
Author: Wang Yonggang, Founder/CEO of SeedV Lab, Executive Dean of AI Academy at Innovation Works
The advent of ChatGPT/GPT-4 has completely transformed the research landscape in the NLP field and ignited the first spark towards AGI with its multimodal potential.
Thus, the era of AI 2.0 has arrived. But where will the technological train of the new era lead? Where are the new business opportunities hidden? Wang Yonggang, founder/CEO of SeedV Lab and executive dean of AI Academy at Innovation Works, believes that multimodal algorithms are at the early stages of a “Cambrian explosion”.
The following is a full share of Wang Yonggang’s notes.

△ Wang Yonggang
I am both a software engineer and an investor and entrepreneur. I have participated in the creation, incubation, or investment of multiple successful AI projects.
Today, ChatGPT has opened a new chapter in the AI 2.0 era, and I am fully engaged in a new entrepreneurial journey involving 3D+AI. In my entrepreneurial team, the core AI technology everyone is most concerned about is multimodal AI that spans text, images, video, 3D, and animation sequences.
Previously, I organized our team’s thoughts in this area into several notes. This article is a summary and synthesis of those notes. Special thanks to team members from SeedV Lab, such as Tong Chao and Pan Hao, who contributed important technical experiments, conclusions, or references to this article.
Table of Contents
-
Core Views
-
The “Monopoly” and “Cabbageization” of Large Language Models
-
The Vast World of Multimodal AI
-
Multimodal Technology is in the Early Stages of Explosion
-
Why Multimodal AI is So Difficult
-
The Multimodal Capabilities of Large Language Models
-
Another “Miracle of Strength” Outcome?
-
Innovative “Blue Ocean” of Multimodal Applications
-
References
Core Views
1. The future of general intelligence must be multimodal intelligence; 2. The large language models represented by GPT-4 possess certain multimodal potentials; 3. Multimodal algorithms are at the early stages of a “Cambrian explosion”; 4. Multimodal algorithms are likely to converge again into a super large model of some sort of “miracle of strength”; 5. Multimodal is the best opportunity for a detour in the research and engineering field of large models; 6. GPT has democratized AI, making it difficult for application developers to establish core technical barriers; 7. However, in the multimodal field, there are still many opportunities to build a “technical moat” within three to five years; 8. The opportunities for application innovation and model innovation in the multimodal field far exceed those in the unimodal field.
The “Monopoly” and “Cabbageization” of Large Language Models
I have been involved in engineering research and development related to natural language processing (NLP) for many years. It is not an exaggeration to say that GPT has ended most independent NLP upstream and downstream tasks. Not only have many research directions been surpassed by GPT, but countless natural language generation, dialogue, and interaction-related application problems have been solved overnight.
The good news is that anyone can use the GPT API to create impressive application products, and those who do not understand programming can hire AI to help code; the bad news is that NLP technology has completely lost its mystique, and all application development teams’ NLP levels have been forcibly aligned. While everyone can compete on products and operations, it has become particularly difficult to establish a technical moat related to NLP on the application side.
On one hand, OpenAI’s ChatGPT, GPT API, and the core ecosystem of ChatGPT Plugin have begun to take shape, while the peripheral ecosystems such as LangChain, AutoGPT, and HuggingGPT are flourishing. In the future, whether in China or the US, as long as the application is consumer-facing, online, does not require private deployment, or does not involve sensitive data, it can generally connect directly to large factory models. Similar to the search and advertising products of the search engine era, this field will inevitably follow a winner-takes-all and large factory monopoly model. In the Chinese and American markets, there are probably two or three super AI large models that will capture the entire share of general intelligent computing.
On the other hand, there are enormous proprietary intelligent computing demands from enterprise and government clients, such as private deployment, private data, sensitive data, and customized development. These demands are limited by the inability to exchange data sufficiently and cannot be solved using large factory models or general solutions. Fortunately, starting with LLaMA, the “alpaca family” has evolved, with a continuous emergence of small models (which can run on terminal devices or even in browsers), medium models (with billions to hundreds of billions of parameters), and large models (with trillions of parameters or more) entering the market in open-source mode. As long as the original licensing agreement supports it, developers can quickly complete customization, domain alignment, encapsulation, and deployment based on these open-source models to provide intelligent application products for enterprise or government clients.
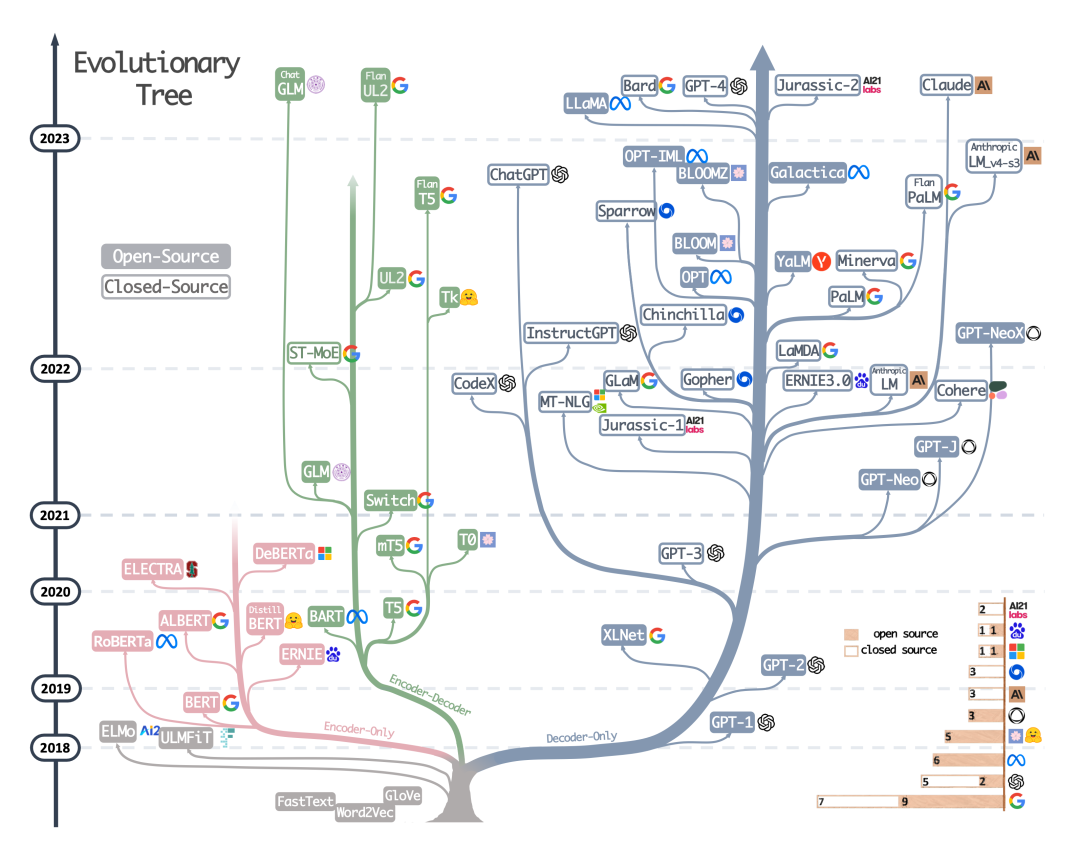
The situation is clear: in the field of general intelligent computing, monopoly will be the basic form of the future; in the field of proprietary intelligent computing, solutions based on simple encapsulation of open-source models will quickly become practical and achieve “cabbage prices” in development and deployment costs.
Large language models (which can also be considered as the “cabbageized” solutions that have already been open-sourced and popularized in the multimodal field, such as the Stable Diffusion suite) will quickly develop into universally usable solutions, just like previous facial recognition technology.
Large language models and related technologies are still developing, but the simultaneous advancement of these super platforms and open-source ecosystems has effectively eliminated the technological differences between AI products. Except for a few super platform product companies and a small number of technology companies that are at the core of the open-source ecosystem, all other tech companies and entrepreneurs find it very difficult to establish a truly meaningful “technical moat” in the field of large language models. For users, the democratization of the new generation of AI technology is certainly a good thing. However, for participants in industry competition, the future competition may not be about technology, but rather about resources, platforms, traffic, models, operational capabilities, and product iteration speed—these age-old market factors.
Of course, entrepreneurs who believe in technology-driven innovation need not be disappointed; I believe that within three to five years, there is still a blue ocean of competition in technology for everyone to surf—compared to large language models, multimodal AI is far from converging technically, and whether in research, engineering, or application layers, it is a vast world with great potential.
The Vast World of Multimodal AI
Conceptually, multimodal AI refers to AI algorithms capable of executing one or more cross-modal/multimodal tasks. Typical cross-modal/multimodal tasks (in research, “cross-modal” and “multimodal” have different connotations, which will not be detailed in this article) include:
-
Cross-modal generation tasks, such as text-to-image;
-
Generation tasks that output multimodal information, such as automatically generating mixed presentation documents that include text, images, and video content based on textual descriptions;
-
Cross-modal understanding tasks, such as automatically generating semantic subtitles for videos;
-
Cross-modal logical reasoning tasks, such as providing a written proof of a theorem based on input geometric figures;
-
Multimodal logical reasoning tasks, such as asking AI to play an escape room game—this requires the AI to infer the optimal solution based on the structure of the escape room space, textual information, image information, etc.;
-
……
After GPT-4 demonstrated strong general problem-solving capabilities, why do we still need to further enhance AI’s cognitive efficiency in the multimodal field?
In fact, we have not yet clarified all the connections between human intelligence and machine intelligence, and it is even difficult to deeply reveal the operational laws of both (explainability). However, some very simple, metaphysical experiential cognitions can help us clarify the complementary relationship between large language models and multimodal models:
-
GPT-4 indeed possesses very obvious preliminary AGI capabilities (see Microsoft’s Spark of AGI paper), and this preliminary AGI capability is primarily acquired by GPT through reading and statistically analyzing human language information;
-
On the other hand, the human living environment and thinking process are undoubtedly multimodal (visual, textual, auditory, optical, electrical, etc.);
-
Even before the emergence of language, human ancestors could perform various types of intelligent tasks—this should be credited to multimodal learning or thinking;
-
Although symbolic systems such as language can indirectly store information or knowledge from other modalities, why can’t computers learn directly from data of other modalities?
-
If AI solely relies on language, can it really learn all the knowledge of this multimodal world?
-
……
Undoubtedly, true AGI must be able to process all modal information in the world immediately, efficiently, accurately, and logically, completing various cross-modal or multimodal tasks. However, the technical path to this ultimate goal may be diverse or require exploration and experimentation. In conclusion, I personally tend to believe that:
-
Future true AGI will inevitably be an efficient multimodal intelligent processor similar to humans;
-
Learning solely from language is unlikely to yield a complete understanding of the world;
-
True AGI needs to learn knowledge, experience, logic, and methods from all modal information simultaneously.
GPT-4 possesses preliminary image semantic understanding capabilities (see GPT-4 Technical Report). The text-to-image model Stable Diffusion, combined with ControlNet, LoRA, and other conditional control and fine-tuning technologies, can also output excellent and controllable results. However, compared to all the multimodal capabilities we truly need, today’s GPT-4 and Stable Diffusion are at most at a kindergarten level in terms of multimodal capabilities.

