Click the “Beginner Learning Vision” above and select “Star” public account
Heavyweight content delivered at the first time

This article is reproduced from I Love Computer Vision, originally published in a Chinese science and technology journal.The author referenced 77 influential and recent papers, providing a detailed overview of the systems, algorithms, data, and performance comparisons in image text detection and recognition, which will be helpful for friends engaged in related research and development.
Overview of Image Text Recognition Technologies
Niu Xiaoming
(1. Sichuan Changhong Electric Co., Ltd., Software and Service Center, Mianyang 621000)
Abstract: This article provides a summary introduction to the technologies involved in image text recognition. First, it introduces the background knowledge of image text recognition, including application fields, technical difficulties and challenges, and system implementation processes; secondly, it introduces the preprocessing methods and processes of image text recognition technology, including rotation correction, line detection, feature matching, character contour extraction and segmentation, and OCR recognition processes; next, it introduces the basic networks and detection networks commonly used in feature extraction during the image text recognition process, as well as their scene adaptation problems; then, it introduces various deep learning networks for image text detection, deep learning networks for image text recognition, and end-to-end deep learning networks for image text detection and recognition that have emerged in recent years, analyzing the network architecture, algorithm ideas, and characteristics of various detection and recognition networks; finally, it introduces publicly available training and testing datasets for image text recognition and performance comparisons of different algorithms.
1 Introduction
OCR (Optical Character Recognition) traditionally refers to the processing and analysis of images to recognize the text information in the images; Scene Text Recognition (STR) refers to recognizing text information in natural scene images. Many people define OCR technology as a broad category of all image text detection and recognition technologies (referred to as image text recognition technology), which includes both traditional OCR recognition technology and natural scene text recognition technology.
OCR images may exhibit rotation, curvature, folding, incompleteness, and blurriness; the text regions in the images may also undergo deformation; additionally, document images mostly belong to regular tabular types of receipts; therefore, to achieve better text detection and recognition results, a large and effective preprocessing process is required: including image denoising, image rotation correction, line detection, feature matching, text contour extraction, and segmentation.
The training process for traditional deep learning OCR includes two models: a text detection model and a text recognition model; during the inference phase, these two models are combined to construct a complete image text recognition system. In recent years, end-to-end image text detection and recognition networks have emerged: during the training phase, the model’s input includes the training image, the text content in the image, and the coordinates corresponding to the text; during the inference phase, the original image is directly predicted for text content information by the end-to-end model. Compared with traditional deep learning methods, this method is simpler to train, more efficient, and has lower resource overhead for online deployment.
Image text recognition technology involves technologies from both computer vision processing and natural language processing fields; it requires image processing methods to extract the location of text areas in images and recognize local image blocks as text, while also relying on natural language processing technology to output the recognized text in a structured manner. It has a wide range of application scenarios: applied to the recognition of receipts, license plates, identity cards, bank cards, business cards, express delivery slips, business licenses, etc.
1.1 Image Text Recognition Preprocessing Technologies and Processes
1.1.1 Image Text Recognition Preprocessing Technologies
Image text recognition preprocessing technologies include image segmentation technology, image rotation correction technology, line detection technology, image matching technology, text contour extraction, and local segmentation technologies.
1.1.1 Image Rotation Correction
Images obtained through printer scanning or mobile phone photography may be rotated; for example, in the case of tabular receipt images, rotated receipt images can severely affect the row and column positioning of the receipt image layout, thereby increasing the difficulty of receipt layout analysis. Therefore, applying effective rotation correction methods to receipt images can significantly enhance the performance of receipt recognition systems.
1.1.2 Line Detection
The accuracy of line detection is crucial for OCR positioning of tabular receipts, and commonly used methods include: projection transformation, Hough transformation, chain code, run-length encoding, etc.; among them, the most practical algorithms are the Hough transformation algorithm and its improved methods. Additionally, vectorization algorithms also have broad applications in the line detection process.
1.1.3 Image Matching
Image feature matching methods can be applied to character localization, seal detection, etc.; with the help of image matching algorithms, the location of the ROI (region of interest) can be retrieved, thus indirectly locating the corresponding character position.
Many matching methods have been proposed both domestically and internationally to improve matching speed and performance; for example, cross-correlation detection image matching algorithms, similarity measurement matching methods, adaptive mapping matching methods, scale-invariant feature transform (SIFT) matching algorithms, and image matching methods based on genetic algorithms.
