Click the “Beginner Learning Vision” above, and select to add “Star” or “Pin“
Important information delivered to you first
01. Introduction to Computer Vision
What is computer vision? Why is it worth our time to understand? How does it work? What applications have commercial value? Let’s explore this topic together today.
What is Computer Vision?
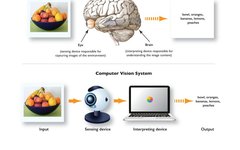
Computer vision refers to the use of computers to automatically perform tasks that the human visual system can accomplish. Similar to how the human eye receives light stimuli from the external environment, computers use digital cameras to receive this information, which is processed in the brain, while computers utilize specific algorithms to process the obtained images.
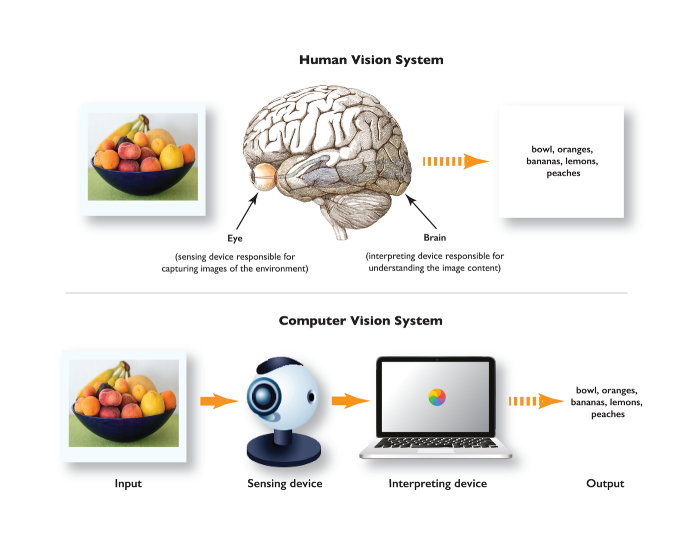
The Eye of Humans vs. the Eye of Computers
Current technology has resolved the issue of inaccurate image acquisition, and over the past decade, it has also addressed the labeling of digital images. In the 2012 version of ILSVRC (ImageNet Large Scale Visual Recognition Challenge), challenge research teams from around the world classified over ten thousand images in its ImageNet dataset across 1000 object categories, with deep learning achieving first place in image classification for the first time.
AlexNet [2] deep learning method (first author Alex Krizhevsky) was proposed by the SuperVision team at the University of Toronto. They utilized a Convolutional Neural Network (CNN) architecture to achieve second place! In contrast, the image classifier trained by Andrej Karpathy achieved a 5.1% error rate. The best method in 2014 was GoogLeNet [3], and Karpathy himself pointed out that if not properly trained, the performance of the image classifier would be much worse. Clearly, not everyone has the patience and training for large-scale pattern recognition:
Does this mean that computers can now “see” like humans? The answer is certainly not. In 2015, researchers found that many advanced computer vision models are vulnerable to attacks using maliciously designed high-frequency patterns, known as “adversarial attacks” [4], which can deceive models into altering their predictions without our notice.
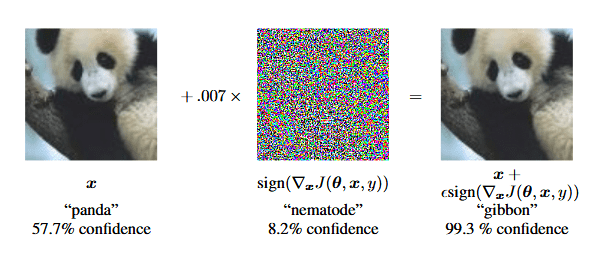
Adding high-frequency “nematode” noise to a “panda” can trick the network into predicting a “gibbon”.
This is another humorous example of how adversarial attacks can deceive computer vision algorithms. Researchers at MIT developed a special pattern and placed it on specially designed toy turtles to trick the network into predicting a “rifle”.
Why Study Machine Vision?
Aside from adversarial attacks, there are highly specialized researchers; why should we care about computer vision? For the same reasons as Andrej Karpathy – large-scale visual recognition requires substantial training and time. Ultimately, there will still be human errors. Based on Karpathy’s single experience competing with methods in ILSVRC, he abandoned the following ideas:
lOutsourcing tasks to multiple individuals for profit (e.g., outsourcing to paid undergraduates or paid labelers on Amazon Mechanical Turk)
lOutsourcing tasks to unpaid academic researchers
Ultimately, Karpathy decided to perform all tasks himself to reduce labeling inconsistencies. Karpathy stated that it took him about 1 minute to identify each image in a smaller test set of 1,500 images. In contrast, modern convolutional neural networks can identify objects in images in less than a second using decent GPUs. What if we need to identify a complete test set of 100,000 images? Although developing computer vision processing systems requires development time and expertise, computers can perform visual recognition more consistently than humans and can scale better when needed.
How Does Computer Vision Work?
For computers, images are 2D arrays of pixel intensities. If the image is black and white, each pixel has one channel. If the image is in color, each pixel typically has three channels. If the image comes from a video, there is also a temporal component. Since arrays are easily manipulated mathematically (see linear algebra), we can develop quantitative methods to detect the content present in images.
Manual Adjustment Method

