
Natural Language Processing (NLP) Library
The Natural Language Processing (NLP) library is a set of software tools and programs for processing and analyzing human language.These libraries provide a range of features to help computers understand, interpret, and generate human language, enabling applications such as machine translation, sentiment analysis, text summarization, keyword extraction, and speech recognition.
In Python, there are several widely used NLP libraries, such as:
1. NLTK (Natural Language Toolkit): NLTK is a powerful NLP library that provides a wide range of tools and resources for processing text data. It supports functionalities such as tokenization, part-of-speech tagging, named entity recognition, and parsing.
2. spaCy: spaCy is a high-performance NLP library that offers a fast and practical API for processing text. spaCy supports multiple languages and provides features such as tokenization, part-of-speech tagging, named entity recognition, and dependency parsing.
3. TextBlob: TextBlob is a simple API for processing text data. It is built on top of NLTK and spaCy, providing functionalities such as tokenization, part-of-speech tagging, and sentiment analysis.
4. gensim: gensim is a Python library for topic modeling and document similarity analysis. It provides algorithms such as TF-IDF, LSA, and LDA for processing large-scale text data.
5. transformers: transformers is a library based on PyTorch and TensorFlow that provides pre-trained models for natural language understanding, such as BERT and GPT-2. It supports tasks like text classification, named entity recognition, and sentiment analysis.
These NLP libraries enable developers and researchers to easily build and deploy various NLP applications.
Introduction
With the remarkable achievements of pre-trained models like BERT, Megatron, and GPT-3 in the NLP field, more and more teams are engaging in large-scale training, which has escalated the scale of model training from hundreds of millions to hundreds of billions and even trillions of parameters. However, deploying such large-scale models in real-world scenarios still presents some challenges. First, the large number of model parameters results in slow training and inference speeds, along with extremely high deployment costs; secondly, in many real-world scenarios, the issue of insufficient data still limits the application of large models in small sample scenarios, making it challenging to improve the generalization of pre-trained models in such contexts. To address these issues, the PAI team launched the EasyNLP Chinese NLP algorithm framework to facilitate the rapid and efficient deployment of large models.
EasyNLP is an open-source natural language processing (NLP) library developed by Alibaba Group. It aims to provide researchers and developers with easy-to-use and powerful tools for rapid prototyping and experimentation in the NLP domain. EasyNLP offers a series of pre-trained models and tools that support various NLP tasks, such as text classification, sentiment analysis, named entity recognition, and machine translation.
Features of EasyNLP include:
– Easy to use: Provides a simple API, allowing users to easily load pre-trained models and perform model training, inference, and other operations.
– Rich pre-trained models: Supports various popular pre-trained models such as BERT, RoBERTa, ALBERT, and models developed by Alibaba.
– Support for various NLP tasks: Provides models and data processing tools tailored for different NLP tasks, capable of easily addressing various text processing needs.
– Extensibility: Supports custom models and data processing workflows, facilitating secondary development and integration by users.
– High performance: During model training and inference, EasyNLP optimizes computational efficiency, supports multi-GPU training, and improves processing speed.
EasyNLP is suitable for academic research and industrial applications, helping users quickly achieve innovation and deployment in the NLP field.