Imagine if AI could collect and effectively process various types of information from the world through multimodal sensors such as vision, hearing, smell, taste, and touch, we would certainly not be satisfied with simple text-to-image functions. If multimodal AI matures early, I particularly look forward to the following enticing application scenarios:
-
Robots can accurately restore the on-site environment solely based on their visual systems. Here, “restoration” includes but is not limited to precise 3D reconstruction, light field reconstruction, material reconstruction, motion parameter reconstruction, etc.
-
If the previous demand for robots is applied to the field of autonomous driving, it would inevitably mean a new generation of autonomous vehicles with the same level of perception and judgment ability as human drivers, capable of obtaining road permission.
-
AI can observe the life footage of a puppy and, like Pixar artists, endow a 3D-modeled toy dog with actions, expressions, postures, emotions, personality, and even virtual life.
-
Animation directors’ shooting ideas described in text can be interpreted and converted by AI into a series of professional tasks such as scene design, storyboard design, modeling design, lighting design, material and rendering design, animation design, and camera control.
-
Children describe their imaginative worlds to AI, and multimodal AI uses virtual reality technology to help children fulfill their dreams.
-
Anyone can become a game designer in the future world. Human users only need to broadly define game scenes, characters, and rules, and the rest of the professional work can be handed over to future multimodal AI.
-
Once multimodal AI matures, chatbots can quickly evolve into next-generation products that can “read the room” in video chats or use “body language” to help improve their expression capabilities.
-
AI programs may finally possess emotional-related functional attributes—imagine an AI assistant that understands the different meanings of tears; or imagine a virtual psychological counselor that deeply understands human emotions.
-
AI may easily master the “synesthesia” techniques commonly used in artistic creation: creating a high-level symphony with layered rhythms and emotions because it sees the turbulent sea cape; or creating an ethereal dance because it appreciates the graceful dance of a white crane…
Multimodal Technology is in the Early Stages of Explosion
In my personal opinion, the current state of technological progress in multimodal AI resembles the NLP field around 2017.
2017 was the year Google proposed the Transformer technology, and it was also the era when NLP research flourished, with multiple paths iterating simultaneously and breakthroughs in various upstream and downstream tasks. In the list of papers from the top NLP academic conference ACL 2017 (https://aclanthology.org/events/acl-2017/), we can find the technical topics that researchers were most concerned about at that time.
In 2017, tasks such as text classification, semantic parsing, vector encoding, machine translation, text generation, reading comprehension, knowledge question answering, topic modeling, aspect extraction, etc., were arranged in various ways with different technical routes such as Attention, RNN, CNN, Sequence-to-sequence, Sequence-to-Dependency, making it overwhelming. Even as we entered the BERT era in 2018, many in the research circle were still debating which route was the optimal path to the “Holy Grail of Artificial Intelligence”.
For myself, at least before GPT-3 appeared, I, as an engineer with years of NLP experience, had no idea that the dawn of AGI was so close to us.
Today, multimodal AI in the research field is almost identical to the NLP research in 2017, with all the upstream and downstream tasks that need research and all possible technical routes playing various forms of combination games. The list of accepted papers for CVPR 2023 (https://cvpr2023.thecvf.com/Conferences/2023/AcceptedPapers) can truly reflect this strong “splicing feeling”.
Taking research on 3D generation as an example, in the past two years, all papers related to text-to-3D, image-to-3D, video-to-3D, and even more basic 3D-representation mostly belong to the splicing, combining, trying, and exploring of different technical modes. The splicable elements involved include different 3D representation methods, various multimodal information alignment and mixed encoding methods, and different 3D reconstruction pipelines, etc.
To summarize simply, to generate 3D objects or scenes, the most basic 3D representation or encoding methods can be selected from the following candidates (including the combination of multiple options; some of the following options also overlap in meaning):
-
3D Mesh
-
Octree
-
3D Voxels (also known as voxels)
-
Implicit Function
-
Point Cloud
-
Neural Field, or Neural Radiance Field (NeRF)
-
Tri-plane
-
……
The entire generation algorithm or network structure can then try to find the optimal solution in the following major technical threads or their further combinations and variations (the following options are not strictly parallel but are commonly used technical means in 3D generation models; not all options can be directly replaced in the generation network):
-
Generative Adversarial Networks (GAN): GAN has been completely defeated by diffusion models in the 2D image generation field, but it is still one of the popular candidate technologies in today’s 3D generation research;
-
Variational Autoencoders (VAE): Often compared with GAN in generative tasks but less frequently designed as an independent backbone network structure. It can evolve into various self-encoders specifically for certain modalities in practical algorithms;
-
Diffusion Models: Having achieved great success in 2D text-to-image tasks, diffusion models will naturally be borrowed for 3D generation; this direction can also include OpenAI’s recently proposed and open-sourced consistency model;
-
Transformer Models: Having shone in the text field, but their use in 3D generation is still relatively limited;
-
Neural Radiance Field (NeRF): It can be seen as either a 3D representation or encoding method used internally in a generative model or as a typical framework design for 3D generation models (using NeRF representation as an intermediary, performing interpolation or inverse solving around a differentiable 3D function);
-
Parameterization: The output results of AI models or sub-modules are input parameters for another or multiple mature subsystems. Parameterization refers more to a thought of interconnecting technical modules rather than a network architecture design;
-
Contrastive Learning-based Multimodal Pre-training (CLIP): This is often seen as a connecting thought between modalities and modules. This technology, invented by OpenAI, has been widely applied in various multimodal combination training. In the multimodal field, it is always important to emphasize CLIP’s “connecting” power; almost any pipeline of multimodal information mixed encoding, alignment, and training can find traces of CLIP’s original design.
-
……
To give some intuitive examples (the papers cited here are only typical design cases for technical routes and model architectures, not a review list, nor a recommendation based on the value of the papers):
Textured-3D-GAN (https://arxiv.org/pdf/2103.15627.pdf) is a typical algorithm design that utilizes 3D Mesh representation of 3D knowledge and uses GAN to complete generation tasks.
The association between input images and 3D Mesh is based on commonly used UV mapping, material mapping (Texture), displacement mapping (Displacement Map), etc. in the 3D pipeline—this association is also a design paradigm that parameterizes 3D modeling.
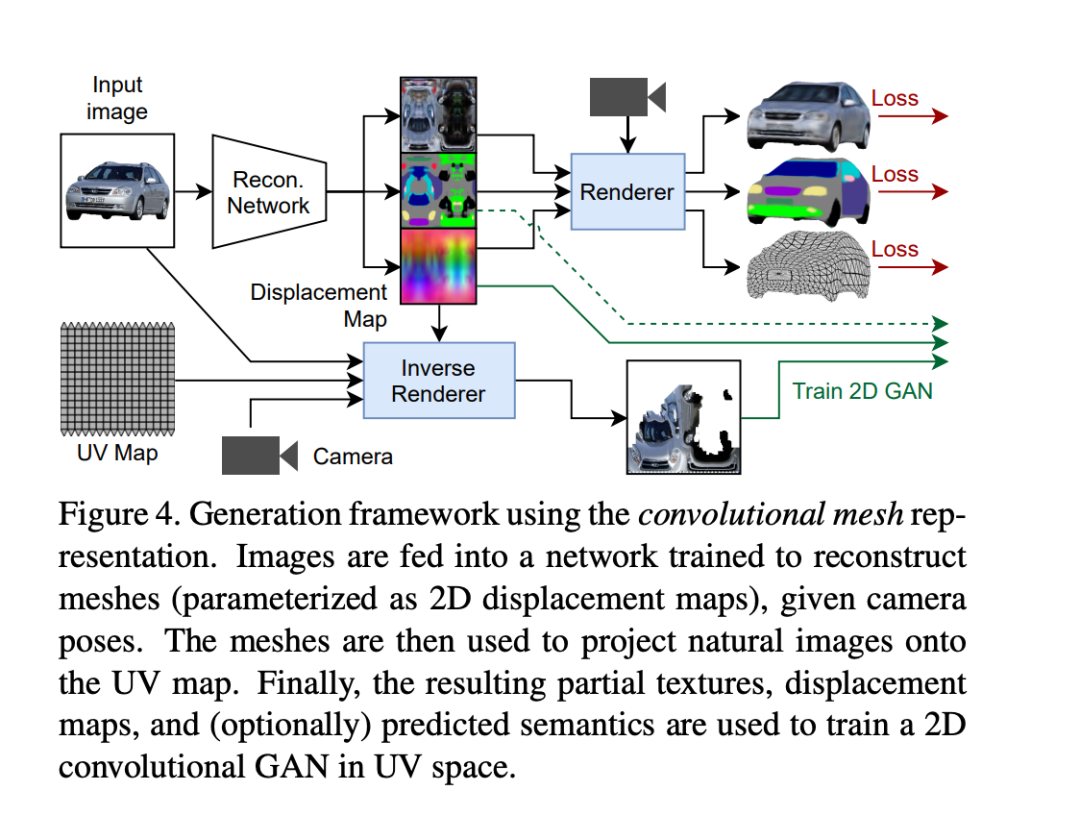
By directly encoding multimodal information based on 3D Mesh, Textured-3D-GAN easily obtains intuitive 3D semantic segmentation illustrations:

