With the rapid development of large models and agent-related technologies, major tech companies are quickly entering the multi-agent era, aiming to help humans handle complex tasks and free up their hands! Microsoft has recently launched the Magentic-One multi-agent framework, built on AotoGen, which not only can converse with humans but also can control computers to perform various complex tasks!
Paper link:
https://arxiv.org/pdf/2411.04468
Project homepage:
https://github.com/microsoft/autogen

What Can Magentic-One Do?
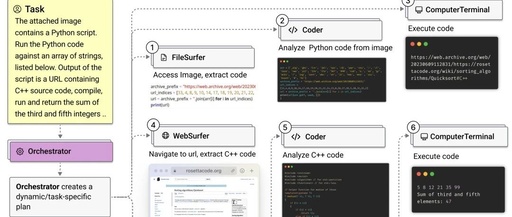
The latest open-source agent framework from Microsoft, Magentic-One, can control computers to help humans handle various complex tasks. Magentic-One consists of five specialized AI agents working together to assist humans in handling open web and file-based complex tasks, such as browsing the web for information, processing local files, and writing code.
For example, a task: What supermarkets within two blocks of Lincoln Park in Chicago have ready-to-eat salads priced under $15? At this point, Magentic-One will automatically use an online map (like Bing Maps) to find supermarkets near Lincoln Park, then navigate to each supermarket’s website to check if they have ready-to-eat salads priced under $15.
For specific deployment methods and usage tutorials, refer to:
https://www.bilibili.com/video/BV1MymbYpEJy/?vd_source=814c868b972bdaeb1b688bc9fe998e2c
Research Background
The development of large models has propelled the advancement of agent systems. To enhance human knowledge and capabilities to improve productivity and change lives, these systems need to possess abilities such as planning, reasoning, acting, responding to new situations, and error correction to complete complex tasks. Magentic-One aims to build such a general-purpose agent system capable of handling various tasks in people’s daily work and lives.
Magentic-One System Overview
Multi-Agent Architecture
It consists of a coordinator (Orchestrator) and four specialized agents (WebSurfer, FileSurfer, Coder, and ComputerTerminal). The coordinator is responsible for task planning, tracking, and adjustments, while the other agents specialize in tasks such as browsing the web, processing files, writing, and executing code.
This innovative multi-agent architecture has many advantages; the modular design allows each agent to focus on its area of expertise, forming an efficient team. The system possesses strong adaptive capabilities, dynamically adjusting strategies based on task requirements and automatically correcting errors. The architecture adopts a plug-and-play design concept, allowing different agents to be added or removed as needed without affecting the overall system operation.
