
MLNLP community is a well-known machine learning and natural language processing community both domestically and internationally, covering NLP master’s and doctoral students, university teachers, and corporate researchers.
The vision of the community is to promote communication and progress between the academic and industrial circles of natural language processing and machine learning, especially for beginners.
Hello everyone, this is NewBeeNLP. Prompt Learning is making great strides in the NLP field, but what sparks will it create when applied to recommender systems?
Today, I will share a work from KDD 2022, which unifies the recommendation and dialogue sub-tasks into a prompt learning paradigm and utilizes knowledge-enhanced prompts based on fixed pre-trained language models to accomplish these two sub-tasks in a unified manner.
Source: Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD 2022)
Title: Towards Unified Conversational Recommender Systems via Knowledge-Enhanced Prompt Learning
Authors: Wang, Xiaolei and Zhou, Kun and Wen, Ji-Rong and Zhao, Wayne Xin
Link: https://dl.acm.org/doi/10.1145/3534678.3539382
Conversational Recommender Systems (hereinafter referred to as CRS) aim to actively elicit user preferences through natural language dialogue and recommend high-quality items. Typically, CRS consists of a recommendation module (for predicting the user’s preferred items) and a dialogue module (for generating appropriate responses). To develop an effective CRS, seamless integration of these two modules is necessary. Existing works either design semantic alignment strategies or share knowledge resources and representations between the two modules. However, these methods still rely on different architectures or techniques to develop these two modules, making effective module integration challenging.
To address this issue, this paper proposes a unified CRS model based on knowledge-enhanced prompt learning, called UniCRS. The proposed method unifies the recommendation and dialogue sub-tasks into the prompt learning paradigm and utilizes knowledge-enhanced prompts based on fixed pre-trained language models (hereinafter referred to as PLMs) to accomplish these two sub-tasks in a unified manner. In prompt design, this paper includes integrated knowledge representations, task-specific soft tokens, and dialogue contexts, which provide sufficient contextual information to adapt the PLM to CRS tasks. Furthermore, for the recommendation sub-task, this paper also incorporates generated response templates as an important component of the prompts to enhance information interaction between the two sub-tasks. Extensive experiments on two public CRS datasets demonstrate the effectiveness of the proposed method. The code for this paper is publicly available at the following link: https://github.com/RUCAIBox/UniCRS.
The main contributions of this paper are:
-
To the best of our knowledge, this is the first time a unified CRS has been developed in a general prompt learning manner.
-
This method formulates the sub-tasks of CRS into a unified prompt learning form and designs specific task prompts with corresponding optimization methods.
-
Extensive experiments on two public CRS datasets demonstrate the effectiveness of this method in recommendation and dialogue tasks.
This paper proposes a unified CRS method, namely, knowledge-enhanced prompt learning based on PLMs, referred to as UniCRS. This paper first outlines the proposed method, then discusses how to integrate semantics from words and entities as part of the prompts, and finally introduces the knowledge-enhanced prompt methods for CRS tasks. The overall architecture of the proposed model is shown in Figure 1.
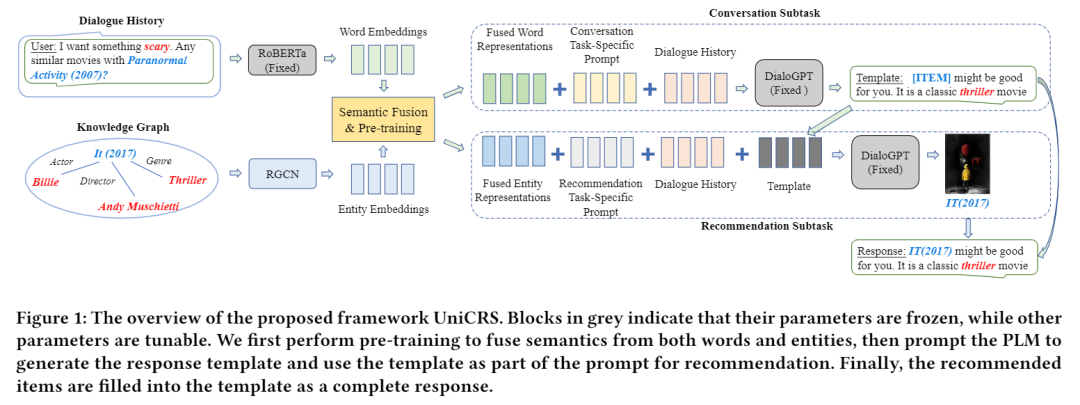
Semantic Fusion for Prompt Learning
Since DialoGPT is pre-trained on general dialogue corpora, it lacks specific capabilities for CRS tasks and cannot be used directly. Based on previous research, this paper integrates knowledge graphs (KGs) as task-specific knowledge resources, as they provide useful knowledge about entities and items mentioned in the dialogue. However, a significant semantic gap exists between the semantic space of dialogues and KGs. This paper requires first merging the two semantic spaces for effective knowledge alignment and enrichment. Specifically, the goal of this step is to fuse token and entity embeddings from different encoders.