PIFuHD (https://arxiv.org/pdf/2004.00452.pdf) and its predecessor PIFu (https://arxiv.org/pdf/1905.05172.pdf) use implicit functions to represent 3D spatial knowledge in the generation process:

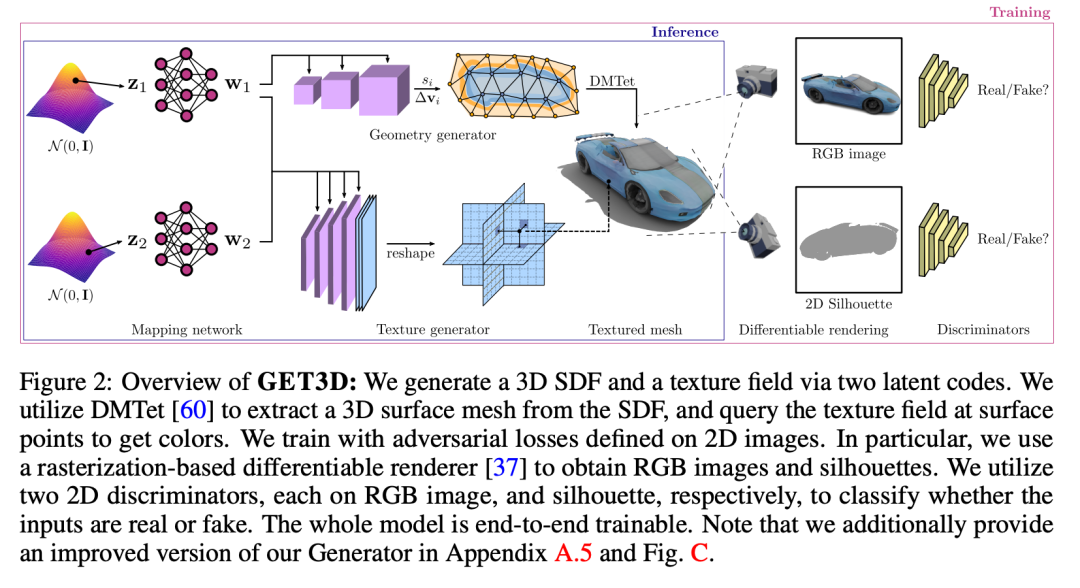
GET3D (https://nv-tlabs.github.io/GET3D/assets/paper.pdf) is an evolution or upgrade of the Textured-3D-GAN design thinking. Overall, it still uses the basic structure of GAN generative networks. The generator internally uses 3D knowledge to divide the generated object into a 3D structure represented by a signed distance field (SDF) and a texture map, and associates the two based on 3D knowledge.

