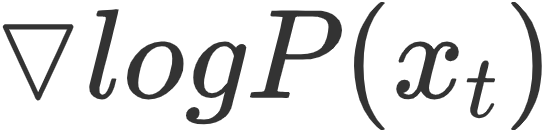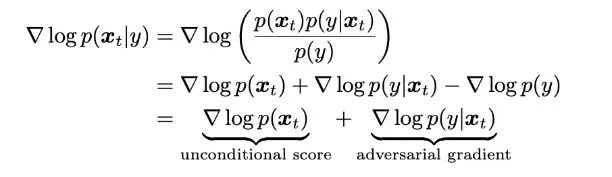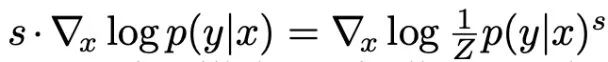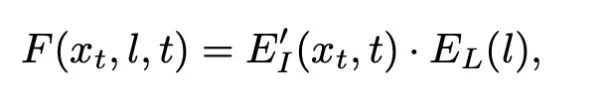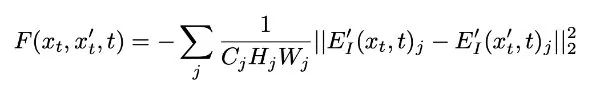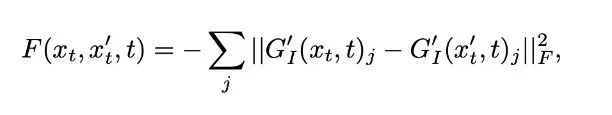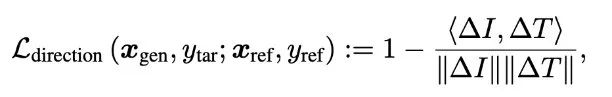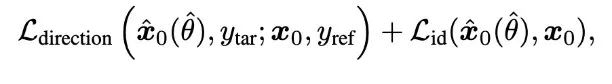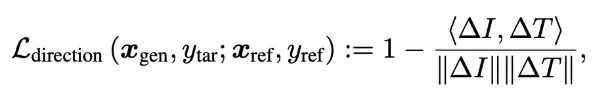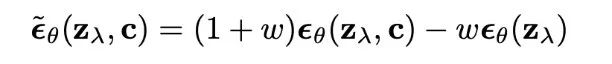MLNLP is a well-known machine learning and natural language processing community both domestically and internationally, covering NLP graduate students, university professors, and corporate researchers.The Vision of the Community is to promote communication and progress between academia, industry, and enthusiasts in natural language processing and machine learning, especially for beginners.Reprinted from | Li RumorAuthor | Zhong Sen
Hello, fellow readers, I am Zhong Sen.
The diffusion model has swept the academic world in the past two years since the introduction of DDPM in 2020, due to its various excellent characteristics (such as ease of training, excellent fitting to data distribution, and its structural system allowing for elegant and direct control of properties). Every day, new articles and methods are proposed, but due to the rapid development of the field, these articles often build upon different stages of diffusion model results, rendering them outdated or only of reference significance within just a few months of publication.
If one lacks a general understanding of the development trajectory of the entire diffusion field, it is often difficult to assess the transferability or reproducibility of a given paper’s approach to the currently used text-to-image models. In this article, I will briefly outline the development of controlled image generation methods using diffusion models over the past two years in chronological order and according to the evolution of technical systems, laying a solid foundation for better future work.
(Warning: I will interpret 14 papers next)
Specifically, the article is divided into three main parts:
The first part is image editing during the DDPM era. As no guided generation techniques had emerged yet, the papers from this stage all belong to the paradigm of generating guided by input images.
The second part surveys the multimodal guided generation techniques based on the CLIP model after the emergence of explicit classifier-guided generation techniques.
The third part investigates image editing techniques based on a series of models such as Stable-Diffusion/Imagen in the recent months (November 2022).
P.S. This article mainly provides a brief introduction and intuitive understanding of different controlled generation methods and may not involve much formula derivation or specific implementation details, only describing from a macro perspective. Interested readers can refer to some notes linked at the end for specific mathematical derivations, and details can refer to the original texts.