Core Modules
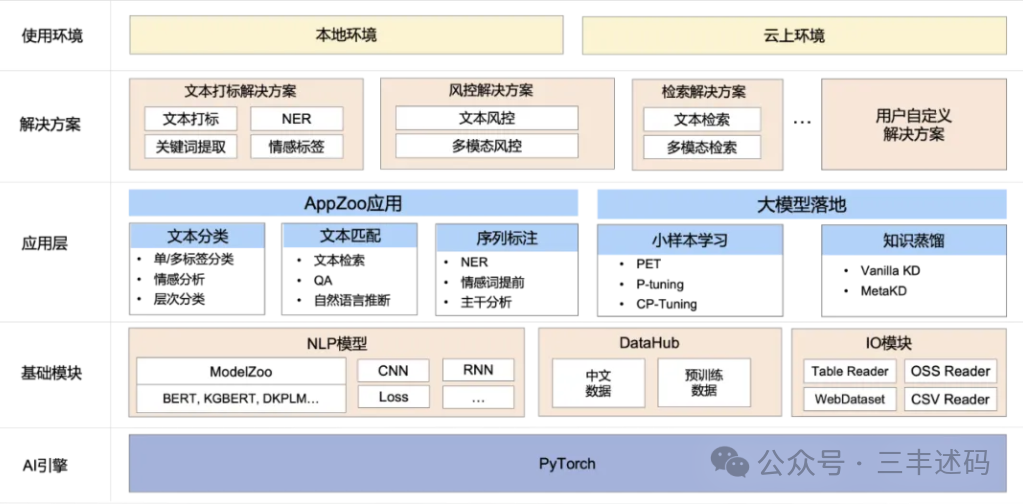
The EasyNLP architecture primarily consists of the following core modules:
-
Basic Module: Provides a pre-trained model library ModelZoo, supporting commonly used Chinese pre-trained models, including BERT, MacBERT, WOBERT, etc.; also offers commonly used NN modules for user-defined models;
-
Application Layer: AppZoo supports common NLP applications such as text classification and text matching; EasyNLP supports pre-trained model deployment tools, including few-shot learning and knowledge distillation, facilitating the rapid deployment of large models, integrating several algorithms developed by the PAI team;
-
NLP Applications and Solutions: Provides multiple NLP solutions and ModelHub models to help users solve business problems;
-
