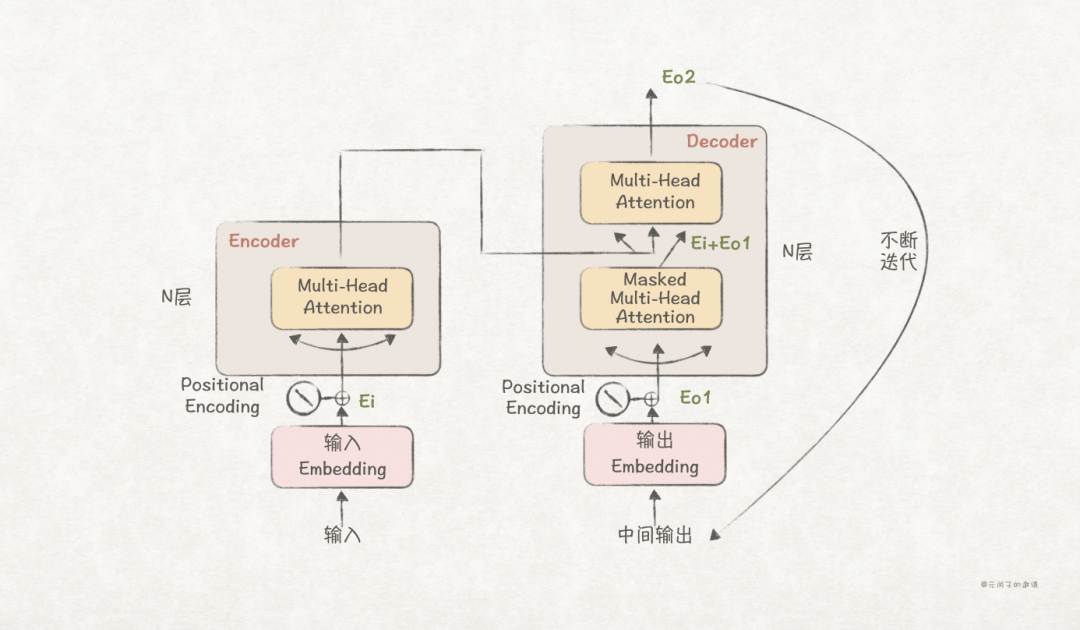
We note that embeddings must first undergo positional encoding before being input into MHA. So, what is the role of positional encoding?
Generally, the semantics of a sentence are closely related to the order of words in it. For example, “Do you know?” and “You don’t know” have completely different meanings. Therefore, we need to add positional information to embeddings, which is the purpose of positional encoding.
The core idea behind MHA is to find the deep semantic relationships (Attention) between words (tokens) in a sentence from multiple perspectives (Multi-Head), thus predicting the next word.
This multi-perspective approach is achieved through linear transformations of vectors, leveraging the ability of a vector to uncover hidden features through linear transformation, while the essence remains the same.
For example, in the phrases “Moonlight before the bed” and “Suspecting it is frost on the ground”, from a semantic perspective, “床前” and “地上” are similar; from a prosodic perspective, “光” and “霜” are similar.
For the input vector<span>E</span>, the following diagram illustrates how attention mechanisms highlight deep semantic relationships:
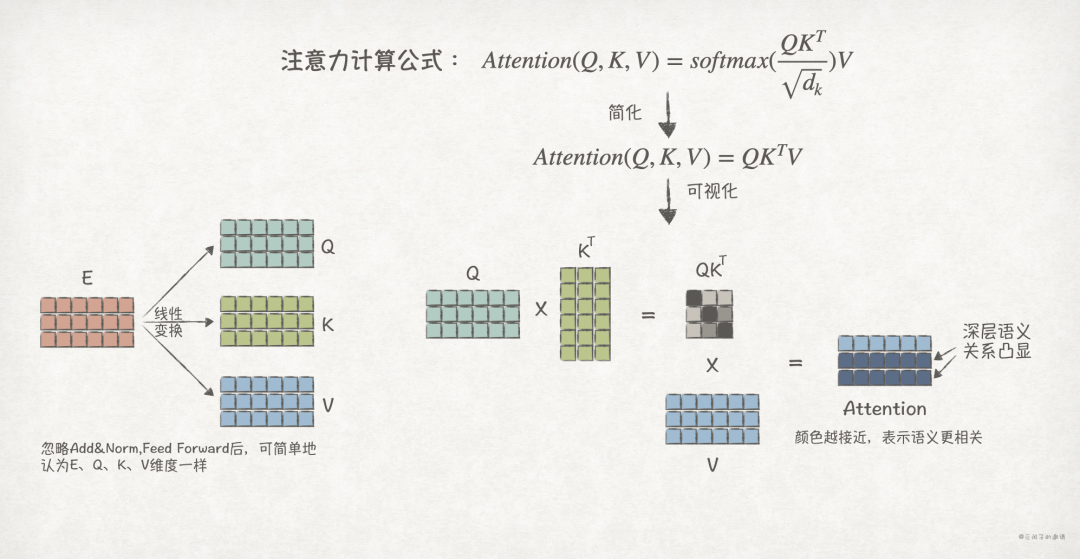
The above diagram simplifies attention computation, where<span>Q</span>, <span>K</span>, and <span>V</span> are derived from the linear transformation of<span>E</span>, ignoring normalization and dimension alignment, they can be considered to have the same dimension.
First, <span>Q</span> and <span>K</span> undergo dot product operations. The higher the similarity between the dot product results of two vectors, the larger the value. Therefore, if two words have a higher semantic similarity, the result of their embedding’s dot product will also be larger. Finally, this (weight) is multiplied by<span>V</span>, which highlights the deep semantic relationships in<span>V</span>.
One attention computation is one head; after multiple attention computations, the results are combined, forming the multi-head attention mechanism. Through multiple computations, it is equivalent to mining semantic relationships from multiple angles, leading to a more accurate final result.