Most of the popular applications we see today, the controlled generation apps, or prototypes of startup products can be found in the following papers. I have derived a lot of insights from different papers while conducting related controlled experiments, but this note will not delve into that. If anyone is interested in discussing technical details or collaborating on research, please feel free to contact me via the contact information at the end of the article or search for the user Zhong Sen on Zhihu.
1
“A Minimal Review of Diffusion Models”
Below is a minimal review of the DDPM diffusion model; specific derivations can be found in notes [1].
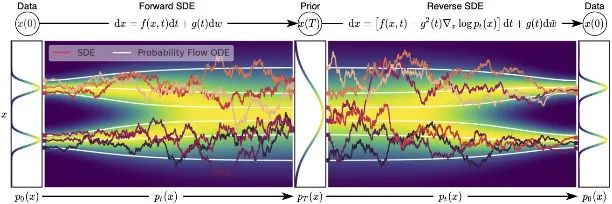
The name of the diffusion model comes from its construction of a discrete step Markov chain for the input X_0, continuously adding random noise until it becomes indistinguishable pure noise X_T. This forward process corresponds to the diffusion process in molecular thermodynamics. The model learns how to gradually remove noise from the noise distribution to restore the image to its original data distribution. The following image intuitively demonstrates this forward noise addition process.For this forward process, Dr. Song Yang proved in his paper that won the 2021 ICLR Outstanding Paper Award that the discrete noise addition in DDPM is merely a discretization of the continuous-time random process. Both the forward diffusion process and the backward denoising process can be represented by corresponding stochastic differential equations and ordinary differential equations. Moreover, the optimization objective of DDPM (predicting the noise added at each step) can actually be understood as learning the optimal gradient direction of the current input towards the target data distribution. This is actually quite intuitive: the noise added to the input effectively moves the input away from its original data distribution, and learning the optimal gradient direction in the data space is equivalent to walking in the direction of noise removal.On the other hand, Dr. Song Jiaming, who is in the same group as Dr. Song Yang, initiated the acceleration of DDPM sampling in his work DDIM. Prior to this, when we added noise to the same image using DDPM and then denoised it, we could not obtain the same image (unless the random seed was fixed). However, in DDIM, Dr. Song proved that we can obtain deterministic sampling results not only by using deterministic ordinary differential equations during backward denoising but also by constructing the inverse process of the backward ordinary differential equation during forward diffusion to obtain the final noise result of the forward process (this statement essentially says that if we have a deterministic path, then the forward and backward processes are just traversing forwards and backwards). This conclusion makes diffusion generation highly controllable, eliminating concerns about obtaining completely different images from the forward and backward processes, thus enabling a series of controls. This work will frequently appear in the series of papers we will discuss next.The bold text in the above two paragraphs is foundational for understanding the remaining papers in this narrative. Each paper I will introduce next is either directly or indirectly derived from these two insights. Interested readers can refer to notes [1][2]. However, understanding the mathematical derivations behind the controlled image generation methods discussed in this article is not necessary.
2
“Image Editing Based on Iterative Denoising Process”
IVLR: Conditioning Method for Denoising Diffusion Probabilistic Models
This paper is directly based on DDPM to develop controlled image generation. Its main focus is the pain point that the high randomness of DDPM makes it difficult to generate images with the desired semantic information. The core idea is very simple yet ingenious: our forward and backward processes are of equal length. During the forward process, the information of the original data gradually diminishes (high-frequency information is lost first, followed by low-frequency information), while during the backward process, information is gradually filled in from pure noise (low-frequency information is filled in first, followed by high-frequency information). If we record the noise images at each step of the forward process and mix them with the noise images in the backward process, we can influence the generation results of the backward process (considering the extreme case of completely replacing the noise image in the backward process, we can easily return to the original image). By controlling the amount of forward information injected during mixing or the number of time steps during backward information injection, we can control the degree of similarity between the generated image and the original image. Specifically, the algorithm is as follows: where Φ_N is a low-pass filter plus a series of dimensionality reduction and restoration processes to maintain the image dimensions.It is evident that we can control the retention ratio of information by adjusting the dimensionality reduction and restoration multiples. We can also adjust the strength of control by varying the number of time steps of noise added during the backward process. As seen in the two images from the original paper, as the compression ratio increases, the loss of detail information leads to a greater semantic difference between the final generated result and the original image. A similar trend can be observed in the number of termination steps applied during backward denoising. The earlier the termination, the greater the semantic difference.To summarize the strengths and weaknesses of this paper: it requires no additional training, has few hyperparameters to control, and is intuitive and easy to understand. However, its application scenarios are quite limited; it can only perform global modifications and cannot adjust locally, and it can only retain the original image’s spatial layout, without the capability to change pose angles or other variations, nor can it finely control the properties of the generated images.
