

In the previous article, I introduced how to deploy large models locally on Mac computers. By customizing prompts, various needs such as domain extraction can be achieved.
However, in reality,<span><span> deploying large models locally</span></span> is not very friendly for individual developers. On one hand, it requires a significant investment to ensure that the hardware has enough computational power to support the training and inference of LLMs; on the other hand, the scale of locally deployed large models is usually not very large, so the results may not be ideal.
For individual developers, the fastest way to develop an AI application is to integrate an API from a large model platform. In this case, all costs mainly reflect in Token expenditure. Here are the Token prices from major LLM platforms:
Tongyi Qianwen
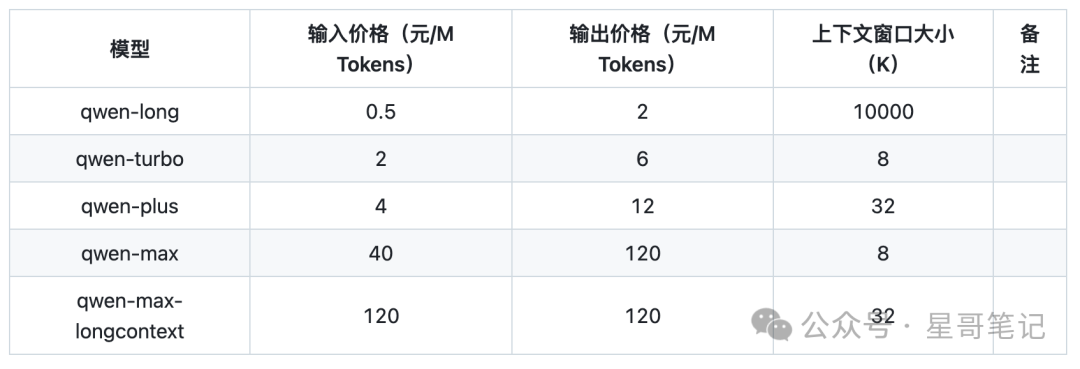
Zhiyu
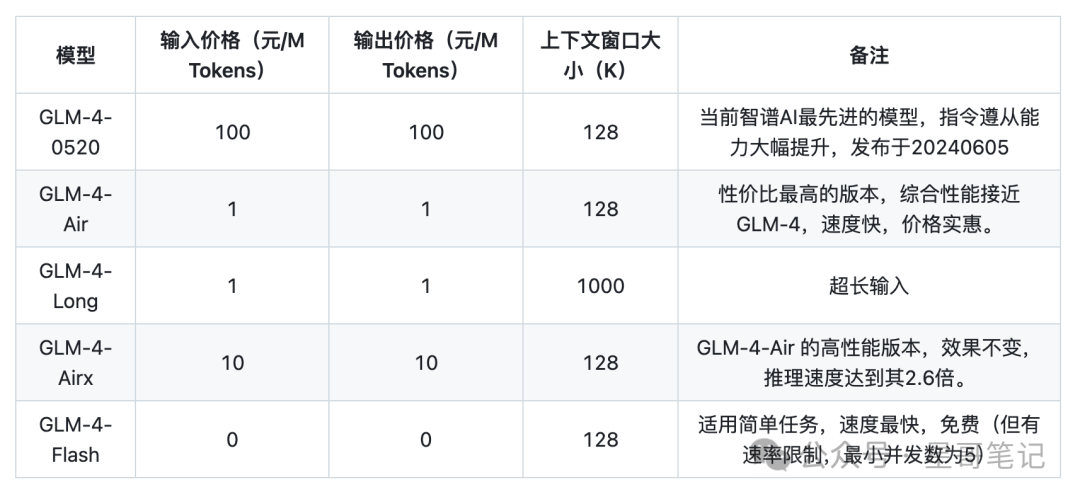
Baidu Wenxin Ernie
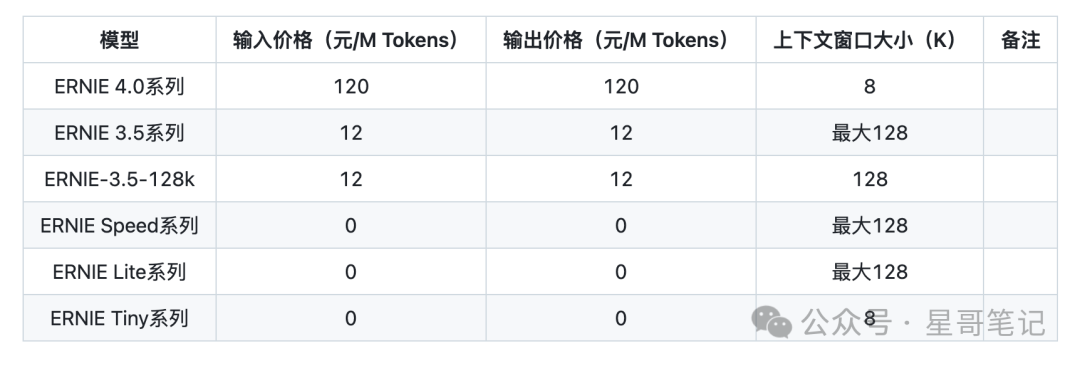
The Dark Side of the Moon Kimi

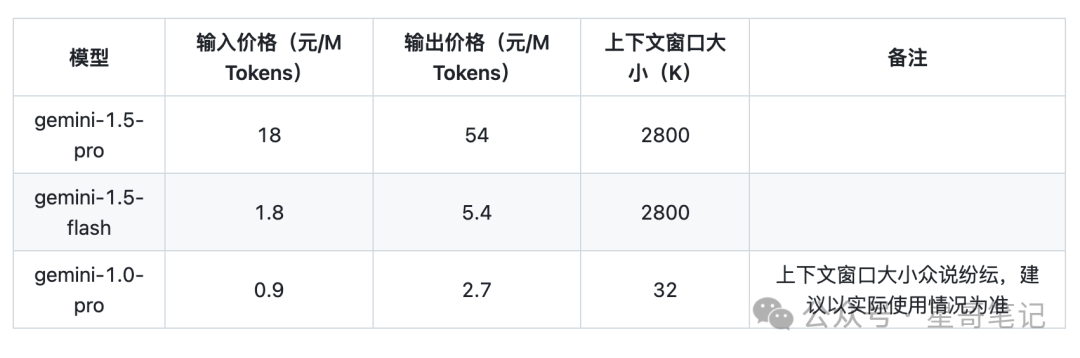
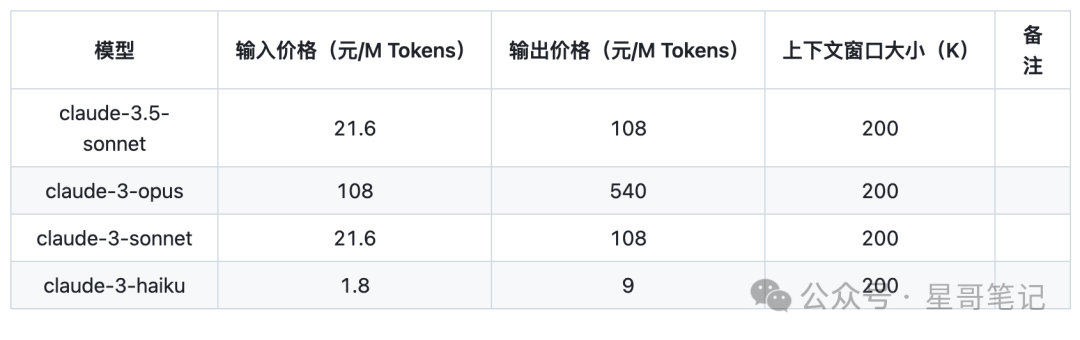
Next, I will use the Tongyi Qianwen platform to implement a pseudo-requirement and see the specific Token usage.
In fact, each platform provides a certain amount of free Tokens. The reason for choosing Tongyi Qianwen is that it is relatively inexpensive.

