
1 Content Overview
Significant progress has been made in automating problem-solving through a group of agents based on large language models (LLMs). Existing LLM-based multi-agent systems can now handle simple conversational tasks. However, solutions for more complex tasks become complicated due to logical inconsistencies, which are caused by the cascading hallucinations that arise from directly chaining large language models. Here, we introduce MetaGPT, an innovative meta-programming framework that integrates efficient human workflows into LLM-based multi-agent collaboration. MetaGPT encodes Standard Operating Procedures (SOPs) into prompt content sequences, streamlining workflows and allowing agents with human-like domain expertise to validate intermediate results and reduce errors. MetaGPT employs an assembly line model to assign a variety of roles to various agents, efficiently breaking down complex tasks into subtasks that require collaboration among many agents. In collaborative software engineering benchmarks, MetaGPT produced more consistent solutions than previous chat-based multi-agent systems.
 Image Source: Wang Knowledge
Image Source: Wang Knowledge
Author: Zhang Changwang, Wang Knowledge
2 Background Introduction
Autonomous agents utilizing large language models (LLMs) are expected to replicate and enhance human workflows. However, existing systems tend to oversimplify complexities relative to real-world applications. They struggle to achieve effective, coherent, and accurate problem-solving processes, especially when meaningful collaboration is required.
Through extensive collaborative practices, humans have established widely accepted Standard Operating Procedures (SOPs) in many fields. These SOPs play a crucial role in supporting task breakdown and effective coordination. Additionally, SOPs outline the responsibilities of each team member while establishing standards for intermediate outputs. Clearly defined SOPs can enhance the consistent and accurate execution of tasks aligned with defined roles and quality standards. For example, in software companies, product managers analyze competition and user needs, creating Product Requirement Documents (PRDs) using standardized structures to guide the development process.
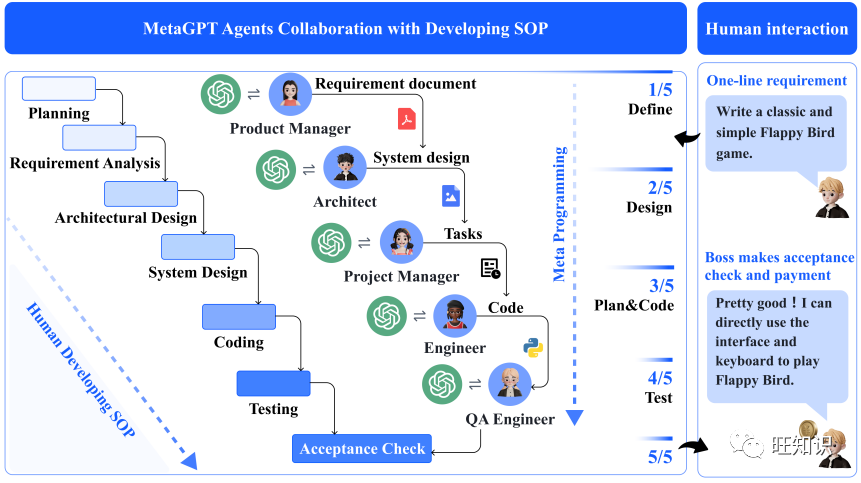 Figure 1: Software Development SOP between MetaGPT and Real-World Human Teams. In software engineering, SOPs facilitate collaboration among different roles. MetaGPT demonstrates its ability to break down complex tasks into specific executable programs assigned to various roles (e.g., product managers, architects, engineers, etc.).
Figure 1: Software Development SOP between MetaGPT and Real-World Human Teams. In software engineering, SOPs facilitate collaboration among different roles. MetaGPT demonstrates its ability to break down complex tasks into specific executable programs assigned to various roles (e.g., product managers, architects, engineers, etc.).
Inspired by these ideas, we designed a GPT-based meta-programming framework called MetaGPT, which can benefit immensely from SOPs. Unlike other works, MetaGPT requires agents to generate high-quality structured requirement documents, design documents, flowcharts, and interface specifications. The use of intermediate structured outputs can significantly increase the success rate of target code generation. By simulating a company, MetaGPT requires all employees to adhere to strict and streamlined workflows, where all handovers must comply with and affirm established standards. In this role-playing framework, this design can reduce the risk of large model hallucinations caused by idle roles engaging in meaningless chit-chat.
