
Author: Sovit Rath
Translated by: ronghuaiyang
This article fine-tunes the TrOCR model on a dataset of curved and blurry text, analyzing the code and training results at each step.
TrOCR (Transformer based Optical Character Recognition) model is one of the best OCR models. In previous articles, we analyzed how well this model performs on single-line printed text and handwritten text. However, like other deep learning models, it has limitations. It performs poorly on curved text. This article will focus on fine-tuning TrOCR on a dataset of curved text.

We know that the previous TrOCR could not recognize curved text and vertical text images. These images are present in SCUT-CTW1500, and we will train TrOCR on this dataset and analyze the results to understand the boundaries of the TrOCR model in different use cases.
We use Hugging Face’s training API to train the model. To complete the entire operation, we need to follow the steps below:
-
Prepare and Analyze Curved Text Image Dataset
-
Load Hugging Face’s TrOCR Small Printed Text Model
-
Initialize Hugging Face’s Sequence to Sequence Training API
-
Define Evaluation Metrics
-
Train Model and Run Inference
Curved Text Dataset
The SCUT-CTW1500 dataset (hereafter referred to as CTW1500) contains thousands of images of curved text in real-world scenes.
The original dataset is available in the official repository: https://github.com/Yuliang-Liu/Curve-Text-Detector, which includes training and testing sets. We split the training set into training and validation sets.
The final dataset contains 6052 training samples and 1651 validation samples. The image labels are stored in a text file, and the images and labels in the dataset are as follows:

From the above image, we can clearly see a few things. In addition to curved text images, the dataset also contains blurry and hazy images. This real-world variation in images presents challenges for deep learning models. Understanding the characteristics of images and text in such a diverse dataset is crucial for the latest performance of any OCR model. This presents an interesting challenge for the TrOCR model, which can certainly perform better on such images after training.
Fine-Tuning TrOCR on Curved Text
Let’s jump into the technical aspects of this article. From here, we will discuss the code for the TrOCR training process in detail.
Installing and Importing Required Libraries
The first step is to install all the required libraries.
!pip install -q transformers
!pip install -q sentencepiece
!pip install -q jiwer
!pip install -q datasets
!pip install -q evaluate
!pip install -q -U accelerate
!pip install -q matplotlib
!pip install -q protobuf==3.20.1
!pip install -q tensorboar
Among these, some are very important:
-
transformers: This is Hugging Face’stransformerslibrary, through which we can access hundreds of transformer-based models, including the TrOCR model. -
sentencepiece: This is thesentencepiecetokenizer library, which can convert words into tokens and numbers, and is also part of Hugging Face. -
jiwer: Thejiwerlibrary contains some metrics for speech and language recognition, including WER (Word Error Rate) and CER (Character Error Rate). We will use the CER metric to evaluate the model training results.
Next, we import the required libraries and packages.
import os
import os
import torch
import evaluate
import numpy as np
import pandas as pd
import glob as glob
import torch.optim as optim
import matplotlib.pyplot as plt
import torchvision.transforms as transforms
from PIL import Image
from zipfile import ZipFile
from tqdm.notebook import tqdm
from dataclasses import dataclass
from torch.utils.data import Dataset
from urllib.request import urlretrieve
from transformers import (
VisionEncoderDecoderModel,
TrOCRProcessor,
Seq2SeqTrainer,
Seq2SeqTrainingArguments,
default_data_collator
)
In the code above, there are several important import statements:
-
VisionEncoderDecoderModel: We need this class to define different TrOCR models. -
TrOCRProcessor: TrOCR requires specific normalization of the dataset, and this class will normalize and preprocess the images appropriately. -
Seq2SeqTrainer: This is used to initialize the training API. -
Seq2SeqTrainingArguments: During training, the training API needs some parameters, and theSeq2SeqTrainingArgumentsclass initializes all the necessary parameters and passes them to the API. -
transforms: The Torchvisiontransformsmodule is used for data augmentation on images.
Now, we set the random seed and define the computation device.
def seed_everything(seed_value):
np.random.seed(seed_value)
torch.manual_seed(seed_value)
torch.cuda.manual_seed_all(seed_value)
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
seed_everything(42)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
Download and Unzip Dataset
The following code includes a helper function to download and unzip CTW1500.
def download_and_unzip(url, save_path):
print(f"Downloading and extracting assets....", end="")
# Downloading zip file using urllib package.
urlretrieve(url, save_path)
try:
# Extracting zip file using the zipfile package.
with ZipFile(save_path) as z:
# Extract ZIP file contents in the same directory.
z.extractall(os.path.split(save_path)[0])
print("Done")
except Exception as e:
print("\nInvalid file.", e)
URL = r"https://www.dropbox.com/scl/fi/vyvr7jbdvu8o174mbqgde/scut_data.zip?rlkey=fs8axkpxunwu6if9a2su71kxs&dl=1"
asset_zip_path = os.path.join(os.getcwd(), "scut_data.zip")
# Download if asset ZIP does not exist.
if not os.path.exists(asset_zip_path):
download_and_unzip(URL, asset_zip_path)
After extraction, the directory structure of the dataset is as follows.
scut_data/
├── scut_train
├── scut_test
├── scut_train.txt
└── scut_test.txt
The data is in the scut_data folder, containing two subdirectories: scut_train and scut_test.
Two text files contain the annotation information, formatted as follows:
006052.jpg ty Starts with Education
006053.jpg Cardi's
006054.jpg YOU THE BUSINESS SIDE OF GREEN
006055.jpg hat is
...
Each line includes the image file name and the text information, separated by a space. The text and image are separated by the first space, and the file name cannot contain spaces.
Define Configuration
Before starting training, we need to define some configurations for training, the dataset, and the model.
@dataclass(frozen=True)
class TrainingConfig:
BATCH_SIZE: int = 48
EPOCHS: int = 35
LEARNING_RATE: float = 0.00005
@dataclass(frozen=True)
class DatasetConfig:
DATA_ROOT: str = 'scut_data'
@dataclass(frozen=True)
class ModelConfig:
MODEL_NAME: str = 'microsoft/trocr-small-printed'
The model will train for 35 epochs, using a batch size of 48 and a learning rate of 0.00005. A learning rate that is too high can lead to unstable training, causing the loss to increase significantly from the start.
We also define the root directory path for the dataset and specify the model to fine-tune as the small printed text model of TrOCR.
Visualizing Some Samples
We visualize some samples from the dataset:
def visualize(dataset_path):
plt.figure(figsize=(15, 3))
for i in range(15):
plt.subplot(3, 5, i+1)
all_images = os.listdir(f"{dataset_path}/scut_train")
image = plt.imread(f"{dataset_path}/scut_train/{all_images[i]}")
plt.imshow(image)
plt.axis('off')
plt.title(all_images[i].split('.')[0])
plt.show()
visualize(DatasetConfig.DATA_ROOT)

