This article is about 11,000 words long and is recommended to be read in over 10 minutes.
This is a survey overview of large models for time series and spatio-temporal data.
Time-related data, especially time series and spatio-temporal data, are ubiquitous in real-world applications. These data capture measurements of dynamic systems and are generated in large quantities by physical and virtual sensors. Analyzing these types of data is crucial for leveraging the rich information they contain, which benefits various downstream tasks. In recent years, advances in large language models and other foundational models have led to an increasing use of these models in time series and spatio-temporal data mining. These methods not only enhance pattern recognition and reasoning capabilities across multiple domains but also lay the groundwork for artificial general intelligence that can understand and handle common time data.
This article presents a survey overview of large models for time series and spatio-temporal data. In the paper, the authors emphasize the importance of analyzing these data types and the potential benefits for various downstream tasks. They categorize the existing literature into two main categories: large models for time series analysis (LM4TS) and spatio-temporal data mining (LM4STD). Additionally, the authors provide a comprehensive collection of resources, including datasets, model assets, and tools, categorized by mainstream applications. The paper emphasizes the latest research advancements centered around large models in time series and spatio-temporal data, as well as future research opportunities in this field.
Paper link: https://arxiv.org/abs/2310.10196
Large models have achieved remarkable results in natural language processing, computer vision, and other fields, but their application in traditional time series and spatio-temporal data analysis methods is relatively limited.
Despite recent efforts to pave the way for large models for time series and spatio-temporal data, the lack of large-scale datasets remains a significant barrier in many cases. Nevertheless, we have witnessed a sharp increase in the number of successful attempts across different tasks and domains, which fully demonstrates the untapped potential of large models in time series and spatio-temporal data analysis.
In this article, the authors address this need by providing a unified, comprehensive, and up-to-date overview specifically focused on large models for time series and spatio-temporal data analysis, including different types of data, scopes, application areas, and representative tasks involving LLMs and PFMs.
The contributions of this overview are summarized as follows:
-
The first comprehensive and up-to-date survey
-
A unified and structured taxonomy
-
A rich compilation of resources
-
Future research opportunities
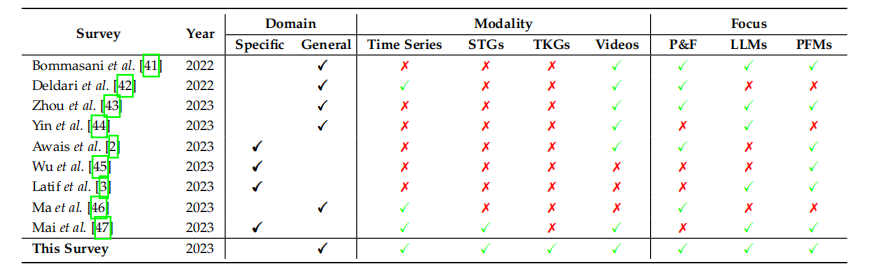
This survey is more comprehensive than others, covering multiple fields and data modalities, while also delving deeply into the current hottest large models and pre-training strategies. It provides readers with a broader perspective, aiding in a more comprehensive understanding of the latest research advancements in fields such as time series and spatio-temporal data.
The main work of this article focuses on reviewing recent progress made with large models in addressing time series and spatio-temporal data tasks. Specifically, the authors focus on two mainstreams within large models: large language models and pre-trained foundational models. Below is the authors’ introduction to these two models and their related content:
01 Large Language Models (LLMs)
Language modeling is fundamental to many natural language processing tasks, and large language models (LLMs) were originally intended to enhance the performance of language modeling. Compared to traditional neural language models (NLMs) and small pre-trained language models (PLMs), LLMs are known for their sudden capabilities and contextual learning abilities in solving various complex tasks, reshaping how we use AI.
With the development of multimodal large language models (MLLMs), the downstream tasks of LLMs have far exceeded the traditional natural language scope, which small PLMs cannot easily solve. In recent uses of LLMs for modeling time series and spatio-temporal data, we categorize them into two main types: visible embedding LLMs and invisible embedding LLMs. The former are typically open-source with publicly accessible internal states, such as BLOOM, Llama, Alpaca, Vicuna, and Falcon, which can usually be fine-tuned for different target tasks and show promising few-shot and zero-shot capabilities without additional retraining. The latter are generally closed-source with no publicly accessible internal states, such as PaLM, ChatGPT1, and GPT-4, which typically infer through prompts in API calls.