1.1.4 Character Contour Extraction and Segmentation
Before character recognition, characters need to be completely segmented; commonly used character segmentation methods mainly include: threshold segmentation algorithms, morphological segmentation algorithms, and model-based segmentation algorithms. The printed fonts of receipts have their own characteristics, and general character segmentation algorithms first perform vertical projection, then analyze character contours, and finally segment based on predetermined character spacing or size; mainly divided into two categories: row-column segmentation methods and isolated image segmentation methods.
1.2 Image Text Detection and Recognition Processes
1.2.1 Traditional OCR Detection and Recognition Processes
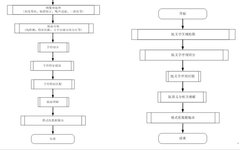
The traditional OCR recognition process mainly includes the following steps: image preprocessing (noise filtering, grayscale transformation, image rotation correction, binarization, etc.), layout analysis (table line detection, feature matching of key areas, text region segmentation, and line segmentation, etc.), character segmentation, character feature extraction, character feature matching, layout understanding, and formatted data output, as shown in Figure 1.

Figure 1 Traditional OCR Recognition Process Diagram Figure 2 Deep Learning OCR Recognition Process Diagram
1.2.2 Deep Learning OCR Detection and Recognition Processes
The deep learning-based OCR recognition process mainly includes the following steps: deep learning text region detection, deep learning text sequence segmentation, deep learning text sequence recognition, deep learning semantic analysis and understanding, and formatted data output processes; where DL refers to Deep Learning, as shown in Figure 2.
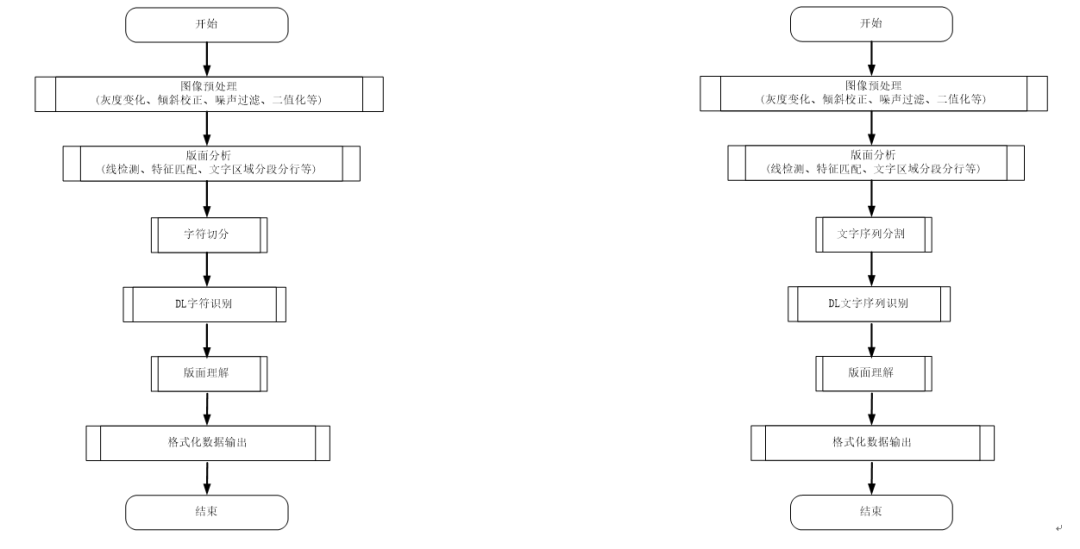 (a) (b)
(a) (b)
Figure 3 Hybrid OCR Recognition Process Diagram
1.2.3 Hybrid OCR Detection and Recognition Processes
This section introduces two process modes for hybrid OCR recognition: the preprocessing part and the character or sequence segmentation part adopt traditional algorithms, while character recognition and sequence recognition adopt deep learning methods, as shown in Figure 3. In the image preprocessing stage, both sub-figures (a) and (b) use traditional methods; in recognition, deep learning methods are used, but (a) is for single character recognition, while (b) is for recognizing the entire text sequence.