Implementing a search for exhibition halls using Tongyi Qianwen
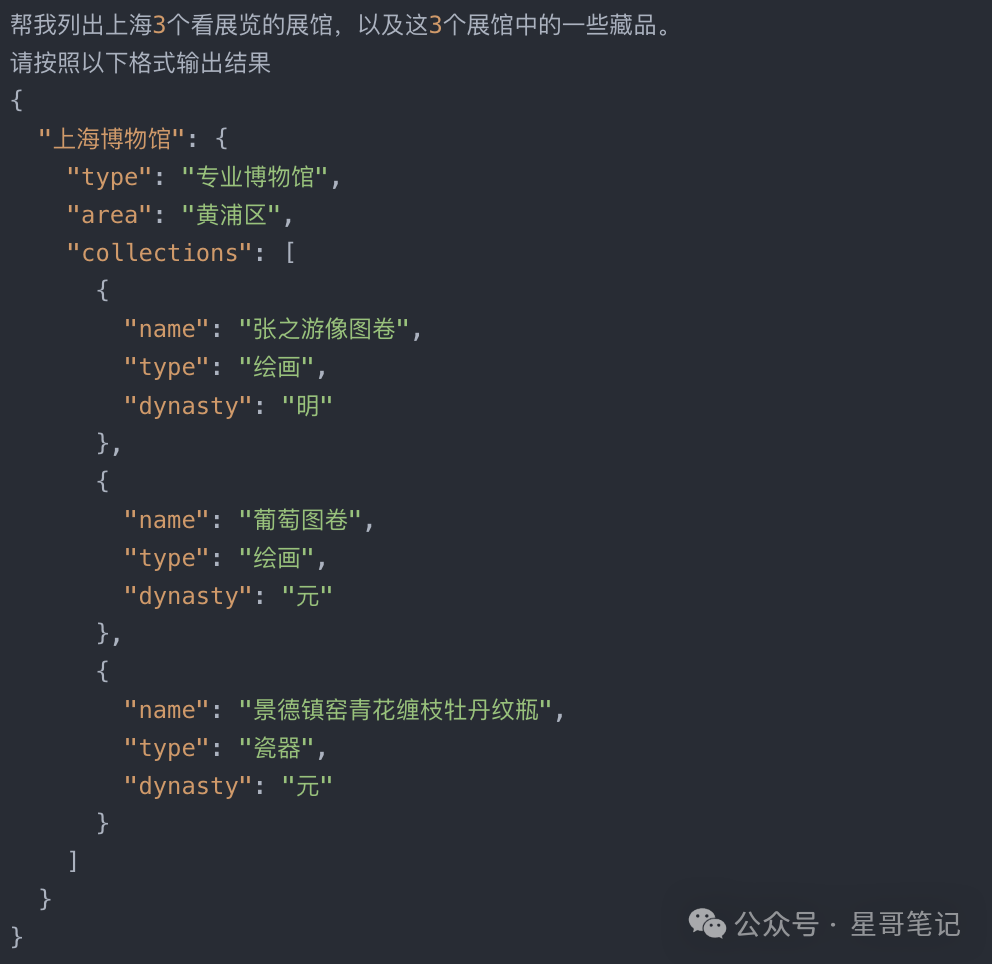
The pseudo-requirement I will implement is: list three exhibition halls in a certain city and introduce some collections of each exhibition hall.
