
Extreme Market Guide
The network structure of this article is manually designed, mainly improving the multi-level division convolution of feature maps, concatenation, which enhances the network’s accuracy while also reducing inference time. It feels like a combination of res2net and ghostnet, and not introducing too many tricks during the training phase, the final experimental results are quite impressive, perhaps a good choice for model optimization. >> Join the Extreme Market CV technology exchange group to stay at the forefront of computer vision
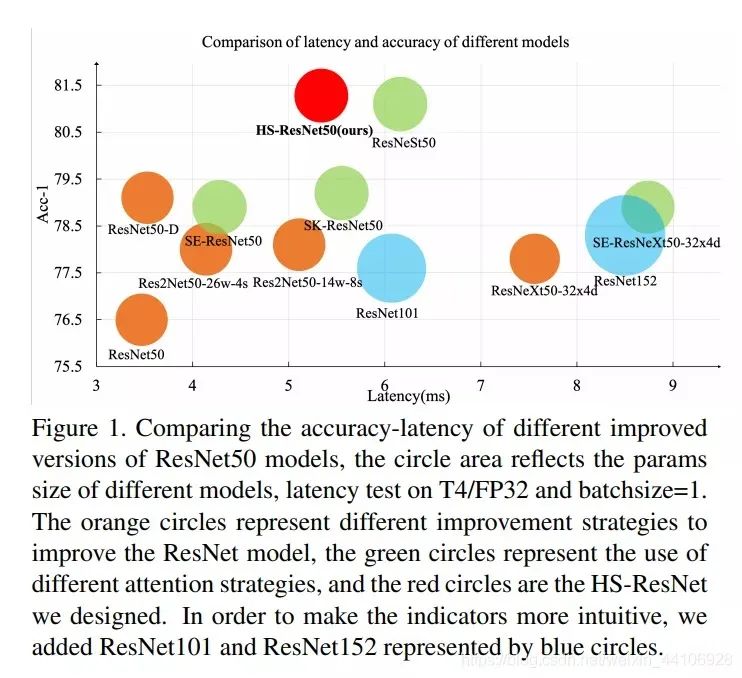 Comparison of CNN model image classification accuracy and inference speed
Comparison of CNN model image classification accuracy and inference speed
Introduction
In this work, we found that multi-level features significantly improve the performance of visual tasks, so we designed a plug-and-play multi-level separation module (Hierarchical-Split Block). The HS-Block includes separation and concatenation of multiple level feature maps, which we replaced in ResNet, resulting in a notable improvement, achieving a top-1 accuracy of 81.28%, while also performing excellently in other tasks such as object detection and segmentation.
Overview
In this paper, we consider the following three questions:
-
How to avoid generating redundant information in feature maps? -
How to allow the network to learn stronger feature representations without increasing computational complexity? -
How to achieve better accuracy while maintaining fast inference speed?
Based on the above three questions, we designed the HS-Block to generate multi-scale feature maps. In the original feature maps, we will divide them into S groups, each group has W channels (i.e., W feature maps).