Tool Layer: Can support local service initiation or deployment and invocation on Alibaba Cloud products, such as PAI-DLC, PAI-DSW, PAI-Designer, and PAI-EAS, providing users with an efficient complete experience from training to deployment.
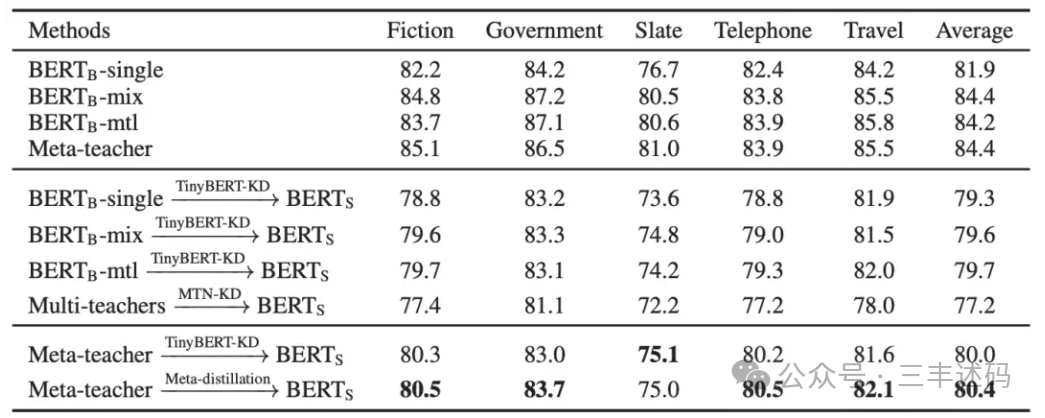
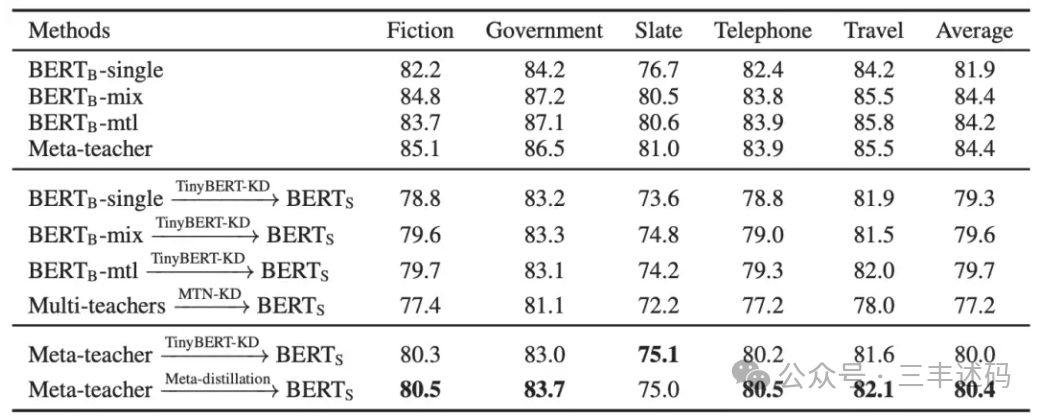
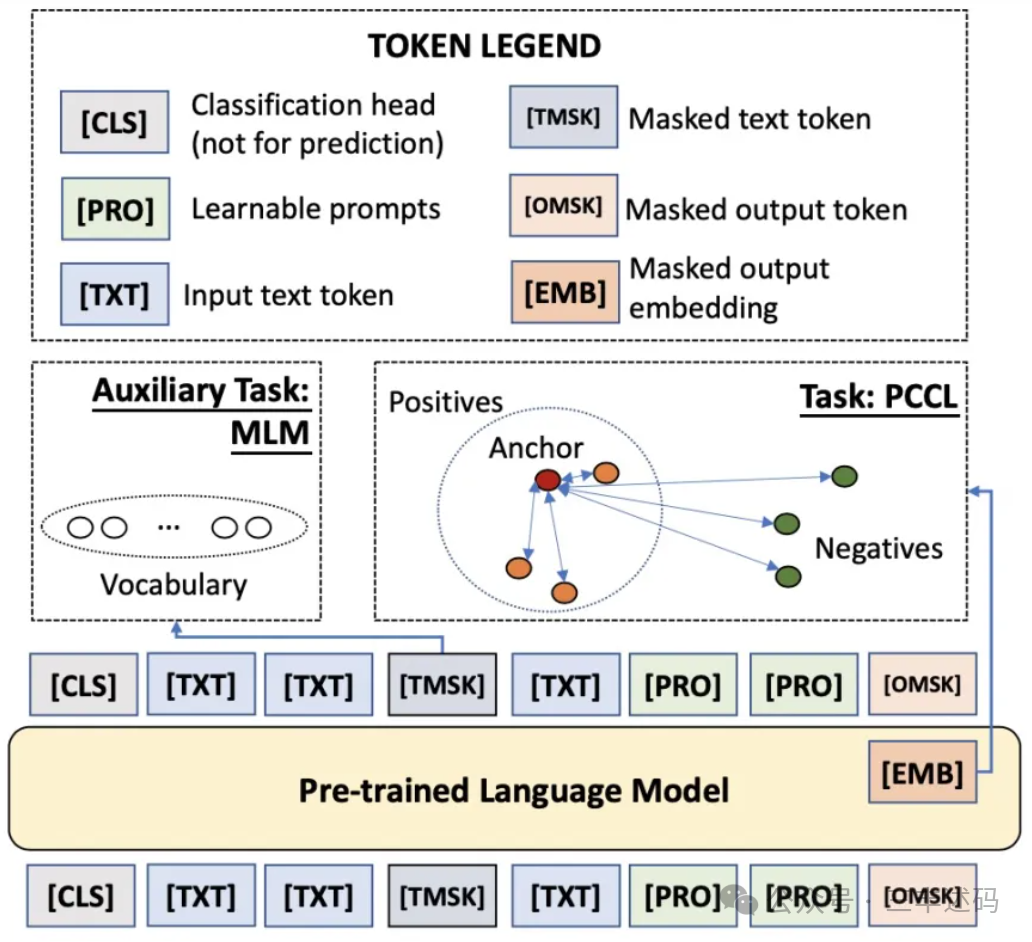
Knowledge Distillation Technology for Large Models
Knowledge distillation technology is a method of transferring knowledge from a large neural network (also known as the teacher model) to a smaller neural network (also known as the student model). The goal of this technology is to reduce the size of the model while maintaining performance, thus lowering the computational cost and storage requirements of the model, making it more suitable for deployment in resource-constrained environments.