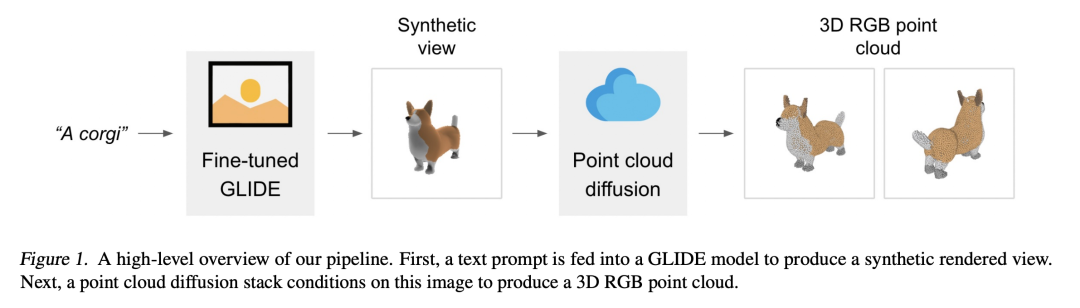
OpenAI’s Point-E (https://arxiv.org/pdf/2212.08751.pdf) is a combination of point clouds and diffusion models; OpenAI’s CLIP pre-training model and Transformer model also play important roles in the entire network structure:

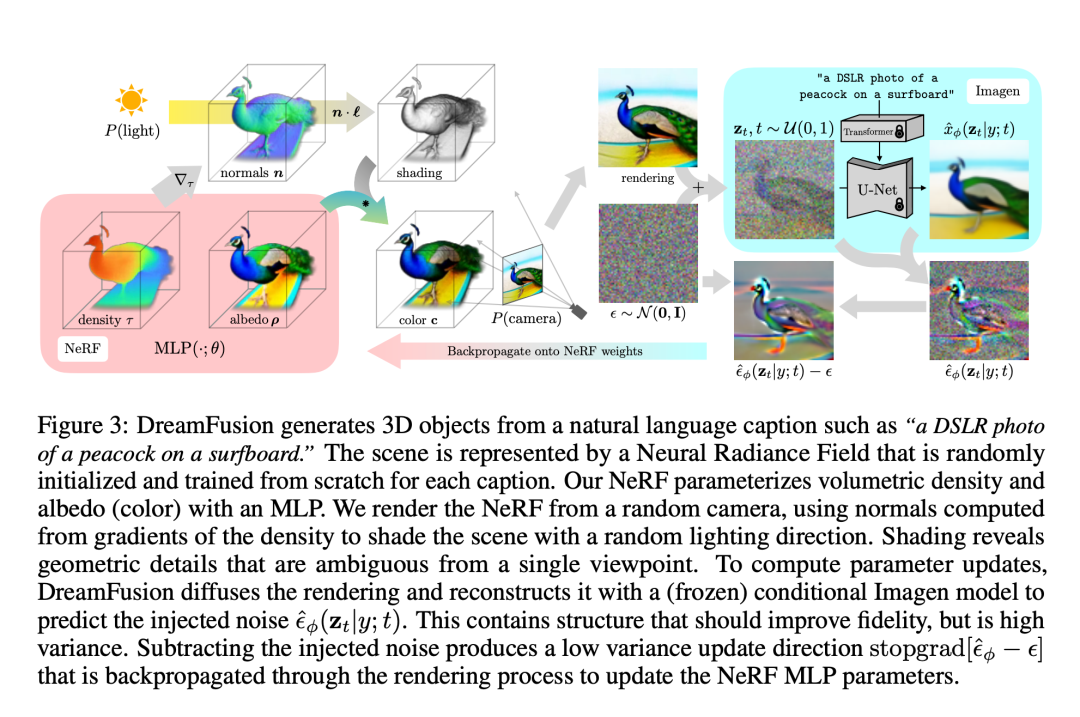
DreamFusion (https://arxiv.org/pdf/2209.14988.pdf) is a representative algorithm of the NeRF method in the 3D generation field, and its overall framework also uses the basic idea of diffusion models from random noise to target objects:
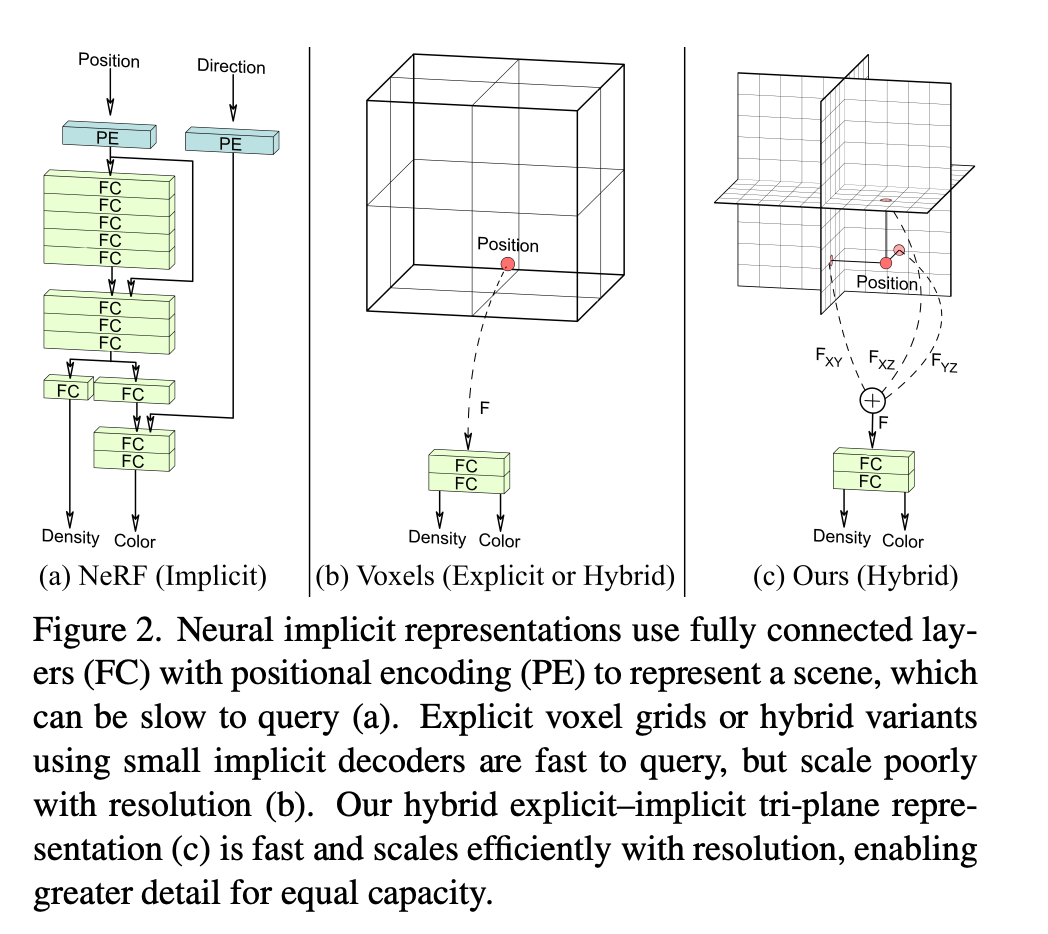
EG3D (https://nvlabs.github.io/eg3d/media/eg3d.pdf) chose GAN for the training framework but used an interesting tri-plane representation for 3D information representation:
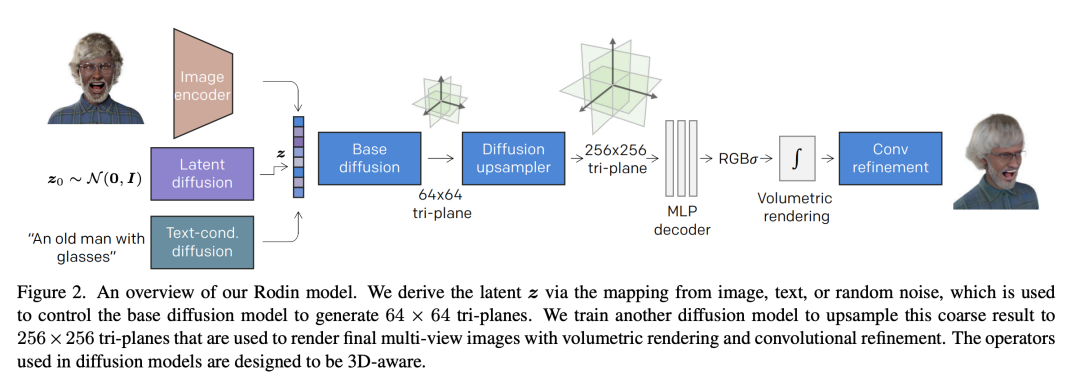
The tri-plane representation of EG3D directly inspired Microsoft’s recently released outstanding virtual head reconstruction algorithm—Rodin (https://arxiv.org/pdf/2212.06135.pdf):
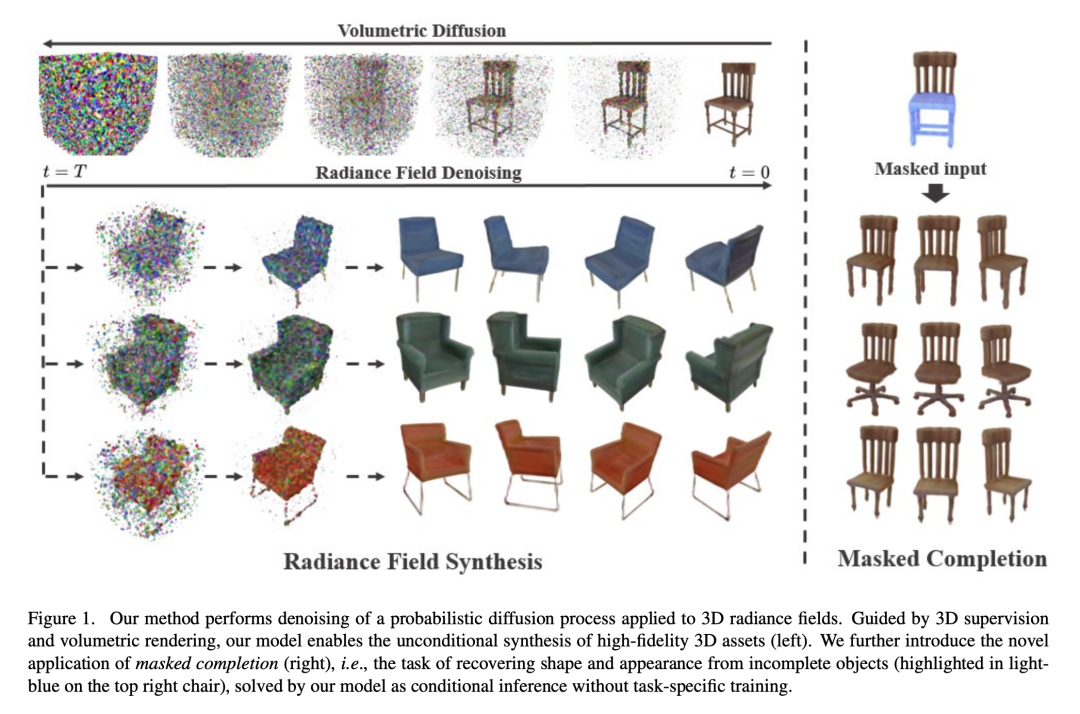
DiffRF (https://sirwyver.github.io/DiffRF/) can be seen as a new combination of neural radiance fields (NeRF) and diffusion models (Diffusion Model):
TANGO (https://arxiv.org/pdf/2210.11277.pdf) combines CLIP’s cross-modal training mode with parameterization methods for various tasks in the 3D world, generating various parameters (materials, normals, lighting, etc.) needed for 3D rendering based on prompt text:
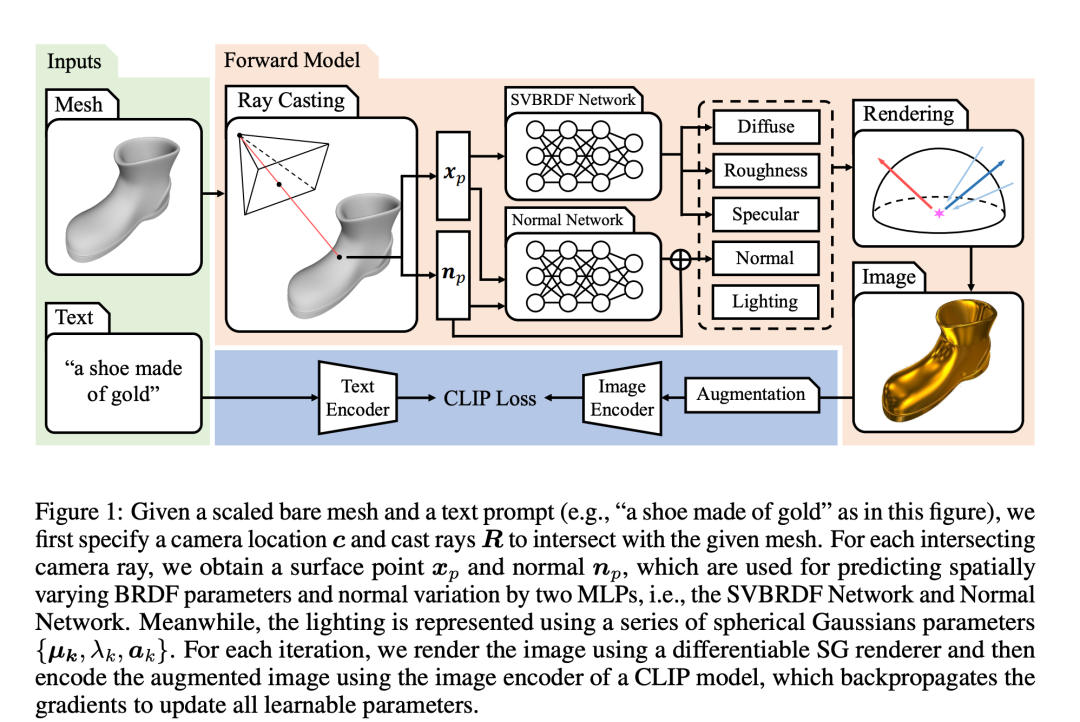