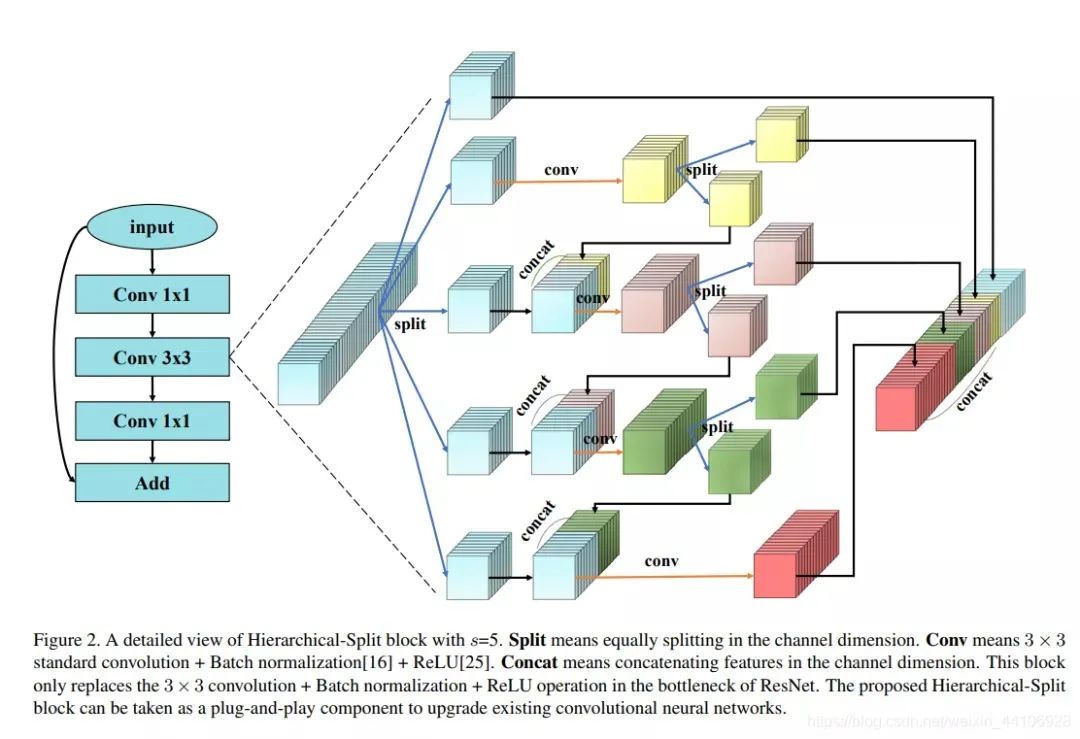 HS-Block module schematic
HS-Block module schematic
Only the first group can be directly sent to the final output. From the second group onward, the operations start to differ:
-
The feature map of the second group undergoes a 3×3 convolution, resulting in the yellow square shown -
Then it will be separated into two groups of sub-feature maps -
One group of sub-feature maps is concatenated to the final output -
The other group of sub-feature maps is concatenated to the third group of feature maps, and this process continues
This operation can be seen as quite complex, but it basically follows the four rules mentioned above in a cyclic manner. Finally, the concatenated feature maps will undergo feature fusion using a 1×1 convolution.
Source of Inspiration
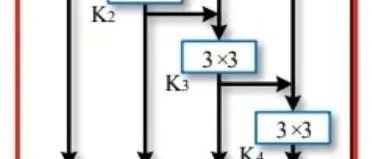
In the paper, the authors also mentioned that the inspiration comes from Res2Net and GhostNet (for analysis, refer to [Huawei GhostNet network]![] We will first review the main module structures of these two networks: The structure of the Res2Net module is as follows: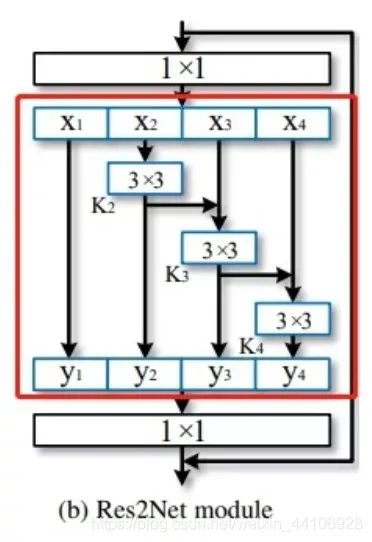
Res2Net module schematic
The Res2Net module also separates a group of feature maps into four groups and performs convolution hierarchically. The special point is that after the 3×3 convolution, the feature map of the second group is added to the third group of feature maps in an elementwise-add manner. Similarly, the feature map of the third group is added to the fourth group of feature maps after a 3×3 convolution in an elementwise-add manner. Now, let’s look at the GhostNet module:
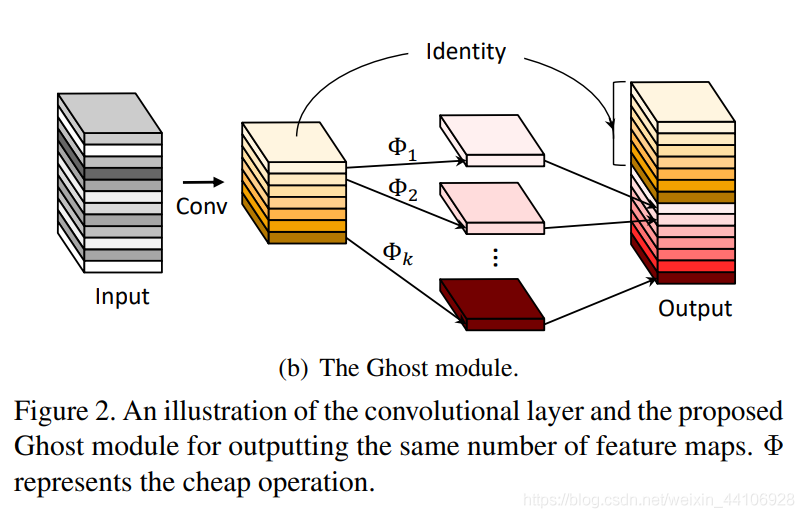 GhostModule module schematic
GhostModule module schematic
The design philosophy of GhostNet is to reduce feature map redundancy, allowing some feature maps to be obtained through convolution operations on existing feature maps. Therefore, it first obtains the yellow part through a convolution module, then generates feature maps within the yellow part (the original paper uses Depthwise Conv), and finally concatenates the two together.