2 Deep Learning-Based Image Text Detection and Recognition Technologies
2.1 General Detection and Transformation Networks
The basic networks used for feature extraction modules in image text recognition tasks can originate from general scene image classification models or from specific scene dedicated network models. The following introduces several deep learning-based general image detection networks and image transformation networks.
2.1.1 Faster RCNN Network
Faster RCNN is a commonly used detection network framework, where the detection result is to find the compact bounding box of the detected object; as shown in Figure 4; Fast RCNN integrates feature extraction, region proposal networks, target region pooling, and target classification into one network, greatly improving the speed of object detection. It introduces a region proposal network on the basis of the Fast RCNN detection framework to quickly generate multiple candidate region reference boxes, and through the target region pooling layer, constructs normalized fixed-size region features for multi-size reference boxes; using shared convolutional networks, it simultaneously inputs feature maps to the aforementioned region proposal networks and target region pooling layers, reducing the parameter and computation of the convolutional layers.
2.1.2 SSD Network
SSD (Single Shot MultiBox Detector) is a fully convolutional object detection algorithm proposed in 2016; compared to the Faster RCNN network, its speed advantage is significant. SSD is a one-stage algorithm that can directly predict the bounding boxes and scores of detected objects. During the detection process, the SSD algorithm uses multi-scale methods for detection, constructing multiple default boxes on feature maps of different scales, and then performing regression and classification; finally, it uses non-maximum suppression methods to obtain the final detection results.
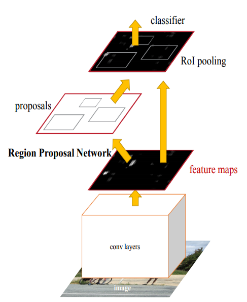
Figure 4 Faster R-CNN Network

Figure 5 SSD Network
2.1.3 FCN Network
Fully Convolutional Network (FCN), initially used for semantic segmentation, removes the fully connected (fc) layers. The advantage of FC is to utilize upsampling operations, such as deconvolution and up-pooling, to change the size of the feature matrix to be close to the original image size; then, it performs category prediction on each pixel position to obtain more accurate object boundaries. Detection networks based on fully convolutional networks predict object bounding boxes directly from high-resolution feature maps without undergoing candidate region regression.
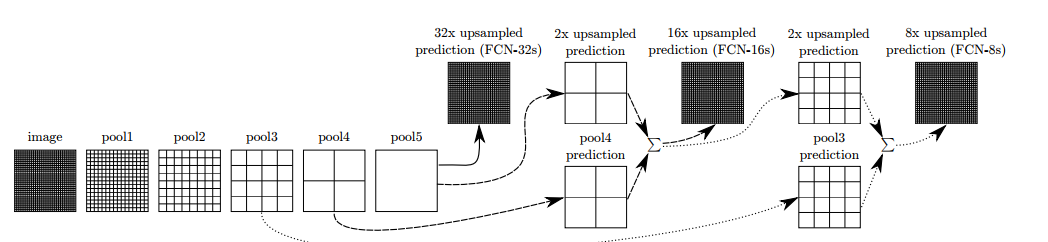
Figure 6 FCN Network
2.1.4 STN Network
Spatial Transformer Networks (STN) serve to correct the spatial position of input feature maps to obtain output feature maps; it allows spatial transformation operations on data within the network, such as translation, scaling, rotation, and distortion, supporting end-to-end model training. The STN network consists of three parts: localization network, grid generator, and sampler.

Figure 7 STN Network
2.2 Image Text Detection Networks
The goal of image text detection is to find the regions containing text in images. Directly using commonly used deep learning detection networks (such as Faster-RCNN, SSD, YOLO, etc.) for image text detection does not yield ideal results; the main reasons are as follows: text lines have directionality; the information amount of object bounding box descriptions is insufficient; artistic fonts may use curved text lines; handwritten fonts have many variations, etc.
In response to these issues, various deep learning-based technical solutions have been proposed in recent years. They have modified existing detection networks from the following dimensions: region proposal networks, multi-target collaborative training, feature extraction, non-maximum suppression, semi-supervised learning, etc.; through these modifications, the accuracy of image text detection has greatly improved.