MetaGPT benefits from the accumulated experience of SOPs, providing a promising framework for conducting meta-programming. In this context, we adopt the definition of “meta-programming” as “programming to program,” rather than its broader definition of “learning to learn.”
This concept of meta-programming also encompasses early works like CodeBERT and recent projects similar to CodeLlama and WizardCoder. However, MetaGPT stands out as a unique solution that allows efficient meta-programming through well-organized groups of specialized agents. Each agent has a specific role and expertise, adhering to established standards. Agent-based technology can enhance meta-programming, thus supporting automated requirement analysis, system design, code generation-modification-execution, and runtime code debugging.
To validate MetaGPT, we evaluated it using publicly available HumanEval and MBPP datasets. Notably, in code generation benchmark tests, MetaGPT achieved new state-of-the-art results (SoTA), achieving 85.9% and 87.7% on the Pass@1 metric. Compared to other popular frameworks for creating complex software projects (AutoGPT, LangChain, AgentVerse, ChatDev), MetaGPT also excelled in handling higher levels of software complexity and providing extensive functionality. Notably, in our experimental evaluations, MetaGPT achieved a 100% task completion rate, demonstrating the robustness and efficiency of our design (measured in time and token cost).
We summarize our contributions as follows:
-
We introduce MetaGPT, a multi-agent collaborative meta-programming framework based on large language models. It is highly convenient and flexible, with clear functionalities such as role definition and message sharing, making it a useful platform for developing LLM-based multi-agent systems.
-
We innovatively integrated human-like SOPs into the design of MetaGPT, significantly enhancing its robustness and reducing inefficient collaboration among large language model agents. Furthermore, we proposed an innovative execution feedback mechanism that supports runtime debugging and code execution, which can significantly improve code generation quality (absolute improvement of 5.4% on the MBPP dataset).
-
We achieved state-of-the-art technical results (SoTA) on the HumanEval and MBPP datasets. A large number of results convincingly validate MetaGPT, indicating that it is a promising meta-programming framework for developing LLM-based multi-agent systems.
3 How It Works
MetaGPT is a meta-programming framework for multi-agent systems based on LLMs. Section 3.1 explains the role specialization, workflows, and structured communication within this framework, and illustrates how to organize multi-agent systems in the context of SOPs. Section 3.2 proposes a communication protocol to improve role communication efficiency. We also implemented structured communication interfaces and effective publish-subscribe mechanisms. These methods enable agents to obtain directed information from other roles and the public environment. Finally, section 3.3 introduces a self-correcting mechanism with executable feedback to further improve the quality of code generation at runtime.
Figure 2: Communication Protocol (left) and Iterative Programming with Executable Feedback (right) Example. Left: Agents use a shared message pool to publish structured messages, and they can also subscribe to relevant messages based on their profiles. Right: After generating the initial code, the engineer agent runs and checks for errors. If errors occur, the agent will check past messages stored in memory and compare them with the PRD, system design, and code files.
3.1 Standard Operating Procedure Agents
Specialized Roles:Role specialization allows complex tasks to be broken down into smaller, more specific tasks. Solving complex tasks or problems often requires collaborative agents with a variety of skills and expertise, each tailored to contribute specialized outputs for specific issues.
In software companies, product managers typically conduct business-oriented analysis and derive insights, while software engineers are responsible for programming. As shown in Figure 1, we defined five roles in a software company: product manager, architect, project manager, engineer, and QA engineer. In MetaGPT, we specify the profiles of these agents, including their names, overviews, goals, and constraints. We also initialize the specific backgrounds and skills of each role. For example, the product manager can use web search tools, while the engineer can execute code, as shown in Figure 2. All agents follow React-style behavior.
Each agent monitors the environment (i.e., the message pool in MetaGPT) to discover important observations (e.g., messages from other agents). These messages can directly trigger actions or assist in completing tasks.