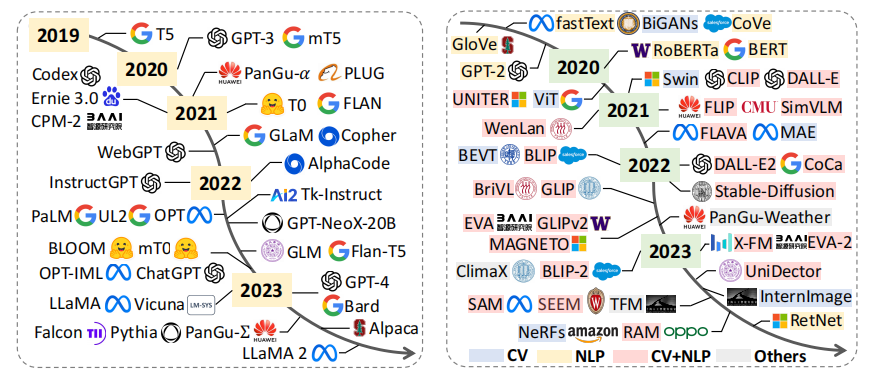
The following diagram provides a brief roadmap of large models, outlining their development history and research focus, clearly revealing the connections and differences between large language models and pre-trained foundational models.
After witnessing the tremendous success of multimodal large language models (MLLMs), one of the authors’ main research interests is how to adjust LLMs to solve time series and spatio-temporal data analysis tasks. In the existing literature, this is often achieved through multimodal reuse or API-based prompting.
This approach is typically used to activate the task-related functionalities of visible embedding LLMs by aligning different modalities in target and pre-training (source) tasks. This is closely related to LLMs’ fine-tuning, such as adapter tuning and low-rank adaptation, and model reprogramming, depending on whether the LLMs are fine-tuned or frozen during the adaptation process. This method allows for deeper utilization of LLMs’ internal states and task-related functionalities but may require more computational resources and access.
On the other hand, this method is more direct, wrapping the target modality into natural language prompts and inputting them into LLMs for generative inference. This is similar to the black-box tuning of language model as a service (LMaaS). Evidence suggests that this approach is applicable across different target tasks in multiple domains and shows promising results, including learning for time series and spatio-temporal data.
02 Pre-trained Foundational Models
Pre-trained foundational models refer to those large-scale pre-trained models that can adapt to solve various downstream tasks. Broadly speaking, LLMs (and MLLMs) also belong to PFMs, but they are more commonly used for natural language-oriented tasks. PFMs constitute a broader category of models characterized by their sudden capabilities and homogeneity, effectively solving different tasks and integrating methodologies for building AI systems, which are significantly different from task-specific models.
The capabilities of PFMs are primarily manifested in three key dimensions: modality bridging, reasoning and planning, and interaction.
-
Modality Bridging: Involves multimodal models, such as visual-language models like MLLMs, which have achieved significant results in unifying language and visual modalities. For example, CLIP was initially proposed to bridge the gap between images and text, and SAM further expanded the concept of text prompts to visual prompts. Other recent works, such as NExT-GPT, have further pushed the boundaries, even allowing bridging across various modalities.
-
Reasoning and Planning: PFMs are also designed for complex reasoning and planning tasks. These models can learn how to reason and solve complex problems from large amounts of pre-training data.
-
Interaction: These models also have the ability to interact with human users in a more natural way, providing a better user experience.
In the real world, data is inherently multimodal; for example, clinical medicine often involves time series and spatio-temporal data. This has also spurred recent research interest in multimodal time series and spatio-temporal data. Although this research is still in its early development stages, it represents an important and promising branch of PFMs.
The second aspect highlights the reasoning and planning capabilities of PFMs. Typical examples in LLMs include CoT, ToT, and GoT, as well as task planning agents. These models possess the ability to perform logical reasoning and make plans across different tasks and contexts.
The final aspect defines the interaction capabilities of PFMs, including actions and communication. Interaction capabilities enable PFMs to communicate information in real-time with users or other systems and take corresponding actions based on needs. In this survey, the authors primarily focus on PFMs used for time series and spatio-temporal data. Most of these models are still in early development stages and have not yet reached the aforementioned second and third aspects. For more details on PFMs, we recommend readers refer to.
In summary, as a cutting-edge AI technology, PFMs’ modality bridging, reasoning planning, and interaction capabilities provide new possibilities for solving complex problems. However, research on PFMs for time series and spatio-temporal data is still in its infancy, with significant room for future development. As technology continues to advance, we look forward to seeing more innovations and breakthroughs that will drive the development of the field of artificial intelligence.
03 Time Series and Spatio-Temporal Data
Time series and spatio-temporal data, as a category of time-related data, appear as foundational data in countless real-world applications. Time series are typically defined as sequences of data points arranged in chronological order. These sequences can be univariate or multivariate. For example, daily temperature readings in a city would form a univariate time series, while combining daily temperature and humidity data would create a multivariate time series.
-
Time Series Data: This is data arranged in chronological order, commonly used to analyze and predict changes in a phenomenon over time. Representative tasks include time series forecasting, anomaly detection, etc.
-
Spatio-Temporal Data: This type of data not only contains time information but also spatial information. They are widely used in geographically related research and applications. Representative tasks include spatio-temporal data interpolation, spatio-temporal forecasting, etc.