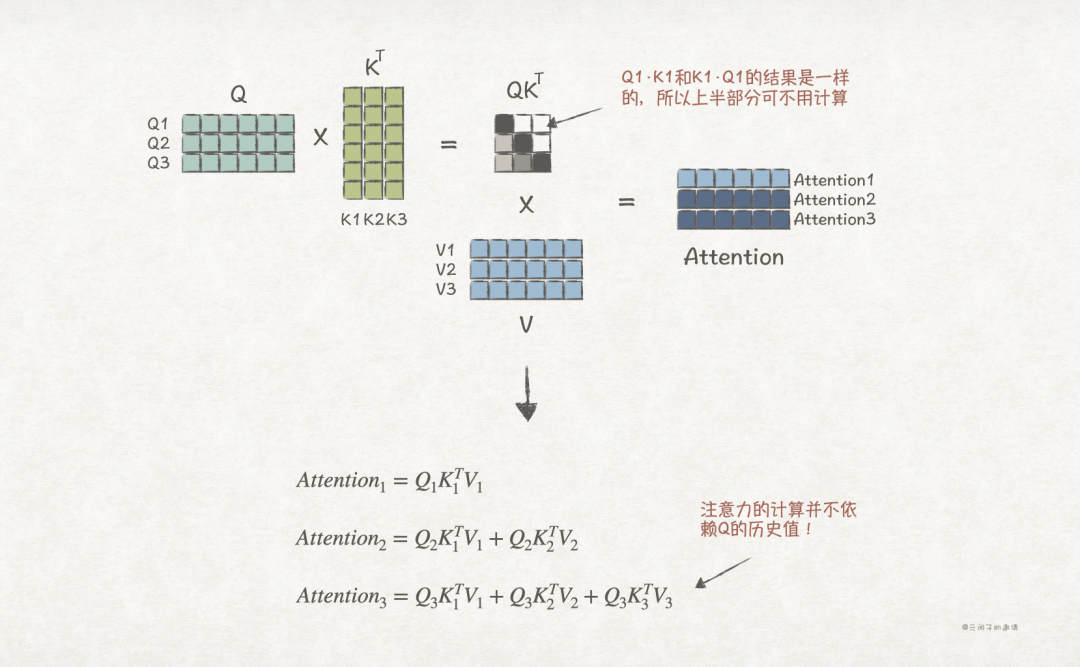
According to the transformer algorithm flow, each computation requires attention calculation for all tokens. For example, if the input is “床前”, after attention calculation, it may yield “明月”, and in the next round of prediction, they will be concatenated, forming “床前明月”, followed by calculations to yield “光”.
In fact, “床前” has already been computed in the previous prediction, and its result can be cached, allowing the next computation to focus solely on “明月”, this is the principle of KV Cache.
As for why Q is not cached, the principle is illustrated in the following diagram:
Limitations of LLMs
While LLMs are powerful, they also have their limitations:
-
Lack of Timeliness. The powerful generative capabilities of LLMs rely on the data used for training. Once training is completed, knowledge is no longer updated, and they cannot perform external searches, leading to a lack of timeliness. -
Hallucination Problem. Insufficient understanding of context or lack of specialized knowledge may lead LLMs to confidently generate inaccurate or non-existent results.
Below, we provide an example of a hallucination problem caused by a lack of context.
Imagine you are a high school student needing to write an article about the Spring Festival, focusing on the customs of your hometown, around 500 words.
Now you want the LLM to help you complete the article, you might input the following prompt:
> “Write an article about the Spring Festival”
The output from the GPT-4o mini model is as follows:

The model output gives a general introduction to the Spring Festival but lacks detailed descriptions, clearly failing to meet your expectations.
The important reason for this “hallucination” phenomenon is the insufficient context provided to the model; you only prompted it to write an article about the Spring Festival without providing more detailed requirements (focusing on the customs of your hometown, etc.).
Now, we enrich the prompt:
>“You are now a high school student with excellent Chinese grades, and you need to write an essay on the Spring Festival similar to the style of Wang Zengqi, around 500 words. Your hometown is Guangdong, and the article should focus on the customs of the New Year’s Eve dinner in Guangdong, introducing common dishes and emphasizing the preparation and taste of the white cut chicken to highlight the food’s color, aroma, and taste, expressing nostalgia for your hometown. The essay does not need a subtitle.”
The model output is as follows:

Clearly, the quality of the output has significantly improved. This method of optimizing prompts to enhance the quality of LLM-generated content is known as prompt engineering.
Prompt Engineering
A prompt is the input for LLMs used to guide them in content generation. Prompt engineering refers to the practice of enhancing output quality through carefully designed prompts.
The core idea is to provide richer context information for prompts, aimed at helping the model better understand user intent.
The simplest form of prompt engineering is to design templates manually and write prompts based on those templates when asking questions.
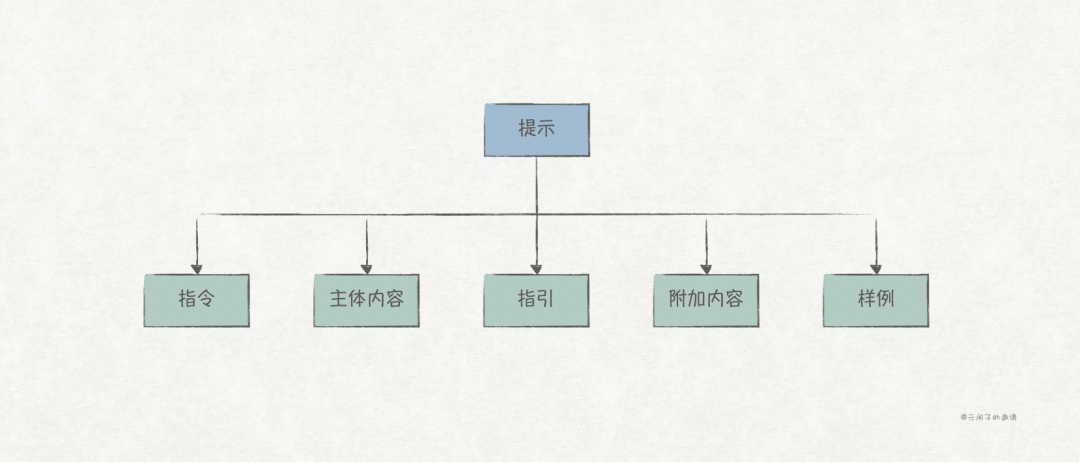
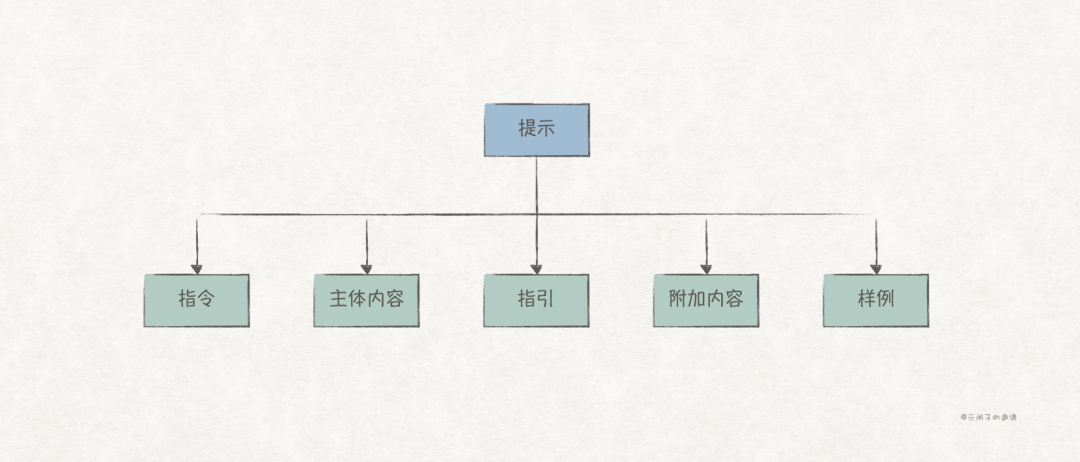
A good prompt typically includes the following elements:
-
Instruction (instruction): The task or question for the model to execute, such as in the previous example, “Write an article about the Spring Festival”. -
Main Content (primary content): The main content for the model to execute, providing more detailed information about the instruction, such as “The article should focus on the customs of the New Year’s Eve dinner in Guangdong, introducing common dishes…” -
Guidance (cue): Supplementary information for the instruction and main content, providing some “constraints” that help, such as “in the style of Wang Zengqi”, “The essay does not need a subtitle” etc. -
Supporting Content (supporting content): Additional content that can be injected into the prompt, such as specialized knowledge or the latest information, to ensure the model’s output is more accurate. -
Example (example): Samples of the model’s generated responses, providing LLM with a reference.