For example: the CTPN network uses the BLSTM module to extract the contextual relationships between characters in image text blocks to improve the accuracy of text block recognition. The RRPN network incorporates rotation factors into the classic region proposal network, describing the ground truth of an image text area with a five-tuple rotation bounding box; during the training phase, it first generates inclined candidate boxes (including direction angles), and then learns the text direction angle during the bounding box regression process. The DMPNet network uses quadrilaterals (non-rectangular) to label text boxes; the SegLink network first segments each word into smaller, directional, and more easily detectable text blocks, and then connects the small text blocks into words using neighboring connection methods. The TextBoxes network adjusts the aspect ratio of the text region reference box and changes the convolution kernels of the feature layers to rectangular shapes, thus better suited for detecting elongated text lines; the FTSN network uses the Mask-NMS method to replace the traditional BBOX non-maximum suppression algorithm to filter candidate boxes; the WordSup network employs a semi-supervised learning strategy.
Below are several text detection-specific networks that have emerged in recent years.
2.2.1 CTPN Network
CTPN is currently one of the most widely used open-source image text detection networks, capable of detecting horizontal or slightly inclined image text lines. Text lines are treated as a character sequence rather than individual independent targets. The characters in the character sequence have contextual relationships; the detection network learns this contextual statistical law in the training phase, thereby improving the prediction accuracy of text blocks.

Figure 8 CTPN Network
2.2.2 RRPN Network
The RRPN (Rotation Region Proposal Networks) incorporates rotation factors into the classic region proposal network (such as Faster RCNN). In this network, the ground truth of an image text area is described with a five-tuple bounding box: the geometric center coordinates of the bounding box, the short edge of the bounding box, the long edge of the bounding box, and the direction angle. During the training phase, inclined candidate boxes (including direction angles) are first generated, and then the text direction angle is learned during the bounding box regression process.

Figure 9 RRPN Text Detection Process
2.2.3 SegLink Network
In the SegLink network, each word is first segmented into smaller, directional, and more easily detectable text blocks, and then the small text blocks are connected into words using neighboring connection methods. This method is suitable for recognizing text lines with directionality and has a large range of length variations; compared to the CTPN image text detection network, the SegLink network has faster inference speed.
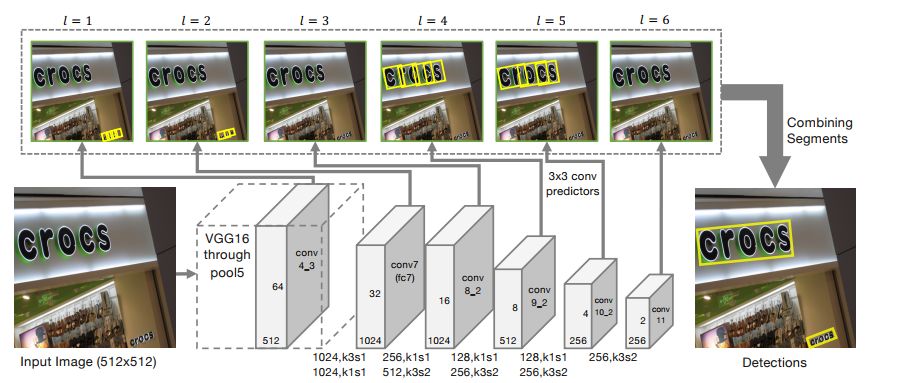
Figure 10 SegLink Network
2.2.4 IncepText Network
To improve the detection accuracy of large-scale, deformed image text in complex scenes, the IncepText network proposes a deformation-based PSROI pooling module for better addressing the above issues. The specific network architecture is as follows:
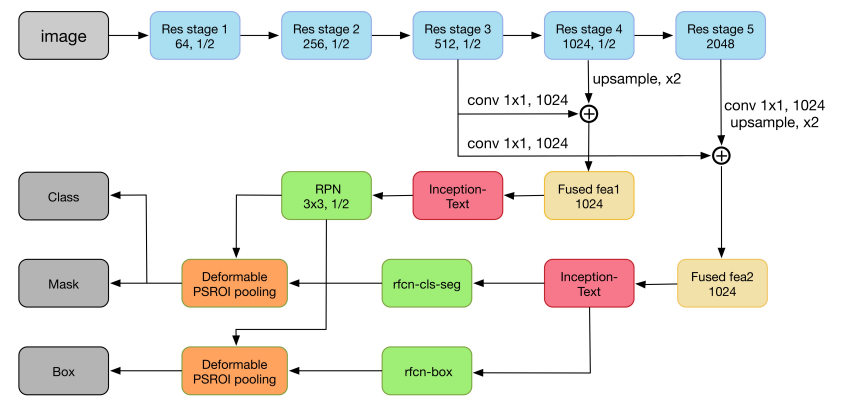
Figure 11 IncepText Network
Subsequently, in end-to-end image text detection, Yuchen Dai, Yuliang Liu, Xinyu Zhou, Dan Deng, and others proposed the FTSN network, DMPNet network, EAST network, PixelLink network, which support inclined text detection; in addition, Han Hu and others proposed the WordSup network, which is applied to mathematical formula image text recognition, deformation, and irregular text recognition.