This field typically includes four main analysis tasks: forecasting, classification, anomaly detection, and imputation. In forecasting, the goal is to predict future values of the time series, which can be further divided into short-term and long-term forecasting based on the forecast horizon. In classification, the goal is to classify the input time series into different categories. Anomaly detection in time series can also be understood as a special classification task, where our goal is to identify anomalous time series from normal time series. In the imputation task, the goal is to fill in missing values in the time series.
2. Spatio-Temporal Graph Tasks
The main downstream task of spatio-temporal graphs is forecasting, which aims to predict future node features by referencing historical attributes and structural information. Typical examples include traffic forecasting and some on-demand services. Other common tasks include link prediction and node/graph classification, where link prediction aims to predict the existence of edges based on historical information, while node/graph classification aims to classify nodes or graphs into different categories.
3. Temporal Knowledge Graph Tasks
There are two important tasks in temporal knowledge graphs: completion and prediction. The former primarily aims to fill in missing relationships in the graph, while the latter focuses on predicting future relationships.
In the field of computer vision, video data contains several core tasks such as detection, annotation, prediction, and querying. The goal of detection is to identify specific objects or actions within the video. Annotation attempts to generate natural language descriptions for video content. Prediction involves forecasting future frames in a video sequence. Finally, the goal of querying is to retrieve video segments related to specific queries. Notably, these tasks often span multiple modalities, which have received considerable attention compared to the previously mentioned data types.
Overview and Classification
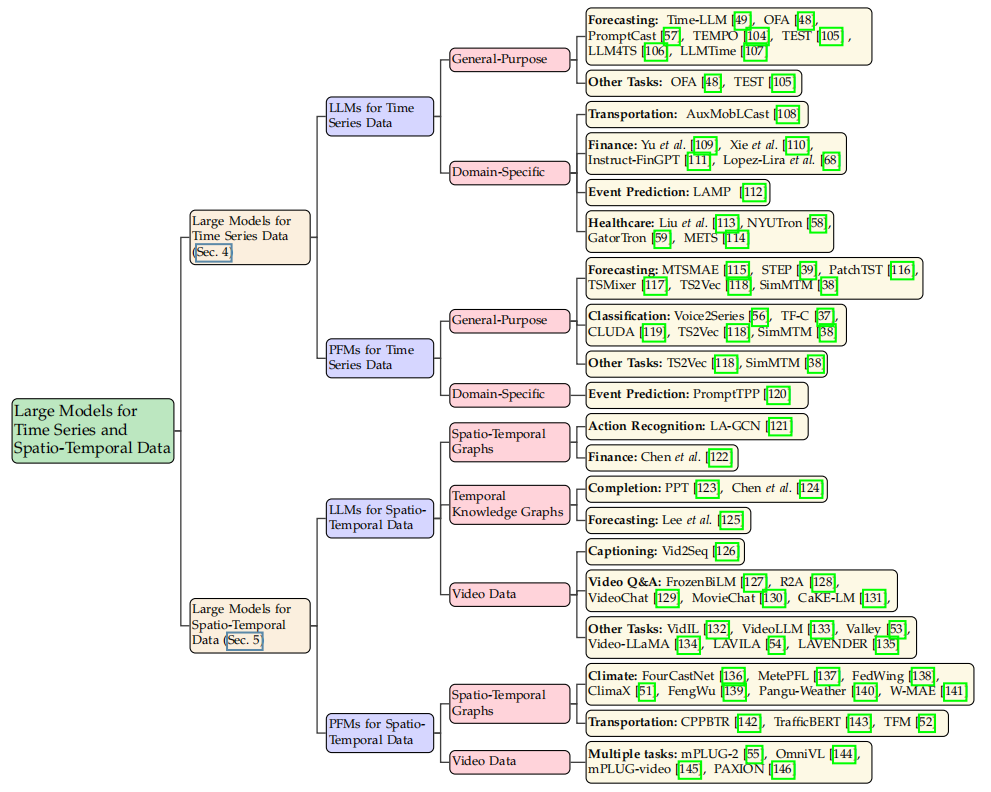
The authors provide an overview and classification of large models for time series and spatio-temporal data. The structure of the survey follows four main dimensions: data categories, model architectures, model scopes, and application areas or tasks. A detailed summary of related works can be found in Figure 3 and Table 2. The authors primarily categorize the existing literature into two main categories: large models for time series data (LM4TS) and large models for spatio-temporal data (LM4STD).
01 Large Models for Time Series Data (LM4TS)
In the LM4TS category, the authors subdivide the research into two classes: LLMs for Time Series Data (LLM4TS) and PFMs for Time Series Data (PFM4TS). The former refers to using LLMs to address time series tasks, regardless of whether the LLMs are fine-tuned or frozen during the adaptation process. The latter, on the other hand, focuses on the development of PFMs explicitly designed for various time series tasks. Notably, the PFM4TS field is relatively new; existing models may not fully encapsulate the potential defined in section 2.2 for general PFMs. However, they provide valuable insights for future development in this field. Therefore, the authors also include them in this survey and classify them as PFM4TS. For these subdivisions, the authors further categorize them as general or domain-specific models, depending on whether these models are designed to solve general time series analysis tasks or are limited to specific domains, including but not limited to transportation, finance, and healthcare.
