If you find this article helpful, please give it a thumbs up and follow us ~~~
Send a private message on WeChat to receive free AI, C++, and other related materials, continuously collected and updated!
• Hello everyone, I am Student Xiao Zhang, sharing AI knowledge and practical cases daily
• Welcome to like + follow 👏, continue learning, and continue delivering valuable content.
• +v: jasper_8017 Let’s communicate 💬 and improve together 💪, with more professional materials to receive!
Send a private message on WeChat to receive free AI, C++, and other related materials, continuously collected and updated! Including but not limited to:
1. Tsinghua University 104-page “DeepSeek: From Beginner to Expert”.pdf
2. DeepSeek User Manual (24 pages).pdf
3. Tsinghua University 35-page “How DeepSeek Empowers Workplace Applications.pdf”
4. “How to Ask ChatGPT for High-Quality Answers: A Complete Guide to Prompt Engineering”
5. “OpenAI: Best Practices for GPT (Layman’s Version)”
6. Selected E-books on Artificial Intelligence
In the field of artificial intelligence, the effectiveness of large models generated is often closely related to the quality of the input prompts. Designing high-quality prompts has become key to enhancing model performance. MetaGPT introduces the SPO strategy (Sequential Prompt Optimization), providing us with an efficient and automated prompt optimization solution that allows us to continuously improve generation results through multiple iterations.
Today, we will delve into MetaGPT’s SPO prompt optimization strategy, analyze the underlying process, and gain a deeper understanding of this automatic prompt optimization strategy through code examples.
1. What is the SPO Strategy?
SPO (Self-Supervised Prompt Optimization) is a multi-round optimization strategy that gradually adjusts and optimizes prompts so that the model can better understand and generate outputs that meet requirements. In each round of optimization, the system adjusts the prompts based on the previous output and evaluates their effectiveness. Ultimately, after multiple iterations, the model will produce an optimal result.
2. Workflow of the SPO Strategy
The core workflow of the SPO strategy includes three important tasks:
-
1. Optimize Prompts: Generate better versions based on existing prompts. -
2. Evaluate the Model: Determine whether the optimized prompts improve output quality. -
3. Execute the Model: Generate outputs based on the optimized prompts.
These three models are responsible for different tasks, working closely together to continuously enhance the quality of the prompts.
2.1 Optimization Model
In each round of optimization, the SPO strategy generates new prompts based on the best prompts and answers from the previous round using the optimization model. The goal of the optimization model is to better meet user needs, thereby generating higher-quality outputs.
2.2 Evaluation Model
Each new prompt generated in each round is evaluated by the evaluation model. The evaluation model determines whether the newly generated answers better meet the requirements. If the new answers are better than the original ones, the new prompts are considered effective and enter the next round of optimization; otherwise, the original prompts are retained.
2.3 Execution Model
The task of the execution model is to generate the final answers based on the optimized prompts. This process determines whether the effects of the optimization can be reflected in practical applications.
3. Key Code Analysis
The implementation of the SPO strategy in MetaGPT is completed through the <span>PromptOptimizer</span> class. Below are some key code snippets and their explanations:
3.1 Initialize Optimization Tasks
SPO_LLM.initialize(
optimize_kwargs={"model": args.opt_model, "temperature": args.opt_temp},
evaluate_kwargs={"model": args.eval_model, "temperature": args.eval_temp},
execute_kwargs={"model": args.exec_model, "temperature": args.exec_temp},
)In this code, three different models are initialized: the optimization model, evaluation model, and execution model. The parameters (such as temperature) of each model can be adjusted according to needs.
Demo file: MetaGPT/examples/spo/optimize.py
3.2 Optimization Function
optimizer = PromptOptimizer(
optimized_path=args.workspace,
initial_round=args.initial_round,
max_rounds=args.max_rounds,
template=args.template,
name=args.name,
)
optimizer.optimize()<span>PromptOptimizer</span> class is responsible for executing the entire optimization process. Through the <span>optimize()</span> method, it begins multi-round optimization, generating new prompts in each round and evaluating and adjusting them.
