
Reported by Xinjiyuan
Reported by Xinjiyuan
[Xinjiyuan Introduction] Do we have a new toy, and do the fraudsters have a new tool?
In recent years, the field of computer vision has seen significant advancements in generative technology, and corresponding “forgery” technology has matured, from DeepFake face-swapping to action simulation, making it difficult to distinguish between real and fake.

Recently, NVIDIA has made a significant breakthrough by presenting a new Implicit Warping framework at the NeurIPS 2022 conference, which uses a set of source images and motion from driving videos to create target animations.

Paper link: https://arxiv.org/pdf/2210.01794.pdf
In terms of results, the generated images are more realistic, with characters moving in the video while the background remains unchanged.
The multiple input source images typically provide different appearance information, reducing the generator’s “fantasy” space, as shown in the two images below used as model inputs.

It can be observed that, compared to other models, Implicit Warping does not produce “spatial distortion” effects similar to beauty filters.
Due to occlusion of characters, multiple source images can also provide a more complete background.

From the video below, it can be seen that if only the left image is used, it is difficult to guess whether the background is “BD” or “ED”, leading to distortion of the background, while using two images generates a more stable image.
When comparing with other models, the effect with only one source image is also better.

Magical Implicit Warping
Magical Implicit Warping
The academic community’s research on video imitation can be traced back to 2005, with many projects utilizing a limited number of techniques such as Generative Adversarial Networks (GAN), Neural Radiance Fields (NeRF), and autoencoders for real-time expression transfer, Face2Face, synthesizing Obama, Recycle-GAN, ReenactGAN, and dynamic neural radiance fields.
Not all methods attempt to generate videos from a single frame image; some studies perform complex calculations on each frame in a video, which is precisely the imitation path taken by Deepfake.
However, due to the limited information obtained by DeepFake models, this method requires training on each video segment, which results in lower performance compared to open-source methods like DeepFaceLab or FaceSwap, both of which can impose one identity onto any number of video segments.
The FOMM model released in 2019 allowed characters to move with the video, injecting new life into the video imitation task.

Subsequently, other researchers attempted to obtain multiple poses and expressions from a single facial image or full-body performance; however, this method typically only applies to subjects that are relatively expressionless and cannot move, such as relatively still “talking heads,” because there are no “sudden changes in behavior” that the network must interpret in facial expressions or poses.

Although some of these techniques and methods gained public attention before the popularity of deep forgery technologies and potential diffusion image synthesis methods, their applicability is limited, and their versatility is questioned.
NVIDIA’s focus on Implicit Warping, however, is to acquire information between multiple frames or even between just two frames, rather than obtaining all necessary pose information from a single frame. This setup does not exist in other competing models or is poorly handled.
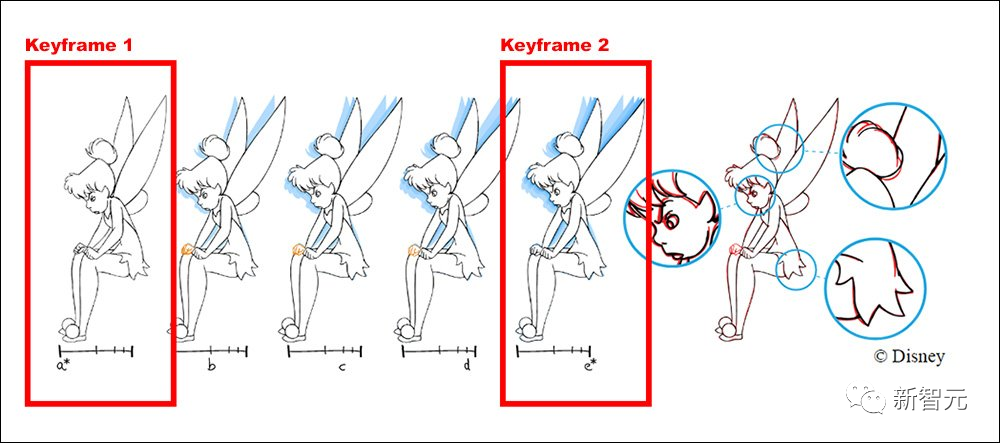
For example, Disney’s workflow involves senior animators drawing the main framework and keyframes, while junior animators are responsible for drawing intermediary frames.
Through testing previous versions, NVIDIA’s researchers found that the quality of results from previous methods deteriorated with additional “keyframes,” while the new method aligns with the logic of animation production, improving performance linearly with the increase in the number of keyframes.
If there is a sudden change in the middle of a clip, such as an event or expression not represented in the starting or ending frames, Implicit Warping can add a frame in between, with the additional information feeding back into the attention mechanism of the entire clip.