Cross-agent workflows can be established by defining the roles and operational skills of agents. In our work, we follow Standard Operating Procedures (SOPs), allowing all agents to work sequentially.
Specifically, as shown in Figure 1, after receiving user requirements, the product manager conducts in-depth analysis and develops a detailed PRD, which includes user stories and a pool of requirements. This is the preliminary functional breakdown. The structured PRD is then passed to the architect, who transforms the requirements into system design components, such as a list of documents, data structures, and interface definitions. Once captured in the system design, the information is directly sent to the project manager for task allocation. The engineer continues to execute the specified classes and functions according to the outline. In the subsequent phase, the QA engineer develops test cases to execute strict code quality checks. In this final step, MetaGPT produces a well-designed software solution. In Figure 3, we present the SOP workflow in MetaGPT.
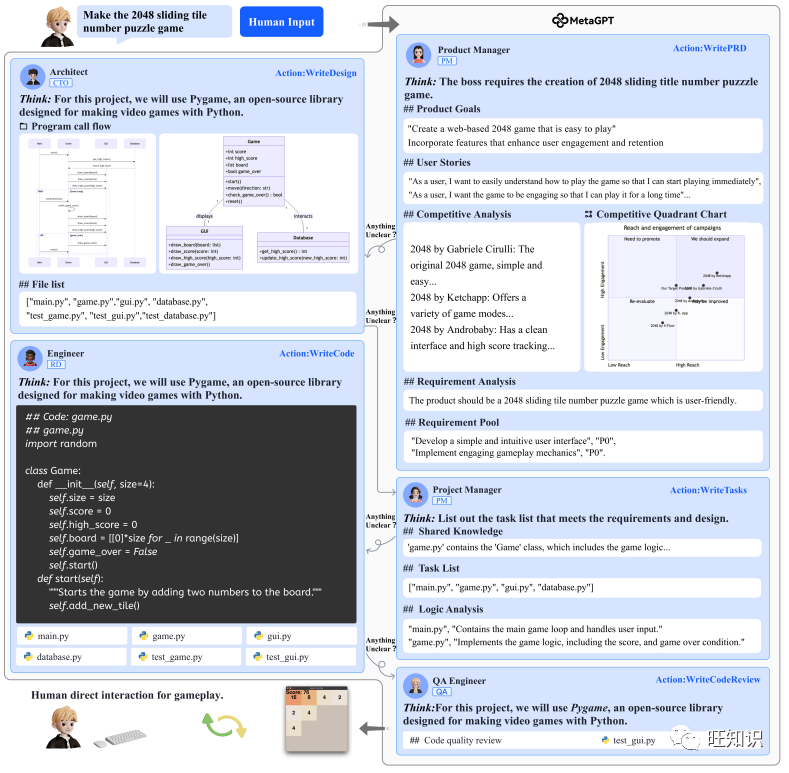
Figure 3: The diagram shows the software development process in MetaGPT, emphasizing its serious reliance on SOPs.
3.2 Communication Protocol
Structured Communication Interface: Most existing LLM-based multi-agent frameworks utilize unconstrained natural language as the communication interface. However, despite the versatility of natural language, a question arises: Is pure natural language communication feasible? Is it sufficient for solving complex tasks?For example, in a game of telephone (or Chinese whispers), after several rounds of communication, the original message may become quite distorted. Inspired by human social structures, we propose using structured communication to formulate the communication methods of agents. We establish a framework and format for each role, requiring individuals to provide necessary outputs based on their specific roles and backgrounds.
As shown in Figure 3, the architect agent produces two outputs: system interface design and a sequence flowchart. These include system module designs and interaction sequences, providing important deliverables for the engineer agent. Unlike ChatDev, agents in MetaGPT communicate through documents and diagrams (structured outputs) rather than dialogue. These documents contain all necessary information, preventing irrelevant or missing content.
Publish-Subscribe Mechanism: Sharing information is crucial for collaboration. For example, architects and engineers often need to reference the PRD. However, communicating this information in previous work was done in a one-to-one manner, which can complicate the communication topology and lead to inefficiencies.