I have a theory… 0 represents curves, 1 represents straight lines.
This is called the “manual adjustment method” because it requires the operator to develop a rule-based theory about how to detect given patterns that the computer can understand. This may be the most obvious way to perform computer vision. However, while it can solve some simple problems, such as recognizing simple digits and letters, it quickly falls apart when presented with more complex images that have variations in lighting, background, occlusion, and viewpoint.
Machine Learning Methods
For example, suppose you want to detect whether an image contains a dog or a cat. During training, you would obtain a large collection of images labeled as either dogs or cats. You apply an algorithm and train it until it can recognize most of the training images well. To check whether it still works well on unseen images, you provide it with new images of cats and dogs and validate its performance.

In recent years, the “boom” of machine learning has actually been the boom of so-called “deep learning” models. These models use layers with learnable weights to extract features and classify, while previous models used manually tuned features and shallow learnable weights for classification. As mentioned earlier, one of the most fundamental models in computer vision is the “Convolutional Neural Network” (CNN or ConvNet). These models extract features from images by repeatedly convolving them with 3D weights and downsampling (think of it as 2D multiplication). The features are then transformed into a one-dimensional vector and multiplied by scalar weights to generate output classifications.
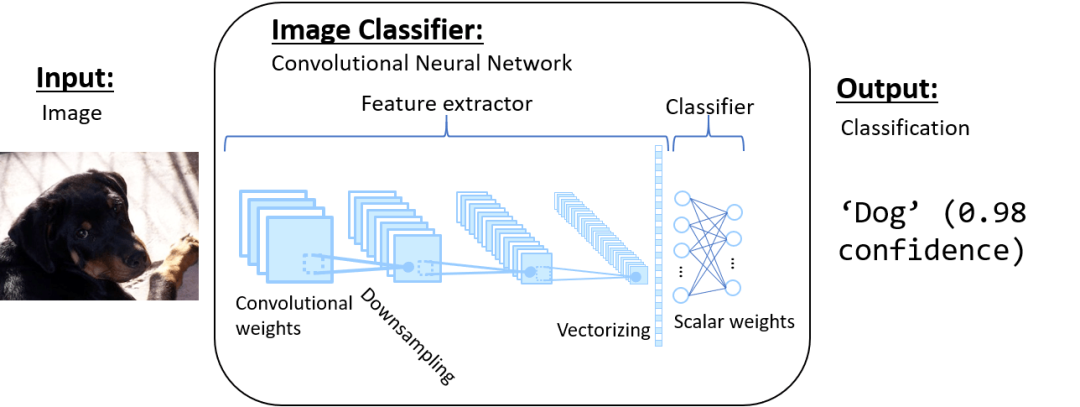
02. Main Tasks of Computer Vision
Since the human visual system can perform many different tasks simultaneously, computer vision should be able to replicate this, so there are many ways to break it down into discrete tasks. Generally, the core tasks that computer vision seeks to solve are as follows (in increasing order of difficulty):
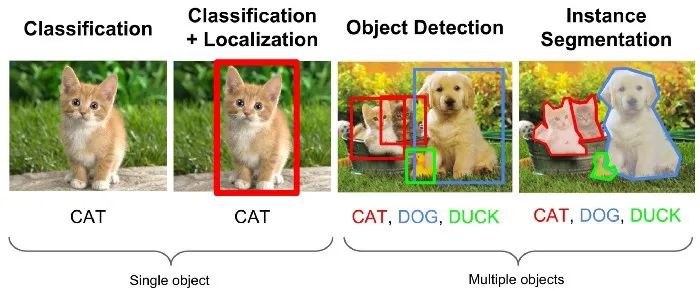
1.Image Classification: Given an image with a single object, predict the object that is present (useful for labeling, searching, or indexing images by object, label, or other attributes)
2.Image Localization: Given an image with a single object, predict the object that is present and draw a bounding box around it (for locating or tracking the appearance or movement of an object)
3.Object Detection: Given an image containing multiple objects, predict that both objects are present and draw a bounding box around each object instance (for locating or tracking the appearance or movement of multiple objects)
4.Semantic Segmentation (not shown in the image): Given an image with multiple objects, predict the presence of two objects and predict which pixels belong to each object category (e.g., pixels belonging to the cat category) (for analyzing the shapes of multiple object categories)
5.Instance Segmentation: Given an image containing multiple objects, predict the presence of two objects and predict which pixels belong to each instance of the object class (e.g., Cat #1 vs. Cat #2) (useful for analyzing the shapes of multiple object instances)
Available Datasets and Models
Just as ILSVRC provides already annotated data (ImageNet) to objectively compare the algorithms of different researchers, competitive researchers also publish their models to support their claims and promote further research. This open collaborative culture means that many of the latest datasets and models are available to the public, and top models can be easily applied, often without needing retraining.
Of course, if objects that need to be recognized, such as “tape_player” and “grey_whale” (perhaps “machine_1” or “door_7”), are not covered, it is necessary to collect custom data and annotations. However, in most cases, new data can simply be used to retrain the latest models and still maintain good performance.
Image Classification (Single Label)