Different application scenarios have different prompt templates. For example, in a middle school writing scenario, the prompt should indicate “You are a high school student”, while in a medical scenario, it should indicate “You are a doctor”.
Moreover, the design of prompt templates is an iterative process that often requires the use of software frameworks for automation, such as Prompt Flow, LangChain, etc.
Prompt engineering is a lightweight optimization method that does not require modification of the model’s parameters, guiding the model’s output through given prompts. However, prompt engineering is not always effective.
The quality of LLM-generated content is closely related to the training data. The essence of prompt engineering is guidance; if the training data lacks specialized medical knowledge, even the best prompt will struggle to guide the model to produce high-quality medical Q&A results.
Here, the phrase “the best prompt” does not include the introduction of high-quality additional content. There is a technique called retrieval-augmented generation (RAG) that can achieve this, which will be introduced later.
For such scenarios, we can use specialized medical datasets for secondary training of the model, enhancing its capabilities, a process known as model fine-tuning.
Model Fine-Tuning
LLMs achieve broad understanding of natural language through extensive training on general datasets (pre-trained models), ensuring system generalization, but may perform poorly in certain specialized fields.
Model fine-tuning (Fine-tune) refers to the process of using specific datasets for secondary training on existing pre-trained models (like GPT-4o, Llama 3.3, etc.) to adjust model parameters for better performance on specific domain tasks.
Model fine-tuning can be broadly divided into two types:
-
Full Fine-Tuning (Full Fine-tuning), which involves comprehensive secondary training of the model and updates all parameters. -
Low-Rank Adaptation (Low-rank adaptation, LoRA), which allows effective fine-tuning with fewer trainable parameters while keeping model weights unchanged.
The choice between full fine-tuning and LoRA is a trade-off; the former provides better fine-tuning results but at a higher computational cost, while the latter sacrifices some accuracy to significantly reduce computational costs.
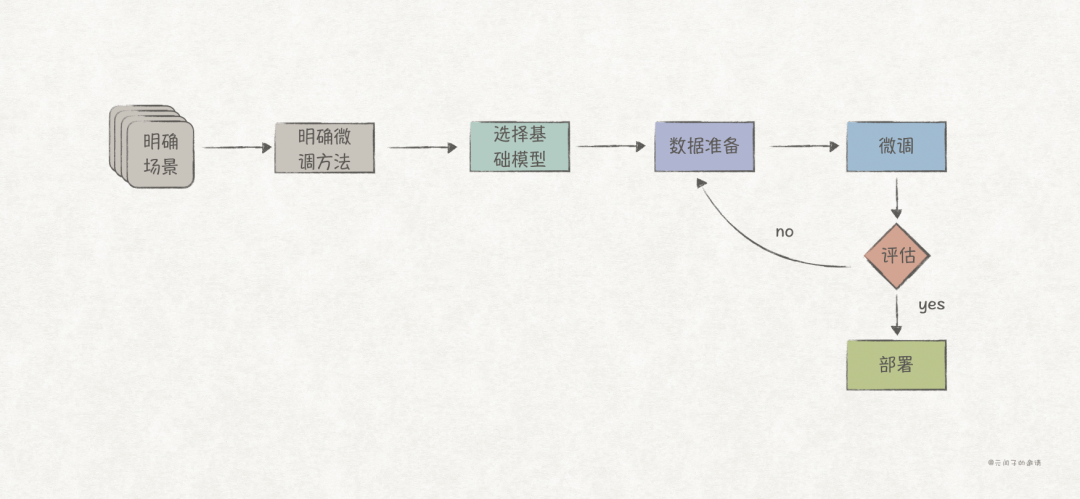
As mentioned, the process of model fine-tuning is also an iterative process, mainly consisting of the following key steps:
-
Select Foundational Model and Fine-Tuning Method. Choose an appropriate foundational model and fine-tuning method based on specific application scenarios, considering factors such as model adaptability to tasks, dataset size, infrastructure, etc. For instance, for a Chinese Q&A application, it’s better to choose Qwen, which has better support for Chinese, rather than Llama. -
Data Preparation. Mainly involves preprocessing steps such as clarity, standardization, and format conversion of the dataset. -
Fine-Tuning. The actual process of fine-tuning the model, involving secondary training of the model. -
Evaluation. Evaluate the fine-tuning effects; if results are poor, adjust parameters and re-fine-tune. Common evaluation metrics typically include accuracy, logical coherence, and fluency of language. -
Deployment. Once evaluated and passed, the model can be deployed and put into production.