To address this challenge, a viable approach is to store information in a global message pool. As shown in Figure 2 (left), we introduce a shared message pool that allows all agents to exchange messages directly. These agents not only publish their structured messages but also transparently access messages from other entities in the pool. Any agent can retrieve the required information directly from the shared pool, thus eliminating the need to ask other agents and wait for their responses. This improves communication efficiency.
Sharing all information with every agent may lead to information overload. During task execution, agents often prefer to receive only task-relevant information and avoid distractions from irrelevant details. The effective management and dissemination of this information play a crucial role. We provide a simple and effective solution—a subscription mechanism. Agents do not rely on dialogue but instead use role-specific interests to extract relevant information. They can choose which information to follow based on their role profiles. In practical implementation, agents only activate their operations after receiving all their prerequisite dependencies. As shown in Figure 3, the architect mainly focuses on the PRD provided by the product manager, while the documents of roles like QA engineers may be less relevant.
3.3 Iterative Programming with Executable Feedback
Debugging and optimization processes play a critical role in daily programming tasks. However, existing methods often lack self-correcting mechanisms, leading to unsuccessful code generation. Previous works introduced non-executable code reviews and self-reflection. However, they still face challenges in ensuring the executability and runtime correctness of the code.
Due to LLM hallucinations, our first implementation of MetaGPT overlooked certain errors during the review process. To overcome this issue, we introduced an executable feedback mechanism after initial code generation to enhance code iteration. More specifically, as shown in Figure 2, engineers are required to write code based on the original product requirements and designs.
This enables engineers to continuously improve the code using their historical execution and debugging memory. To gain additional information, engineers write and execute corresponding unit test cases, and subsequently receive the test results. If necessary, additional development tasks can be initiated. Otherwise, engineers continue debugging the code before resuming programming. This iterative testing process continues until the tests pass or the maximum retry count is reached.
4 Experimental Evaluation
4.1 Experimental Environment Configuration
Datasets: We use publicly available datasets, HumanEval and MBPP, as well as a more challenging software development dataset, SoftwareDev, that we generated ourselves.
-
HumanEval consists of 164 handwritten programming tasks. These tasks include functional specifications, descriptions, reference code, and tests.
-
MBPP consists of 427 Python tasks. These tasks cover core concepts and standard library functionalities and include descriptions, reference code, and automated tests.
-
Our SoftwareDev dataset is a collection of 70 representative software development task examples, each with its own task prompt. These tasks vary in scope, such as mini-games, image processing algorithms, and data visualization. They provide a robust testing platform for real development tasks. Unlike previous datasets, SoftwareDev focuses on engineering aspects. In our comparisons, we randomly selected seven representative tasks for evaluation.
Evaluation Metrics: For the HumanEval and MBPP datasets, we follow the unbiased version of Pass@k to evaluate the functional accuracy of top-k code generation:
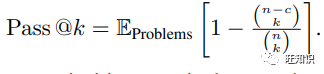
For the SoftwareDev dataset, we prioritize practical use and evaluation performance through human evaluation (A, E) or statistical analysis (B, C, D):
-
A Executability: Execution scoring from 1 (failure/not working) to 4 (perfect). “1” indicates non-runnable, “2” indicates runnable but not perfect, “3” indicates nearly perfect, and “4” indicates perfect code.
-
B Cost: This cost assessment includes (1) runtime, (2) token usage, and (3) expenditure.
-
C Code Statistics: This includes (1) code files, (2) lines of code per file, and (3) total lines of code.
-
D Productivity: Essentially defined as the number of tokens used divided by the number of lines of code, i.e., tokens consumed per line of code.
-
E Human Revision Cost: Quantified by the number of modification rounds required to ensure code runs smoothly, indicating the frequency of human intervention, such as debugging or importing packages.
Baseline: We compare our approach with recent code domain LLMs, including AlphaCode, Incoder, CodeGeeX, CodeGen, CodeX, and CodeT, as well as general LLMs including PaLM and GPT-4.