From a narrow perspective, the above examples are sufficient to illustrate the basic situation of today’s research in the 3D generation field:
-
The research momentum is strong;
-
The research directions are in an exploratory and divergent stage;
-
The overall effect of 3D generation currently cannot meet user needs;
-
In some limited domains or styles, SOTA models can perform tasks well.
From 2017 to 2022, the NLP field experienced an explosive research phase that led to the dominance of super large models like GPT-4.
Today, will the constantly emerging multimodal AI algorithms, with their various forms of combinations, give rise to another type of super large model?
Why is Multimodal AI So Difficult?
Multimodal generation, semantic understanding, logical reasoning, and other tasks are certainly more challenging than simple NLP tasks.
Text-to-image, as the most basic cross-modal task, many people today believe has been perfectly solved. The combination of Stable Diffusion + ControlNet + LoRA seems flawless, and the Midjourney tool appears to be user-friendly.
However, the reality is that diffusion model-based text-to-image algorithms are very popular in entertainment and mass communication fields, but integrating into professional production processes or replacing professional artists still poses considerable difficulty.
The article “CG Boss Challenges AI Painting Live” (https://zhuanlan.zhihu.com/p/623967958) documents a specific case of human professional artists challenging AI painting. From this case, it is evident that human control over creativity and details is still far superior to that of AI for the time being. What ControlNet does is essentially use human control to compensate for the AI’s tendency to diverge and be difficult to control—this, from another perspective, proves the irreplaceability of high-level human artists at this current time.
Text-to-image is like this; text-to-video, text-to-3D, text-to-animation, and mixed logic reasoning tasks are indeed still at a very early stage. The fundamental reason behind this is that multimodal AI is particularly difficult.
The Carnegie Mellon University paper “Foundations & Trends in Multimodal Machine Learning: Principles, Challenges, and Open Questions” summarizes the challenges faced by multimodal AI research into the following six points:
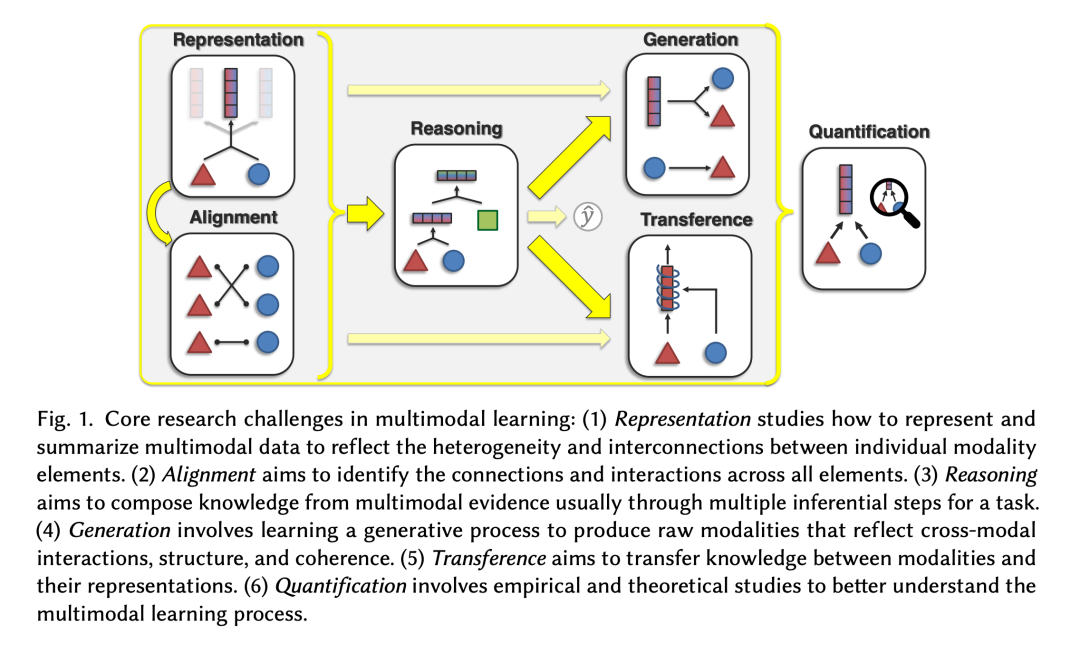
First, Representation: The methods of information representation in the text and image fields are relatively stable, while video, animation, 3D, and other fields are still experimenting with various new representation methods. Without good representation methods, AI cannot learn high-quality knowledge.
Second, Alignment: CLIP provides a framework idea for mutual alignment between different modalities, but when it comes to processing multimodal alignment, it still requires repeated experimentation to find the optimal solution.
Third, Reasoning: If the first two points are not solved well, the model’s reasoning ability cannot be improved; even if reasoning is considered independently, it involves a lot of details such as information connection relationships in cognitive space, model network structure, and model scale.
Fourth, Generation: The generation part includes three stages: multimodal information extraction, cross-modal information translation, and multimodal information creation. Compared to pure text generation tasks, the complexity of these three tasks in multimodal tasks rises dramatically.
Fifth, Knowledge Transfer: Knowledge in many fields exists naturally in information from different modalities, but how can we communicate between multimodal information, complement missing knowledge? More importantly, some modalities (like 3D) have extremely scarce training data, while the image and video fields with relatively rich training data actually contain a lot of 3D knowledge. At this point, how to achieve knowledge transfer becomes a key question that must be answered.
Sixth, Quantification: This difficulty exists in all deep learning models. How to quantitatively evaluate the strengths and weaknesses of model network structures, how to improve the weakest links in the model during continuous iteration, how to identify whether the model has learned biases, and how to test the model’s robustness are all long-standing problems in deep learning theory.
Taking the automatic generation of 3D scenes or objects as an example, the research or engineering challenges faced by multimodal AI in the 3D generation field will translate into the following very tricky issues:
-
Data Scarcity: Compared to the high-quality image datasets that are ubiquitous, high-quality 3D datasets are scarce. Commonly used research image datasets usually contain hundreds of millions or more images, while many high-quality, research-usable 3D datasets only have thousands or tens of thousands of 3D models.
-
Difficult Knowledge Transfer: Current research is still focused on dissecting the 3D information contained in a single or multiple images; accurately restoring or aligning the 3D information contained in text, video, and animation sequences is even more challenging.
-
Difficult Technical Selection: Taking the representation methods for 3D scenes or objects as an example, there are many selectable methods, and new methods continue to emerge. If it is difficult to reach a conclusion on how to represent the information at the input end, how can we demand quality at the output?
-
Heavy Dependence on Computing Power: In the future, the computing power required to train a multimodal super large model may far exceed that required to train GPT-4.
-
Lack of Positive Cycle: Because 3D generation is difficult, products related to 3D generation struggle to solve ordinary users’ practical problems, making it hard to obtain more user data and feedback, and thus unable to iterate and improve model quality based on user feedback.
The technical challenges of multimodal AI genuinely exist, but challenges imply opportunities; through technological breakthroughs and innovations, this is the best time to make significant strides in multimodal AI.
The Multimodal Capabilities of Large Language Models
On one hand, multimodal AI has quite a few technical challenges to solve; on the other hand, large language models like GPT have already learned part of the multimodal knowledge recorded in human language (GPT-4 also encodes image semantics and can accept inputs from both text and images simultaneously; this aspect of information can refer to the GPT-4 paper, which will not be discussed further in this section). Can we leverage the multimodal knowledge learned by large language models to accelerate research and application development in multimodal AI?
This is a super interesting technical path worth exploring in depth.
For example, regarding the 3D creation and control tasks that our team cares about, since the moment GPT-4’s open interface and API were available, we have been testing GPT-4’s knowledge reserve and logical reasoning capabilities regarding three-dimensional space.
A small part of GPT-4’s 3D capabilities was mentioned in the paper by Microsoft’s Spark of AI. In one experiment, researchers asked GPT-4 to create “a fantasy world with floating islands, waterfalls, bridges, a dragon flying overhead, and a castle on the largest island” using JavaScript (the actual experimental process involved multiple rounds of instructions or prompts). The 3D world created by GPT-4 through JavaScript programming is shown below—though rudimentary like a child’s work, it semantically restored the prompt requirements:

