
[Introduction] Natural Language Processing has become an important branch of artificial intelligence, which studies various theories and methods that enable effective communication between humans and computers using natural language. This article provides a brief introduction to Natural Language Processing to help readers quickly get started.
Author | George Seif
Compiled by | Xiaowen

An Easy Introduction to Natural Language Processing
Using computers to understand human language
Computers are very good at handling standardized and structured data, such as database tables and financial records. They can process this data faster than we humans can. However, we do not communicate using “structured data” and do not speak in binary! We communicate with words, which is unstructured data.
Unfortunately, computers find it difficult to process unstructured data because there are no standardized techniques to handle it. When we program computers using languages like C, Java, or Python, we are essentially giving them a set of rules they should operate under. For unstructured data, these rules are abstract and challenging to define concretely.
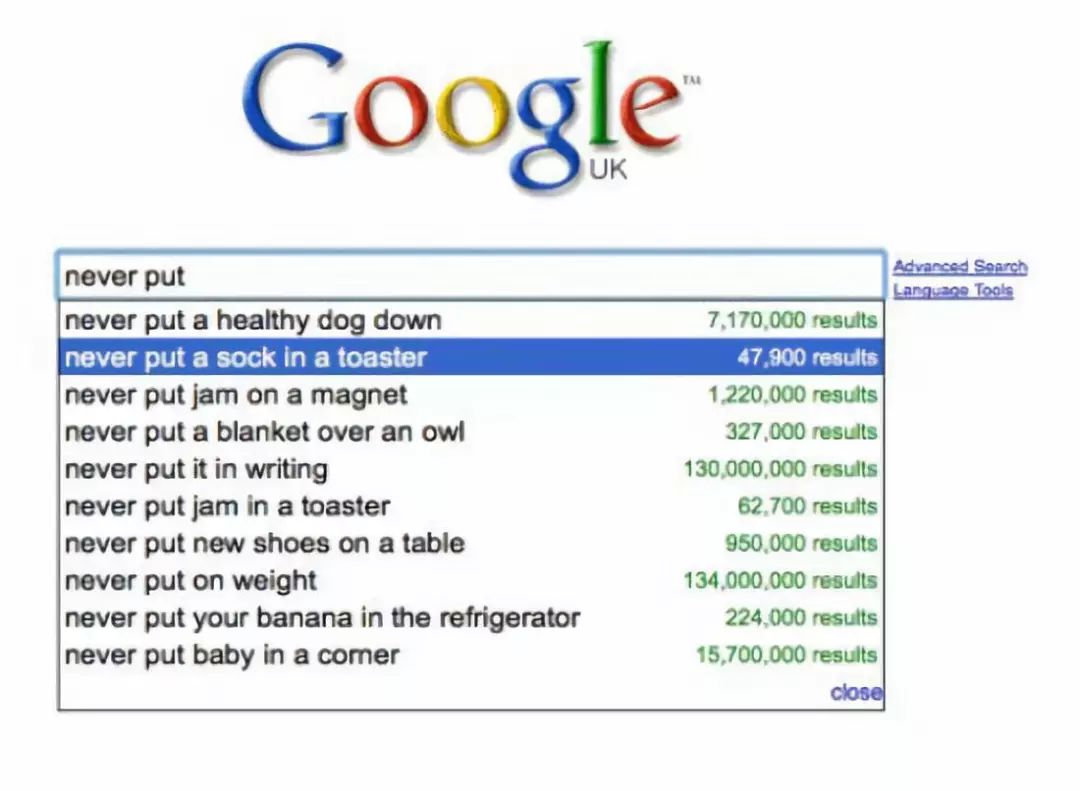
There is a lot of unstructured natural language on the internet, and sometimes even Google does not understand what you are searching for!
Understanding Language Between Humans and Computers
Humans have been writing for thousands of years. During this time, our brains have gained a lot of experience in understanding natural language. When we read something on a piece of paper or a blog on the internet, we understand its true meaning in the real world. We feel the emotions triggered by reading these things, and we often imagine what they would look like in real life.
Natural Language Processing (NLP) is a subfield of artificial intelligence that aims to enable computers to understand and process human language, bringing computers closer to human understanding of language. Computers’ intuitive understanding of natural language is still not as good as humans; they cannot truly comprehend what language is trying to convey. In short, computers cannot read between the lines.