Knowledge distillation typically involves the following steps:
1. Training the Teacher Model: First, train a large, complex neural network model that performs well on a specific task.
2. Distillation Process: During the distillation process, both the teacher model and the student model run the same input data simultaneously. The output of the teacher model includes class probability distributions that contain rich information about the input data. The student model then attempts to learn these probability distributions.
3. Soft Label Generation: The output of the teacher model is usually transformed using a technique called temperature scaling to generate soft labels. These soft labels contain similarity information between different classes, aiding the student model in learning.
4. Training the Student Model: The student model is typically trained to minimize a loss function that combines predictions of hard labels (true labels in the original dataset) and the soft labels provided by the teacher model.
5. Performance Evaluation: Finally, evaluate the student model to determine whether it can approach the performance of the teacher model.
The key advantage of knowledge distillation technology is that it allows the student model to capture the complexity and generalization ability of the teacher model while reducing the number of parameters and computational complexity. This makes the student model more suitable for deployment in mobile devices, embedded systems, or applications requiring quick responses.
Few-Shot Learning Technology for Large Models
Few-shot learning technology for large models refers to a method of using large-scale pre-trained models to address few-shot learning problems. In few-shot learning, the model needs to quickly adapt to new tasks or categories with only a small number of labeled samples. The few-shot learning technology for large models typically involves the following key steps:
1. Pre-training Phase: First, train a large-scale model using a large amount of unlabeled or semi-labeled data. This model learns rich feature representations through self-supervised learning, unsupervised learning, or weakly supervised learning methods.
2. Fine-tuning Phase: In the fine-tuning phase, adapt the pre-trained large model to new tasks. Since the new task may have only a few labeled samples, carefully designed fine-tuning strategies are needed to avoid overfitting.
3. Meta-Learning: Meta-learning is a method that allows the model to learn how to quickly adapt to new tasks. In the few-shot learning for large models, meta-learning can be used to optimize the model’s parameters, enabling quick adaptation to new categories.
4. Transfer Learning: Transfer learning is utilizing knowledge learned from the source task to improve performance on the target task. In few-shot learning for large models, transfer learning can help the model leverage the general knowledge learned during pre-training to enhance its adaptability to few samples.
5. Data Augmentation: To increase the diversity of the few samples, data augmentation techniques can be used to generate more training samples. These augmented samples can help the model generalize better to unseen data.
6. Model Adaptation: During the fine-tuning phase, it may be necessary to adapt the model to meet the specific requirements of the new task. This may include changing the model structure, adjusting the learning rate, or introducing specific regularization terms.
The goal of few-shot learning technology for large models is to leverage the knowledge learned from large-scale pre-trained models on vast amounts of data so that the model can quickly adapt to new tasks or categories with only a few labeled samples. This approach is particularly useful in many applications, especially in situations where labeled data is scarce or costly to obtain.
Practical Implementation
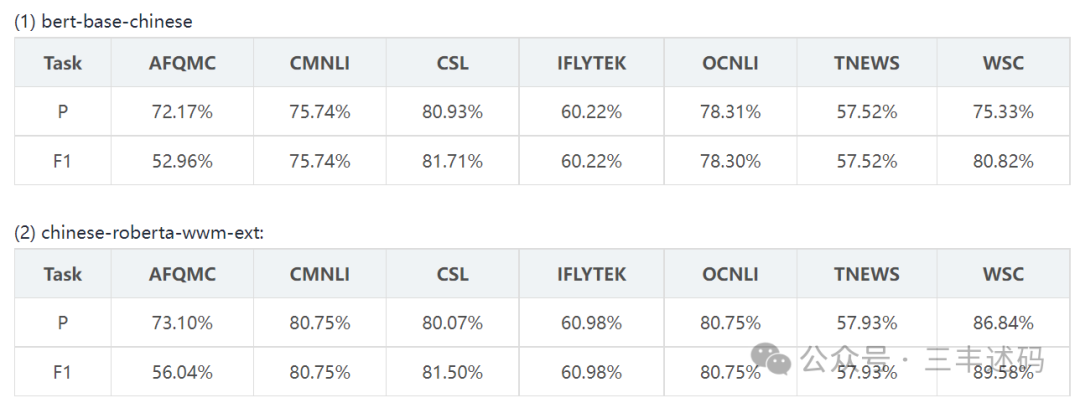
EasyNLP is Alibaba’s open-source natural language processing (NLP) platform, designed to simplify the development and deployment of NLP tasks. EasyNLP provides a series of tools and pre-trained models that support various common NLP tasks, such as text classification, sentiment analysis, named entity recognition, and more. Practical implementation often involves applying EasyNLP to real business scenarios to solve specific NLP problems. Here are some possible practical implementation cases:
1. Text Classification: In scenarios such as news classification, social media analysis, and user comment classification, use EasyNLP for text classification to help enterprises understand user feedback, monitor brand reputation, or automate content review.