Design Philosophy
The multi-scale separation of HS-Block and the convolution approach allow different groups of feature maps to enjoy different scales of receptive fields. In the previous feature maps, the concatenated features have undergone fewer convolutions, resulting in smaller receptive fields, which can focus on detail information. In the later feature maps, the concatenated features have undergone more convolutions, resulting in larger receptive fields, which can focus on global information. This idea originates from Res2Net, which increases feature richness through different receptive fields. However, this raises another issue: the approach of Res2Net increases computational complexity when the number of channels is large. So, are all feature maps necessary? Observations in GhostNet indicate that they are not.
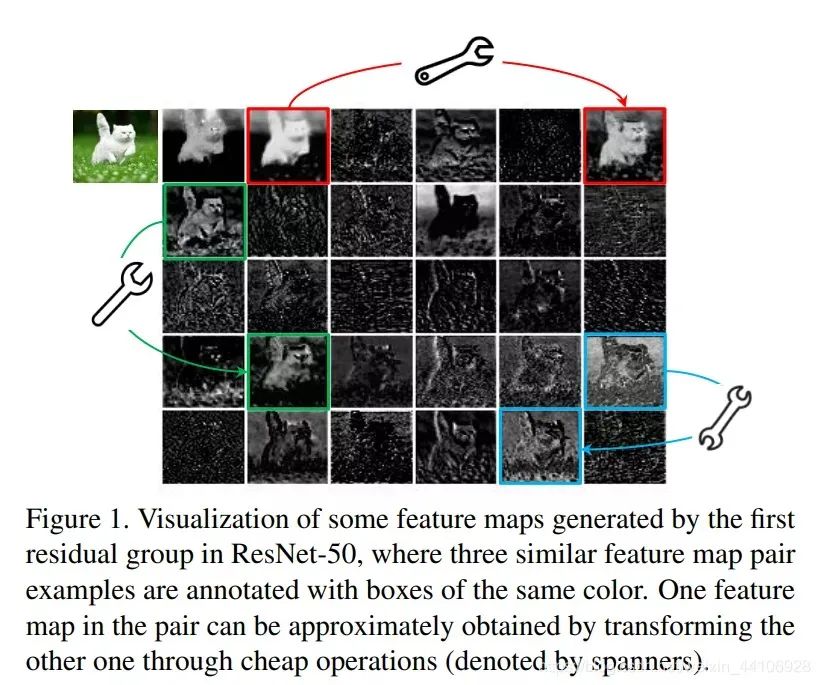 Feature map redundancy
Feature map redundancy
Some feature maps can be generated from existing feature maps. Therefore, drawing on the ideas of GhostNet, we concatenate some feature maps obtained from the convolution of S2 group to S3 group, achieving feature map reuse. Subsequent groups follow the same approach, successfully reducing computational complexity with the GhostNet philosophy.