Nevertheless, recent advancements in Machine Learning (ML) have allowed computers to perform many useful tasks using natural language! Deep learning enables us to write programs to perform tasks such as language translation, semantic understanding, and text summarization. All of this adds value to the real world, allowing you to easily understand and execute computations on large blocks of text without manual intervention.
Let’s start with a quick introduction to how NLP works conceptually. After that, we will dive into some Python code so you can start using NLP yourself!
The Real Reason NLP is Difficult
The process of reading and understanding language is far more complex than it first appears. To truly understand what a piece of text means in the real world, there is a lot to consider. For example, what do you think the following text means?
“Steph Curry was on fire last night. He totally destroyed the other team”
For a person, the meaning of this sentence is clear. We know Steph Curry is a basketball player; even if you don’t know, we know he is on some team, probably a sports team. When we see “on fire” and “destroyed,” we understand that it means Steph Curry played very well last night and defeated another team.
Computers often take things too literally. Literally, we see “Steph Curry” and assume based on capitalization that it is a person, a place, or something else significant. But then we see Steph Curry “on fire”… the computer might tell you someone set Steph Curry on fire yesterday! … Oh no. After that, the computer might say, curry has destroyed another team… they no longer exist… great…

Steph Curry is really on fire!
But not everything machines do is brutal; thanks to machine learning, we can actually do some very clever things to quickly extract and understand information from natural language! Let’s see how to do this in just a few lines of code using a few simple Python libraries.
Using Python Code to Solve NLP Problems
To understand how NLP works, we will use the following text from Wikipedia as our running example:
Amazon.com, Inc., doing business as Amazon, is an American electronic commerce and cloud computing company based in Seattle, Washington, that was founded by Jeff Bezos on July 5, 1994. The tech giant is the largest Internet retailer in the world as measured by revenue and market capitalization, and second largest after Alibaba Group in terms of total sales. The amazon.com website started as an online bookstore and later diversified to sell video downloads/streaming, MP3 downloads/streaming, audiobook downloads/streaming, software, video games, electronics, apparel, furniture, food, toys, and jewelry. The company also produces consumer electronics—Kindle e-readers, Fire tablets, Fire TV, and Echo—and is the world’s largest provider of cloud infrastructure services (IaaS and PaaS). Amazon also sells certain low-end products under its in-house brand AmazonBasics.
Required Libraries
First, we will install some useful Python NLP libraries that will help us analyze this article.
### Installing spaCy, general Python NLP lib
pip3 install spacy
### Downloading the English dictionary model for spaCy
python3 -m spacy download en_core_web_lg
### Installing textacy, basically a useful add-on to spaCy
pip3 install textacy
Entity Analysis
Now that everything is installed, we can perform quick entity analysis on the text. Entity analysis goes through the text and identifies all the important words or “entities” in the text. When we say “important,” we really mean words that have some real-world semantic significance.
Check out the code below, which performs all the entity analysis for us:
# coding: utf-8
import spacy
### Load spaCy's English NLP model
nlp = spacy.load('en_core_web_lg')
### The text we want to examine
text = "Amazon.com, Inc., doing business as Amazon,
is an American electronic commerce and cloud computing
company based in Seattle, Washington, that was founded
by Jeff Bezos on July 5, 1994. The tech giant is the
largest Internet retailer in the world as measured by
revenue and market capitalization, and second largest
after Alibaba Group in terms of total sales. The amazon.
com website started as an online bookstore and later
diversified to sell video downloads/streaming, MP3
downloads/streaming, audiobook downloads/streaming,
software, video games, electronics, apparel, furniture,
food, toys, and jewelry. The company also produces
consumer electronics-Kindle e-readers, Fire tablets,
Fire TV, and Echo-and is the world's largest provider
of cloud infrastructure services (IaaS and PaaS).
Amazon also sells certain low-end products under
its in-house brand AmazonBasics."
