Many researchers often need to input a bunch of theorem formulas when writing papers. Some formulas are exactly as they appear in books or literature, and typing them one by one into Word or LaTeX can be very tiring. If there were software that could recognize formulas, it would definitely improve efficiency. Today, I will recommend a formula recognition software.
Software Introduction
InftyReader is an OCR application developed by a Japanese company that can recognize formulas and foreign text. We mainly use it to recognize formulas from PDF articles or images. Unlike ABBYY, it can recognize and translate complex mathematical formulas into LaTeX, MathML, XHTML, HRTeX, IML, and Microsoft Word documents!
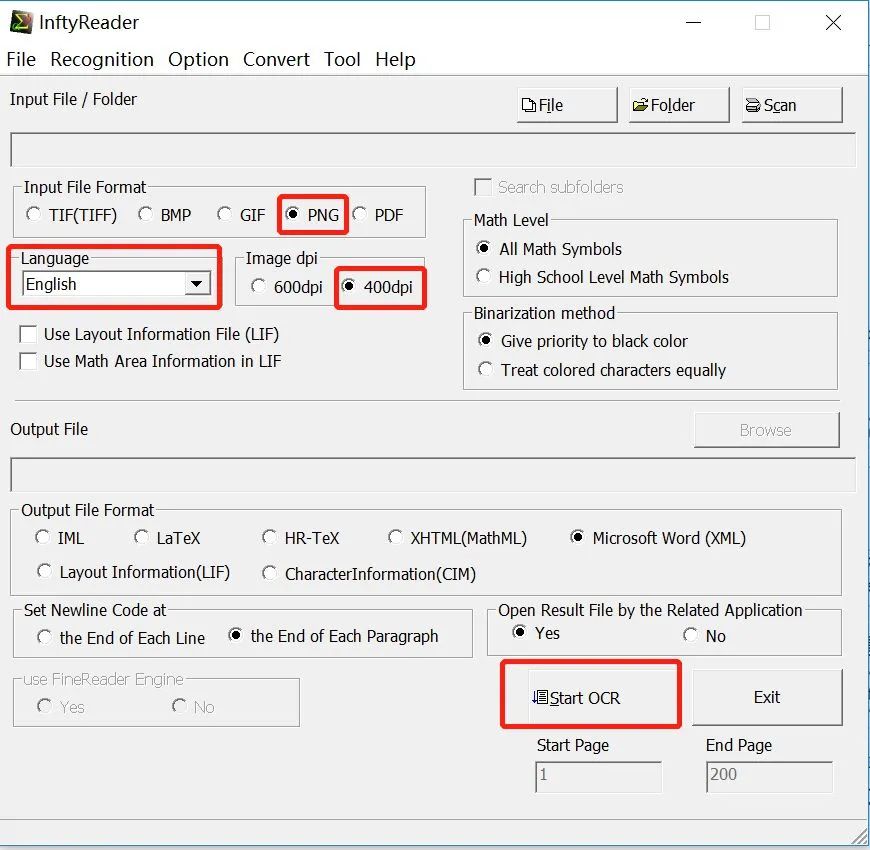
This software operates in a completely English environment. After opening the software, first find the document type selection area after the file button; we choose PDF, then go back to the file button to open the document that needs recognition. In the output file format, select LaTeX, then find start OCR and press Enter.
Here are some notes:
1. This software can recognize English and Japanese literature but cannot recognize Chinese literature.
2. The software may have some recognition errors, requiring some experience for judgment.
3. This software works best for text-based PDFs or requires clear scanned versions.
4. JPG images can also be recognized, but similarly require high clarity and resolution.