The costs of model fine-tuning are substantial, and the following diagram illustrates the various stages of model training along with their computational and time costs:
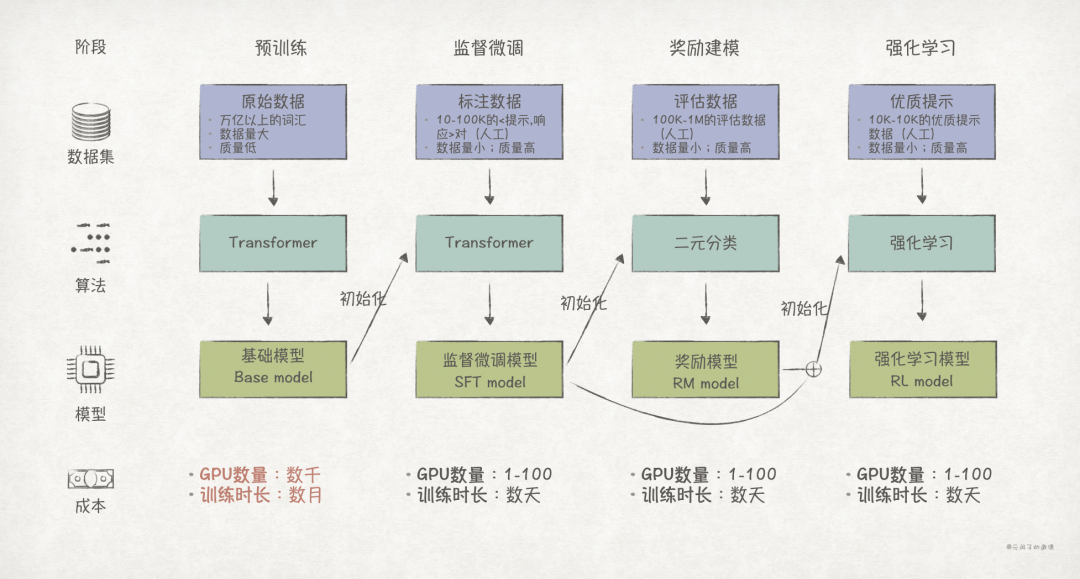
For applications with high timeliness requirements, to ensure that the model always contains the latest knowledge, continuous fine-tuning is necessary.
On one hand, fine-tuning is very time-consuming (taking several days), which may not meet timeliness requirements; on the other hand, the enormous costs of repeated fine-tuning are also unacceptable to users.
If there were a way for LLMs to automatically retrieve the latest knowledge and use it as input to generate results, it would ensure both timeliness and avoid high fine-tuning costs!
Retrieval-augmented generation (RAG) is such a technology.
Retrieval-Augmented Generation
Retrieval-augmented generation (RAG) is a technique that utilizes information retrieval to optimize LLM outputs by referencing knowledge bases outside of training data before generating results, enriching context and thus enhancing the accuracy of generated content.
As mentioned earlier, prompts have a key element of additional content, which can provide LLM with context beyond training data.
The essence of RAG is to retrieve relevant knowledge from external knowledge bases based on user queries, and then add it to the prompt as additional content, enhancing the generated content of LLMs.
Basic Workflow of RAG
As mentioned earlier, in LLMs, text is converted into vectors to capture deep semantic relationships; RAG operates similarly, where both text and external knowledge must first be converted into vectors for processing:
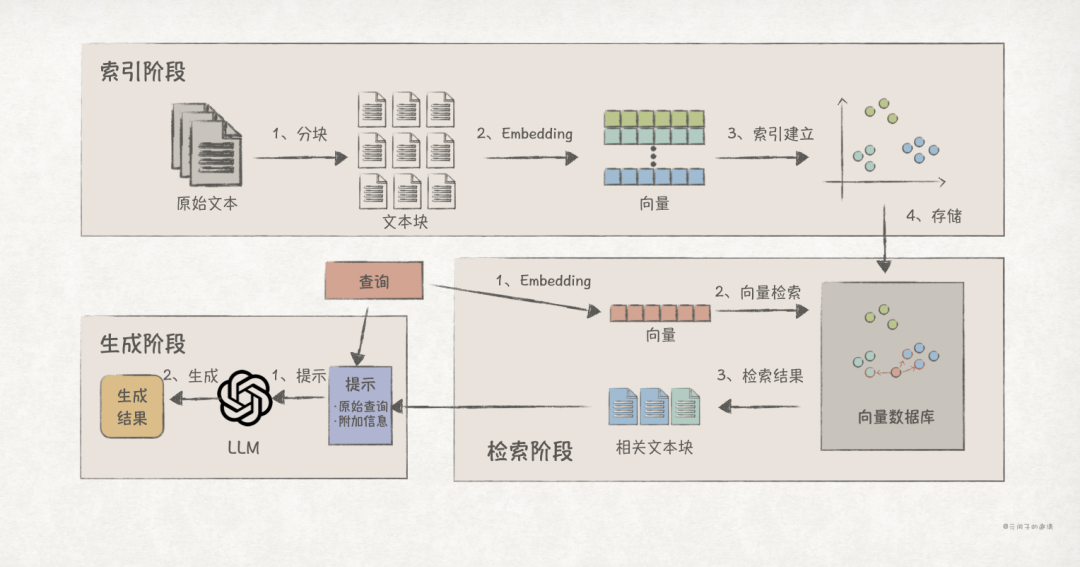
As shown in the diagram above, the RAG workflow is divided into two stages: indexing, retrieval, and generation.
1. Indexing Stage
The indexing stage involves organizing external knowledge into a specific data structure for more efficient retrieval. The main steps include:
1. Text Chunking. Raw text often has characteristics of being lengthy and information-dense, such as a book, which is not conducive to efficient retrieval. On one hand, excessive distracting information affects retrieval accuracy; on the other hand, the computational overhead during retrieval is high. Text chunking can break long texts into smaller, more granular chunks, allowing for more accurate matching of user query intent while reducing computational and storage overhead.
2. Embedding. Convert text chunks into vectors using an embedding model.
3. Indexing. Build an index for the vectors using specific data structures, such as graph-based HNSW, hash bucket-based LSH, inverted index IVF, etc.
4. Storage. Store the original vectors and index data, either using specialized vector databases like Milvus or traditional databases with vector index plugins, such as PostgreSQL + pgvector.
2. Retrieval Stage
The retrieval stage involves using queries to retrieve relevant text chunks, with two main steps:
1. Embedding. Use the same embedding model from the indexing stage to convert the original query into a vector.
2. Retrieval. Use vector similarity calculations to find the Top N relevant text chunks that best match the original query.
3. Generation Stage
The generation stage first combines the relevant text chunks with the original query to form a new prompt, guiding the LLM to complete content generation based on the relevant text chunks.
Based on the above RAG process, we can easily answer questions like: “What is the iconic building of Guangzhou?”
However, for questions that require multi-hop reasoning or global summary, it may be difficult to answer, such as: “What is the iconic building of the capital city of the province where Shenzhen is located?” or “What are the iconic buildings of each province in Guangdong?”.
This is because such questions require combining multiple text chunks (which may not be similar vectors) to generate an answer.