2.3 Image Text Recognition Networks
Image text recognition networks recognize the segmented text region image blocks as text content, and commonly used image text recognition networks include: CRNN network, RARE network, ESIR network.
2.3.1 CRNN Network
CRNN (Convolutional Recurrent Neural Network) is currently a popular image text recognition network that can recognize relatively long, variable text sequences. The feature extraction layer includes CNN and BLSTM, allowing for end-to-end joint training. It effectively improves the accuracy of image text recognition by learning the contextual relationships between character images with the help of BLSTM and CTC networks, as shown in Figure 12.

Figure 12 CRNN Network Framework Diagram
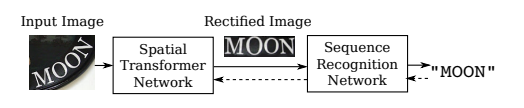
Figure 13 RARE Network System Block Diagram
2.3.2 RARE Network
RARE (Robust text recognizer with Automatic Rectification) network performs relatively well when recognizing deformed image text. As shown in Figure 12, during the model inference process, the input image undergoes a spatial transformation network to obtain a corrected image; then, the corrected image enters the sequence recognition network to finally obtain the predicted text results.
2.3.3 ESIR Network
ESIR end-to-end scene text recognition includes two parts: an iterative text correction network and a sequence recognition network.

Figure 14 ESIR Network Framework Diagram
2.4 End-to-End Image Text Detection and Recognition Networks
The goal of end-to-end image text detection and recognition is to directly locate and recognize all text content from images in a one-stop manner; in recent years, commonly used end-to-end image text detection and recognition networks include FOTS network, STN-OCR network, Integrated Framework, and MORAN network.
2.4.1 FOTS Network
FOTS (Fast Oriented Text Spotting) is an end-to-end learning network where image text detection and recognition are trained simultaneously. The detection and recognition share convolutional feature layers, saving computation time and learning more image features. It introduces rotation regions of interest, supporting the recognition of inclined texts, as shown in Figure 15.

Figure 15 FOTS Network System Block Diagram
2.4.2 STN-OCR Network
STN-OCR is an end-to-end image text detection and recognition network. The detection process embeds a spatial transformation network to perform affine transformations on the input image. With this spatial transformation network, the detected text blocks are rotated, scaled, and skewed, equivalent to data augmentation, thereby improving the accuracy of the recognition phase. STN-OCR is a semi-supervised learning model that only requires labeling the content of the text without needing to label the position information of the text.
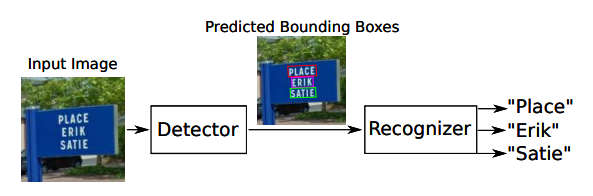
Figure 16 STN-OCR Network System Block Diagram
2.4.3 Integrated Network
The integrated end-to-end text detection and recognition network merges the detection model and recognition model into a continuous end-to-end training model through model parameter sharing; through parameter sharing, it not only improves the efficiency of detection and recognition but also enhances the accuracy of end-to-end text detection and recognition. The overall process framework is shown in the figure below:

Figure 17 Integrated Network System Block Diagram
2.4.4 MORAN Network
MORAN text recognition end-to-end network consists of a correction subnet MORN and a recognition subnet ASRN; MORN designs a novel pixel-level weak supervision learning mechanism for irregular text shape correction, greatly reducing the difficulty of recognizing irregular text. MORN and ASRN can undergo end-to-end joint learning, and the training process does not require supervision information for labeled character positions or pixel-level segmentation, greatly simplifying the training process of the network.
