
Click 01 Muggle Society Follow our public account, never get lost in AI learning

-
Have you ever considered running open-source LLM locally?
-
Do you have to manually download large model files?
-
Are you struggling to build an API for your local model?
-
Have you tried managing multiple models locally?
I guess you have thought about it! These are all heavy physical tasks.
Fortunately, here comes Ollama.
Ollama is a popular large model management tool for deploying and running large language models locally – https://ollama.ai/
Now, you no longer need to worry about these troubles; a single application can solve all these problems.
All you need to do is visit their official website, download the application, and install it. That’s it! Now, you will have a CLI or GUI for model management, including pulling, removing, running, creating custom models, and more.
What models does Ollama support?
Ollama supports a wide range of mainstream models. You can find the list of supported models at https://ollama.ai/library.
The current list is as follows:
-
llama2
-
mistral
-
llava
-
mixtral
-
starling-lm
-
neural-chat
-
codellama
-
dolphin-mixtral
-
mistral-openorca
-
llama2-unsensored
-
……
Running Ollama
Once you have installed the application, you can start it by running the Ollama desktop application. Alternatively, you can also start it via the CLI:
$ ollama serveOllama CLI
Let’s take a look at Ollama’s command line interface.
Pulling Models
The command ollama pull <model name> will automatically download the model files for you.
01coder@X8EF4F3X1O ollama-libraries-example % ollama pull tinyllamapulling manifest pulling manifest MB/s 4s ▏ 284 MB/637 MB 28 MB/s 12spulling 2af3b81862c6... 100% ▕████▏ 637 MB pulling af0ddbdaaa26... 100% ▕████▏ 70 B pulling c8472cd9daed... 100% ▕████▏ 31 B pulling fa956ab37b8c... 100% ▕████▏ 98 B pulling 6331358be52a... 100% ▕████▏ 483 B verifying sha256 digest writing manifest removing any unused layers success Running Models
The command ollama run <model name> runs the model and starts an interactive dialogue with the specified model.
01coder@X8EF4F3X1O ollama-libraries-example % ollama run orca-mini>>> Explain the word distinct Distinct means separate or distinct from others, with no similarity or connection to others. It refers to something that is unique or different in a way that cannot be easily identified or compared with other things. In other words, something that is distinct is not like anything else that you might encounter.
>>> What did I ask? You asked me to explain the word "distinct".
>>> Send a message (/? for help)Querying Locally Deployed Models
The command ollama list lists all locally downloaded and deployed models.
01coder@X8EF4F3X1O ollama-libraries-example % ollama listNAME ID SIZE MODIFIED llama2:7b-chat fe938a131f40 3.8 GB 8 weeks ago orca-mini:latest 2dbd9f439647 2.0 GB 25 hours ago phi:latest e2fd6321a5fe 1.6 GB 29 hours ago tinyllama:latest 2644915ede35 637 MB 6 minutes agoOllama HTTP API
When you start Ollama, it provides a series of APIs for model management. Please refer to the following documentation for a complete list of endpoints:
https://github.com/ollama/ollama/blob/main/docs/api.md
Text Completion
Ollama listens by default on port 11434.
curl http://localhost:11434/api/generate -d '{ "model": "orca-mini", "prompt":"Explain the word distinct"}'Chat Completion
curl http://localhost:11434/api/chat -d '{ "model": "orca-mini", "messages": [ { "role": "user", "content": "Explain the word distinct" } ]}'Python and Javascript Development Packages
Recently, Ollama released Python and JavaScript libraries that allow developers to integrate Ollama into existing or new applications with minimal effort.
