
The Retrieval-Augmented Generation (RAG) technology is revolutionizing the AI application field by integrating external knowledge bases with internal knowledge of LLM (Large Language Model), enhancing the accuracy and reliability of AI systems. The knowledge “recall ability” of the multimodal knowledge extractor directly determines whether the large model can obtain accurate professional knowledge when answering reasoning questions.
However, as RAG systems are widely applied, challenges arise in their evaluation and optimization. Existing evaluation methods struggle to comprehensively reflect the complexity and actual performance of RAG systems. Recently, Amazon and the Shanghai Artificial Intelligence Research Institute launched the RAGChecker diagnostic tool, which can provide detailed, comprehensive, and reliable diagnostic reports for RAG systems, indicating directions for performance enhancement. The RAGChecker framework has designed a comprehensive evaluation system that includes overall metrics, diagnostic retriever metrics, and diagnostic generator metrics.
By inputting samples that include queries, documents, and real answers, and using large language models to break down the text into independent statements, each statement’s accuracy is then verified by another model, achieving fine-grained evaluation of the model.
In related studies, RAGChecker has undergone rigorous experimental validation, and its correlation with human judgment far exceeds traditional evaluation metrics like BLEU, ROUGE, and BERTScore, fully demonstrating its scientific validity and reliability. The RAGChecker metrics can also assist practitioners in developing and evaluating more effective RAG systems, providing improvement suggestions by adjusting the settings of RAG systems (such as the number of retrievers, block size, block overlap ratio, and generation prompts). Based on such an authoritative evaluation framework, we conducted a comprehensive performance test on MedGPT, a medical vertical large model.
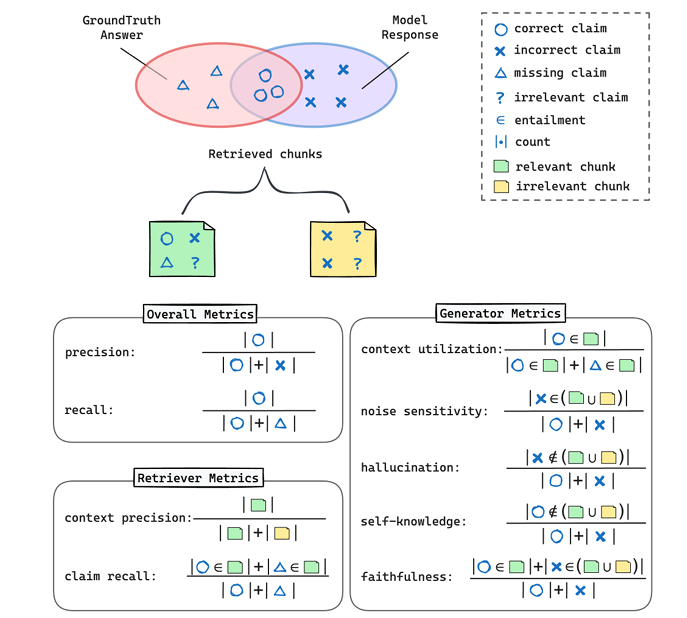
Figure: Illustration of the proposed metrics in RAGChecker
This test selected 30 medical professional questions simulated by professional doctors, and the results showed that MedGPT exhibited significant advantages across multiple key metrics.
In overall evaluation (measuring the overall quality of the entire RAG process), MedGPT’s precision reached 65.4, recall was 58.3, and the F1 score was 59.9, which are better scores compared to the best scores of other models mentioned in the reference text. This means that MedGPT can more accurately hit key information when addressing medical issues and comprehensively cover the knowledge areas related to the questions, providing strong data support for medical decision-making.
In the retrieval dimension (the ability to find relevant information), context precision reached 62.2. This indicates that MedGPT can filter out content closely related to the questions with high precision when retrieving medical knowledge, ensuring high-quality material for subsequent answer generation.
In the generation dimension (the ability to utilize retrieved context, handle noisy information, and generate accurate and faithful responses), MedGPT showed excellent performance. Its context utilization rate was 66.3, fully reflecting its ability to efficiently integrate and utilize retrieved medical knowledge.
The noise sensitivity in relevant chunks of incorrect statements in model-generated responses was only 16.4; the noise sensitivity in irrelevant chunks was 4.5, which strongly proves that MedGPT has outstanding resistance to interference when processing complex medical information, effectively filtering out irrelevant noise and focusing on generating accurate and valuable answers. Overall, MedGPT’s performance in the medical vertical field is already quite remarkable, providing reliable and accurate medical knowledge and advice for medical professionals and patients.
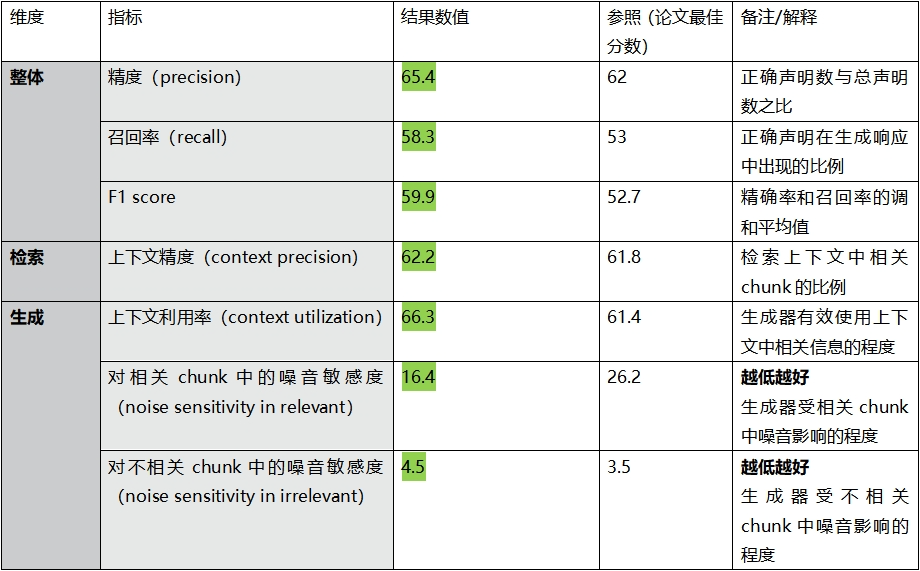
The above test results strongly confirm that MedGPT, as a vertical large model focused on the medical field, demonstrates excellent performance in addressing medical professional questions. With its high precision, high reliability, and strong anti-interference capability, it stands out in the field of medical AI. Whether assisting medical personnel in diagnosing diseases or providing professional medical consultation services for patients, MedGPT is undoubtedly an ideal choice, providing strong momentum for the intelligent process of the medical industry.
References:
[2408.08067] RAGChecker: A Fine-grained Framework for Diagnosing Retrieval-Augmented Generation