02 Large Models for Spatio-Temporal Data (LM4STD)
In the LM4STD category, the authors adopt a similar classification, defining LLMs for Spatio-Temporal Data (LLM4STD) and PFMs for Spatio-Temporal Data (PFM4STD). Unlike time series data, spatio-temporal data encompasses a broader array of entities across multiple domains; thus, the authors explicitly categorize LLM4STD and PFM4STD according to their relevant domains. Here, the authors focus on three most prominent fields/modalities, using them as subclasses: spatio-temporal graphs, temporal knowledge graphs, and video data. For each of these, the authors summarize representative tasks as leaf nodes, which is similar to LM4TS. Notably, compared to their time series counterparts, PFM4STD has seen broader development. Current research primarily targets STGs and video data, often featuring enhanced capabilities of PFMs, such as modality bridging and reasoning.
Large Models for Time Series Data
In recent years, the application of large language models and pre-trained foundational models in time series analysis has made significant progress. These models possess powerful learning and representation capabilities, effectively capturing complex patterns and long-term dependencies in time series data. In this section, the authors will discuss the progress of large language models and pre-trained foundational models in time series analysis and further categorize the discussion based on the models’ generality and domain specificity.
01 Applications of Large Language Models in Time Series Analysis
Over time, large language models (LLMs) have gradually shown their potential in the field of time series analysis. As one of the early efforts to approach general time series forecasting from the LLM perspective, a study formally introduced a new task: prompt-based time series forecasting—PromptCast. Since both the input and output are natural language sentences, PromptCast provides a novel “no-code” solution for time series forecasting, offering a fresh perspective rather than just focusing on designing complex architectures. Moreover, to address the challenge of the lack of large-scale training data, a study proposed a unified framework based on partially frozen LLMs, where only the embedding and normalization layers are fine-tuned while keeping the self-attention and feed-forward layers unchanged. This approach achieved state-of-the-art or comparable performance across all major time series analysis tasks, including time series classification, short-term/long-term forecasting, imputation, anomaly detection, few-shot, and zero-shot forecasting.
Other studies have focused more on specific aspects of time series forecasting. For example, TEMPO concentrates on time series forecasting but incorporates additional time series decomposition and soft prompting as fine designs. Other research has utilized LLMs for time series forecasting, adopting a two-stage fine-tuning process: first, supervised fine-tuning guides the LLM towards time series data, followed by downstream fine-tuning focused on time series forecasting. Additionally, some studies have activated LLMs’ capabilities on time series through new embedding methods, tokenizing and encoding data through instance, feature, and text prototype alignment, then creating prompts to pass to LLMs for task execution.
2. Domain-Specific Models
Transportation Sector: Time series forecasting plays a crucial role in Intelligent Transportation Systems (ITS). To fully leverage the application potential of large language models in the transportation sector, a novel AuxMobLCast pipeline has been proposed, utilizing LLMs for traffic data mining, such as human mobility prediction tasks.
AuxMobLCast transforms human mobility data into natural language sentences, enabling the pre-trained LLM to be directly applied during the fine-tuning phase to predict human mobility. This work represents the first attempt to fine-tune existing LLMs for predicting data in the transportation sector, providing new ideas and methods for the application of LLMs in transportation.
Finance Sector: In recent years, several studies focusing on large language models (LLMs) in the finance sector have been reported in the literature. One study proposed a simple yet effective instruction tuning method for sentiment analysis in finance. Through this method, classification-based sentiment analysis datasets were transformed into generative tasks, allowing LLMs to apply their extensive training and superior analytical capabilities more effectively. Besides NLP tasks, leveraging LLMs’ exceptional knowledge and reasoning capabilities for financial time series forecasting is also appealing. One study used GPT-4 for zero-shot/few-shot reasoning and Llama for instruction-based fine-tuning to produce interpretable predictions, which, although relatively underperformed compared to GPT-4, still achieved reasonable performance. Another study employed a similar approach to predict stock price movements based on text data. These studies showcase the potential and diversity of LLMs in the finance sector, providing new perspectives and tools for future financial applications and research.
Event Prediction: Unlike synchronous (regular) time series data with equal sampling intervals, event sequences are asynchronous time series with irregular timestamps. Event sequences play a significant role in the real world, such as in finance, online shopping, and social networks. Temporal Point Processes (TPPs) have become the standard method for modeling such data. Event prediction aims to forecast future times and event types based on the past. For example, in the online shopping domain, the authors aim to build a model of users’ timestamped access sequences and predict their future shopping behavior based on their past shopping reviews. Large language models (LLMs) can potentially be useful in this setup, as event sequences often come with rich textual information, and LLMs excel at processing this information.