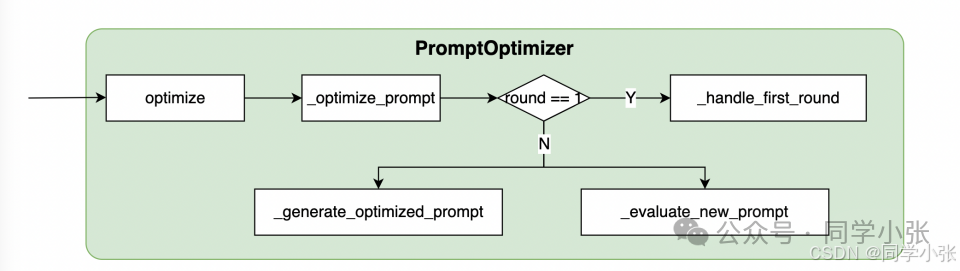
Each round’s execution function is as follows: <span>self._optimize_prompt()</span> function
async def _optimize_prompt(self):
prompt_path = self.root_path / "prompts"
load.set_file_name(self.template)
data = self.data_utils.load_results(prompt_path)
if self.round == 1:
await self._handle_first_round(prompt_path, data)
return
directory = self.prompt_utils.create_round_directory(prompt_path, self.round)
new_prompt = await self._generate_optimized_prompt()
self.prompt = new_prompt
logger.info(f"\nRound {self.round} Prompt: {self.prompt}\n")
self.prompt_utils.write_prompt(directory, prompt=self.prompt)
success, answers = await self._evaluate_new_prompt(prompt_path, data, directory)
self._log_optimization_result(success)
return self.prompt3.3 Special Handling for the First Optimization
async def _handle_first_round(self, prompt_path: Path, data: List[dict]) -> None:
logger.info("\n⚡ RUNNING Round 1 PROMPT ⚡\n")
directory = self.prompt_utils.create_round_directory(prompt_path, self.round)
prompt, _, _, _ = load.load_meta_data()
self.prompt = prompt
self.prompt_utils.write_prompt(directory, prompt=self.prompt)
new_samples = await self.evaluation_utils.execute_prompt(self, directory)
_, answers = await self.evaluation_utils.evaluate_prompt(
self, None, new_samples, path=prompt_path, data=data, initial=True
)
self.prompt_utils.write_answers(directory, answers=answers)The handling of the first optimization is different from subsequent optimizations because there is no historical data for reference. In this round, the optimizer generates new results based on the initial prompts and evaluates them. The main steps are as follows:
(1) Create a directory for this round (2) Load the original prompt: <span>load.load_meta_data()</span> (3) Write the original prompt into this round’s directory (4) Execute the prompt to generate answers: <span>self.evaluation_utils.execute_prompt</span> (5) Evaluate the generated answers: <span>self.evaluation_utils.evaluate_prompt</span> (6) Write local answers into this round’s directory
3.4 Generate Optimized Prompts
async def _generate_optimized_prompt(self):
_, requirements, qa, count = load.load_meta_data()
samples = self.data_utils.get_best_round()
logger.info(f"\n🚀Round {self.round} OPTIMIZATION STARTING 🚀\n")
logger.info(f"\nSelecting prompt for round {samples['round']} and advancing to the iteration phase\n")
golden_answer = self.data_utils.list_to_markdown(qa)
best_answer = self.data_utils.list_to_markdown(samples["answers"])
optimize_prompt = PROMPT_OPTIMIZE_PROMPT.format(
prompt=samples["prompt"],
answers=best_answer,
requirements=requirements,
golden_answers=golden_answer,
count=count,
)
response = await self.llm.responser(
request_type=RequestType.OPTIMIZE, messages=[{"role": "user", "content": optimize_prompt}]
)
modification = extract_content(response, "modification")
logger.info(f"Modification of {self.round} round: {modification}")
prompt = extract_content(response, "prompt")
return prompt if prompt else ""Each round of optimization will generate new optimized prompts based on the best results<span>get_best_round()</span> from the previous round, thereby enhancing the final output effects.