Object Localization (Multiple Bounding Boxes)
Frustum PointNets (2017), AP = 84.00%
Semantic Segmentation (Multiple Category Segmentation)

Instance Segmentation (Multiple Instance Segmentation)
 EfficientPS (2019), AP = 39.1%
EfficientPS (2019), AP = 39.1%03. Possible Commercial Applications
Now that we understand what computer vision is, why it is useful, and how it is executed, what potential applications are there for businesses? Unlike text or database records, images are often not well categorized and stored by companies. However, we believe that companies in certain specialized fields will have the data and motivation to benefit from extracting additional value from their stored image data using computer vision.
Industry
The first area is manufacturing, resource extraction, and construction. These companies typically produce products in large quantities, extract resources, or build civil engineering projects, and many monitoring or predictive analyses are done manually or using simple analytical techniques. However, we believe that computer vision would be useful for automating the following tasks:
Defect Detection, Quality Control: By learning the appearance of normal products, computer vision systems can flag potential defects when machine operators detect them (e.g., AiBuild’s Ai Maker)

Predictive Maintenance: By understanding what a given machine looks like as its lifespan nears its end, computer vision systems can monitor machines in real time, quantify their status (e.g., 90% strength), and predict when maintenance is needed
Remote Measurement: By learning to draw a bounding box around objects of interest (e.g., cracks in materials), computer vision systems can determine the actual size of that object
Robotics: By learning to recognize objects in their field of view, computer vision systems embedded within robots can learn to manipulate objects (e.g., in factories) or navigate their environments
Medical Field
The medical field is another area that can benefit from computer vision, as many tasks focus on monitoring and measuring the physical conditions of human patients (rather than machines or manufactured goods).
Medical Diagnosis Assistance Tools: By learning the appearance of diagnostic tissues of interest to doctors, computer vision systems can suggest relevant areas and speed up the diagnosis process (e.g., using HistoSegNet to segment histological types from pathological slices)
Remote Measurement: Similarly, by learning to draw bounding boxes around objects of interest (e.g., lesions), computer vision systems can determine the actual size of that object to monitor patient progress over time (e.g., Swift Skin and Wound from Swift Medical)

Documents and Multimedia
Documents and multimedia are another area that can benefit from computer vision, as most companies store large amounts of unstructured (and unannotated) information in the form of scanned documents, images, and videos. Although most companies tend not to label these images, some may have useful labels that can be leveraged (e.g., product information from online retail stores).
Optical Character Recognition (OCR): Can recognize and extract text from scanned documents for further processing
Image Search Engines: Images can be used to search for other images (e.g., for online retail websites, searching for visually similar products or styles to recently purchased items)
Visual Question Answering (VQA): Users can ask computer vision systems questions about the scenes depicted in images and receive responses in natural language – this is important for video captioning.