Workflow
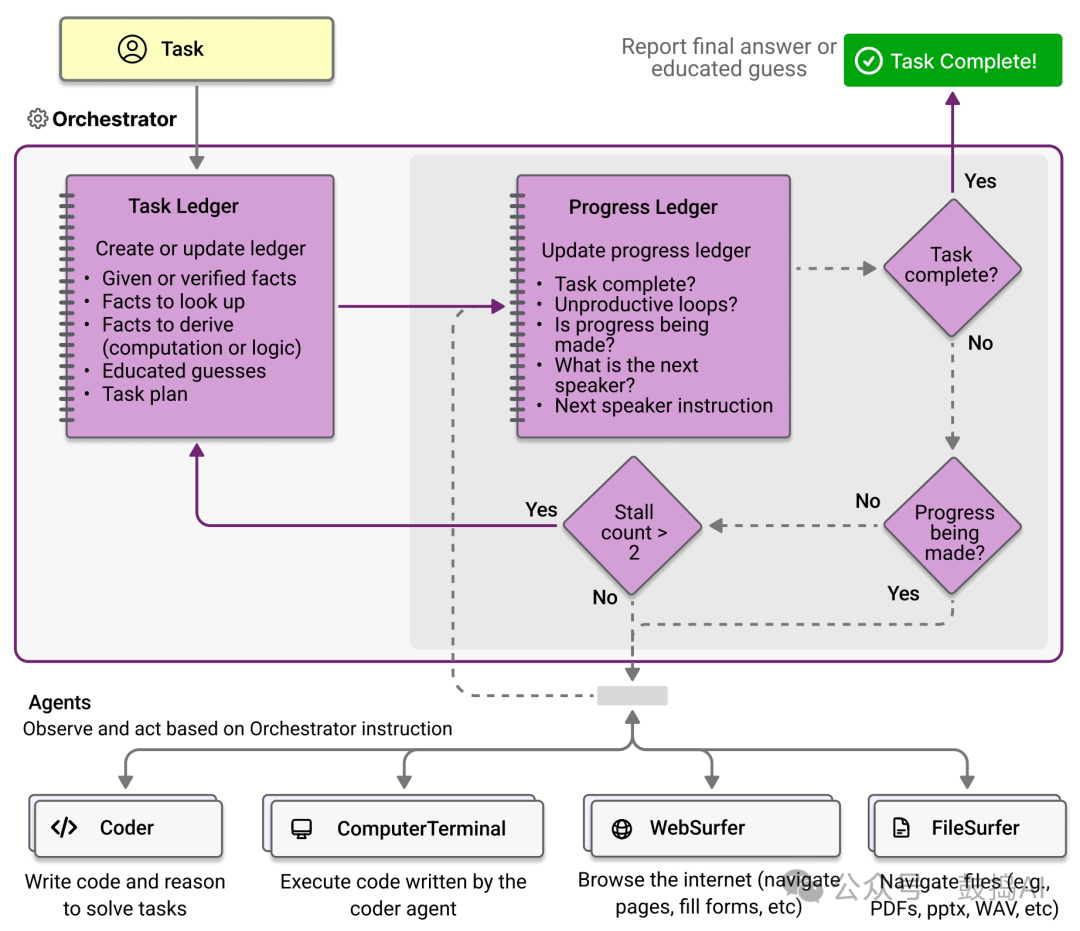
Task Reception and Ledger Creation: The coordinator first receives the task and then creates a task ledger, filling it with given or verified facts, facts that need to be searched and deduced, and preliminary guess information. This information provides a basis for subsequent task planning.
Task Planning and Agent Selection: The coordinator formulates a natural language expressed step-by-step execution plan (similar to chain-of-thought prompting) based on team members’ descriptions and the information in the task ledger to guide task execution, though strict adherence is not required. During the planning process, the coordinator decides which specialized agent to call upon based on task requirements. For example, if the task involves web browsing and operations, the coordinator may choose the WebSurfer agent; if it involves file processing, it may choose the FileSurfer agent, etc.
Task Assignment and Execution Monitoring: The coordinator assigns tasks to the selected specialized agents and monitors task execution progress through a progress ledger. In each inner loop iteration, the coordinator answers questions about whether the task is complete, whether the team is stuck in a loop, whether there is progress, who the next speaking agent is, and what instructions should be given to that agent, to ensure the task proceeds as planned. If task execution issues arise, such as getting stuck in a loop or lacking progress, the coordinator will take appropriate measures, such as re-planning the task, adjusting agent instructions, or changing agents.
Looping and Adjustments: If the coordinator detects the team is stuck in a loop or not making progress, it will increase a counter. When the counter exceeds a threshold, the coordinator will exit the inner loop, reflect and self-improve, update the task ledger, revise the original plan, and then restart the inner loop. This process allows agents to recover from errors or continue advancing tasks under uncertainty.
Task Completion and Result Reporting: When the coordinator determines that the task is complete or has reached termination conditions, it reviews the entire task execution process’s records and ledgers and ultimately reports the final answer or best guess for the task.
Experimental Design and Results
Experimental Setup
The AutoGenBench tool was developed to evaluate the agent system in a strictly controlled environment, ensuring the independence and safety of the experiments.
Three benchmarks, GAIA, AssistantBench, and WebArena, were selected to test the Magentic-One system, which included complex multi-step tasks involving web navigation, file processing, data analysis, and coding skills.