Preparing the Dataset
The labels are in the text file, and we convert the training and testing text into a Pandas DataFrame format for easier loading.
train_df = pd.read_fwf(
os.path.join(DatasetConfig.DATA_ROOT, 'scut_train.txt'), header=None
)
train_df.rename(columns={0: 'file_name', 1: 'text'}, inplace=True)
test_df = pd.read_fwf(
os.path.join(DatasetConfig.DATA_ROOT, 'scut_test.txt'), header=None
)
test_df.rename(columns={0: 'file_name', 1: 'text'}, inplace=True)
Now, the file_name column contains the file names, and the text column contains the corresponding text for the images.

The next step is to define data augmentations.
# Augmentations.
train_transforms = transforms.Compose([
transforms.ColorJitter(brightness=.5, hue=.3),
transforms.GaussianBlur(kernel_size=(5, 9), sigma=(0.1, 5)),
])
We apply ColorJitter and GaussianBlur to the images, without the need for rotation and flipping, as the original dataset already has sufficient diversity.
The best way to prepare the dataset is to write a custom dataset class, allowing better control over the input. The following code defines the CustomOCRDataset class to prepare the dataset.
class CustomOCRDataset(Dataset):
def __init__(self, root_dir, df, processor, max_target_length=128):
self.root_dir = root_dir
self.df = df
self.processor = processor
self.max_target_length = max_target_length
def __len__(self):
return len(self.df)
def __getitem__(self, idx):
# The image file name.
file_name = self.df['file_name'][idx]
# The text (label).
text = self.df['text'][idx]
# Read the image, apply augmentations, and get the transformed pixels.
image = Image.open(self.root_dir + file_name).convert('RGB')
image = train_transforms(image)
pixel_values = self.processor(image, return_tensors='pt').pixel_values
# Pass the text through the tokenizer and get the labels,
# i.e. tokenized labels.
labels = self.processor.tokenizer(
text,
padding='max_length',
max_length=self.max_target_length
).input_ids
# We are using -100 as the padding token.
labels = [label if label != self.processor.tokenizer.pad_token_id else -100 for label in labels]
encoding = {"pixel_values": pixel_values.squeeze(), "labels": torch.tensor(labels)}
return encoding
The __init__() method receives the path of the root folder, DataFrame, TrOCR processor, and the maximum length of labels as parameters.
The __getitem__() method first reads the image and label, then applies data augmentation, and uses TrOCRProcessor to return normalized pixel values in PyTorch tensor format. The text labels are tokenized, and if the labels are shorter than 128 characters, they are padded with -100, and if longer, they are truncated. Finally, pixel values and labels are returned in dictionary form.
Before generating the validation set, we need to initialize TrOCRProcessor so it can be passed into the dataset class.
processor = TrOCRProcessor.from_pretrained(ModelConfig.MODEL_NAME)
train_dataset = CustomOCRDataset(
root_dir=os.path.join(DatasetConfig.DATA_ROOT, 'scut_train/'),
df=train_df,
processor=processor
)
valid_dataset = CustomOCRDataset(
root_dir=os.path.join(DatasetConfig.DATA_ROOT, 'scut_test/'),
df=test_df,
processor=processor
)
The code above includes the dataset preparation operations.
Preparing the TrOCR Small Printed Text Model
The VisionEncoderDecoderModel class provides access to all TrOCR models. The from_pretrained() method accepts the repository name as a parameter and loads the pre-trained model.
model = VisionEncoderDecoderModel.from_pretrained(ModelConfig.MODEL_NAME)
