
Deep learning stands out in artificial intelligence, and to learn deep learning, one must first master an effective deep learning framework. This article will review the currently popular deep learning frameworks worldwide, enhancing everyone’s understanding of these frameworks based on their popularity and application scenarios.

Without further ado, here is a chart showing the activity levels of various mainstream deep learning frameworks on GitHub as of February 1, 2019, along with their support for programming languages and systems.
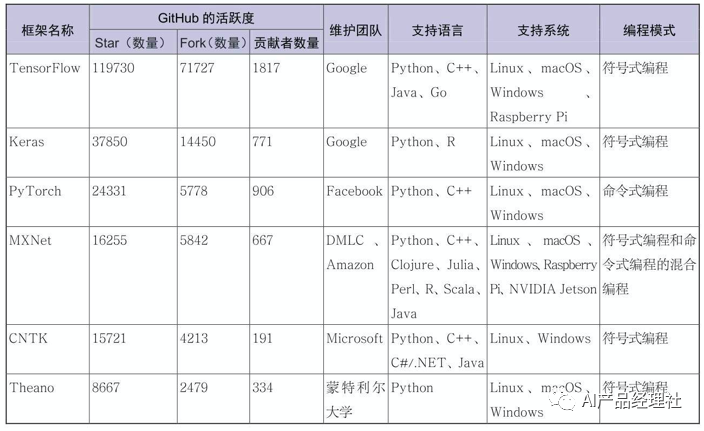
1. TensorFlow Framework
TensorFlow was released by Google in November 2015 and is a relatively mature and complete deep learning framework that employs symbolic programming.
There are two important concepts in TensorFlow: Tensor and Flow. We can think of a “tensor” as an N-dimensional array, while “flow” intuitively expresses the process of transformation between tensors through computation. A series of tasks in deep learning essentially explores the internal function mapping given input and output. Tensors and flow explain the operation of deep learning algorithms in an easy-to-understand manner, indicating how tensors transform through computation.
The operation principle of TensorFlow is to define a data model with tensors, define the data model and operations in a computation graph, and run calculations using sessions. It supports multiple programming languages such as Python, C++, Java, and Go through SWIG, while also supporting all mainstream deep learning algorithms.
In terms of hardware performance, TensorFlow supports mainstream operating systems and mobile platforms, suitable for distributed systems composed of multiple CPUs, GPUs, and TPUs.
Disadvantages of TensorFlow include: on one hand, its pursuit of a comprehensive development environment and programming languages, along with rapid version iterations, lead to a rather complex and somewhat disorganized framework, which can be slightly costly for beginners; on the other hand, it has weaknesses in static computation graphs, making some implementations, such as dynamic RNNs and the Beam Search algorithm in Seq2Seq, quite complex.
In summary, TensorFlow’s support for multiple platforms and languages, backed by Google’s powerful team maintenance capabilities and comprehensive support for the deep learning ecosystem, has made it the most popular deep learning framework currently.
2. Keras Framework
The Keras framework appeared in 2015 with the goal of providing a simple and easy-to-use deep learning framework. Keras is not an independent deep learning framework but a wrapper built on top of Theano.
Keras is a Python-based deep learning library designed to help users quickly prototype experiments, turning ideas into experimental results with minimal latency. Building and training networks with Keras is very easy. Moreover, in most cases, if deeper control over the model is needed, users can simply use some functions provided by Keras, rarely needing to delve into the backend engine. Keras has developed rapidly, featuring: symbolic programming, Python support, rapid prototyping, high modularity, and ease of expansion. The modules in Keras are simple, understandable, and configurable, allowing free combinations of neural networks, loss functions, optimizers, initialization methods, activation functions, and regularization modules. The modularity simplifies the complexity of writing deep learning models and shortens the time to try new network structures. Therefore, Keras is suitable for rapid prototyping. Model definitions in Keras can be completed directly by Python scripts without the need for additional configuration files, making it easier for users to debug models and hyperparameters. If TensorFlow is viewed as C++, heavy and comprehensive; Keras resembles Python, simple and elegant. Consequently, the Keras community has grown rapidly, and it currently has many stars and forks on GitHub.
Due to its simplicity and modularity, Keras is currently one of the most user-friendly and easiest deep learning frameworks for newcomers in the field of artificial intelligence.