The prompt template for optimizing prompts is as follows:
PROMPT_OPTIMIZE_PROMPT = """
You are building a prompt to address user requirement. Based on the given prompt,
please reconstruct and optimize it. You can add, modify, or delete prompts. Please include a single modification in
XML tags in your reply. During the optimization, you can incorporate any thinking models.
This is a prompt that performed excellently in a previous iteration. You must make further optimizations and improvements based on this prompt. The modified prompt must differ from the provided example.
requirements:
{requirements}
reference prompt:
{prompt}
The execution result of this reference prompt is(some cases):
{answers}
The best answer we expect(some cases):
{golden_answers}
Provide your analysis, optimization points, and the complete optimized prompt using the following XML format:
<analyse>Analyze what drawbacks exist in the results produced by the reference prompt and how to improve them.</analyse>
<modification>Summarize the key points for improvement in one sentence</modification>
<prompt>Provide the complete optimized prompt {count}</prompt>
"""3.5 Execute Prompt
Utilize large models to execute prompts and normally generate answers corresponding to that prompt.
async def execute_prompt(self, optimizer: Any, prompt_path: Path) -> dict:
optimizer.prompt = optimizer.prompt_utils.load_prompt(optimizer.round, prompt_path)
executor = QuickExecute(prompt=optimizer.prompt)
answers = await executor.prompt_execute()
cur_round = optimizer.round
new_data = {"round": cur_round, "answers": answers, "prompt": optimizer.prompt}
return new_data3.6 Evaluate Prompt
prompt_evaluate, TRUE indicates that the newly generated answers are good, meaning the new optimized prompt is good; FALSE indicates that the original answers are better, meaning the optimized prompt is not as good as the original prompt.
async def prompt_evaluate(self, samples: dict, new_samples: dict) -> bool:
_, requirement, qa, _ = load.load_meta_data()
if random.random() < 0.5:
samples, new_samples = new_samples, samples
is_swapped = True
else:
is_swapped = False
messages = [
{
"role": "user",
"content": EVALUATE_PROMPT.format(
requirement=requirement, sample=samples, new_sample=new_samples, answers=str(qa)
),
}
]
try:
response = await self.llm.responser(request_type=RequestType.EVALUATE, messages=messages)
choose = extract_content(response, "choose")
return choose == "A" if is_swapped else choose == "B"
except Exception as e:
logger.error(e)
return FalseThe template for evaluating is as follows:
EVALUATE_PROMPT = """
Based on the original requirements, evaluate the two responses, A and B, and determine which one better meets the requirements. If a reference answer is provided, strictly follow the format/content of the reference answer.
# Requirement
{requirement}
# A
{sample}
# B
{new_sample}
# Golden answer
{answers}
Provide your analysis and the choice you believe is better, using XML tags to encapsulate your response.
<analyse>Some analysis</analyse>
<choose>A/B (the better answer in your opinion)</choose>
"""3.7 Evaluate New PROMPT
async def _evaluate_new_prompt(self, prompt_path, data, directory):
logger.info("\n⚡ RUNNING OPTIMIZED PROMPT ⚡\n")
new_samples = await self.evaluation_utils.execute_prompt(self, directory)
logger.info("\n📊 EVALUATING OPTIMIZED PROMPT 📊\n")
samples = self.data_utils.get_best_round()
success, answers = await self.evaluation_utils.evaluate_prompt(
self, samples, new_samples, path=prompt_path, data=data, initial=False
)
self.prompt_utils.write_answers(directory, answers=answers)
return success, answers3.8 Get Best Round
def get_best_round(self):
self._load_scores()
for entry in self.top_scores:
if entry["succeed"]:
return entry
return None4. How to Use the SPO Strategy?