2. Sentiment Analysis: In e-commerce platforms, social media, or customer service, use EasyNLP for sentiment analysis to understand consumer sentiment towards products or services, thereby improving product offerings or enhancing service quality.
3. Named Entity Recognition: In information extraction, knowledge graph construction, or document analysis, use EasyNLP to recognize specific entities in text (such as names, locations, organizations, etc.) for automated information extraction or enhanced search capabilities.
4. Machine Translation: In multilingual communication, international business, or cross-language content generation, use EasyNLP’s machine translation capabilities to achieve automatic translation between different languages.
5. Question Answering Systems: In customer service, education, or information retrieval, use EasyNLP to build question-answering systems that provide users with quick and accurate answers.
6. Text Generation: In content creation, advertisement generation, or automated report writing, use EasyNLP’s text generation capabilities to produce coherent text content based on given contexts.
7. Chatbots: In customer service, online consulting, or entertainment interactions, use EasyNLP to build chatbots that interact with users in natural language.
8. Speech Recognition: Combine speech recognition technology with EasyNLP to process and analyze speech data, achieving speech-to-text conversion and further language understanding.
9. Multimodal Applications: In tasks involving both images and text, such as image description generation and image-text matching, use EasyNLP to handle the text portion, combined with image processing technologies for richer applications.
10. Personalized Recommendations: In recommendation systems, use EasyNLP to analyze user comments, feedback, or queries to better understand user preferences and provide personalized recommendations.
These practical implementation cases demonstrate the flexibility and practicality of EasyNLP across different industries and application scenarios. Through these practices, enterprises can more effectively process and analyze large amounts of text data, leading to more informed business decisions.
Open Source Address
/EasyNLPYou May Also Like:
【Open Source】20K Stars! Low-Code Platform to Save You Hundreds of Hours of Work
ERP Management System Built on Open Source Projects, Covering All Aspects of Enterprise Operations, Such as Financial Management, Supply Chain Management, Human Resources Management, Production Management, Customer Relationship Management, Project Management, etc.
【Open Source】Visual Drag-and-Drop Programming, Automatically Generate Projects, Automatically Generate Code, Self-Import Third-Party Components
【Open Source】No-Code, Fully Functional, Highly Secure ORM Library, Zero-Code Backend Interfaces and Documentation, Customized JSON Data and Structure for Frontend (Client)
【Upgrade】UniApp 2.0 Visual Development Tool Update: Improve Development Efficiency, Intuitively Build Application Interfaces, Automatically Generate Code, Template Center Motion Enhancement, Introduction of AI Assistant
Add WeChat to Join Relevant Discussion Groups,
Note “Microservices” to Join the Group Discussion
Note “Low-Code” to Join the Low-Code Group Discussion
Note “AI” to Join the AI Big Data and Data Governance Group Discussion
Note “Digital” to Join the IoT and Digital Twin Group Discussion
Note “Security” to Join Security-Related Group Discussions
Note “Automation” to Join Automation Operations Group Discussions
Note “Trial” to Apply for Product Trials
Note “Channel” for Channel Cooperation Information
Note “Customization” for Custom Projects, Full Source Code Delivery