Considering that GPT-4 has never directly learned any 3D modal information, only acquiring knowledge about the 3D world, 3D modeling, and 3D programming from human language, such output is astonishing.
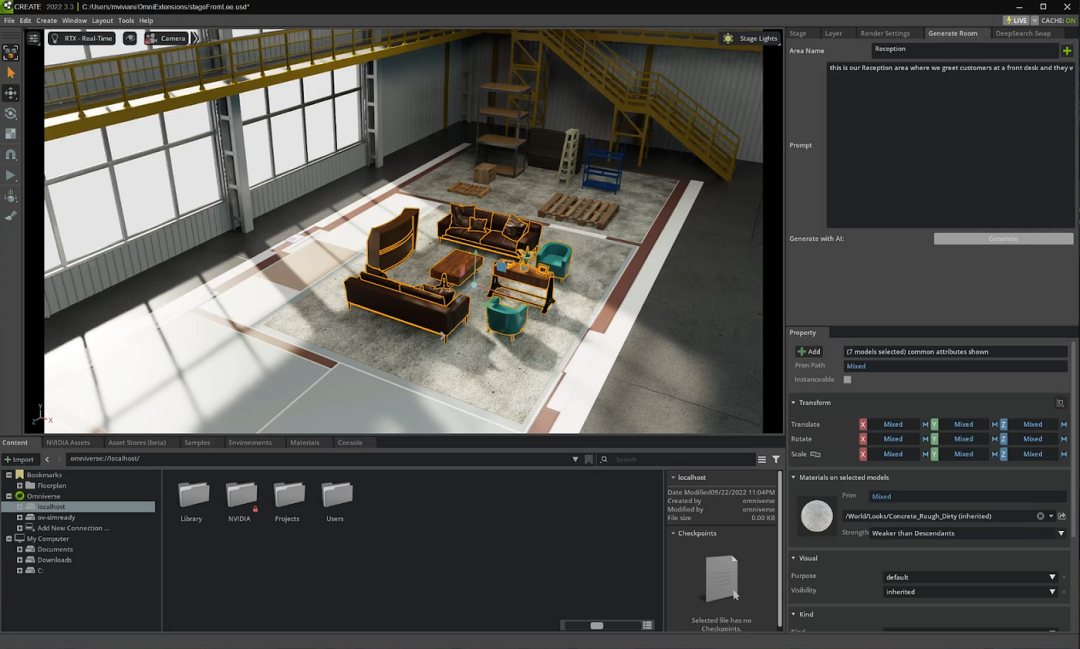
The NVIDIA Omniverse team utilized ChatGPT and GPT-4 to conduct another 3D content creation experiment, which interestingly demonstrated the creativity and control that GPT-4 can achieve when connected to 3D tools’ programming interfaces (see the article How ChatGPT and GPT-4 Can Be Used for 3D Content Generation):
Unlike Microsoft’s and NVIDIA’s research teams, our team hopes to delve into how well GPT-4 understands the basic elements of 3D space. We expect GPT-4 to understand and manipulate the basic spatial elements to include:
-
Coordinate Systems
-
Spatial Orientation
-
Three-dimensional Composition of Geometric Shapes
-
Formal Representation of Geometric Shapes
-
Spatial Relationships of Geometric Shapes
-
Spatial Motion of Geometric Shapes
We conducted a large number of related experiments, and the results were shocking: GPT-4’s “intelligence level” in 3D spatial cognition and manipulation is similar to that of a 2-3 year old child building blocks; GPT-4 can accurately understand the most basic spatial orientations and comprehend the basic configurations of geometric shapes, but it is also like a toddler, always “clumsy” and struggling to control the details of spatial elements.
Before conducting specific experiments, we hoped GPT-4 would recommend a group of formal methods to describe spatial objects within the limited text length. GPT-4 fully understood that directly using (x, y, z) coordinate systems and 3D meshes for precise expression would not suffice within thousands of semantic symbols (tokens). It recommended several simplified formal methods:
-
Using octrees (Octree) to encode the spatial structure of objects;
-
Using Constructive Solid Geometry to combine basic shapes or custom meshes into complex shapes;
-
Using low-poly methods to simplify 3D meshes;
-
Using run-length encoding (RLE) to compress the formal expression of 3D shapes;
-
Using parametric or procedural modeling methods;
-
Using different precision expression systems at different levels of spatial hierarchy.
Clearly, GPT-4 has drawn well from mainstream methods for formally describing 3D objects from 3D graphics books or articles. We used GPT-4’s recommended methods to further test its practical abilities in 3D tasks.
Based on the idea of Constructive Solid Geometry, we asked GPT-4 to use 1x1x1 unit blocks to build a “rough” block dog within a given small space and output the coordinates or numbers of each unit block’s location. We used a Blender plugin to directly render GPT-4’s output results into a 3D scene. The block object GPT-4 constructed based on the prompt of “a block dog” is shown below:

We added prompts asking GPT-4 to add details to the dog, particularly its ears. GPT-4 excellently completed the task:

When we asked GPT-4 to unleash its creativity and build a small house that it thought was beautiful, complete with a door and a window, the block structure created by GPT-4 was also very interesting:

In the absence of prompts, GPT-4 seems not to leave holes for doors and windows in a “hollowed-out” manner; instead, it stacked blocks representing doors and windows at the locations of the doors and windows. To visually distinguish, we rendered the blocks GPT-4 considered as doors and windows in blue (during the generation process, GPT-4 meticulously explained the purpose of each group of blocks step by step).
Next, when we asked GPT-4 to build a block figure with arms and legs, while providing Minecraft-style constraints, GPT-4’s creation of the block figure was concise and accurate:

Interestingly, when we asked GPT-4 to extend one arm of the block figure forward, GPT-4 accurately performed the action of extending an arm forward, but regrettably got the sides wrong; the figure’s arm extending forward in the image below is not the left arm but the right arm:

This is an interesting phenomenon that has repeatedly appeared in similar experiments: GPT-4 can usually accurately recognize or locate up and down, front and back in 3D space but often confuses left and right. In our experiments, if the prompt does not emphasize which direction is left and which is right, GPT-4’s probability of confusing left and right is much higher than correctly processing left and right. Toddlers seem to have similar difficulties distinguishing left from right—could it be that GPT-4 has already developed some “life characteristics”?
With a reminder from our team advisor, this phenomenon of confusing left and right is actually not difficult to explain: in all language-based descriptions of 3D scenes, most speakers describe the spatial orientation from a third-person observer’s perspective. If the observer is facing the front of a virtual character in 3D space, the observer’s left side would correspond to the character’s right hand, and the observer’s right side would correspond to the character’s left hand. Since GPT-4 learns 3D knowledge solely from language materials, forming a left-right direction reversal “observer bias” is inevitable.
This left-right reversal phenomenon further suggests that learning world knowledge solely from language materials is insufficient to establish a complete and accurate multimodal cognition. In the future, AI will likely still need to learn knowledge directly from multimodal sensors, imaging materials, 3D scenes, and animation sequences.
If GPT-4 is allowed to use any shapes of six-sided blocks, we must limit each round of GPT-4’s output to the spatial position (x, y, z) and spatial size (w, h, d) of each block, and then modify our Blender plugin accordingly.
The image below shows the block dog that GPT-4 reassembled after choosing block sizes:

The image below shows the creation based on the prompt of “a puppet figure similar to Pinocchio” that GPT-4 built using self-selected block shapes (the visual imagery of the “long nose” should be what GPT-4 gleaned from the prompt “Pinocchio”).:

Note in the image above that GPT-4 placed the puppet figure’s two eyes at the front of the head. To resolve this spatial orientation error, we used several rounds of prompts to “teach” GPT-4 how to move the two eyes to above the face.
Next, we expect GPT-4 to generate continuous animation keyframes that gradually raise one leg of the puppet figure. GPT-4 can accurately understand our intentions and map the action of “raising one leg” to the structure of objects in space. However, the expression capability of six-sided blocks is limited (the formal language we agreed upon with GPT-4 even lacks the expression of block rotation angles), and the best visual effect GPT-4 could achieve is as shown below:

In addition to the above simple and interesting results, we also conducted many more detailed and in-depth experiments, including:
-
In-depth exploration of GPT-4’s spatial expression capabilities in the direction of octrees and Boolean combinations of basic geometric shapes;
-
Exploring GPT-4’s ability to associate rendering effects with spatial locations in the direction of geometric UV mapping;
-
Exploring GPT-4’s ability to control lighting in scenes based on instructions (such as “lighting design for a typical photography studio with three lights”);
-
Testing GPT-4’s understanding and control capabilities of animation keyframes;
-
……
In the future, we may publish a dedicated article systematically presenting these experimental results and the regular knowledge observed from them.
The series of experiments conducted by our team continuously approaches GPT-4’s cognitive limits in 3D modal tasks. The deeper we delve into the experiments, the more we feel that GPT-4’s behavioral characteristics in this field are very similar to those of a 2-3 year old child building blocks. The so-called “dawn of AGI” may also be understood from this direction.
Another “Miracle of Strength” Outcome?
Today’s multimodal AI is still in a phase of great exploration and development of technical directions.
Will multimodal AI be completely replaced by a “miracle of strength” super large model like NLP tasks?
I personally believe that this outcome is highly likely; however, the path to reach this conclusion may be very long.
First, AI giants like OpenAI or Google are already working on developing the next generation of multimodal mixed pre-training models. General large models trained on a mix of text, images, and even text, images, and videos should soon demonstrate multimodal capabilities far surpassing GPT-4. Based on empirical cognition, it is a high probability event that OpenAI will once again win in the competition for multimodal super large models.
Second, as mentioned earlier, there are still considerable variables in multimodal fields beyond text and images—extremely scarce training data, the lack of recognized optimal solutions for representing and aligning complex multimodal information such as 3D, and the computing power requirements for multimodal training are far higher than those for pure text data, all of which pose technical challenges that loom like a chasm before all researchers and developers.
Essentially, text encodes semantic information on a one-dimensional time series, images represent typical two-dimensional spatial information, videos can be understood as a combination of two-dimensional spatial information and time series (three-dimensional information), while 3D animations upgrade to a combination of three spatial dimensions and time series (four-dimensional information). Theoretically, 3D animations are the ultimate mapping of real-time and space; text, images, and even videos are merely projections of real-time and space in lower dimensions.