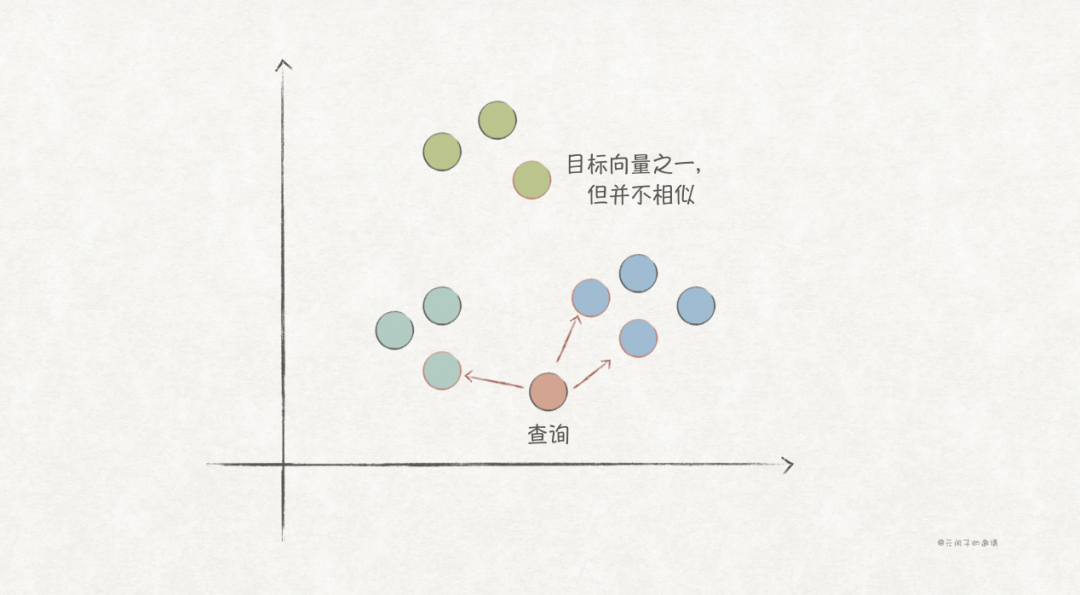
This highlights the limitations of traditional RAG, which relies solely on vector similarity retrieval:
-
Ignoring Relationships. Text chunks are often interconnected rather than isolated; relying solely on vector retrieval makes it difficult to capture highly structured relationships in knowledge. -
Lack of Global Information. Vector retrieval can only retrieve subsets of text, making it challenging to obtain global information, hindering tasks like global summarization.
To establish relationships, we can easily think of knowledge graphs (KG), which organize data in a graph structure where entities are the vertices and relationships are the edges of the graph.
Introducing Knowledge Graphs to RAG
The combination of RAG and knowledge graphs is referred to as GraphRAG, which is an important branch of RAG, aiming to organize text in the form of graphs/knowledge graphs, considering the interconnections between texts to more accurately capture deep relationships between texts; additionally, it can identify subgraphs or communities to obtain global information, thereby addressing scenarios like global summarization.
There are many implementation solutions for GraphRAG, and we will focus on Microsoft’s open-source implementation (https://github.com/microsoft/graphrag).
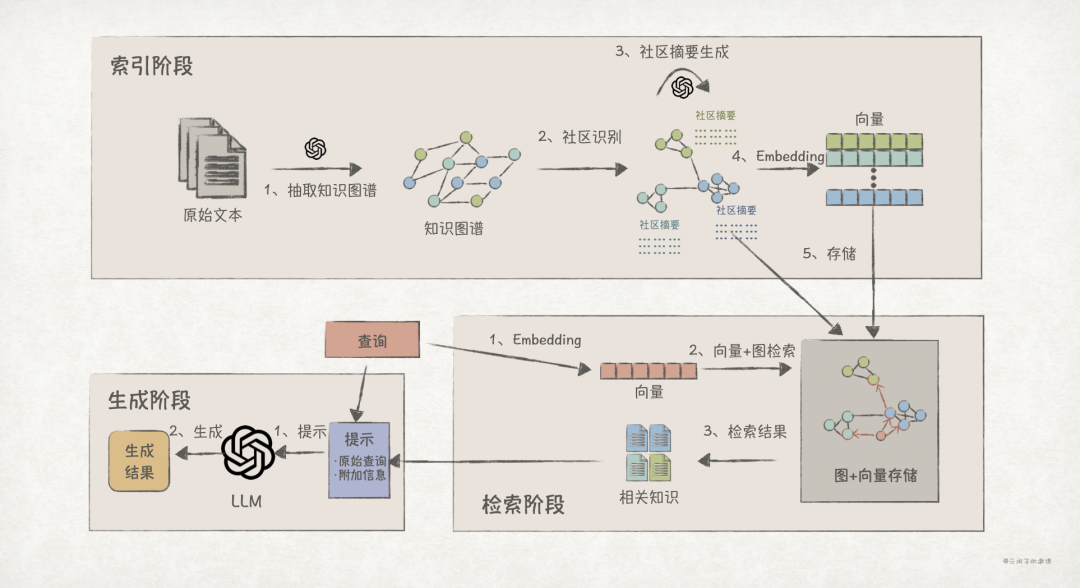
As shown in the diagram above, the differences between GraphRAG and traditional RAG mainly lie in the indexing and retrieval stages.
1. Indexing Stage
1. Use LLMs to extract knowledge graphs from text chunks and store them in graph format.
Microsoft’s GraphRAG stores this in Parquet data tables on disk and does not use graph databases.
2. Use the Leiden algorithm to identify multi-level communities and generate community summaries for each community using LLMs to aid processing in the subsequent generation stage.
3. Convert entities, relationships, community summaries, and text chunks from the knowledge graph into vectors using the embedding model, storing them in a vector database.
Microsoft’s GraphRAG currently implements compatibility with Azure AI Search, Azure Cosmosdb, and LanceDB (which can only be deployed on a single machine).
2. Retrieval Stage
Depending on the query type, multi-hop reasoning queries use local queries, while global summary queries use global queries:
1. Local Queries. Based on the query, retrieve the starting entities from the vector database, then use them as starting points in the knowledge graph to retrieve other related entities and relationships, adding this as additional content to the prompt.
2. Global Queries. For each community summary, perform preliminary parallel summarization using LLMs to generate intermediate results, which are then finalized in the generation stage.
The drawbacks of Microsoft’s GraphRAG are evident, as it frequently uses LLMs in both the indexing and querying stages, resulting in high computational costs.
To address this, Microsoft released an optimized version, LazyGraphRAG, at the end of 2024, employing techniques such as using lightweight NLP algorithms for knowledge graph extraction during the indexing stage and decomposing original queries into sub-queries to improve query efficiency, ensuring that query accuracy does not decline while significantly reducing costs.
To date, whether traditional RAG or GraphRAG, each user query is only retrieved once, which may still result in inaccuracies in some complex query tasks.
If a feedback mechanism could be established, automatically adjusting retrieval conditions when evaluating that the current retrieval does not meet requirements, and executing the next retrieval, the probability of obtaining high-quality retrieval results would significantly increase after multiple iterations.