MetaGPT provides several different usage methods, allowing users to choose the most suitable way to optimize based on their needs:
4.1 Using Python Scripts
Directly launch the optimization task using a Python script:
from metagpt.ext.spo.components.optimizer import PromptOptimizer
from metagpt.ext.spo.utils.llm_client import SPO_LLM
if __name__ == "__main__":
# Initialize LLM settings
SPO_LLM.initialize(
optimize_kwargs={"model": "claude-3-5-sonnet-20240620", "temperature": 0.7},
evaluate_kwargs={"model": "gpt-4o-mini", "temperature": 0.3},
execute_kwargs={"model": "gpt-4o-mini", "temperature": 0}
)
# Create and run optimizer
optimizer = PromptOptimizer(
optimized_path="workspace", # Output directory
initial_round=1, # Starting round
max_rounds=10, # Maximum optimization rounds
template="Poem.yaml", # Template file
name="Poem", # Project name
)
optimizer.optimize()4.2 Command Line Interface (CLI)
Start optimization using the command line:
python -m examples.spo.optimizeRequired parameters include:
--opt-model Model for optimization (default: claude-3-5-sonnet-20240620)
--opt-temp Temperature for optimization (default: 0.7)
--eval-model Model for evaluation (default: gpt-4o-mini)
--eval-temp Temperature for evaluation (default: 0.3)
--exec-model Model for execution (default: gpt-4o-mini)
--exec-temp Temperature for execution (default: 0)
--workspace Output directory path (default: workspace)
--initial-round Initial round number (default: 1)
--max-rounds Maximum number of rounds (default: 10)
--template Template file name (default: Poem.yaml)
--name Project name (default: Poem)4.3 Streamlit Web Interface
If you want a more intuitive interface to configure and run optimization tasks, you can use the Streamlit web interface:
pip install "streamlit~=1.42.0"
python -m streamlit run metagpt/ext/spo/app.py4.4 Create Your Iteration Template Before Use
Create an iteration template and place it in metagpt/ext/spo/settings/task_name.yaml.
prompt: |
Please solve the following problem.
requirements: |
...
count: None
qa:
- question: |
...
answer: |
...
- question: |
...
answer: |
...-
• prompt: Initial prompt for iteration -
• requirements: Expected effects/results (e.g., generate more thoughts, use more humorous language) -
• count: Target word count for the generated prompt (e.g., 50). Set to “None” for unlimited -
• Common Questions: QA pairs for iteration can include an appropriate number of pairs (usually 3 pairs) -
• Questions: Questions in the dataset for iteration -
• Answers: Corresponding answers. Can include desired thinking patterns or responses rather than actual answers, or can be left blank.
Refer to metagpt/ext/spo/settings/Navigate.yaml
5. Directory Structure and Results
Each optimization result will be stored in the specified working directory. Taking <span>workspace</span> as an example, the optimization results will be stored in the following structure:
workspace
└── Project_name
└── prompts
├── results.json
├── round_1
│ ├── answers.txt
│ └── prompt.txt
├── round_2
│ ├── answers.txt
│ └── prompt.txt
├── round_3
│ ├── answers.txt
│ └── prompt.txt
└── ...-
• results.json: Records the success or failure of each round of optimization and related information. -
• prompt.txt: The prompts generated after each round of optimization. -
• answers.txt: The output results generated after each round of optimization.
6. Conclusion
Through MetaGPT’s SPO prompt optimization strategy, we can continuously optimize prompts and enhance the performance of generation models across multiple iterations. Whether through Python scripts, command line, or web interface, MetaGPT provides flexible usage methods to help you easily perform optimization tasks.
I hope that through today’s introduction, you can better understand and apply the SPO strategy, making your prompts more intelligent with each round of optimization!
If you find this article helpful, please give it a thumbs up and follow us ~~~