### Parse the text with spaCy
### Our 'document' variable now contains a parsed version of text.
document = nlp(text)
### print out all the named entities that were detected
for entity in document.ents:
print(entity.text, entity.label_)We first load spaCy’s learned ML model and initialize the text we want to process. We run the ML model on the text to extract entities. When you run that code, you will get the following output:
Amazon.com, Inc. ORG
Amazon ORG
American NORP
Seattle GPE
Washington GPE
Jeff Bezos PERSON
July 5, 1994 DATE
second ORDINAL
Alibaba Group ORG
amazon.com ORG
Fire TV ORG
Echo LOC
PaaS ORG
Amazon ORG
AmazonBasics ORG
The three-letter codes next to the text are tags indicating the type of entity we are looking at. It seems our model did a good job! Jeff Bezos is indeed a person, the date is correct, Amazon is an organization, and Seattle and Washington are geopolitical entities (i.e., countries, cities, states, etc.). The only tricky issue is that things like Fire TV and Echo are actually products, not organizations. However, the model missed other products sold by Amazon, such as “video downloads/streaming, mp3 downloads/streaming, audiobook downloads/streaming, software, video games, electronics, apparel, furniture, food, toys, and jewelry,” likely because they seem relatively unimportant in a large list.
Overall, our model has done what we wanted. Imagine we have a massive document filled with hundreds of pages of text; this NLP model can quickly give you an idea of the document’s content and what the key entities are.
Manipulating Entities
Let’s try to do something more practical. Suppose you have the same block of text as above, but for privacy reasons, you want to automatically remove all names of people and organizations. The spaCy library has a very useful cleaning function that we can use to clear any entity categories we don’t want to see. Here’s how:
# coding: utf-8
import spacy
### Load spaCy's English NLP model
nlp = spacy.load('en_core_web_lg')
### The text we want to examine
text = "Amazon.com, Inc., doing business as Amazon,
is an American electronic commerce and cloud computing
company based in Seattle, Washington, that was founded
by Jeff Bezos on July 5, 1994. The tech giant is the
largest Internet retailer in the world as measured by
revenue and market capitalization, and second largest
after Alibaba Group in terms of total sales. The
amazon.com website started as an online bookstore and
later diversified to sell video downloads/streaming,
MP3 downloads/streaming, audiobook downloads/streaming,
software, video games, electronics, apparel, furniture
, food, toys, and jewelry. The company also produces
consumer electronics - Kindle e-readers, Fire tablets,
Fire TV, and Echo - and is the world's largest
provider of cloud infrastructure services (IaaS and
PaaS). Amazon also sells certain low-end products
under its in-house brand AmazonBasics."
### Replace a specific entity with the word "PRIVATE"
def replace_entity_with_placeholder(token):
if token.ent_iob != 0 and (token.ent_type_ == "PERSON" or token.ent_type_ == "ORG"):
return "[PRIVATE] "
else:
return token.string
### Loop through all the entities in a piece of text and apply entity replacement
def scrub(text):
doc = nlp(text)
for ent in doc.ents:
ent.merge()
tokens = map(replace_entity_with_placeholder, doc)
return "".join(tokens)
print(scrub(text))
It works great! This is actually a very powerful technique. People often use the ctrl+f function on computers to find and replace words in documents. But with NLP, we can find and replace specific entities, considering their semantic meaning, not just their raw text.
Extracting Information from Text
The textacy library we installed earlier implements several common NLP information extraction algorithms on top of spaCy. It allows us to do some more advanced things than simple out-of-the-box tasks.
One of the algorithms it implements is semi-structured statement extraction. This algorithm essentially analyzes the information that the spaCy NLP model can extract and obtains more specific information about certain entities! In short, we can extract certain “facts” about the entities we choose.
Let’s see what this looks like in code. For this example, we will extract the entire summary from the Washington D.C. Wikipedia page.