Introducing Feedback Mechanisms to RAG
Introducing feedback mechanisms to RAG requires an evaluation module to assess the quality of retrieval results and determine the next execution strategy:
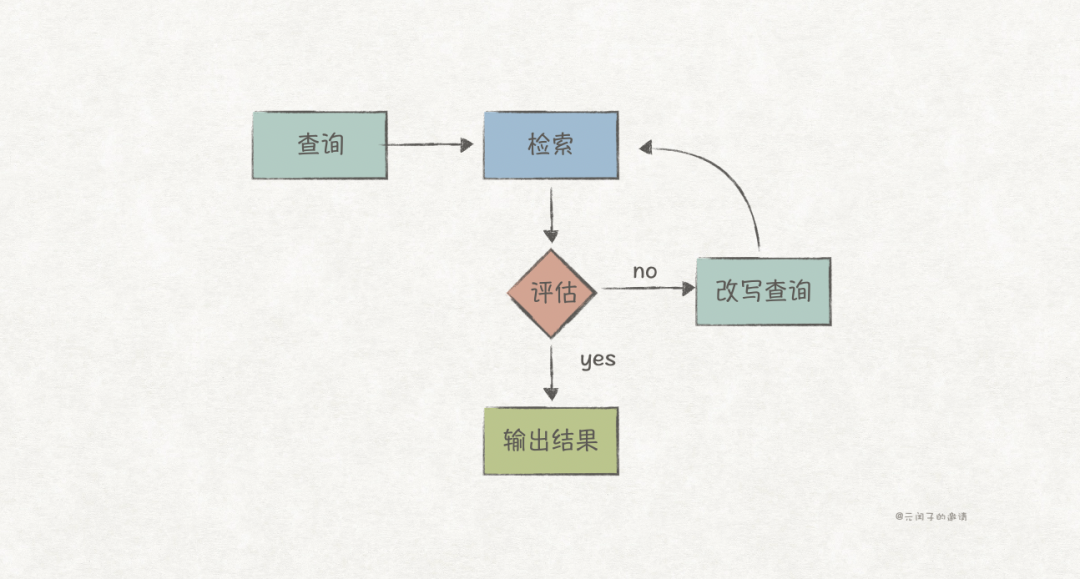
We can easily think of using AI agents for evaluation and decision-making, which is precisely their expertise.
AI agents are intelligent entities capable of perceiving the environment, making decisions, and executing actions. They can analyze environmental information and data (retrieval results), automatically perform tasks, and optimize behaviors (deciding whether to terminate or continue iterating) to achieve specific goals (returning high-quality retrieval results).
The combination of RAG and AI agents is referred to as Agentic RAG. In addition to evaluation and decision-making, it can also perform query decomposition, query routing, and information retrieval.
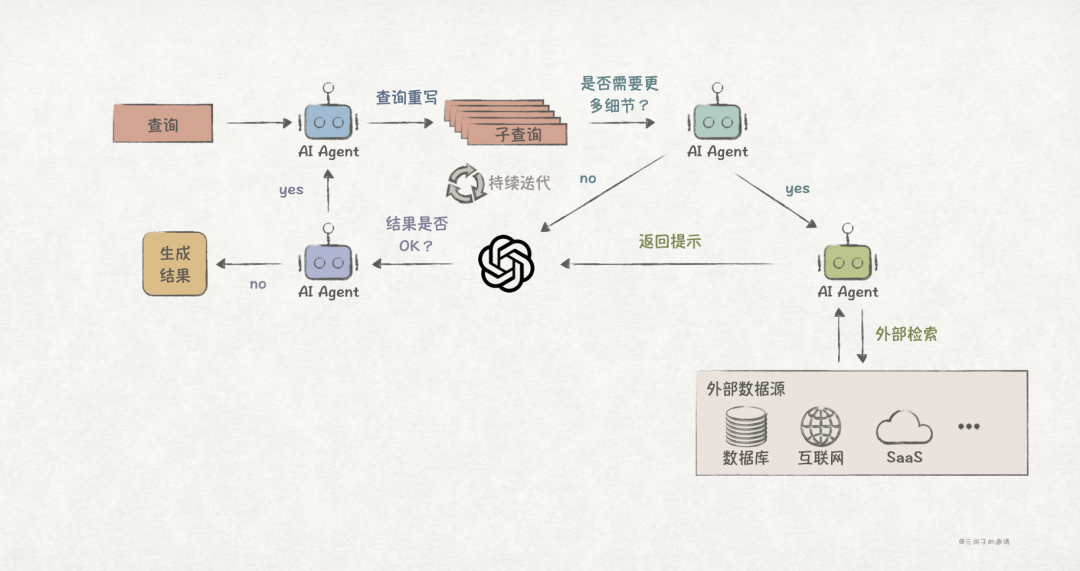
The integration of AI agents brings great flexibility to RAG, allowing for easy expansion of new functionalities based on user needs.
Of course, Agentic RAG also increases system complexity and computational resource requirements; in short, there is no perfect RAG solution; everything is a trade-off.
Reviewing the Technological Evolution of RAG
Looking back, from traditional RAG to GraphRAG, and then to Agentic RAG, these step-by-step optimizations correspond to the evolution of the three paradigms of RAG.