We modified certain role-based prompts in MetaGPT to generate code suitable for target problems (e.g., generating functions instead of classes for HumanEval and MBPP). For the SoftwareDev benchmark tests, we provide detailed comparisons between MetaGPT, AutoGPT, LangChain+Python Read-Eval-Print Loop (REPL) tools, Agent-Verse, and ChatDev.
4.2 Key Experimental Results
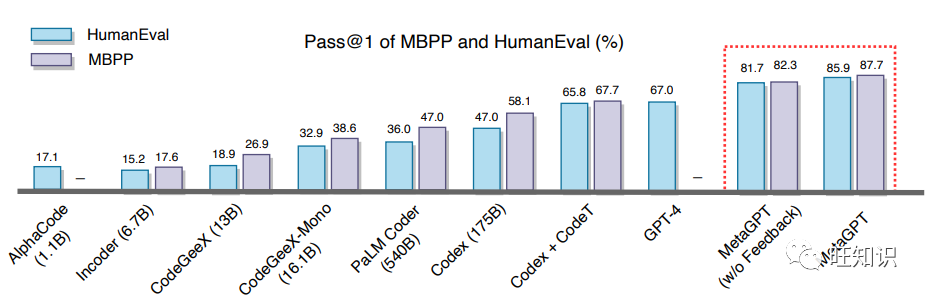
Figure 4: Pass rates in a single attempt on MBPP and HumanEval evaluation datasets
As shown in Figure 4, MetaGPT outperformed all other methods on the MBPP and HumanEval evaluation datasets. When collaborating with GPT-4, MetaGPT significantly improved Pass@k in HumanEval benchmarks compared to GPT-4. It achieved 85.9% and 87.7% on these two public benchmark tests. Furthermore, as shown in Table 1, on the challenging SoftwareDev dataset, MetaGPT outperformed ChatDev on nearly all metrics. Notably, considering executability, MetaGPT scored 3.75, very close to 4 (perfect). Additionally, it took less time (503 seconds), significantly less than ChatDev. Considering code statistics and human modification costs, it also performed significantly better than ChatDev. Although MetaGPT required more tokens (24,613 or 31,255 compared to 19,292), generating a line of code only consumed 126.5/124.3 tokens. In contrast, ChatDev used 248.9 tokens. These results highlight the benefits of SOPs in collaboration among multiple agents. Additionally, we visually demonstrate MetaGPT’s autonomous software generation capabilities through examples (Figure 5).
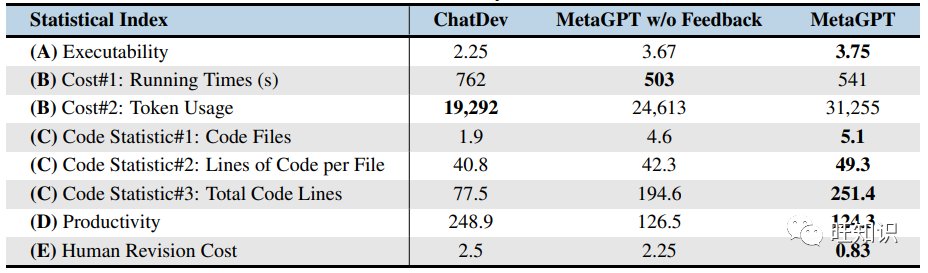 Table 1: Statistical analysis of evaluation results for the SoftwareDev dataset
Table 1: Statistical analysis of evaluation results for the SoftwareDev dataset
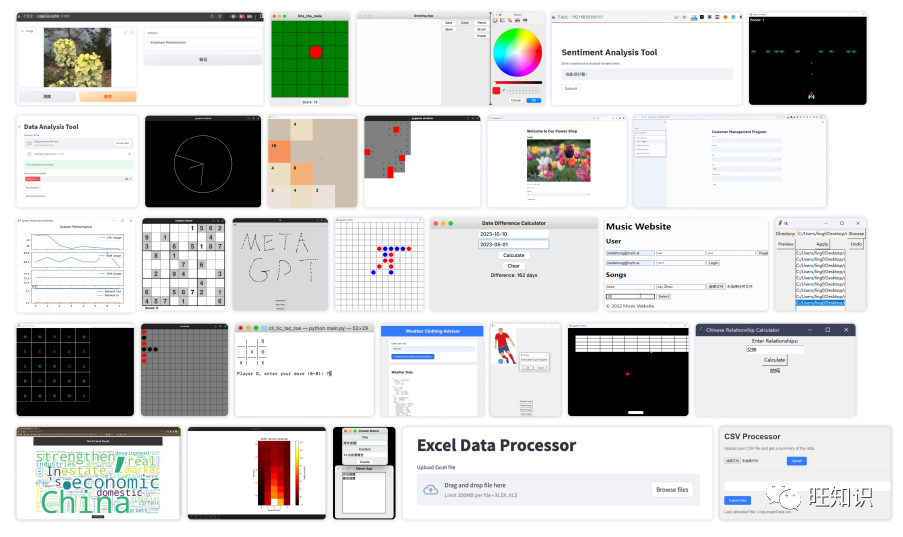 Figure 5: Demo software developed by MetaGPT
Figure 5: Demo software developed by MetaGPT
4.3 Capability Analysis