Return in JSON format
By customizing the Prompt, we can have the large model return data in a fixed format, a commonly used format is JSON. The Prompt is as follows:
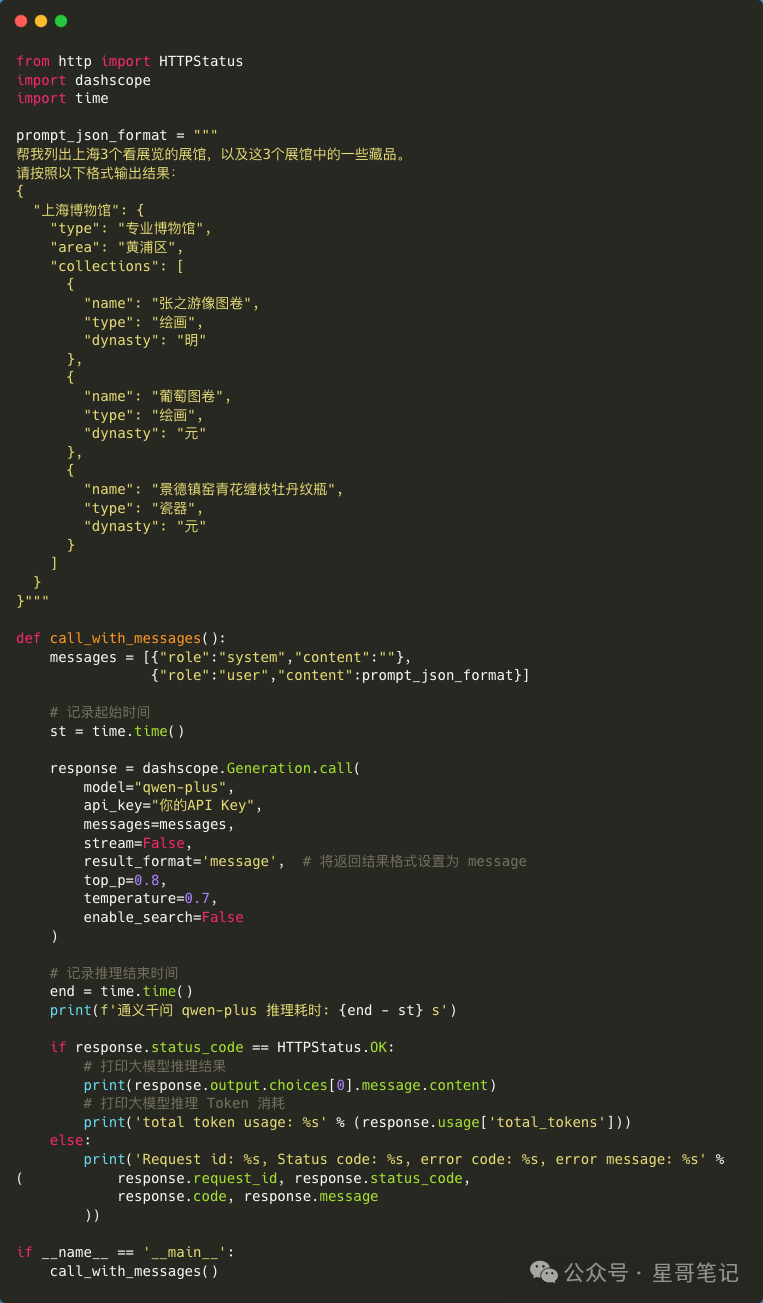

<span>1000000/543 = 1841</span> requests.1000 users * 10 requests * Tokens per request 543 = 5430000 Tokens
As a qualified poor person, it is essential to conserve Token usage. How to optimize prompts to reduce Token usage while maintaining accuracy is particularly important.