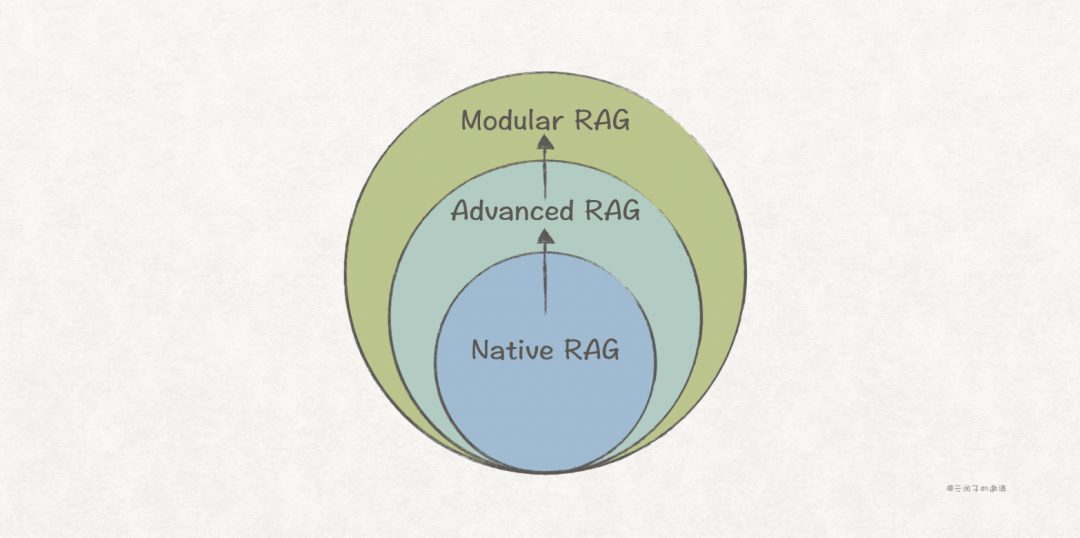
1. Native RAG
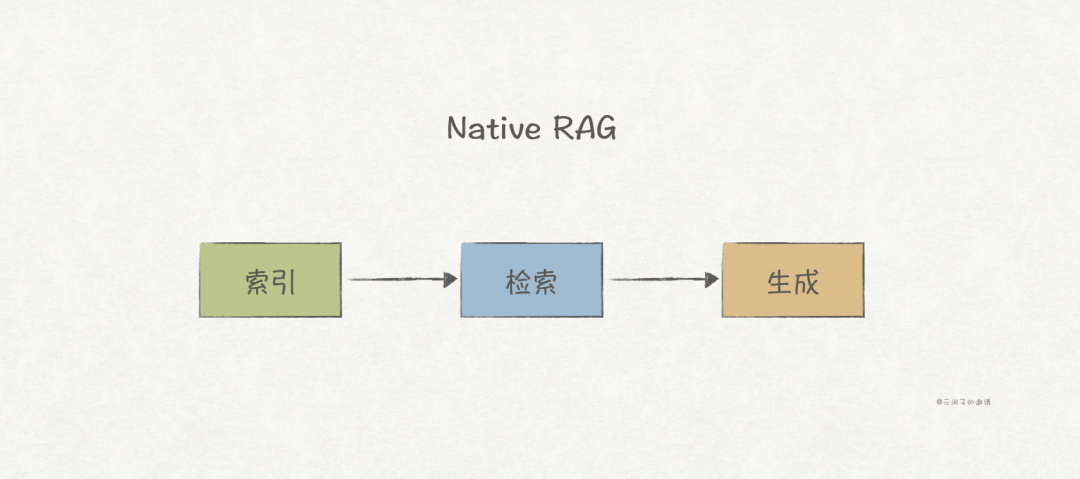
Native RAG is the earliest paradigm, following the traditional paradigm of Index -> Retrieval -> Generation. As previously mentioned, it still faces low retrieval accuracy issues in complex scenarios (multi-hop reasoning, global summarization, etc.).
2. Advanced RAG
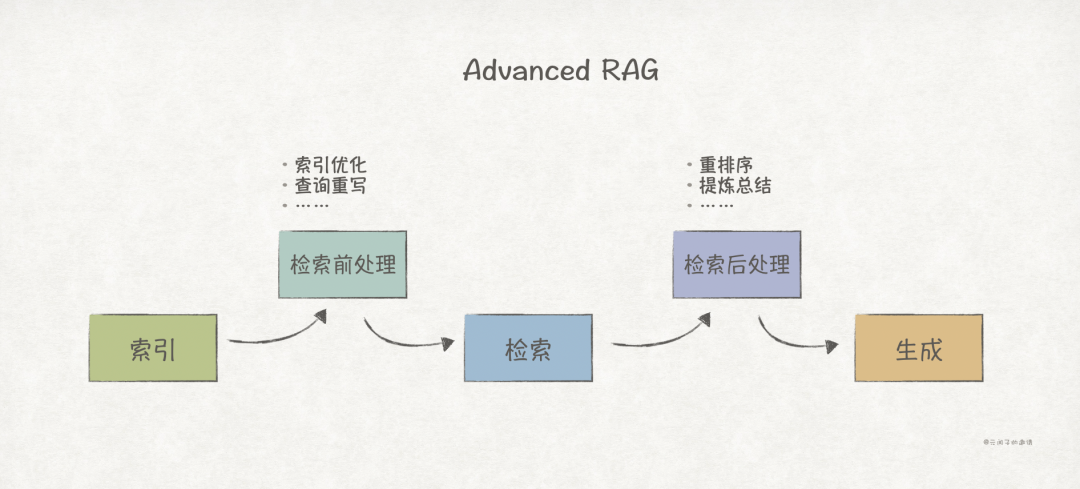
Advanced RAG adds pre-retrieval and post-retrieval processing steps to the Native RAG, somewhat overcoming its limitations:
-
Pre-Retrieval Processing mainly optimizes the index structure (for example, GraphRAG introduces knowledge graphs) and original query optimization (for example, LazyGraphRAG’s sub-query decomposition). -
Post-Retrieval Processing mainly involves reordering or summarizing retrieval results to further enhance context accuracy.
3. Modular RAG
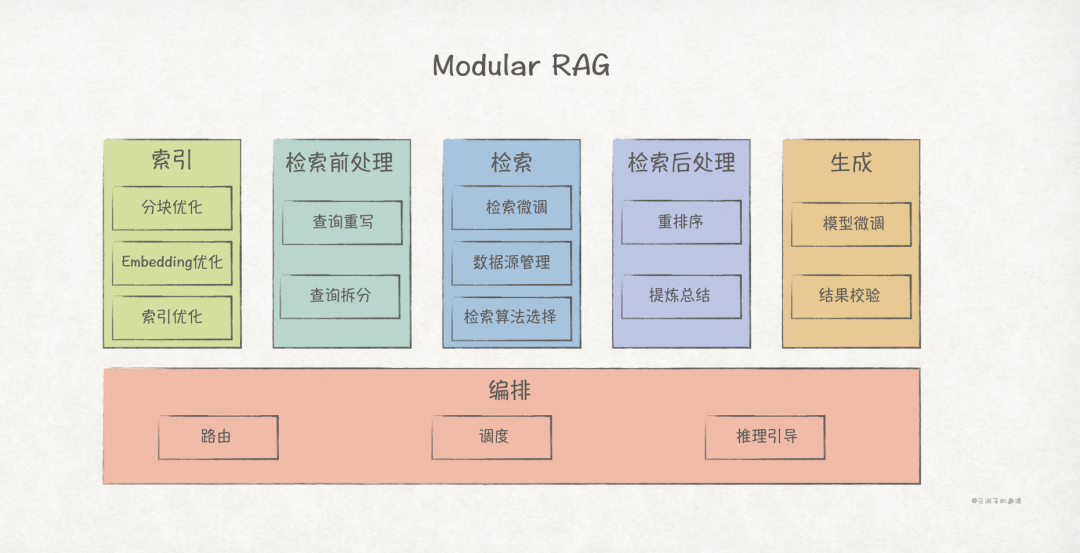
Modular RAG offers stronger adaptability based on the first two paradigms, supporting flexible orchestration of retrieval workflows to address different scenarios.
So far, we have found that regardless of the RAG paradigm, vector retrieval is indispensable. This is because vectors are the language of AI models; text, images, and videos must be converted into vectors for LLMs to utilize. The key component that provides vector retrieval capability is the vector database (vector database).
Vector Databases
A vector database is a type of database used to store, manage, and query high-dimensional vectors, enabling efficient similarity retrieval.