Encoding Word Tokens and Knowledge Graph Entities Given the dialogue history 𝐶, this paper first encodes the dialogue words and KG entities appearing in 𝐶 into word embeddings and entity embeddings, respectively. To complement the base PLM DialoGPT (a unidirectional decoder), this paper utilizes another fixed PLM RoBERTa (a bidirectional encoder) to derive word embeddings. The contextual token representations derived from the fixed encoder RoBERTa are concatenated into a word embedding matrix, i.e.
Word-Entity Semantic Fusion To bridge the semantic gap between words and entities, this paper uses a cross-interaction mechanism to relate the two semantic representations through bilinear transformations:
Pre-trained Fusion Module For this pre-trained task, this paper simply utilizes the context sequence enhanced by prompts to predict the entities appearing in the responses. The probability formula for predicting entities is:
Task-Specific Prompt Design
Although the base PLM is fixed and does not require fine-tuning, this paper can design specific prompts to adapt it to different sub-tasks of CRS. For each sub-task (recommendation or dialogue), the main design of the prompts consists of three parts: dialogue history, task-specific soft tokens, and integrated knowledge representations. For the recommendation, this paper further incorporates generated response templates as additional prompt tokens. Next, this paper describes the specific prompt designs for these two sub-tasks in detail.
Prompt for Generating Responses The prompt for response generation consists of the original dialogue history (in the form of word tokens 𝐶), specific soft tokens for generation (in the form of latent vectors), and the fused text context (in the form of latent vectors). Formally represented as:
In the above prompt design, the only adjustable parameters are the pre-trained fused text representations and the task-specific soft tokens. They are represented as. This paper derives the prediction loss for learning from the context enhanced by prompts, which takes the form of:

Prompt for Item Recommendation The prompt for item recommendation consists of the original dialogue history 𝐶 (in the form of word tokens), specific soft tokens for recommendation (in the form of latent vectors), fused entity context (in the form of latent vectors), and response template 𝑆 (in the form of word tokens), formally described as:
This paper utilizes the context enhanced by prompts to derive the prediction loss for learning, which takes the form of:
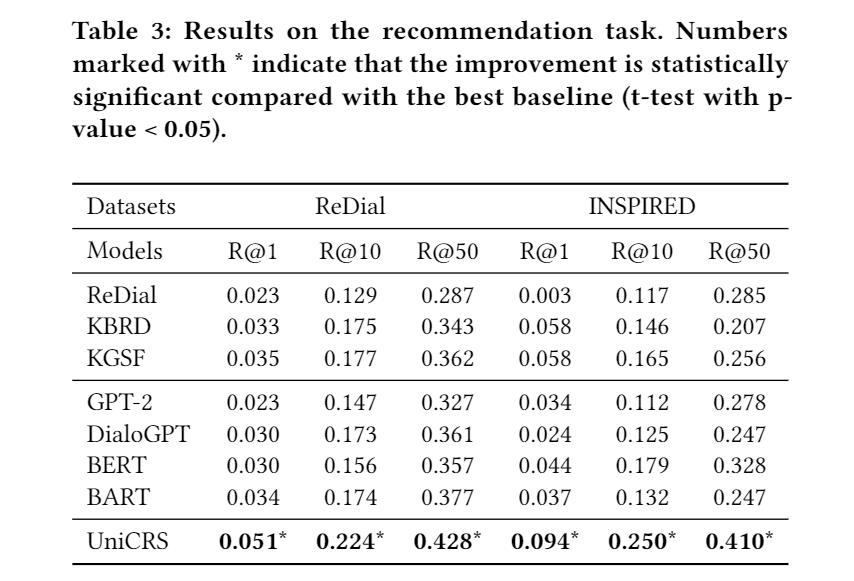
Table 3 shows the performance of different methods on the recommendation task. For these three CRS methods, the performance order across all datasets is consistent, i.e., KGSF > KBRD > ReDial. Both KGSF and KBRD incorporate external KGs into their recommendation modules, which enrich the semantics of the entities mentioned in the dialogue history to better capture user intentions and preferences. Additionally, KGSF also employs mutual information maximization methods to further improve entity representations. For the four pre-trained models, it can be seen that BERT and BART outperform GPT-2 and DialoGPT. The reason may be that GPT-2 and DialoGPT are based on unidirectional Transformer architectures, which limit their dialogue understanding capabilities. Furthermore, it can be seen that BART achieves considerable performance on the ReDial dataset, even outperforming BERT. This indicates that BART can also understand the dialogue semantics of recommendation tasks well. Finally, it can be observed that the proposed model significantly outperforms all baselines. This paper utilizes specifically designed prompts to guide the base PLM and enhances prompt quality through pre-training tasks combined with KGs.