# coding: utf-8
import spacy
import textacy.extract
### Load spaCy's English NLP model
nlp = spacy.load('en_core_web_lg')
### The text we want to examine
text = """Washington, D.C., formally the District of Columbia and commonly referred to as Washington or D.C., is the capital of the United States of America.[4] Founded after the American Revolution as the seat of government of the newly independent country, Washington was named after George Washington, first President of the United States and Founding Father.[5] Washington is the principal city of the Washington metropolitan area, which has a population of 6,131,977.[6] As the seat of the United States federal government and several international organizations, the city is an important world political capital.[7] Washington is one of the most visited cities in the world, with more than 20 million annual tourists.[8][9]
The signing of the Residence Act on July 16, 1790, approved the creation of a capital district located along the Potomac River on the country's East Coast. The U.S. Constitution provided for a federal district under the exclusive jurisdiction of the Congress and the District is therefore not a part of any state. The states of Maryland and Virginia each donated land to form the federal district, which included the pre-existing settlements of Georgetown and Alexandria. Named in honor of President George Washington, the City of Washington was founded in 1791 to serve as the new national capital. In 1846, Congress returned the land originally ceded by Virginia; in 1871, it created a single municipal government for the remaining portion of the District.
Washington had an estimated population of 693,972 as of July 2017, making it the 20th largest American city by population. Commuters from the surrounding Maryland and Virginia suburbs raise the city's daytime population to more than one million during the workweek. The Washington metropolitan area, of which the District is the principal city, has a population of over 6 million, the sixth-largest metropolitan statistical area in the country.
All three branches of the U.S. federal government are centered in the District: U.S. Congress (legislative), President (executive), and the U.S. Supreme Court (judicial). Washington is home to many national monuments and museums, which are primarily situated on or around the National Mall. The city hosts 177 foreign embassies as well as the headquarters of many international organizations, trade unions, non-profit, lobbying groups, and professional associations, including the Organization of American States, AARP, the National Geographic Society, the Human Rights Campaign, the International Finance Corporation, and the American Red Cross.
A locally elected mayor and a 13‑member council have governed the District since 1973. However, Congress maintains supreme authority over the city and may overturn local laws. D.C. residents elect a non-voting, at-large congressional delegate to the House of Representatives, but the District has no representation in the Senate. The District receives three electoral votes in presidential elections as permitted by the Twenty-third Amendment to the United States Constitution, ratified in 1961."""
### Parse the text with spaCy
### Our 'document' variable now contains a parsed version of text.
document = nlp(text)
### Extracting semi-structured statements
statements = textacy.extract.semistructured_statements(document, "Washington")
print("**** Information from Washington's Wikipedia page ****")
count = 1
for statement in statements:
subject, verb, fact = statement
print(str(count) + " - Statement: ", statement)
print(str(count) + " - Fact: ", fact)
count += 1

Our NLP model discovered three useful facts about Washington D.C. from this article:
(1) Washington is the capital of the United States
(2) Washington’s population and the fact that it is a metropolitan area
(3) Many national monuments and museums
The best part is that these are the most important pieces of information in that paragraph!
Diving Deeper into NLP
Here we conclude our simple introduction to NLP. We’ve learned a lot, but this is just a small attempt…
NLP has many better applications, such as language translation, chatbots, and more specific and complex analysis of text documents. Most of today’s work is done using deep learning, particularly recurrent neural networks (RNNs) and long short-term memory (LSTMs) networks.
If you want to play more with NLP, checking out the spaCy documentation[2] and textacy documentation[3] is a great starting point! You will see many examples of how to handle parsing text and extracting very useful information from it. Everything is fast and simple, and you can gain substantial value from it. It’s time to do bigger and better things with in-depth learning!
Reference Links:
[1] https://spacy.io/usage/linguistic-features#entity-types
[2] https://spacy.io/api/doc
[3] http://textacy.readthedocs.io/en/latest/
Original article link:
https://towardsdatascience.com/an-easy-introduction-to-natural-language-processing-b1e2801291c1
-END-
Special Knowledge
Get the complete collection of knowledge materials on 26 topics in the field of artificial intelligence and join the special knowledge AI service group: Welcome to scan the QR code to join the special knowledge AI knowledge community, get professional knowledge tutorial video materials and communicate and consult with experts!

Please log in to www.zhuanzhi.ai on PC or click on the original text to register and log in to get more AI knowledge materials!
Please add the special knowledge assistant WeChat (scan the QR code below to add), join the special knowledge theme group (please note the theme type: AI, NLP, CV, KG, etc.) for communication~
Please follow the special knowledge public account to obtain professional knowledge in artificial intelligence!
Click “Read the original text” to use special knowledge