Model Structure
Model Structure
Previous methods, such as FOMM, Monkey-Net, and face-vid2vid, used explicit warping to draw a time series, where the information extracted from the source face and controlled motion must fit and conform to this time series.
Under this model design, the final mapping of key points is quite strict.
In contrast, Implicit Warping employs a cross-modal attention layer, which includes fewer predefined bootstrapping in its workflow, allowing it to adapt to inputs from multiple frames.
The workflow also does not require warping on a per-keypoint basis, as the system can select the most appropriate features from a series of images.
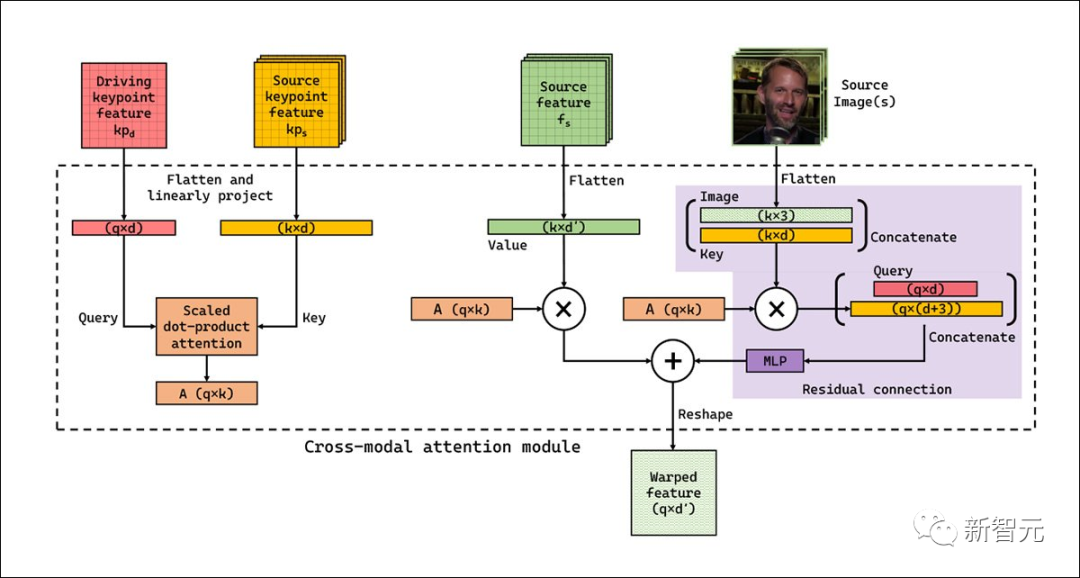
Implicit Warping also reuses some key point prediction components from the FOMM framework, ultimately encoding the derived spatial-driven key point representation with a simple U-net. An additional U-net is used to encode the source images along with the derived spatial representation, and both networks can operate within a resolution range of 64px (256px square output) to 384x384px.
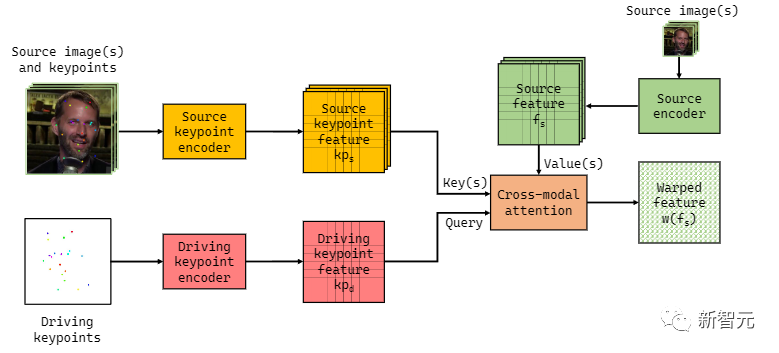
Because this mechanism cannot automatically interpret all possible variations of poses and motions in any given video, additional keyframes are necessary and can be temporarily added. Without this intervention capability, keys with insufficient similarity to the target motion points will automatically uprate, leading to a decline in output quality.
The researchers explain that while it is the key most similar to the query among a given set of keyframes, it may not be sufficient to produce a good output.
For example, if the source image has a closed-lip face, and the driving image has an open-lip face with exposed teeth, there are no keys (and values) in the source image suitable for the mouth area of the driving image.
This method overcomes the issue by learning additional image-independent key-value pairs, which can handle situations where information is missing in the source image.
Although the current implementation runs quite fast, at about 10 FPS on 512x512px images, the researchers believe that future versions can optimize the pipeline through a factorized I-D attention layer or Spatial Reduced Attention (SRA) layer (i.e., pyramid vision Transformer).