Healthcare Sector: The healthcare sector is one of the most important areas in event sequences, where clinical models can assist doctors and administrators in making decisions in daily practice. The use of structured data-based clinical models is limited, but the expansion and improvement of clinical LLMs like GatorTron and NYUTron provide the potential for medicine to read alongside doctors and offer guidance at the point of care. LLMs can also bring significant improvements in health tasks by fine-tuning with few-shot prompts, using numerical time series data from wearable devices and clinical-grade sensors as a foundation.
02 Applications of Pre-trained Foundational Models in Time Series Analysis
In addition to utilizing LLMs for time series analysis, the development of time series pre-training and related foundational models is also promising. These models help identify general time series patterns that remain consistent across various domains and downstream tasks.
Since 2021, numerous pre-trained foundational models have been proposed, most of which are general models. Voice2Series leverages the representation learning capabilities of pre-trained speech processing models, using speech data as univariate time signals for time series classification, representing the first framework capable of reprogramming for time series tasks.
Following Voice2Series, pre-trained foundational models for time series data based on contrastive learning techniques have emerged, including TF-C, TS2Vec, and CLUDA. TF-C includes a time-based component and a frequency-based component, each trained separately through contrastive estimation, with self-supervised signals provided by the distance between the time and frequency components, i.e., time-frequency consistency. TS2Vec proposes a general contrastive learning framework for learning contextual representations of arbitrary subsequences in the time series domain at various semantic levels, processing enhanced contextual views hierarchically. This framework supports multivariate input and can be used for various tasks in the time series domain.
CLUDA is an unsupervised time series domain adaptation model based on contrastive learning. CLUDA features two novel components: customized contrastive learning and nearest neighbor contrastive learning. They are aligned between the source domain and target domain using adversarial learning. The contrastive learning component of CLUDA aims to learn a representation space where semantically similar samples are closer together while dissimilar samples are further apart. Thus, CLUDA can learn domain-invariant contextual representations in multivariate time series to adapt to different domains. The emergence of these models provides richer and more powerful tools for time series analysis.
In addition to the aforementioned models and techniques, many other techniques have been adopted in the field. For instance, the STEP model incorporates a pre-trained model and a spatio-temporal graph neural network (STGNN). The pre-trained model is designed to learn time patterns efficiently from long historical time series and generate segment-level representations. These representations provide contextual information for the short-term time series inputs of STGNNs and help model the dependencies between time series.
MTSMAE is a self-supervised pre-training method for multivariate time series prediction. The pre-training method based on Masked Autoencoders (MAE) involves a new block embedding that reduces memory usage and allows the model to handle longer sequences, addressing the challenge of processing high information density in multivariate time series.
SimMTM also extends the pre-training method based on masked modeling to time series by revealing the local structure of the manifold. To enhance the performance of masked modeling, the masked time points are recovered through weighted aggregation of multiple neighbors outside the manifold, enabling SimMTM to combine complementary temporal variations from multiple masked sequences and improve the quality of the reconstructed sequences.
PatchTST is a transformer-based long-term time series forecasting model. To overcome the limitations of other models in capturing local semantic information, PatchTST introduces a patch mechanism for extracting local semantic information and designs channel independence, allowing each sequence to learn its own attention map for prediction. It is also applied in pre-training tasks.
Additionally, TSMixer is a lightweight MLP-Mixer model for multivariate time series prediction. It introduces two novel online harmonization heads that utilize the inherent temporal properties of hierarchical patch aggregation and cross-channel correlations to adjust and improve predictions. Unlike transformer-based models, TSMixer significantly enhances the learning capability of simple MLP structures.
2. Domain-Specific Models
PromptTPP proposes a general method for pre-training foundational models for event sequences and addresses the issue of continuous model monitoring through continual learning (CL). This enables PromptTPP to continuously learn a series of tasks under real-world constraints without suffering from catastrophic forgetting. Accordingly, PromptTPP integrates the foundational model with a continual time retrieval prompt pool. These prompts are learnable small parameters stored in memory space and jointly optimized with the foundational model, ensuring that the model can learn event streams sequentially without buffering past samples or task-specific attributes.
By this means, PromptTPP not only adapts to changing data environments but also effectively utilizes memory resources, avoiding information forgetting during continual learning. The introduction of this method opens up new possibilities for continual learning of event sequences and provides effective tools for solving related practical problems.
Large Models for Spatio-Temporal Data
In this section, the authors explore the advancements of large models in spatio-temporal data analysis, spanning three main data categories: spatio-temporal graphs, temporal knowledge graphs, and videos. Each of these has extensive real-world applications.
01 Spatio-Temporal Graphs
In the era of deep learning, spatio-temporal graph neural networks (STGNNs) have become the most popular method for spatio-temporal graph prediction. They primarily utilize graph neural networks to capture spatial correlations between vertices and employ other models (such as RNNs and CNNs) to learn temporal dependencies between different time steps.