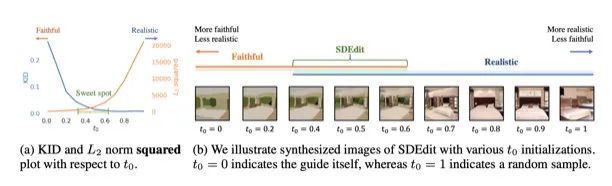
SDEdit: Guided Image Synthesis and Editing with Stochastic Differential Equations
This paper is a contemporaneous work with the previous IVLR, released just four days earlier, involving the whole group of Dr. Song Yang and Dr. Song Jiaming. Its core idea is also very elegant and intuitive: as mentioned above, the forward diffusion process is essentially a process where the semantic information of the image is continuously masked by noise, starting from high-frequency information to low-frequency information. In IVLR, low-pass filtering and down-sampling were used to extract low-frequency information to influence the backward denoising process. So, could we directly skip this step and let the forward process not add noise to pure noise but rather to an intermediate process, retaining some low-frequency information? The following image intuitively reflects this process, where t0 is the proportion of forward noise addition. By controlling the amount of information retained, we similarly control the degree of similarity between the generated image and the original image.The core ideas of these two works are very close, although the discussion methods and experimental analyses are slightly different.
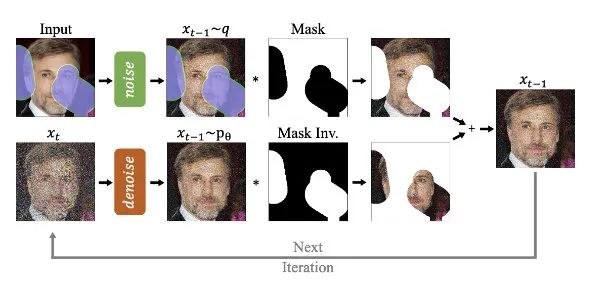
RePaint: Inpainting using Denoising Diffusion Probabilistic Models
This work is slightly later than the above two, with a core idea that is also very close, but it adds a mask operation to address the limitation of only being able to perform global modifications, transforming the task into an image completion task, making local modifications possible.Specifically, the authors’ approach still records the noise images at each step of the forward diffusion. During the backward denoising, we extract the areas that are not masked from the forward records, while the masked areas are filled with noise, merging them into a complete image, after which we start iterative denoising. At each step, we update the unmasked region with the forward record part, while the masked region is updated with the backward denoising result. The method is illustrated in the following image.However, this simple approach has a significant drawback: all information in the masked area is essentially discarded, and the regenerated results are often locally semantically coherent but do not consider global semantics. For example, in the following case, comparing the original image on the far left with the result generated by our naive approach, we can see that although the regenerated result in the masked part is close to the surrounding material and color, the global semantics of this image are clearly inconsistent.Therefore, the authors provide a very insightful insight: during the backward denoising, the combined image we consider includes the static output of the original image’s forward diffusion. Even if we continuously attempt to generate semantically consistent content during the backward denoising, the unmasked areas in the image will be replaced in the next step by the forward diffusion output that does not consider the backward generation process, leading to semantic inconsistency. Furthermore, as the denoising process deepens, our variance also decreases, making correcting the semantic inconsistency more difficult. In other words, the model requires more steps to correct the semantic inconsistency. The authors’ specific approach combines the above two insights: during each denoising step, we re-add noise to the denoised combined result x_{t-1] and then repeat the same backward denoising steps. By repeating this process n times, we obtain the semantically consistent output result shown in the above image. This approach addresses both the issue of the unmasked area not considering the backward generation result and the need for more steps for generation.This paper’s standout feature may be the brilliant insights introduced above (the algorithm is integrated into Huggingface’s diffusers library). However, it is still limited by its framework, which is based on the unconditional generation of the DDPM model (i.e., generating without conditioning on text, images, or categories), and its control over masked areas remains very limited, relying on randomness for regeneration. Next, I will introduce image generation based on explicit classifier guidance.