model.to(device)
print(model)
# Total parameters and trainable parameters.
total_params = sum(p.numel() for p in model.parameters())
print(f"{total_params:,} total parameters.")
total_trainable_params = sum(
p.numel() for p in model.parameters() if p.requires_grad)
print(f"{total_trainable_params:,} training parameters.")
This model contains 61.5 million parameters, fine-tuning on all parameters.
A crucial part of model preparation is configuring the model parameters. The configuration is as follows:
# Set special tokens used for creating the decoder_input_ids from the labels.
model.config.decoder_start_token_id = processor.tokenizer.cls_token_id
model.config.pad_token_id = processor.tokenizer.pad_token_id
# Set Correct vocab size.
model.config.vocab_size = model.config.decoder.vocab_size
model.config.eos_token_id = processor.tokenizer.sep_token_id
model.config.max_length = 64
model.config.early_stopping = True
model.config.no_repeat_ngram_size = 3
model.config.length_penalty = 2.0
model.config.num_beams = 4
The pre-trained TrOCR model has its own configuration information, but to fine-tune it, some parameters need to be modified, including token IDs, vocabulary size, and end of sequence token.
Additionally, early stopping is set to True, ensuring that training stops after several epochs when the metric ceases to improve.
Optimizing Metrics
We use the AdamW optimizer, with a weight decay parameter of 0.0005.
optimizer = optim.AdamW(
model.parameters(), lr=TrainingConfig.LEARNING_RATE, weight_decay=0.0005
)
The metric used is CER (Character Error Rate).
cer_metric = evaluate.load('cer')
def compute_cer(pred):
labels_ids = pred.label_ids
pred_ids = pred.predictions
pred_str = processor.batch_decode(pred_ids, skip_special_tokens=True)
labels_ids[labels_ids == -100] = processor.tokenizer.pad_token_id
label_str = processor.batch_decode(labels_ids, skip_special_tokens=True)
cer = cer_metric.compute(predictions=pred_str, references=label_str)
return {"cer": cer}
CER is the number of characters the model failed to predict correctly; the lower the CER, the better the model.
Training and Validating TrOCR
Before training, we need to initialize the training parameters.
training_args = Seq2SeqTrainingArguments(
predict_with_generate=True,
evaluation_strategy='epoch',
per_device_train_batch_size=TrainingConfig.BATCH_SIZE,
per_device_eval_batch_size=TrainingConfig.BATCH_SIZE,
fp16=True,
output_dir='seq2seq_model_printed/',
logging_strategy='epoch',
save_strategy='epoch',
save_total_limit=5,
report_to='tensorboard',
num_train_epochs=TrainingConfig.EPOCHS
)
We used FP16 during training to use less GPU memory, allowing for a larger batch size, and used TensorBoard for logging reports.
Training parameters and other required parameters are sent to the training API.
# Initialize trainer.
trainer = Seq2SeqTrainer(
model=model,
tokenizer=processor.feature_extractor,
args=training_args,
compute_metrics=compute_cer,
train_dataset=train_dataset,
eval_dataset=valid_dataset,
data_collator=default_data_collator
)
Use the train() method to start the training process.
res = trainer.train()
Epoch Training Loss Validation Loss Cer
1 3.822000 2.677871 0.687739
2 2.497100 2.474666 0.690800
3 2.180700 2.336284 0.627641
.
.
.
33 0.146800 2.130022 0.504209
34 0.145800 2.167060 0.511095
35 0.138300 2.120335 0.494496
After training, the model’s CER is 49%. Given that we used the small TrOCR, this is a very good result.
Below is a graph of CER during the training process on TensorBoard:

The curve shows a general downward trend during training. Although longer training may yield better results, we will first test our existing model.
Running Inference with the Fine-Tuned TrOCR Model
With the trained model, we can run inference on the validation data.
The first step is to load the latest saved model.
processor = TrOCRProcessor.from_pretrained(ModelConfig.MODEL_NAME)
trained_model = VisionEncoderDecoderModel.from_pretrained('seq2seq_model_printed/checkpoint-'+str(res.global_step)).to(device)
Below are several helper functions, the first one reads an image.
def read_and_show(image_path):
"""
:param image_path: String, path to the input image.
Returns:
image: PIL Image.
"""
image = Image.open(image_path).convert('RGB')
return image
The following function performs forward propagation of the image through the model.
def ocr(image, processor, model):
"""
:param image: PIL Image.
:param processor: Huggingface OCR processor.
:param model: Huggingface OCR model.
Returns:
generated_text: the OCR'd text string.
"""
# We can directly perform OCR on cropped images.
pixel_values = processor(image, return_tensors='pt').pixel_values.to(device)
generated_ids = model.generate(pixel_values)
generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)[0]
return generated_text
The last function performs inference on all images in a loop.
def eval_new_data(
data_path=os.path.join(DatasetConfig.DATA_ROOT, 'scut_test', '*'),
num_samples=50
):
image_paths = glob.glob(data_path)
for i, image_path in tqdm(enumerate(image_paths), total=len(image_paths)):
if i == num_samples:
break
image = read_and_show(image_path)
text = ocr(image, processor, trained_model)
plt.figure(figsize=(7, 4))
plt.imshow(image)
plt.title(text)
plt.axis('off')
plt.show()
eval_new_data(
data_path=os.path.join(DatasetConfig.DATA_ROOT, 'scut_test', '*'),
num_samples=100
)
We ran inference on 100 samples.
The following two images were incorrectly recognized before training, one is a curved text, and the other is a vertical text:


After fine-tuning the model, the results can now be correctly recognized. In this example, despite the text being highly distorted, it can still be accurately recognized.



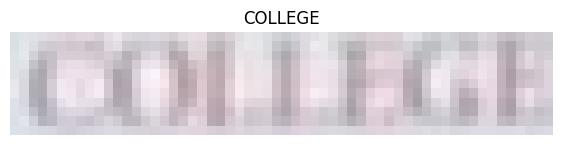
In the above three examples, the model can correctly predict even very blurry images.
Conclusion
In this article, we introduced the fine-tuning of the TrOCR model on a dataset of curved text recognition. We started with a discussion of the dataset, followed by dataset preparation and training of the TrOCR model. After training, we performed inference experiments and analyzed the results. Our results show that fine-tuning the TrOCR model can lead to better performance, even on blurry or curved text images.
OCR is not just about recognizing text in scenes; it also involves building applications using OCR, such as captcha recognizers or combining TrOCR recognizers with license plate detection pipelines.

Original article: https://learnopencv.com/fine-tuning-trocr-training-trocr-to-recognize-curved-text/