In recent years, the emergence of LLMs (large language models) and PFMs (pre-trained foundational models) has provided valuable support for STGNNs in the field of spatio-temporal representation learning. These models excel at processing and contextualizing textual data, enabling them to extract insights from various textual sources (including news articles, social media content, to reports). These insights can be seamlessly integrated into spatio-temporal structures, enhancing the richness of their context. Moreover, they facilitate the fusion of multiple modalities, including text, images, and structured data, thereby broadening the depth and breadth of spatio-temporal understanding. These models have the ability to generate human-interpretable explanations, improving transparency and reliability, especially in applications such as urban planning or disaster response. Additionally, they promote computational efficiency by encoding high-level information in concise representations, streamlining training and inference processes.
1. Applications of Large Language Models in Spatio-Temporal Graphs
Compared to PFMs, literature utilizing LLMs to enhance STGNNs’ learning capabilities is relatively sparse. One method involves using LLMs to learn relationships between vertices. An early study can be found in reference [122], which proposed a novel framework that leverages the impressive graph reasoning capabilities of LLMs to enhance STGNNs’ predictions of stock price fluctuations. In this approach, ChatGPT is used to extract evolving network structures from daily financial news, which are then seamlessly integrated into GNNs to generate node embeddings for each company. These embeddings have proven helpful in improving the performance of downstream tasks related to stock fluctuations.
Additionally, a second series of studies utilize the prior knowledge of LLMs to support downstream applications of STGNNs, such as LA-GCN for human behavior recognition. In LA-GCN, LLM-derived knowledge is transformed into prior global relationship (GPR) topology and prior category relationship (CPR) topology, defining interconnections between nodes. GPR serves as a guiding framework for generating novel skeletal representations, primarily aimed at highlighting key node information extracted from the foundational data.
2. Applications of Pre-trained Foundational Models in Spatio-Temporal Graphs
We are currently witnessing a surge in pre-trained machine learning models tailored for mastering STGs (spatio-temporal graphs) across various real-world applications. These models significantly promote STG learning through knowledge transfer. In other words, they achieve the transfer of learned representations, thereby enhancing the capacity of STGs to capture complex patterns, leading to more effective and efficient learning.
Contrastive learning is a representation learning method widely applied in image and text domains, which has also proven to be very effective in spatio-temporal graph learning. One representative method is STGCL, which extracts rich and meaningful representations from complex spatio-temporal graph data by contrasting positive sample pairs with negative sample pairs. This method makes contrastive learning feasible for practical applications in diverse fields such as traffic forecasting and electricity consumption prediction. To learn informative relationships between vertices, SPGCL maximizes the distinguishing boundary between positive and negative neighbors and generates optimal graphs using a self-paced strategy.
Considering the urgent need for computational efficiency and timely climate forecasting, Pathak et al. introduced FourCastNet, a climate PFM that achieves high-resolution predictions and rapid inference using adaptive Fourier neural operators. Its training process involves two stages—pre-training and fine-tuning. During pre-training, FourCastNet undergoes supervised training to achieve mappings from one time step to the next. In the fine-tuning stage, it is built upon the pre-trained model and optimized to predict the next two time steps in an autoregressive manner.
PanGu demonstrates stronger mid-term forecasting capabilities than FourCastNet through a novel 3D Earth-specific transformer model. This 3D deep network enhances Earth-specific priors, effectively handling complex meteorological data patterns.
ClimaX is a highly adaptable deep learning model applied in climate and weather sciences, trained on diverse datasets. It extends the transformer architecture with innovative components, optimizing computational efficiency. Initially pre-trained on CMIP6 climate data, ClimaX can be fine-tuned for various climate and weather tasks, even involving unseen variables and spatio-temporal scales.
W-MAE integrates a self-supervised pre-training method (i.e., Masked Autoencoder) into climate forecasting tasks. This integration enables the model to extract key meteorological features and general knowledge from large amounts of unlabeled meteorological data, aiding in the processing of diverse data sources. Unlike the above methods, FengWu addresses mid-term climate forecasting issues through multimodal and multi-task approaches. It employs a deep learning architecture with model-specific transformers and cross-modal fusion strategies. This design is meticulously crafted, incorporating uncertainty loss for regional adaptive optimization of various predictors.
In the transportation sector, CPPBTR is a transformer-based new framework for crowd flow prediction, characterized by a two-stage decoding process. In the first decoding stage, an initial sequence is generated. Subsequently, in the second decoding stage, each time step of this initial sequence is systematically masked and input into the transformer encoder to predict the fine flow at each masked position.
In the traffic flow forecasting domain, TrafficBERT leverages key features inspired by BERT. It adopts a bidirectional transformer structure similar to BERT, capable of predicting overall traffic flow rather than individual time steps. Compared to conventional models that require separate training for each specific road, TrafficBERT enhances the model’s generalization ability by using data from multiple roads during pre-training.