3. PyTorch Framework
PyTorch was launched by Facebook in October 2016. PyTorch has undergone several transformations, originally stemming from Torch (launched in October 2002). On April 1, 2018, PyTorch merged with another framework strongly supported by Facebook, Caffe2. On October 1, 2018, Facebook officially released the PyTorch 1.0 preview version. Regarding the merger of PyTorch and Caffe2, Caffe2’s author, Jia Yangqing, stated: “PyTorch has an excellent frontend, while Caffe2 has an excellent backend. Integrating them can further maximize developer efficiency.”
PyTorch is a Python-first deep learning framework aiming to make designing scientific computing algorithms more convenient. PyTorch primarily attracts two types of users: those looking to better utilize GPU performance as a replacement for Python’s NumPy package, and those wanting to experience PyTorch as a flexible and fast deep learning research platform.
Compared to TensorFlow, PyTorch has always been in a follower position. PyTorch is relatively new, and its community is smaller, but its documentation is more organized and user-friendly for learners. PyTorch also provides visualization tools like tensorboardX and supports dynamic graph rendering. Compared to static TensorFlow, PyTorch’s dynamic neural networks can more efficiently handle issues such as RNNs that require varying time lengths. Furthermore, PyTorch has consistently promoted its efficiency and speed advantages, as well as its user-friendliness with a Python-first approach, making it worth trying when developing new deep learning models. The rapid increase in stars and forks on GitHub for PyTorch also indicates users’ optimism regarding its prospects.
4. MXNet Framework
MXNet first appeared in December 2015 at the NIPS machine learning systems Workshop and was developed by the DMLC (Distributed Machine Learning Community). On November 22, 2016, Amazon CTO Werner Vogels wrote in his blog that MXNet was officially chosen by AWS as its cloud computing deep learning platform. In October 2017, Amazon and Microsoft launched a new deep learning interface called Gluon for MXNet, making it easier to build deep learning models.
Like TensorFlow, MXNet supports various programming languages such as C++, JavaScript, Python, R, and Perl through SWIG. Developers can choose the programming language they are familiar with for their development work. In the backend of MXNet, all code is compiled in C++, ensuring high-performance development regardless of the programming language used to build the model.
MXNet has been criticized for its documentation and tutorials: the API documentation is somewhat lacking, and the absence of custom tutorials makes it difficult for users to get started. The MXNet community is relatively small, and sometimes users need to refer to and modify the source code themselves when encountering issues, leading to a higher barrier to entry. However, MXNet is actively improving, with its documentation gradually being refined and its community growing.
5. CNTK Framework
The Cognitive Toolkit (CNTK) was launched by Microsoft on January 25, 2016. CNTK originated from a set of internal tools designed by Dr. Huang Xuedong and his team at Microsoft Research in 2014 to help improve computer understanding of speech more quickly. This internal tool became the foundation of the now widely known Cognitive Toolkit (CNTK) and is the source of its name.
CNTK was initially used in the field of speech recognition and has now evolved into a general-purpose, cross-platform deep learning framework. Compared to other deep learning frameworks, Microsoft has consistently emphasized the speed advantages of CNTK. CNTK claims to be significantly faster than TensorFlow, especially on RNNs, where it can be 5-10 times faster. CNTK provides a unique one-bit SGD (Stochastic Gradient Descent) for stochastic gradient descent, quantizing each subgradient to compress each value to one bit. This technology enhances performance by ten times while maintaining accuracy. In terms of cloud platforms, CNTK is supported by Microsoft’s own Azure cloud platform and can now also be used on other cloud platforms such as AWS, Google Cloud, Alibaba Cloud, and Tencent Cloud.
6. Theano Framework
Theano ranks last in activity levels but was once the “dominant” framework in deep learning in 2015. Theano was born in 2008 and was developed and maintained by the Lisa Lab team at the University of Montreal. It was the first deep learning framework to be widely used and serves as the foundation for other deep learning frameworks. Theano is a fully Python-based symbolic computation library designed for handling computations for training large-scale neural networks.
Regrettably, as competition among deep learning frameworks intensified, Theano bid farewell to the community on September 29, 2017, after releasing its latest version 1.0. Its core contributors, Yoshua Bengio and Pascal Lamblin, stated: “We will continue to do minor maintenance to keep Theano working for a year, but we will stop developing new features.” Regarding the reasons for Theano’s departure, Yoshua Bengio explained that, on one hand, many new deep learning frameworks have emerged and evolved rapidly, inheriting Theano’s innovations and addressing its shortcomings; on the other hand, the relatively outdated codebase has hindered Theano’s innovation.

Please click 【Read More】 to encourage Chang Gong further