5. This is a paid software; otherwise, you can only scan five pages per day.
6. The principle of the software is to convert PDF files into images, then recognize the images, which can be slow, and finally generate XML to open in Word.
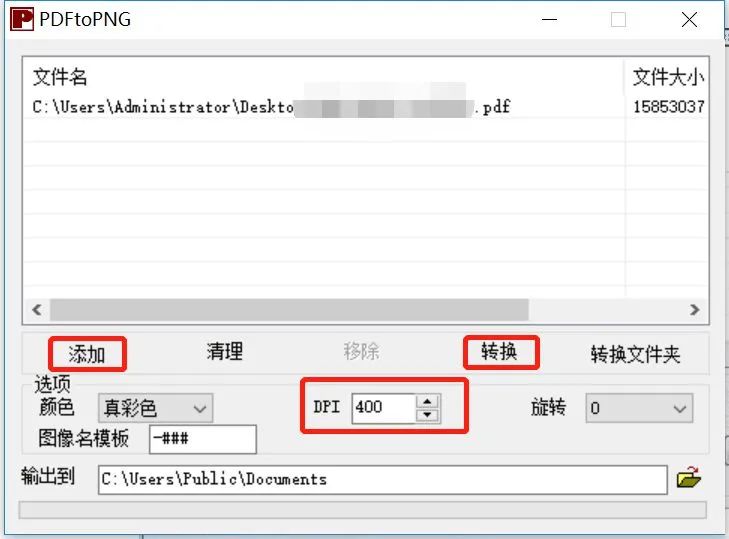
Step 1: Convert the PDF paper to PNG format.
Open PDFtoPNG, as shown in the image below, and remember to change the DPI to 400.
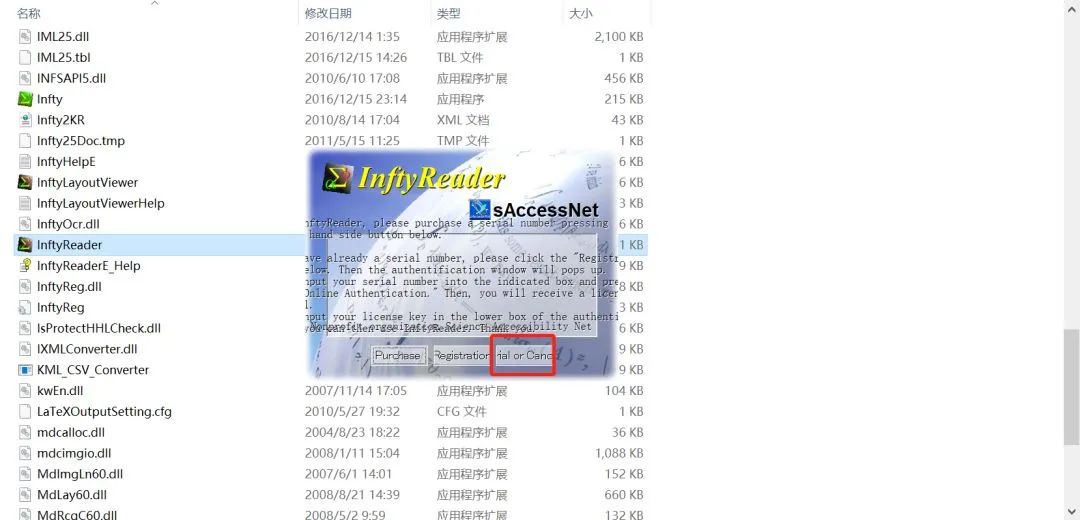
Step 2: Open InftyReader, select trial version, noting that the trial version can only parse five images of formulas per day. At the end of this article, I will provide a PJ version.
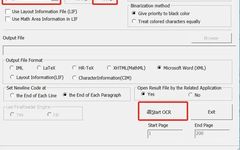
Step 3: After opening the software, follow the instructions in the red box. The key points are to select PNG, English, 400 DPI, output in Word format, and finally click Start OCR. Note that the trial version can only parse one image at a time. You can also directly import PDF format, but it is slower.

Step 4: Word usually opens the XML document automatically; if not, please go to the output directory to open it in Word and compare the recognition effect.
The original image part is as follows:

The recognition result is as follows, showing a high accuracy of recognized formulas, and the formulas are editable.

Reply with the keyword 【20210603】 in the backend for the authorization tutorial.
Past Content Review
Hard-to-find formula editors online!