Experimental Results
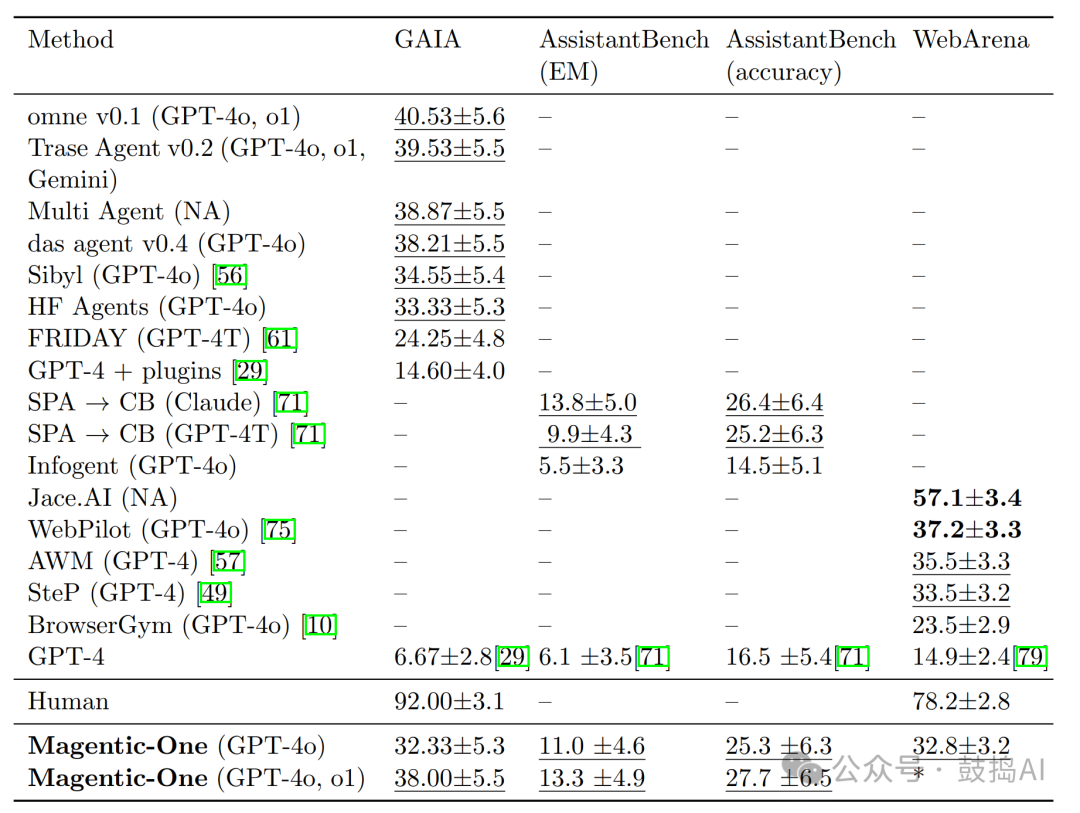
Magentic-One performed excellently in the three benchmark tests, remaining competitive compared to existing state-of-the-art methods. In the test sets of GAIA and AssistantBench, its task completion rates were 32.33% and 25.3%, respectively; in all tasks of WebArena, the completion rate was 32.8%.
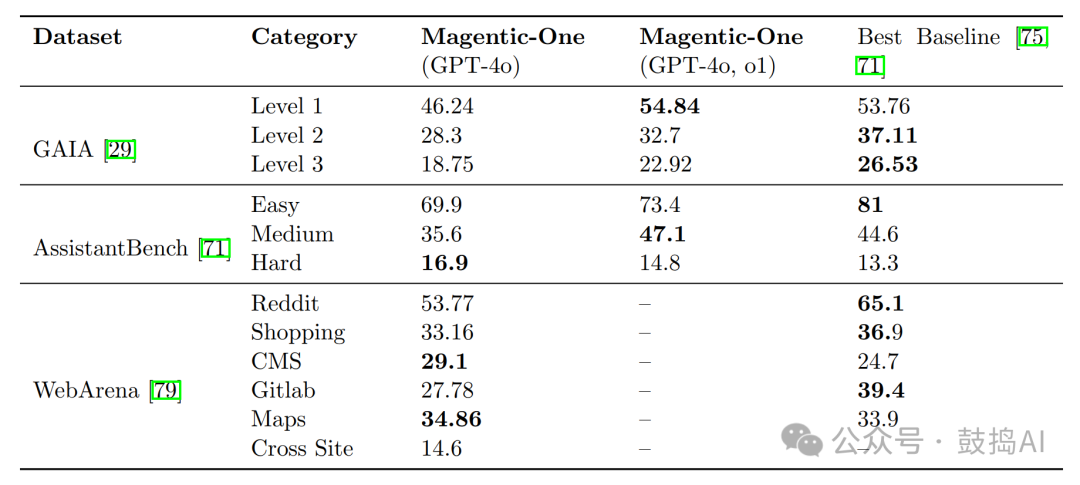
Performance analysis of task difficulty and domains indicates that Magentic-One performs better when handling more difficult tasks, but there is room for improvement on simpler tasks. In the most difficult category of AssistantBench, Magentic-One outperformed baseline methods.