Since Implicit Warping uses global attention rather than local attention, it can predict factors that previous models could not.
Experimental Results
Experimental Results
The researchers tested the system on the VoxCeleb2 dataset, the more challenging TED Talk dataset, and the TalkingHead-1KH dataset, comparing the baseline between 256x256px and full 512x512px resolution, using metrics including FID, AlexNet-based LPIPS, and Peak Signal-to-Noise Ratio (pSNR).
Comparison frameworks used for testing include FOMM and face-vid2vid, as well as AA-PCA. Since previous methods had little or no capability to use multiple keyframes, this is also the main innovation of Implicit Warping, and the researchers designed similar testing methods.
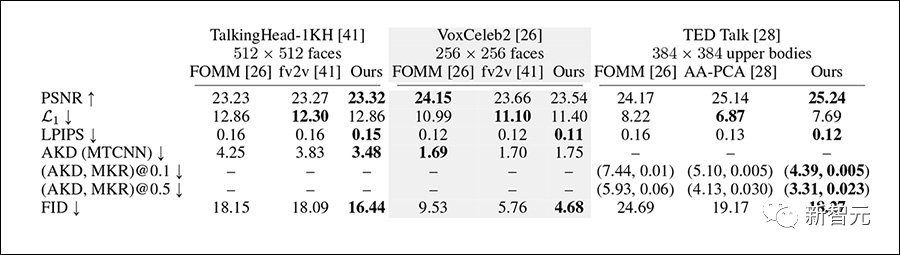
Implicit Warping performed better than most comparison methods on most metrics.
In the multi-keyframe reconstruction tests, researchers used sequences of up to 180 frames and selected gap frames, with Implicit Warping achieving a comprehensive victory this time.
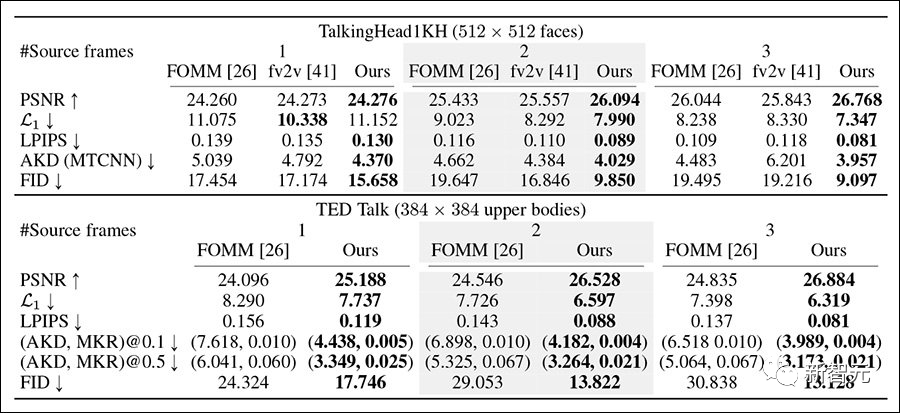
As the number of source images increases, the method can achieve better reconstruction results, with scores improving across all metrics.
However, as the number of source images increases, the reconstruction effect of previous works deteriorates, contrary to expectations.

After qualitative research conducted by AMT staff, it was also concluded that the generative results of Implicit Warping were superior to other methods.
If this framework can be utilized, users will be able to create more coherent and longer video simulations and full-body deepfake videos, all capable of showcasing a much larger range of motion than any framework that this system has already tested.
However, more realistic image synthesis research has also raised concerns, as these technologies can easily be used for forgery, and the paper includes standard disclaimers.
If our method is used to create DeepFake products, it could have negative impacts. Malicious voice synthesis through cross-identity transfer and dissemination of false information can lead to identity theft or the spread of fake news. However, in controlled settings, the same technology can also be used for entertainment purposes.
The paper also highlights the system’s potential in neural video reconstruction, such as Google’s Project Starline, where reconstruction work is primarily focused on the client side, utilizing sparse motion information from the other end.
This approach is increasingly attracting interest in the research community, and some companies plan to achieve low-bandwidth video conferencing by sending pure motion data or sparsely spaced keyframes, which will be interpreted and inserted into complete HD video upon reaching the target client.

