
Recently, I saw that ByteDance released a paper on video generation: OmniHuman-1. OmniHuman, a framework based on diffusion Transformer, expands data by mixing motion-related conditions into the training phase.
The model is powerful and can generate videos from just one image and a segment of audio.
OmniHuman supports various visual and audio styles. It can generate realistic human videos in any aspect ratio and body proportion (portrait, half-body, full-body), with realism derived from comprehensive aspects including motion, lighting, and texture details.
Let’s click the video below to see the effect:
Previously, Alibaba also released a model called “EchoMimic”, which is open source. Interested partners can take a look. It can combine images and audio to create digital humans.
OmniHuman is an end-to-end multimodal conditional human video generation framework that can generate human videos based on a single human image and motion signals (for example, a combination of audio, video, or both).
In OmniHuman, we introduce a multimodal motion condition mixing training strategy that allows the model to benefit from mixed condition data expansion. This overcomes the issues faced by previous end-to-end methods due to the scarcity of high-quality data. OmniHuman significantly outperforms existing methods, generating extremely realistic human videos based on weak signal inputs (especially audio).
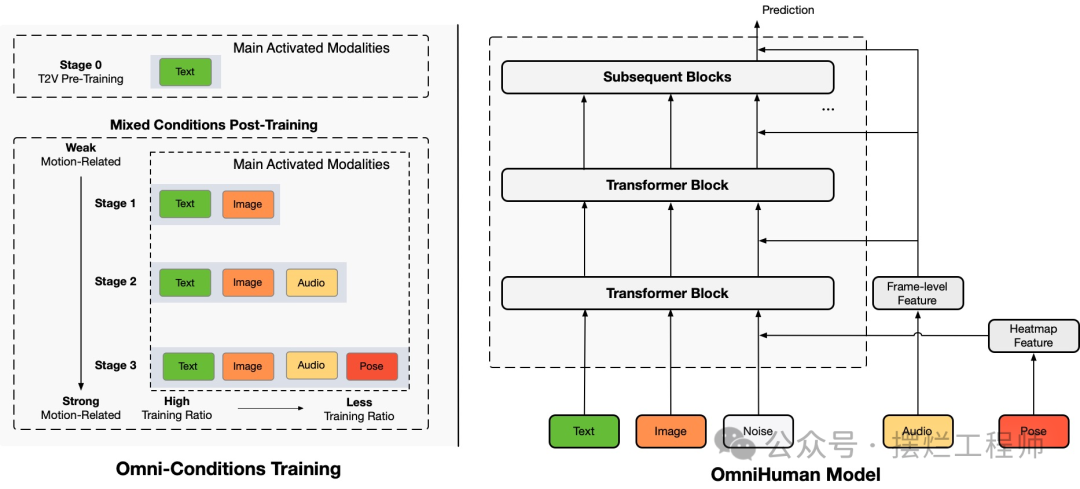
OmniHuman can support voice input in any aspect ratio. It significantly improves gesture processing, which is challenging for existing methods, and produces highly realistic results.

In terms of input diversity, OmniHuman supports cartoons, artificial objects, animals, and challenging poses, ensuring that motion features match the unique characteristics of each style.
Reference: https://omnihuman-lab.github.io
Conclusion: Free MBTI Personality Type Test
If you don’t know your MBTI personality type yet, hurry to this public account backend to take the test.