Simplifying JSON Format
Based on the JSON format, simplify the format and remove unnecessary content. The following content is added to the previous Prompt:
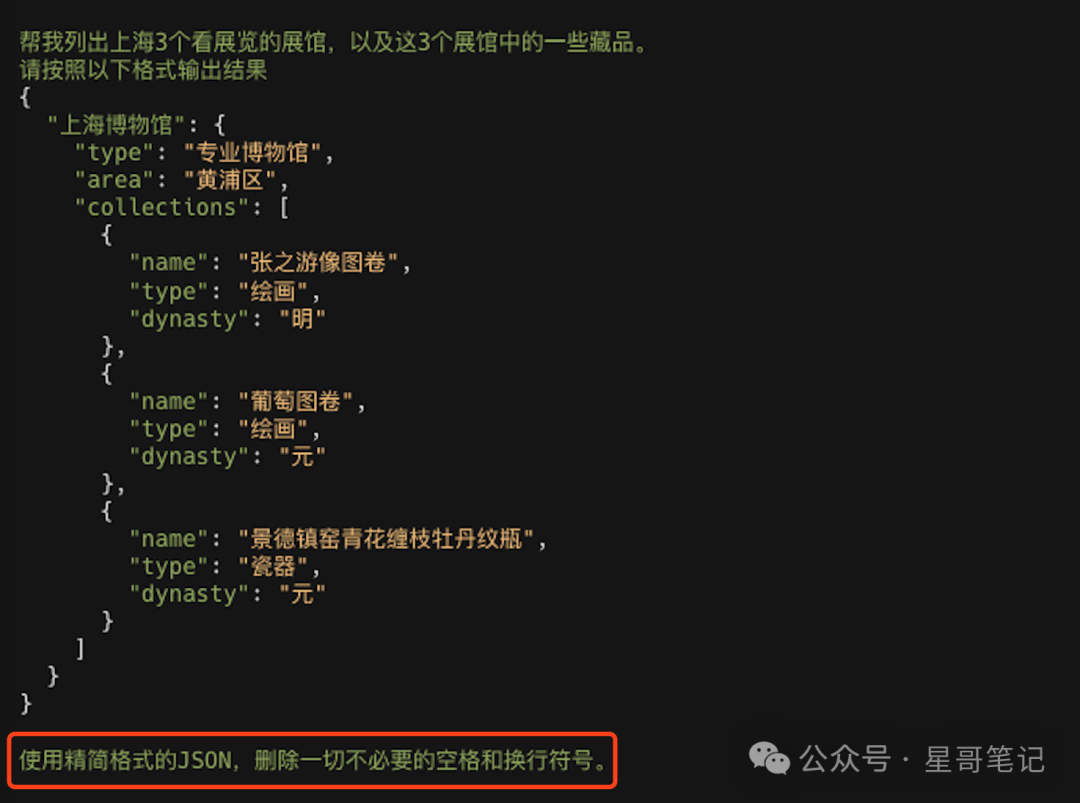
It can be seen that the Prompt has added a line “Use simplified JSON mode, removing all unnecessary spaces and line breaks”.