Ablation Studies and Error Analysis
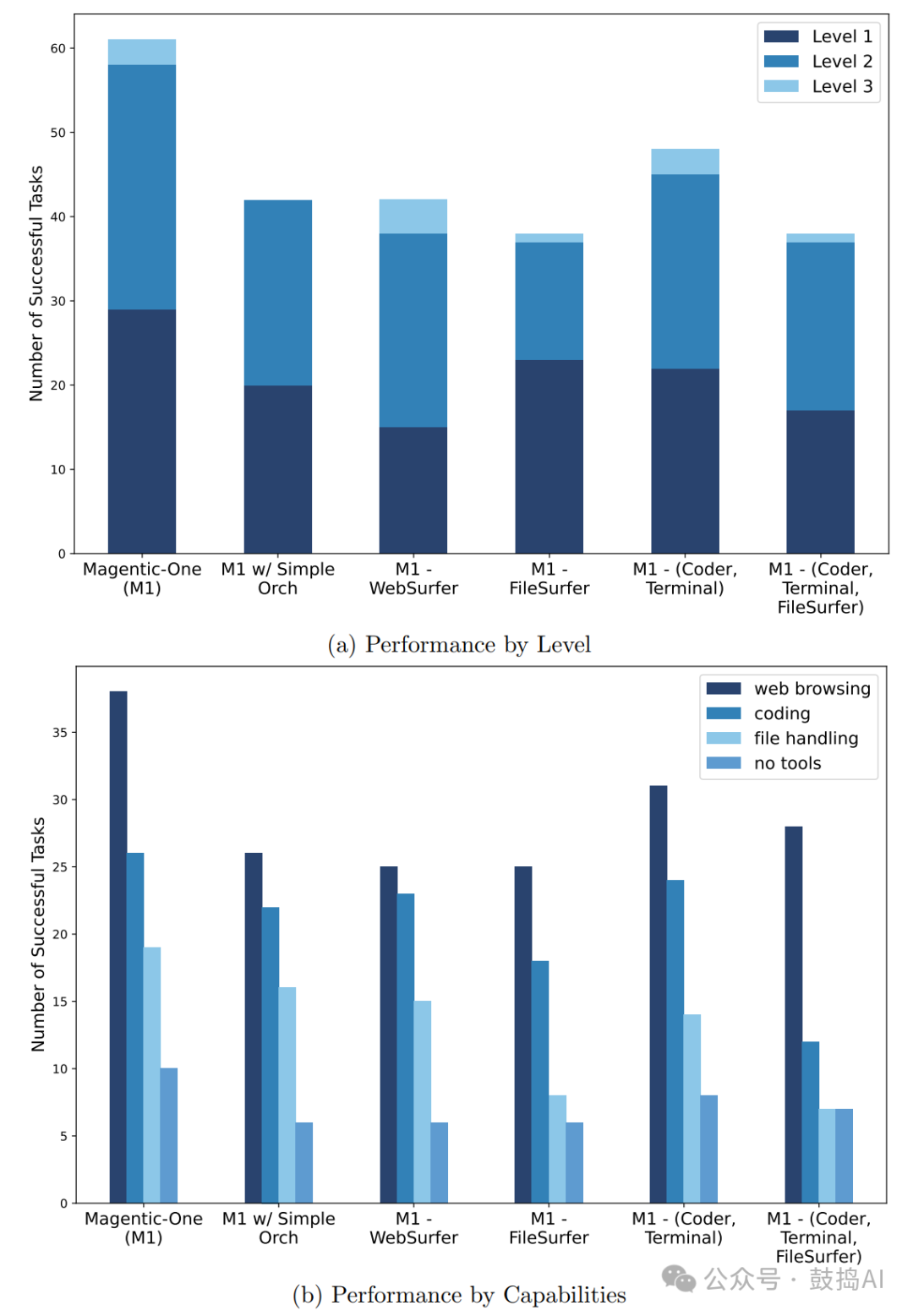
Ablation Studies: Ablation studies were conducted on the GAIA validation set, revealing that the coordinator’s ledger and all specialized agents are crucial for system performance; removing any one agent would lead to a decline in performance.