Large language models like GPT establish a paradigm of intelligence that may lead to AGI. However, extending this intelligence paradigm to three-dimensional and four-dimensional temporal and spatial ranges sees an exponential increase in complexity. Therefore, in the more complex multimodal fields such as video, 3D, and animation sequences, the time cycle for technological iteration and convergence to a unified method may be quite long; three to five years is merely my conservative estimate.
Perhaps new algorithm designs must be employed to address the problem of complexity explosion. Alternatively, the possibility of knowledge transfer between modalities may help AI understand training data-rich low-dimensional text and image information more deeply, enabling faster learning from high-dimensional information. Additionally, quickly launching practical products based on today’s early-stage multimodal technologies and then establishing interconnections between user scenarios, data, engineering, and research through platform-level and tool-level products is also a good idea for accelerating technological iteration.
In simple terms, both good news and bad news coexist; the development trend of multimodal AI is extremely difficult to predict. The predictions regarding the future in this article are not based on rigorous mathematical modeling and are certainly inaccurate. Looking back over the past few decades of AI technology development, no one has accurately predicted when AI research would peak or when it would hit a low point.
Everything depends on the hard work of us practitioners.
The Innovative “Blue Ocean” of Multimodal Applications
Large language models like GPT have opened a new era of application innovation. Vibrant multimodal AI will push this round of application innovation to its peak.
Compared to pure interaction or input-output through natural language, multimodal applications clearly possess stronger perceptual, interactive, and “synesthetic” inherent properties. The innovative application models of Midjourney in the text-to-image domain, I believe, are just the tip of the iceberg in the future multimodal application world.
Here are some future multimodal applications that I am very optimistic about:
-
Cross-modal semantic knowledge retrieval and data extraction;
-
A new generation of multimodal databases;
-
Cross-modal knowledge mining, typically in the medical field (cross-medical records, medical imaging, gene sequences, molecular structures, etc.);
-
Automatic generation of multimodal information displays (such as products, annual reports, courses, speeches);
-
Automatic generation of multimodal advertisements;
-
Automatic generation of multimodal web pages or mini-programs;
-
Automatic video editing;
-
Automatic video generation;
-
Next-generation user-generated content (UGC) tools or platforms with mixed multimodal creation capabilities;
-
Virtual shopping guides within e-commerce platforms;
-
Automatically generated interactive e-commerce shelves;
-
Virtual courses and virtual teachers in the education field;
-
Various types of virtual characters;
-
AI expressions or body language;
-
AI virtual emotions;
-
AI music and dance creation;
-
A new generation of animation design tools centered around AI;
-
Automatic game development;
-
New-generation robotic technologies enhanced with multimodal perception and decision-making capabilities;
-
New-generation autonomous driving technologies enhanced with multimodal perception and decision-making capabilities;
-
Automatic content creation in virtual reality and mixed reality;
-
Automatic generation of multimodal social applications;
-
Automatic generation of multimodal mini-games;
-
……
Today’s large number of AI applications are still limited to incremental innovations within existing markets and application models; many of the multimodal application innovation opportunities listed above belong to transformative innovations that could create a new incremental market or platform product.
Why is the multimodal field likely to breed transformative innovations?
Taking UGC tools and platforms as an example: Twenty years ago, the original content created by ordinary users on the Internet was primarily text-based; as we entered the mobile internet era, the proportion of images and long videos in user-generated content significantly increased; in recent years, short video tools and platforms have become the core traffic of the UGC world… But have ordinary users’ creative desires been fully satisfied? It is important to note that the imagination of ordinary users is limitless. As long as there are better means of expression and simpler tools, users will certainly create new waves of digital content again.
The fundamental contradiction is that current technical tools cannot meet users’ strong creative demands. For example, professional teams in film, 3D animation, and gaming excel in creating various exciting content or extraordinary user experiences, but ordinary users find it hard to emulate. Professional tools like Final Cut Pro, After Effects, Blender, Cinema 4D, and Unity are designed in such a way that they exclude the vast majority of ordinary users; they all have very steep learning curves, pursue extreme professional control, and must meet the needs of professional workflows and toolchain integration.
The new generation of multimodal AI technology clearly has a significant opportunity to redefine content creation tools. If a “grassroots user” plans to construct imaginative inventions in a virtual world (refer to the physical works of Handwork Geng), could they directly use natural language to instruct AI to complete tasks instead of learning how to use professional software from scratch? If a child creates a brilliant game play style but lacks professional experience in game development, could the future multimodal AI shine?
AI-empowered intelligent tools will eventually shed the burden of “professionalism” and liberate ordinary users from steep learning curves. Every content creator can focus on creativity itself rather than the complex interactions with tool software. By then, will the next generation of UGC platforms remain limited to simple forms like text, images, and short videos?
Multimodal applications have vast imaginative space. Even assuming multimodal AI has matured, a large number of engineering technical issues still need exploration and iteration at the application level. For example:
-
How can AI-generated elements perfectly integrate with traditional film, 3D, animation, and gaming workflows?
-
How should human-computer interaction dominated by natural language be designed for maximum efficiency in multimodal scenarios?
-
How will future computers, phones, or the next generation of personal computing devices connect different modalities of sensors?
-
How will operating systems or applications present computing results in better multimodal forms?
-
How will Apple’s upcoming VR/AR devices change the competitive landscape of the multimodal application market?
-
How can AI-assisted programming better enhance the efficiency of developing and deploying multimodal applications?
-
……
I personally believe that in the post-GPT era, multimodal presents the greatest opportunities for research, engineering, and application development. My perspective is limited, and this basic viewpoint, along with the above thoughts, is certainly not entirely correct. This is organized and published for everyone’s reference.
References: [1] Harnessing the Power of LLMs in Practice: A Survey on ChatGPT and Beyond, https://www.researchgate.net/publication/370224758_Harnessing_the_Power_of_LLMs_in_Practice_A_Survey_on_ChatGPT_and_Beyond[2] Sparks of Artificial General Intelligence: Early experiments with GPT-4, https://arxiv.org/abs/2303.12712[3] GPT-4 Technical Report, https://arxiv.org/abs/2303.08774[4] Foundations and Trends in Multimodal Machine Learning: Principles, Challenges, and Open Questions, https://arxiv.org/abs/2209.03430[5] How ChatGPT and GPT-4 Can Be Used for 3D Content Generation, https://medium.com/@nvidiaomniverse/chatgpt-and-gpt-4-for-3d-content-generation-9cbe5d17ec15
— End —
Quantum Bit Think Tank “China AIGC Industry Panorama Report”
Open Download!
The first AIGC industry panorama report is now open for download!
Three major types of players, four business models, a trillion-scale market, the 50 most noteworthy companies, along with specific track deployment opportunities and industry transformation opportunities will be analyzed and presented in the report. More industry insights are not to be missed.
Reply “AIGC” in the WeChat public account background to download the complete report~

Click here👇 to follow me, remember to star it~
One-click triple connection “share”, “like”, and “view”
Daily updates on cutting-edge technological advancements ~