The specific modified code is as follows:
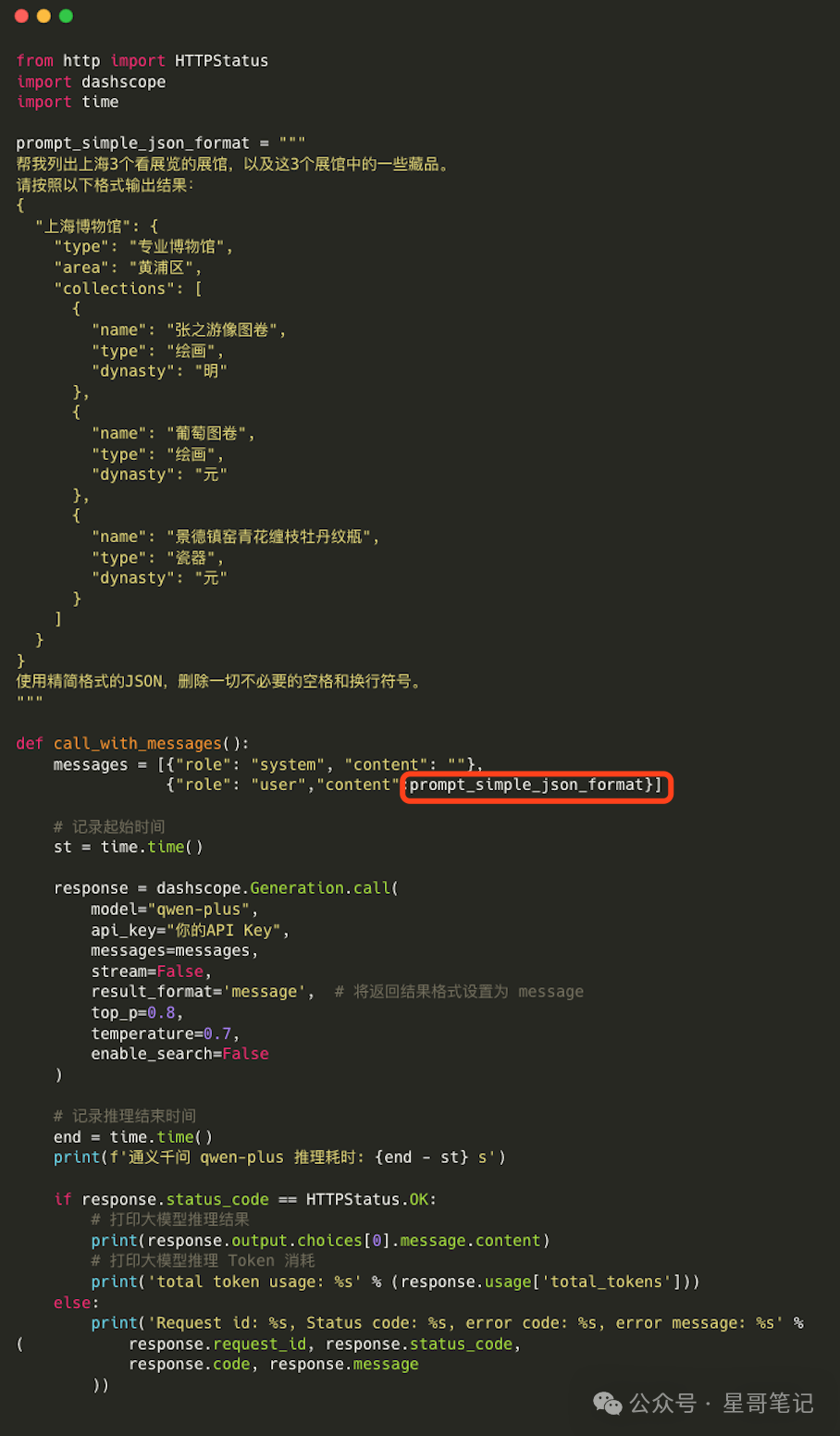
Running the above code, the final return result is as follows:
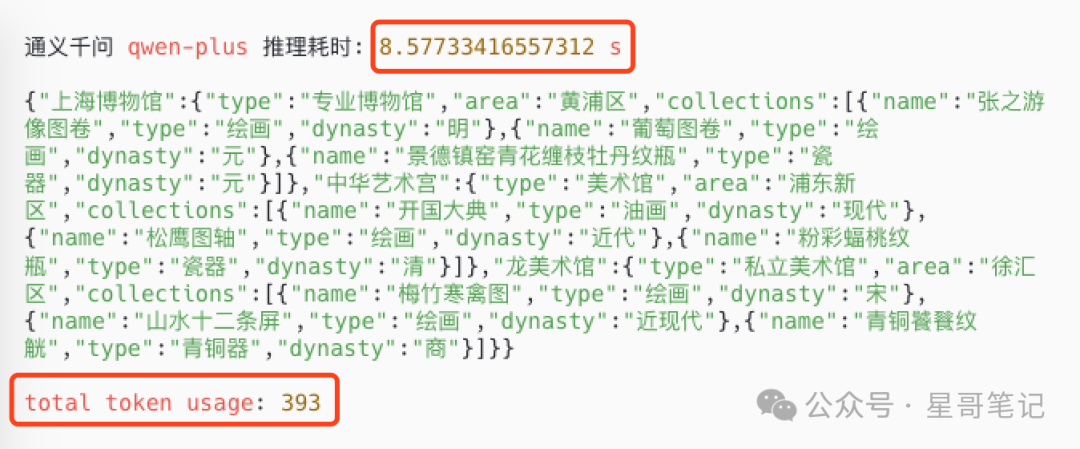
It is obvious that performance has significantly improved: inference time optimized to 8 seconds, and Token consumption reduced to 393.