Furthermore, Wang et al. introduced the Traffic Foundational Model (TFM), which incorporates traffic simulation into the realm of traffic forecasting. TFM cleverly captures the complex dynamics and interactions between participants within the traffic system using graph structures and dynamic graph generation algorithms. This data-driven, model-free simulation approach effectively addresses the long-standing issues of structural complexity and model accuracy in traditional systems, laying a solid foundation for solving complex traffic problems using real-world data.
02 Temporal Knowledge Graphs
Applications of structured knowledge reasoning, such as search engines, question-answering systems, dialogue systems, and social networks, require reasoning over foundational structured knowledge. In particular, knowledge graphs (KGs), as important models for studying this type of knowledge in complex multi-relational settings, have garnered widespread attention. KGs represent facts (events) in the form of triples (s, p, o), typically extracted from textual data, where s and o represent subject and object entities, and p represents the predicate type as the relationship. However, in the real world, knowledge is constantly evolving, which has spurred the construction and application of temporal knowledge graphs (TKGs), where facts extend from triples (s, p, o) to quadruples with timestamps t, i.e., (s, p, o, t). By effectively capturing the temporal and structural dependencies between facts, TKGs contribute to a better understanding of entities’ behaviors and how they contribute to fact generation over time. Therefore, the application and improvement of TKGs are significant for enhancing the performance and accuracy of these systems.
Given the remarkable performance of LLMs in many textual reasoning tasks in recent years, it is natural to actively explore the effectiveness of LLMs in TKGs. Depending on the tasks performed, LLM-based TKG models can be divided into two categories: prediction and completion.
Videos are digital representations of visual information, typically composed of a series of images or frames that collectively convey motion and temporal changes. These data have become ubiquitous in various practical applications, including surveillance systems, entertainment platforms, social media, and driver assistance systems. Conventional deep learning methods for video understanding primarily involve two key paradigms:
(1) 2D CNNs: In this paradigm, each video frame is processed separately through 2D convolutions and then aggregated along the temporal axis at the top of the network. This approach primarily focuses on spatial features, with simpler handling of temporal features.
(2) 3D CNNs: This method learns 3D convolutions to aggregate spatial and temporal features, thereby learning the spatio-temporal representation of videos. Compared to 2D CNNs, 3D CNNs are better at capturing temporal dynamics in videos.
In recent years, transformers have also been widely applied to model the spatio-temporal dependencies of videos for video recognition due to their ability to capture long-range dependencies. This method does not rely on convolution operations but uses self-attention mechanisms to capture global spatio-temporal dependencies.
However, the recent developments of LLMs (large language models) and PFMs (pre-trained foundational models) have paved the way for enhancing video understanding by leveraging the inherent multimodal nature of videos. Models such as OpenAI’s CLIP and DALL-E can effectively extract rich contextual information from video data by jointly processing visual and textual modalities, achieving a more comprehensive understanding of complex scenes and events. Furthermore, these models have the potential to facilitate effective transfer learning across different domains, improving the generalization ability and robustness of video analysis tasks.
Resources and Applications
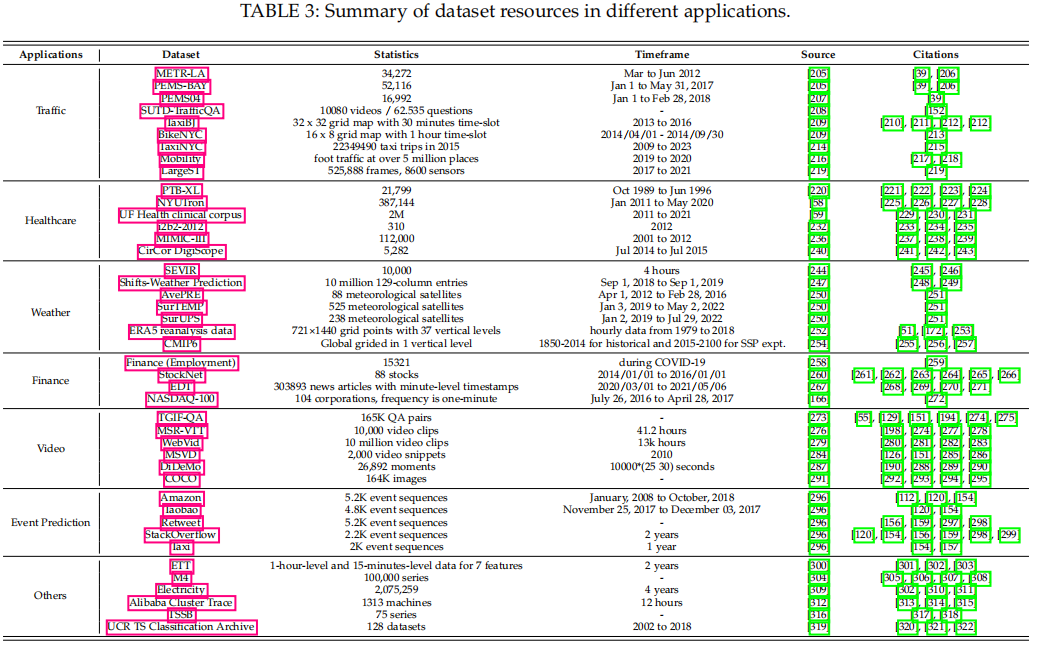
This section summarizes various datasets, models, and tools commonly associated with applications related to time series and spatio-temporal data. These datasets, models, and tools are listed in the table below, providing valuable resources and references for researchers and practitioners. Through these datasets, models, and tools, we can gain deeper insights into and analyze time series and spatio-temporal data, further advancing and progressing related fields.