-
Python: https://github.com/ollama/ollama-python
-
JavaScript: https://github.com/ollama/ollama-js
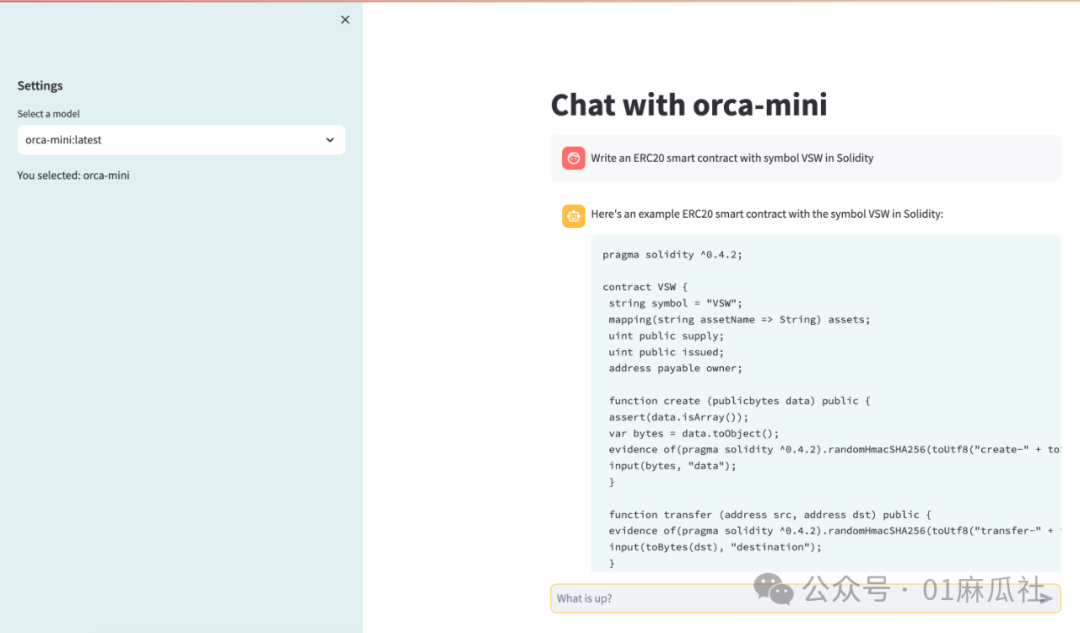
Python Library Use Case | Chat with LLM using Streamlit Application
Streamlit is a development framework well-suited for rapidly developing AI applications.
I created a simple project demonstrating how to build a web application using the Ollama Python library to chat with any model supported by Ollama. Please check it out at:
https://github.com/sugarforever/ollama-libraries-example/tree/main/python
This is based on a Streamlit tutorial created using the OpenAI Python SDK:
https://docs.streamlit.io/knowledge-base/tutorials/build-conversational-apps
The code is straightforward, and here are some key points:
Getting the Model List
import ollama
model_list = ollama.list()Chatting with the Model
Compared to the OpenAI Python SDK, the chat function of the Ollama Python library returns data in a different format. In streaming mode, you should parse the chunks as follows:
full_response = ""
for chunk in ollama.chat(
model=st.session_state["model_name"],
messages=[
{"role": m["role"], "content": m["content"]}
for m in st.session_state.messages
],
stream=True,
):
if 'message' in chunk and 'content' in chunk['message']:
full_response += (chunk['message']['content'] or "")
message_placeholder.markdown(full_response + "▌")With this example application, you should see an interface similar to the following.
Alright, that’s it for today’s sharing. Have a great weekend!🎿⛷🏂🪂🏋️♀️
📝 Recommended Reading
[Preparing for Gemini] Introduction to Google Vertex AI API and LangChain Integration
Google releases the strongest model Gemini – Bard integrates Gemini Pro, API integration interface released on December 13
[Privacy First] Llama 2 + GPT4All + Chroma achieves 100% localization RAG
[Spark API Gateway] iFlytek Starfire Model seamlessly replaces OpenAI GPT4-Vision
No coding required! Create OpenAI Assistants applications – [Zero-code platform Flowise practical]
[Stylish RAG] 03 Multi-document-based agent
[Stylish RAG] 02 Multimodal RAG
[Stylish RAG] 01 RAG on semi-structured data