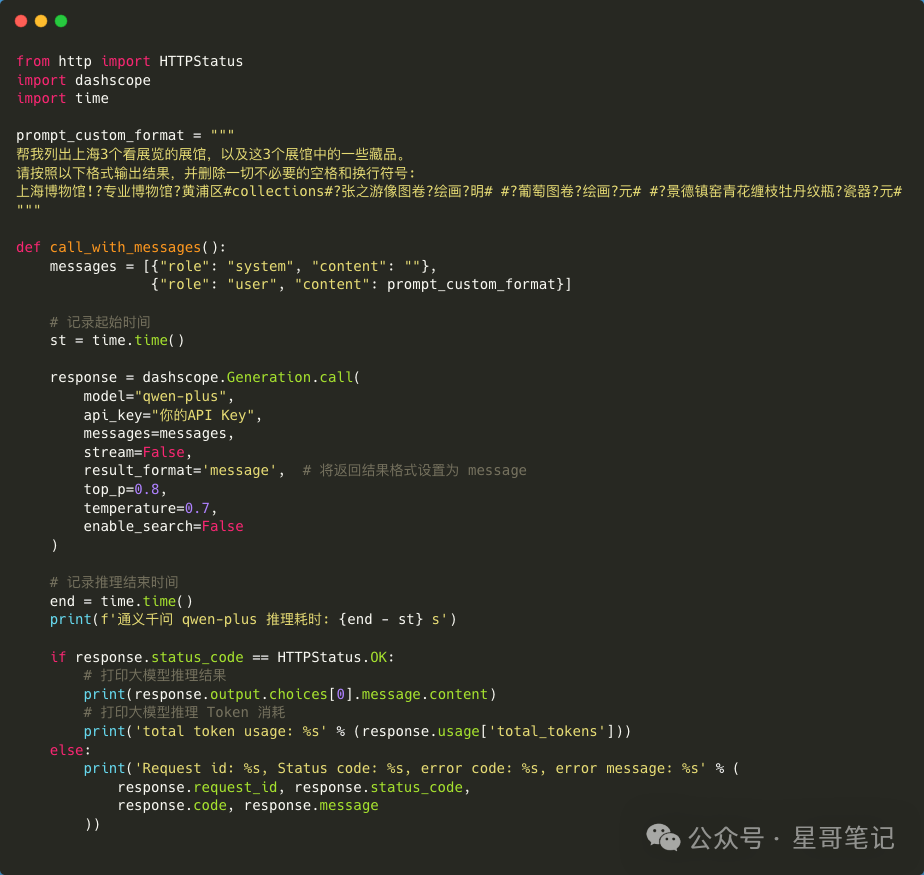
Using Custom Format
In fact, even the simplified JSON format is still a relatively complex data format. We can define a simpler custom format to further reduce the inference time of the large model and Token usage.
For example, the following format:

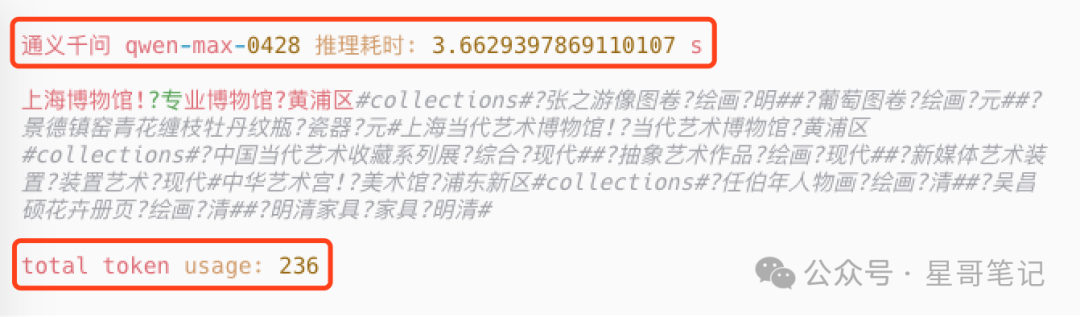
In the above image, our custom format is represented by the ! symbol for a JSON Object, the ? symbol for a string, and the # symbol for an array object.

If you like this article
Long press the QR code to follow