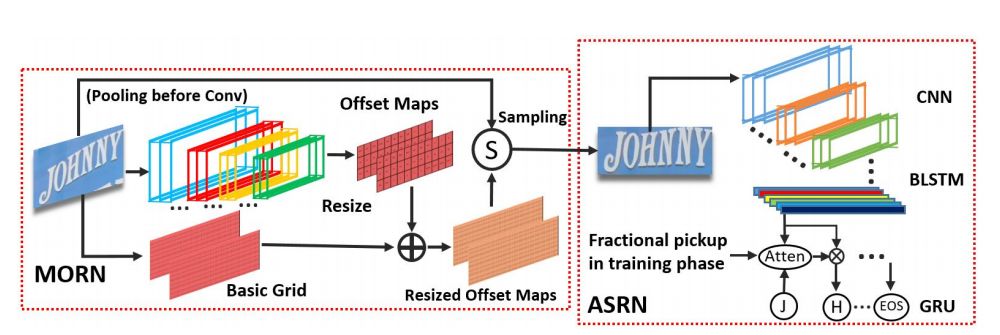
Figure 18 MORAN Network System Block Diagram
2.4.5 AON Network
AON (Arbitrary Orientation Network) effectively recognizes regular and irregular text images in natural scenes. The AON network can extract scene text features and character localization information from four directions, designing a filter gate (FG) to fuse four directional text features, integrating the AON network, filter gate, and Attention-Based decoding into the character recognition framework, making the entire network an end-to-end model. The specific model framework is as follows:
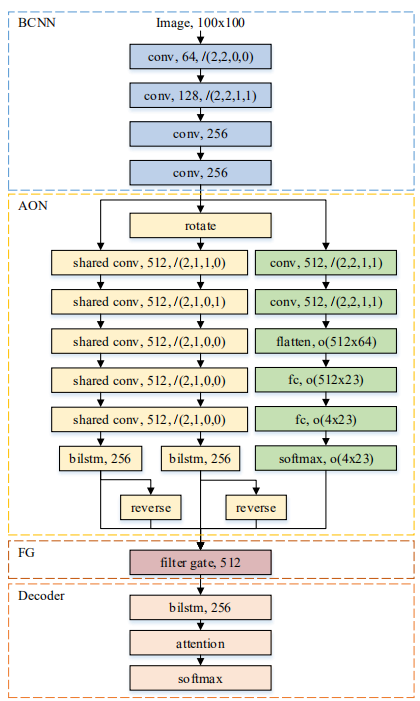
Figure 19 AON Network System Block Diagram
2.4.6 Unconstrained End-to-End Network
The Unconstrained end-to-end network effectively recognizes text images of any shape. The Unconstrained end-to-end network includes a Mask R-CNN detection network and a Seq2Seq (sequence-to-sequence) Attention-Based decoding network; it reduces the detection of text of any shape to an instance segmentation problem, then uses an Attention-Based model to decode the text region of any shape without prior correction of the text region. The specific network structure is as follows:

Figure 20 Unconstrained End-to-End Network System Block Diagram
Subsequently, Anh Duc Le and others also proposed an end-to-end text recognition method, where the detection process uses the CTPN network and the recognition process uses the AED network, achieving good results in receipt OCR recognition. Mohammad Reza Sarshogh and others proposed a multi-task end-to-end recognition network that can simultaneously perform text detection, text recognition, and text classification.
3 Datasets and Performance Comparisons
This section lists publicly available large-scale image text recognition training and testing datasets as well as performance comparisons of different detection networks and end-to-end recognition networks.
3.1 Datasets
Large-scale image text recognition training and testing datasets include: CTW (Chinese Text in the Wild) dataset, RCTW-17 (Reading Chinese Text in the Wild) dataset, ICPR MWI 2018 Challenge dataset, Total-Text dataset, Google FSNS (Google Street View Text dataset), COCO-TEXT dataset, Synthetic Data for Text Localization natural scene text data, Synthetic Word Dataset, Caffe-ocr Chinese synthetic data, ICDAR15 dataset, SVT-Perspective dataset, and CUTE80 dataset.