The results are shown in Figure 2. It can be seen that removing any component leads to a decline in performance. This indicates that all components in the proposed model contribute to improving the performance of the recommendation task. Among these, the performance drop is the largest when the pre-training task in the semantic fusion module is removed. This demonstrates that such a pre-training process is crucial in the proposed method, as it can learn the semantic relevance between entities and tokens, thereby enforcing the semantic consistency of entity semantics with the base PLM.

This paper presents the evaluation results of automatic metrics for different methods in Table 4. It can be seen that, among the three CRS methods, the performance order is also consistent with KGSF > KBRD > ReDial. This is because KBRD uses KG-based token bias to enhance the probability of low-frequency tokens, while KGSF designs KG-enhanced cross-attention layers to improve the feature interaction of entities and tokens during generation. Additionally, it can be observed that the performance of the PLM outperforms the three CRS methods. Finally, compared to these baselines, the proposed model consistently performs better. In this method, the paper performs semantic fusion and rapid pre-training. In this way, task-specific knowledge can be effectively injected into the PLM, helping generate information-rich responses. Furthermore, since only a few parameters are adjusted compared to full parameter fine-tuning, the method can alleviate the catastrophic forgetting problem of the PLM.

This paper proposes a novel conversational recommendation model called UniCRS, which accomplishes the recommendation and dialogue sub-tasks in a unified manner. First, using a fixed PLM (i.e., DialoGPT) as the backbone, this paper utilizes the knowledge-enhanced prompt learning paradigm to reformulate these two sub-tasks. Then, this paper designs multiple effective prompts to support these two sub-tasks, including integrated knowledge representations generated by the pre-trained semantic fusion module, task-specific soft tokens, and dialogue contexts. This paper also leverages response templates generated from the dialogue sub-task as an important part of the prompts to enhance the recommendation sub-task. The aforementioned prompt designs can provide sufficient information about dialogue contexts, task instructions, and background knowledge. By optimizing only these prompts, the model can effectively accomplish the recommendation and dialogue sub-tasks. Extensive experimental results indicate that the proposed method outperforms several competitive CRS and PLM methods, especially when only limited training data is available.
In the future, this paper will apply the model discussed to more complex scenarios, such as topic-guided CRS and multimodal CRS. This paper will also consider designing more effective prompt pre-training strategies to quickly adapt to various CRS scenarios.
Technical Group Invitation

△ Long press to add the assistant
Scan the QR code to add the assistant on WeChat
Please note: Name-School/Company-Research Direction
(e.g.: Xiaozhang-Harbin Institute of Technology-Dialogue Systems)
to apply to join the Natural Language Processing/Pytorch technical group
About Us
MLNLP community is a grassroots academic community jointly built by machine learning and natural language processing scholars from both domestic and international backgrounds. It has now developed into a well-known machine learning and natural language processing community, aiming to promote progress between the academic and industrial circles of machine learning and natural language processing and enthusiasts.
The community can provide an open communication platform for related practitioners’ further studies, employment, and research. Everyone is welcome to follow and join us.