Video Summarization: Computer vision systems can summarize events in videos and return concise summaries – this is crucial for automatically generating video descriptions.

Retail and Surveillance
Retail (which we have mentioned before) and surveillance are other fields that can benefit from computer vision. They rely on real-time monitoring of human actors and their behaviors to optimize desired outcomes (e.g., purchasing behaviors, illegal activities). If the behavior can be visually observed, computer vision can be a great solution.
Human Activity Recognition: Computer vision systems can be trained to recognize the current activities of humans in video feeds (e.g., walking, sitting), which is useful for quantifying the number of people sitting in a crowd or identifying bottlenecks in crowd flow.
Human Pose Estimation: Computer vision systems can also be trained to locate the positions and orientations of human joints, which is very useful for virtual reality interactions, gesture control, or analyzing human movements for medical or athletic purposes.
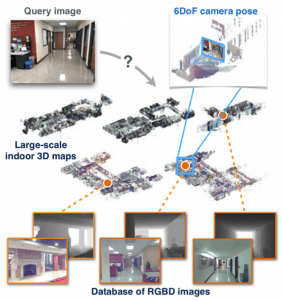
Indoor Visual Localization: Computer vision systems can be used to match the current real-time images or video feeds of indoor environments with a database of known snapshots and locate the current user’s position within that indoor environment (e.g., a user taking a photo indoors at a university campus and having an app display their location).
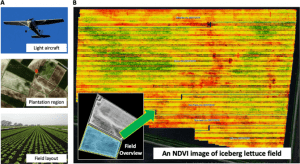
Satellite Imagery
Satellite imagery is the last area where we can see the usefulness of computer vision, as it is often used to monitor land use and environmental changes over time through tedious manual annotations by experts. If trained, computer vision systems can accelerate real-time analysis of satellite images and assess which areas are affected by natural disasters or human activities.
Vessel/Wildlife Tracking: Through satellite imagery or ports or wildlife reserves, computer vision systems can quickly count and locate vessels and wildlife without tedious manual annotations and tracking.


Crop/Livestock Monitoring: Computer vision systems can also monitor the conditions of agricultural land (e.g., by locating diseased or low-yield areas) to optimize pesticide use and irrigation distribution.
As we can see, computer vision offers many applications for businesses. However, companies should first consider the following points:
lData: Are you obtaining image data from third parties or vendors, or are you collecting image data yourself? Most digital datais unavailable or unanalyzed
lAnnotations: Are you obtaining annotations from third parties or vendors, or are you collecting annotations yourself?
lProblem Statement: What kind of problem are you trying to solve? This is wheredomain expertisecomes into play (for example, is it sufficient to detect when a machine is defective (image recognition), or do we also need to locate the defective area (object detection)?
lTransfer Learning: Can a pre-trained model perform the job well (if so, less R&D work is needed)?
lComputational Resources: Do you have enough computational power for training/inference (computer vision models typically require cloud computing or powerful localGPUs)?
lHuman Resources: Do you have enough time or expertise to implement the model (computer vision typically requires machine learning engineers, data scientists, or research scientists with graduate-level education who dedicate their time to research problems)?
lTrust Issues: Do end users/customers trust computer vision methods? Good relationships must be established, and interpretable approaches must be adopted to ensure transparency and accountability, fostering higher user acceptance.
Discussion Group
Welcome to join the reader group of the public account to communicate with peers. Currently, there are WeChat groups on SLAM, 3D Vision, Sensors, Autonomous Driving, Computational Photography, Detection, Segmentation, Recognition, Medical Imaging, GAN, Algorithm Competitions, etc. (will gradually be subdivided later). Please scan the WeChat ID below to join the group, and note: “Nickname + School/Company + Research Direction”, for example: “Zhang San + Shanghai Jiao Tong University + Vision SLAM”. Please follow the format for notes; otherwise, it will not be approved. Once added successfully, you will be invited into the relevant WeChat group based on your research direction. Please do not send advertisements in the group, otherwise, you will be removed from the group. Thank you for your understanding~