Compared to open-source baseline methods like AutoGPT and autonomous agents like AgentVerse and ChatDev, MetaGPT provides functionalities for software engineering tasks. As shown in Table 2, our framework encompasses various capabilities to effectively handle complex and specialized development tasks. The integration of SOPs (e.g., role-playing expertise, structured communication, simplified workflows) can significantly improve code generation. Other baseline methods can easily integrate similar SOP designs to enhance their performance, similar to injecting thought chains into LLMs.
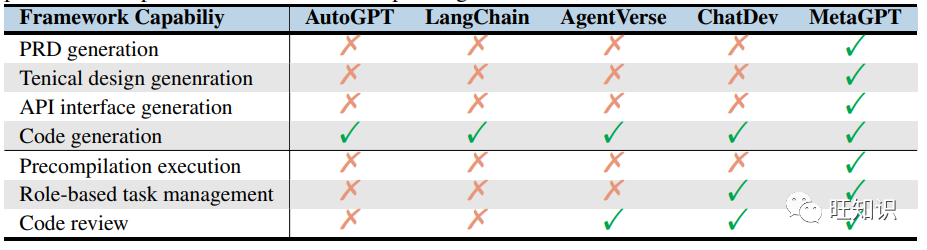 Table 2: Comparison of functionalities between MetaGPT and other methods.
Table 2: Comparison of functionalities between MetaGPT and other methods.
4.4 Ablation Studies
Effectiveness of Roles: To understand the impact of different roles on the final outcome, we performed two tasks, including generating executable code and calculating average statistics. When we excluded certain roles, non-functional code was generated. As shown in Table 3, adding roles different from the engineer can continuously improve revisions and executability. While more roles slightly increase costs, overall performance significantly improves, demonstrating the effectiveness of various roles.
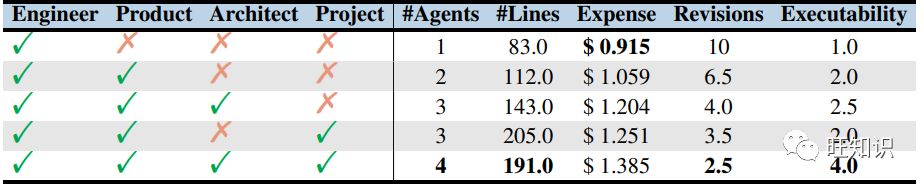 Table 3: Role ablation study. “Product”: “Product Manager”, ‘Project’: ‘Project Manager’.
Table 3: Role ablation study. “Product”: “Product Manager”, ‘Project’: ‘Project Manager’.
Effectiveness of Executable Feedback Mechanism: As shown in Figure 4, adding executable feedback to MetaGPT significantly improved Pass@1 on HumanEval and MBPP by 4.2% and 5.4%, respectively. Furthermore, Table 1 shows that the feedback mechanism improved executability (from 3.67 to 3.75) and reduced human modification costs (from 2.25 to 0.83). These results demonstrate how our designed feedback mechanism can generate higher quality code. Tables 4 and 6 show additional quantitative results for MetaGPT and MetaGPT without executable feedback.