3.2 Performance Comparisons
Tables 1 and 2 respectively list the performance comparisons of different recognition methods on the ICDAR15 dataset, SVT-Perspective dataset, and CUTE80 dataset; where Table 1 lists the recognition performance comparisons on regular datasets, and Table 2 lists the recognition performance comparisons on irregular datasets. Experimental conditions: hardware uses Intel Xeon(R) E5-2650 CPU, NVIDIA Tesla P40 GPU; software configuration is CUDA8 and CUDNN V7.
In Tables 1 and 2, “50” and “1k” indicate comparisons using image texts containing “50” and “1k” character sequences; “Full” indicates comparisons using all character sequences in the dataset; “None” indicates no constraints.
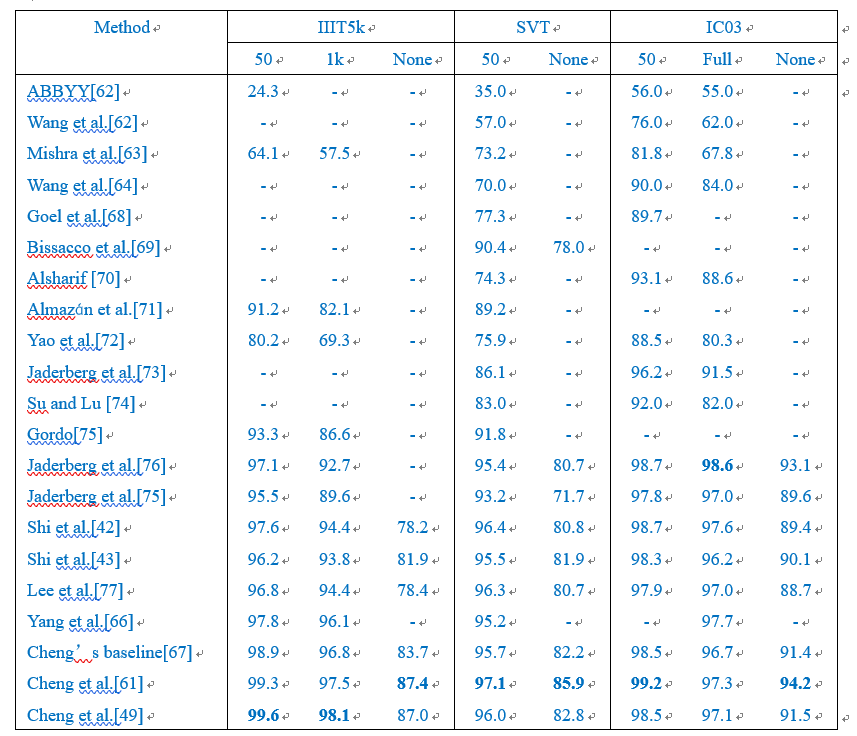
Table 1 Performance Comparison of Image Text Recognition on Regular Datasets

Table 2 Performance Comparison of Image Text Recognition on Irregular Datasets
From the performance comparisons of different image text recognition algorithms in Tables 1 and 2, it can be seen that with the development of deep learning algorithms in recent years, image text recognition performance has significantly improved. On irregular datasets, algorithms such as Shi et al., Yang et al., Cheng et al., and others have achieved good results on the SVT-Perspective dataset; additionally, Cheng et al. have relatively good recognition performance on the CT80 and IC15 datasets, while Yang et al. performed relatively well in the “None” testing mode on the SVT-Perspective dataset. On regular datasets, algorithms such as Gordo, Jaderberg et al., Shi et al., Lee et al., and others have achieved good results across different datasets.
4 Conclusion
Image text detection and recognition technology can be applied in banking, finance, industry, and other fields. Traditional image text data is recorded manually, which is time-consuming; utilizing image text recognition technology to convert images into text and output structured data can greatly save labor and improve efficiency. This article provides a comprehensive introduction to commonly used technologies in image text recognition from a system perspective: first, it introduces the application background of image text recognition; secondly, it introduces the commonly used feature extraction networks and detection networks in the image text recognition process, as well as their limitations in the application field; thirdly, it introduces various image text detection networks, image text recognition networks, and end-to-end image text detection and recognition networks that have emerged in recent years, and finally introduces large publicly available datasets in the field of image text recognition and performance comparisons of different algorithms for image text detection and recognition.