Outlook and Future Opportunities
This section discusses the potential limitations of current research and highlights six future research directions aimed at developing more robust, transparent, and reliable large models for time series data analysis.
01 Theoretical Analysis of Large Models
Due to the sequential nature of textual data and temporal data, recent studies have extended LLMs to handle time series and spatio-temporal tasks. This implies that representations learned from LLMs’ textual data can be fine-tuned to capture temporal data patterns. However, this remains a very advanced understanding. Like other deep learning models, LLMs are also regarded as “black boxes” due to their complexity, making it difficult to understand which data influences their predictions and decisions. There is a need for deeper theoretical analysis of LLMs to explore the potential pattern similarities between language and temporal data and how to effectively apply them to specific time series and spatio-temporal tasks, such as forecasting, anomaly detection, classification, etc.
02 Development of Multimodal Models
In real-world applications, many time series and spatio-temporal data often come with supplementary information, such as textual descriptions. This is particularly useful in scenarios like economics and finance. For example, economic forecasting can leverage information from both textual (e.g., news articles or tweets) and numerical economic time series data. Therefore, LLMs can adapt to learn joint representations that consider both the sequential nature of temporal data and the unique characteristics of other modalities. Additionally, different modalities may have different temporal resolutions. LLMs can adapt to handle the differences in temporal data from multiple modalities with varying temporal resolutions. Thus, all information from different temporal resolutions can be fully utilized to enhance performance.
03 Continual Learning and Adaptation
Real-world applications often face constantly changing scenarios. Therefore, it is necessary to study the models’ ability to adapt to non-stationary environments, avoiding catastrophic forgetting of old knowledge. Although some research has explored these issues in conventional machine learning and deep learning models, how to enable large models to continually adapt to changing temporal data, including online learning strategies, adapting to concept drift, and accommodating evolving patterns in data, remains an underexplored issue.
04 Interpretability and Understandability
Understanding why models make specific predictions or forecasts is also crucial for time series analysis, especially in critical domains like healthcare and finance. Currently, the internal understanding of LLMs remains limited. Therefore, it is important to develop theoretical frameworks to understand what LLMs have learned and how to apply them to time series data for predictions. Interpretability and understandability can enhance the transparency of LLMs, providing fundamental principles for time series analysis, such as highlighting why predictions of future values are made, how specific points are viewed as anomalies, or explaining the reasons for specific classifications. Researching how to enhance large models to perform temporal reasoning and infer causal relationships in time series data is essential. This includes developing methods to identify causality, which is crucial for applications such as root cause analysis and intervention planning.
05 Privacy and Adversarial Attacks on Large Models
Temporal data can be highly sensitive, especially in applications like healthcare and finance. When LLMs are trained or fine-tuned on such data, they may memorize specific details from the training data, leading to the risk of leaking private data. Therefore, there exists a vast array of research opportunities on how to leverage privacy-preserving techniques, such as differential privacy and federated learning, to benefit from the powerful capabilities of LLMs in time series and spatio-temporal analysis while ensuring data privacy.
06 Model Generalization and Vulnerability
LLMs are typically pre-trained on general data and then fine-tuned on specific tasks. If the fine-tuning data contains adversarial or noisy samples, this process may introduce vulnerabilities. If the temporal data used for fine-tuning has not been carefully processed, the model may inherit biases or vulnerabilities from this data, leading to compromised robustness in real-world applications. Furthermore, although LLMs are trained on large datasets, they may not generalize well to unseen or out-of-distribution data. Time series and spatio-temporal data may exhibit sudden changes or trends. If an LLM has not encountered similar patterns during training, it may produce unreliable outputs, emphasizing the need for robust generalization.
This article provides a comprehensive and up-to-date overview of large models applicable to time series and spatio-temporal data analysis. The authors aim to classify the reviewed models by introducing a new taxonomy, providing a fresh perspective for this dynamic field. They not only describe but also summarize the most prominent techniques within each category, delving into their advantages and limitations, ultimately illuminating promising pathways for future research. The scope of groundbreaking investigations in this exciting topic is limitless. This review will serve as a catalyst to spark curiosity and foster a lasting enthusiasm for research on large models in the field of time series and spatio-temporal data analysis. The authors hope this review can provide researchers with a comprehensive and in-depth reference to continuously advance the field and inspire more innovations and applications.
Editor: Huang Jiyuan
Proofreader: Lin Yilin