5 Related Work
Automatic Programming: The roots of automatic programming can be traced back to the last century. In 1969, Waldinger & Lee (1969) introduced “PROW,” a system designed to accept program specifications written in predicate calculus, generate algorithms, and create LISP implementations (McCarthy, 1978). Balzer (1985) and Soloway (1986) made efforts to advance automatic programming and identify potential methods for achieving it. Recent approaches utilize natural language processing (NLP) techniques (Ni et al., 2023; Skreta et al., 2023; Feng et al., 2020; Liet et al., 2022; Chen et al., 2018; 2021b; Zhang et al., 2023). Automatic programming has evolved into an industry providing paid features (e.g., Microsoft Copilot). Recently, LLM-based agents (Yao et al., 2022; Shinn et al., 2023; Lin et al., 2023) have advanced automatic programming development. Among them, ReAct (Yao et al., 2022) and Reflexion (Shinn et al., 2023) utilize a series of thinking prompts (Wei et al., 2022) to generate reasoning trajectories and action plans with LLMs. Both works demonstrate the effectiveness of ReAct-style reasoning loops as design paradigms supporting automatic programming. Additionally, ToolFormer (Schick et al., 2023) can learn how to use external tools through simple APIs. This research is most consistent with our work by Li et al. (2023), which proposed a simple role-playing programming framework involving communication between agents playing different roles. Qian et al. (2023) leverage multiple agents for software development. Although existing papers (Li et al., 2023; Qian et al., 2023) have improved productivity, they have not fully utilized structured output formats for effective workflows. This makes it more challenging to address complex software engineering problems.
LLM-Based Multi-Agent Frameworks: Recently, LLM-based autonomous agents have garnered significant interest in both industry and academia (Wang et al., 2023).
Many works (Wang et al., 2023c; Du et al., 2023; Zhuge et al., 2023; Hao et al., 2023; Akata et al., 2023) have improved the problem-solving capabilities of LLMs through integrated discussions. Stable-Alignment (Liu et al., 2023) derives consensus value judgments through interactions with agents in a sandbox to create instruction datasets. Other works focus on sociological phenomena. For example, Generative Agents (Park et al., 2023) created a “town” composed of 25 agents to study linguistic interaction, social understanding, and collective memory. In the Natural Language-Based Mind Society (NLSOM) (Zhuge et al., 2023), agents with different functionalities interact through multi-round “mind storms” to solve complex tasks. Cai et al. (2023) proposed a model that combines large models as tool makers with smaller models as tool users to reduce costs.
Some works emphasize cooperation and competition related to planning and strategy (Bakhtin et al., 2022); others propose LLM-based economies (Zhuge et al., 2023). In our implementation, we observed several challenges faced by multi-agent collaboration, such as maintaining consistency and avoiding unproductive loops. This prompted us to focus on applying advanced concepts, such as standard operating procedures in software development, to multi-agent frameworks.
6 Conclusion and Outlook
This work introduces MetaGPT, a novel meta-programming framework that leverages SOPs to enhance the problem-solving capabilities of LLM-based multi-agent systems. MetaGPT models a group of agents to simulate a software company, similar to the simulated towns and Minecraft sandboxes in Voyager. MetaGPT utilizes role specialization, workflow management, and efficient sharing mechanisms (e.g., message pools and subscriptions), making it a flexible and portable platform suitable for autonomous agents and multi-agent frameworks. It employs executable feedback mechanisms to improve the quality of code generation at runtime. Through extensive experiments, MetaGPT achieves state-of-the-art performance across multiple benchmark tests. The successful integration of human-like SOPs inspires future research into human-like technologies for artificial multi-agent systems. We also view our work as an early attempt to standardize LLM-based multi-agent frameworks.
Original Paper:
Sirui Hong et al., MetaGPT: meta programming for a multi-agent collaborative framework, https://arxiv.org/pdf/2308.00352.pdf.