Vector databases can be classified into two types:
-
Specialized databases designed for vector retrieval, such as Milvus, Weaviate, Pinecone, etc. -
Conventional databases that support vector retrieval functions, such as PostgreSQL (through the pgvector plugin), Elasticsearch, etc.
With the rise of generative AI, vector databases have become increasingly popular over the past two years, with more conventional databases beginning to support vector retrieval functions. As application scenarios diversify, specialized vector databases are also starting to support scalar queries, full-text searches, and other functions typical of conventional databases.
Comprehensive vector databases are gradually becoming a trend.
Vector databases primarily leverage the principle of vector similarity, which has been previously introduced, so we will not elaborate further here.
Software Architecture Based on Generative AI
In the past, enterprise software architecture has undergone several significant transformations from the monolithic era to the service-oriented era and then to the cloud-native era to meet the ever-changing business needs.
Today, the rise of generative AI will promote a new round of software architecture transformation.
The author of the book defines the software architecture based on generative AI as follows:
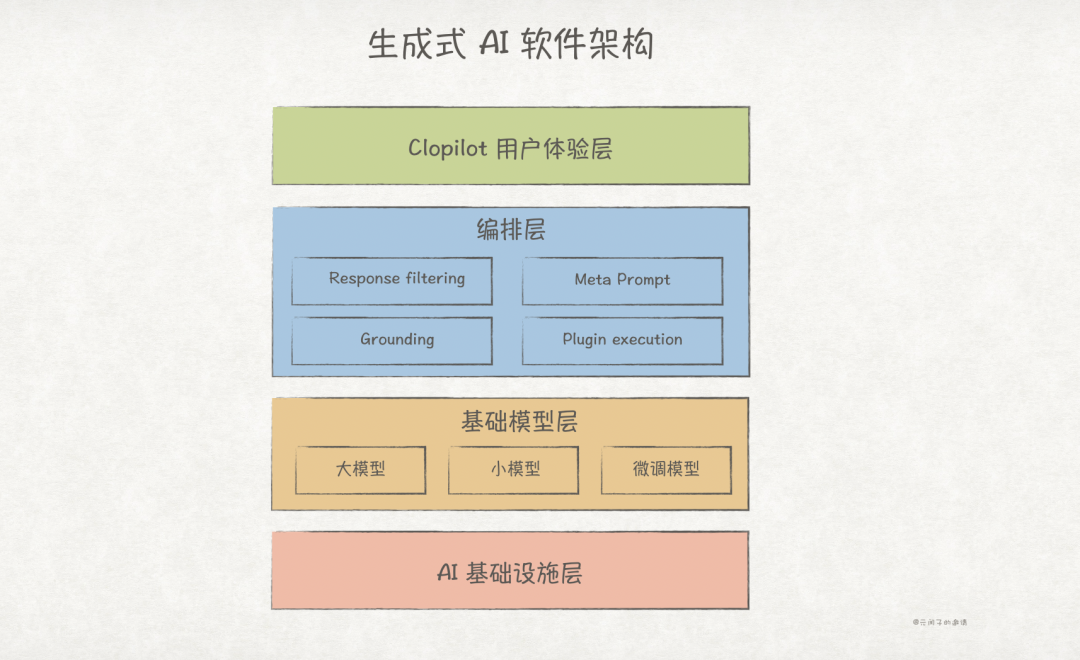
AI Infrastructure Layer
The AI infrastructure layer is the driving force behind everything, encompassing the hardware (XPU, memory, storage, etc.), software (compilers, OS, containers, etc.), and services (observability services, etc.) that support the development and deployment of generative AI applications.
It is typically optimized for workloads associated with generative AI and possesses high-performance computing capabilities to support LLM training and inference.
Foundational Model Layer
The foundational model layer encompasses various foundational models:
It can include high-performance large models (LLMs), such as DeepSeek V3 671B, Llama 3.1 405B, etc.
It can also include small models (SLMs) for edge/end-side applications, such as Phi-4 14B, Gemma-2 2B, etc.
Or it can include models fine-tuned for specific domains, such as medical models like MMedLM, Med-PaLM v2.0, etc.
Orchestration Layer
The orchestration layer is key to the entire architecture, responsible for task allocation, resource management, and workflow optimization, consisting of four components: Response filtering, Meta prompt, Grounding, and Plugin execution.
-
Response Filtering. Analyzes, filters, and optimizes prompts and responses from foundational models, ensuring that responses returned to users are accurate and safe. -
Meta Prompt. Provides additional information and constraints for foundational models, which can be user-defined or automatically generated; prompt engineering falls under this layer. -
Grounding. Ensures that responses are relevant to the context specified by users; RAG falls under this layer. -
Plugin Execution. Provides additional functionalities for the system, such as data retrieval, formatting, validation, etc. The vector databases relied upon by RAG fall under this layer.
Currently, the industry has seen the emergence of many orchestration frameworks, such as LangChain, Llama-Index, Hugging Face, etc.
Copilot User Experience Layer
Copilot, the AI co-pilot, is an important concept in generative AI, aimed at enhancing human capabilities and creativity.
The Copilot user experience layer provides users with powerful and easy-to-use AI toolchains/interfaces, operating in different modes based on various application scenarios, such as GitHub Copilot for coding assistance and Microsoft 365 Copilot for office assistance.
In Conclusion
Generative AI is still rapidly evolving.
Recently released domestic large model DeepSeek V3 has taken the internet by storm, utilizing FP8 mixed precision training and multi-token prediction techniques to significantly reduce costs while ensuring high performance.
Google’s latest Titans architecture aims to address the memory bottleneck issues present in the current transformer architecture when processing long sequence data, claiming to be the successor to the latter.
Prompt engineering is also continuously evolving, integrating with technologies like Chain of Thought to tackle more complex scenarios.
Model fine-tuning has not disappeared due to the emergence of RAG; both play significant roles in different application scenarios.
According to a survey by the China Internet Network Information Center (CNNIC), as of December 2024, the user base for generative AI applications in China has reached 249 million, accounting for 17.7% of the total population.
The era of generative AI has arrived.
References
[1] Generative AI in Action, Amit Bahree
[2] Attention Is All You Need, Ashish Vaswani, etc.
[3] https://www.zhihu.com/question/596900067, Learn through images
[4] Retrieval-Augmented Generation for Large Language Models: A Survey, Yunfan Gao, etc.
[5] Modular RAG: Transforming RAG Systems into LEGO-like Reconfigurable Frameworks, Yunfan Gao, etc.
[6] Graph Retrieval-Augmented Generation: A Survey, Boci Peng Boci, etc.
[7] CNNIC Report: The User Base of Generative AI Products Reaches 249 Million, Southern Metropolis Daily
For more articles, please follow our WeChat public account:Yuan Runzi’s Invitation