Analysis of Computational Complexity
The conventional convolution kernel parameter calculation is
In the BottleNeck structure of ResNet, the input and output channel numbers remain unchanged, while here, we divide into S groups, each with W channels. In other words, the input channels are consistent while the length and width of the convolution kernels used are also consistent, which translates to the above formula as
Now let’s look at the computational load of HS-Block. Since the first group of feature maps is directly concatenated to the later ones, there is no computational load for the latter feature maps; the input channels need to be concatenated, and for the first half of the feature maps, thus on the original W, there is an additional term, with input channels being: the derivation of input channels here may not be clear just by looking at the formula, actually, it can be manually calculated, the basic situation is
Finally, the parameters for each group of convolutions are $$param_i = K*K*W*W*( rac{2^{i-1}-1}{2^{i-1}}+1) ext{ (note that the above is the parameters for each group of convolutions, we need to sum the total parameters)}
where 1 is the constant term, summed s-1 times, and the total is s-1, we take it out separately.
It is easy to deduce the sum term, thus we have derived the inequality
Substituting into the previous formula gives
Comparing with conventional convolution parameters
We can see that the parameter amount is indeed reduced.
Experimental Results
Image classification experimental results
It can be seen from the final experiments that, thanks to reasonable design philosophy, the performance and speed of HS-ResNet are quite fast. 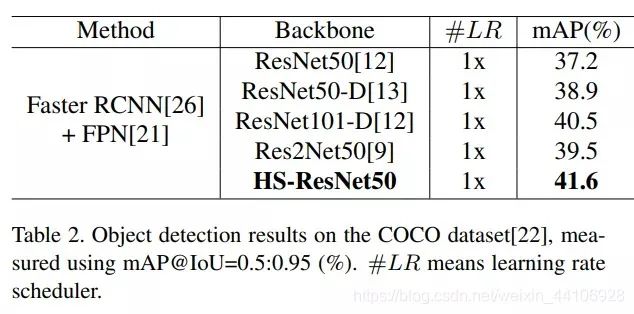
Object detection experiment
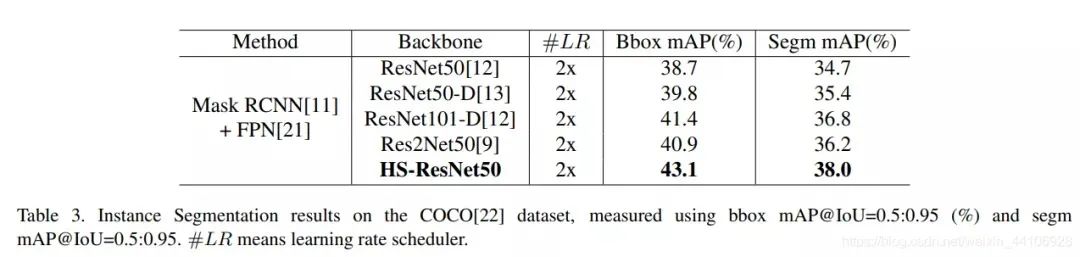
Image segmentation experiment
It also performs excellently in other tasks such as object detection and segmentation.
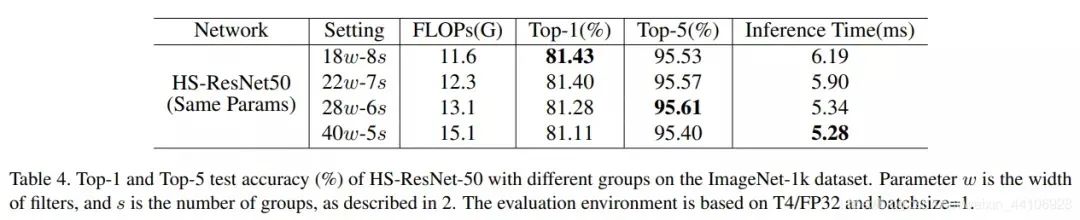
The author also discussed the impact of the number of groups on performance and inference speed at the end, showing that this module is quite flexible, and both performance and speed can be adjusted as needed.
Conclusion
Currently, Paddle’s official team is still conducting follow-up experiments, and the relevant code models have not yet been released. The author’s ideas are not very complex; they blend the philosophies of Res2Net and GhostNet while retaining flexibility and scalability. I believe this model will have even greater potential.
Recommended Reading
-
Let’s Talk About ResNet and Its Variants
-
How to Explain CNN (Convolutional Neural Networks) from the Frequency Domain Perspective?
-
Res2Net: A New Multi-Scale Structure in Deep Learning, Immediate Improvement in Object Detection