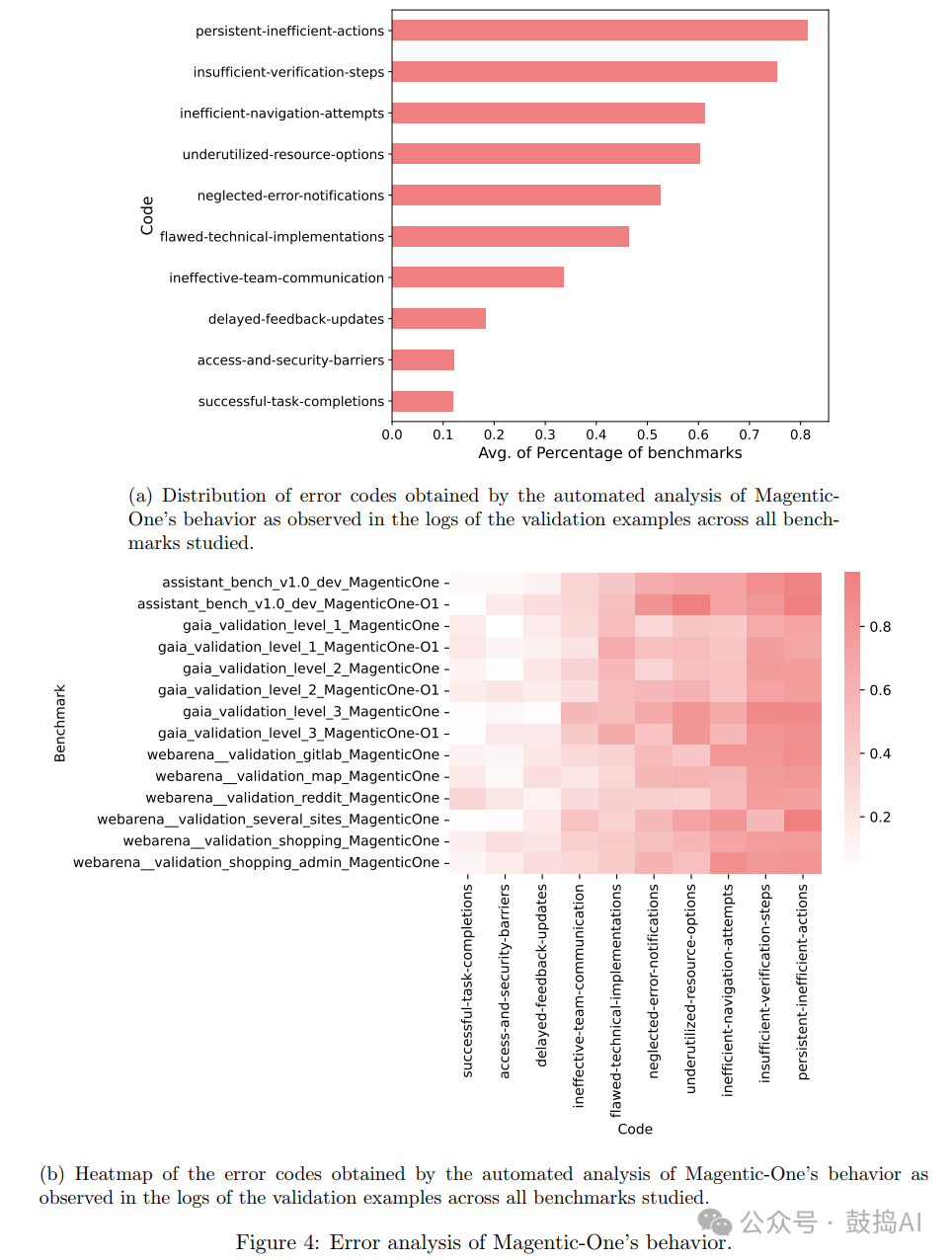
Error Analysis: Automated log analysis revealed that Magentic-One’s primary error patterns include persistent inefficient actions, insufficient verification steps, and inefficient or erroneous navigation, which lead to task delays or unreliable results.
Discussion and Outlook
Advantages of the Multi-Agent Paradigm: The multi-agent design helps simplify development, improve reusability and scalability, allowing different agents to focus on specific tasks. Future research can further explore the impact of different control flows and task assignment methods on performance.
Limitations: Magentic-One faces issues such as single accuracy assessment, high costs, significant delays, limited modalities, restricted action space, limited coding ability, fixed team members, and limited learning capabilities. Future improvements are needed in evaluation protocols, cost reduction, expanding modality support, enhancing coding ability, and achieving dynamic team formation.
Risks and Mitigation Measures: Interactions between agents and the digital world pose risks, such as executing dangerous operations and being subjected to cyberattacks. Measures must be taken to ensure agents operate under the principle of least privilege, increase human oversight and validation, and enhance the model’s safety and robustness.
Please click the card below to follow the “Gad AI” public account
Thank you for reading. If there are any inaccuracies, you can follow the public account “Gad AI” for feedback, and all criticisms and corrections are welcome.
Previous Selected Recommendations
Paper Dispatch | Beihang University’s “Pre-trained Generation Model” Published in Nature Sub-Journal
Paper Dispatch | Tsinghua University’s Latest Review, A Comprehensive Analysis of LLMs-as-Judges Research Status
Tsinghua University’s Latest Review! Understanding the World or Predicting the Future? A Comprehensive Understanding of World Models!
Exciting News! Google Scientists Released the Most Comprehensive 144-Page Review on Reinforcement Learning!
Please open in the WeChat client