3
“Image Guided Generation Based on Explicit Classifiers”
In the minimal review of diffusion models above, I mentioned that the optimization objective of the diffusion model is essentially to fit the optimal gradient direction towards the target data distribution in the data space.
Therefore, naturally, if we want to perform guided generation, we can use Bayes’ theorem to decompose the gradient based on conditional generation into a gradient based on explicit classifiers and a regular unconditional generation gradient. In other words, we can still continue to train an unconditional generation model using the previous DDPM approach, and now we just need to train an additional classifier based on noise input.In fact, the idea of explicit classifiers was proposed earlier in Dr. Song Yang’s paper on Diffusion SDE, but it only occupied a small portion at the end. Currently, the main reference for discussing classifier image-guided generation is the following paper.
Diffusion Models Beat GANs on Image Synthesis
This paper has several important contributions, including exploration of the UNet architecture, higher generation quality, explicit classifiers in DDPM and DDIM, and the trade-offs between conditional generation quality and diversity. Due to space limitations, this note will only discuss the guided generation part.Specifically, the paper uses the down-sampling part of the first half of the UNet with an added Attn Pooling structure to serve as the classifier. The training data consists of the noisy results from DDPM during training along with some augmentation strategies. When using gradient guidance, the authors found that simply increasing the gradient guidance by a ratio of 1:1 does not yield good results. Therefore, an intuitive idea is to increase the strength of the guiding gradient, making its categorical nature more apparent. As shown in the figure below, using a gradient guidance ratio of one when generating a Welsh Corgi yields poor results, with minimal categorical influence. However, when the ratio is increased to ten, the effect becomes direct.Of course, as the strength of the guidance increases, diversity will also be affected. Simply put, observe the following equation. Z is a constant introduced by taking the logarithm of the gradient, which can be normalized. Therefore, effectively, increasing the guidance strength approximates a more concentrated distribution (closer to the mode). This naturally leads to better generation quality, but at the cost of losing diversity in generation.
The advantages of the image-guided generation method proposed in this paper lie in presenting a trade-off between generation quality and diversity, achieving superior results compared to GANs at the time. However, the drawbacks are also evident, as the classification judgments on noisy images cannot directly reuse common classification models, requiring an additional new model to be trained. Moreover, generating based on categories limits its application scenarios. Next, we will look at how large-scale text-image alignment pre-trained models based on CLIP can greatly expand its application scenarios. (For an explanation of the CLIP model, please refer to the interpretation of CLIP in Appendix [6])
4
“Multimodal Image Guided Generation Based on CLIP Model”
More Control for Free! Image Synthesis with Semantic Diffusion Guidance
As mentioned earlier, explicit classifier guidance allows for the generation of images of specified categories. The major contribution of the Semantic Diffusion Guidance (SDG) paper is that it expands the definition of P(y|x). In fact, we can entirely extend the definition of classification guidance to text, images, or multimodal guidance. Specifically, we can rewrite the classifier as an equation.With the above definition, we can now perform some loss calculations using the representations aligned between text and images in the CLIP model. Specifically, to use a text to guide image generation, we can calculate the distance between the current image representation and the text representation at each step, using the gradient of the equation to calculate the direction to reduce this distance. The simplest method is to use cosine distance:Where E’_I represents the image encoder, and E_L represents the text encoder.With the image, we can similarly apply cosine distance, but using cosine distance alone does not consider spatial and style information. Here, the authors used more specific losses: one is the L2 norm of corresponding feature maps considering spatial layout, and the other is the Gram-Matrix of corresponding feature maps considering style information (for the relationship between Gram-Matrix and style guidance, please refer to the paper Demystifying Neural Style Transfer).It is noteworthy that the image encoders mentioned above are encoders for noise input xt, so the authors retrained the image encoder in CLIP. Architecturally, they changed the bias and scaling in BatchNorm to depend on the time step t. However, for the loss of encoder training, the authors did not use the L2 norm or MSE to align the outputs of noisy images and clean images but instead used CLIP’s contrastive cross-entropy loss for the matching task. I believe this is a more realistic loss setting, as expecting the convolution in noisy images to achieve the same encoding effect over long time steps with greatly varying noise variance is unrealistic.The above image compares some text-image guided effects at the time. We can see that for image guidance, IVLR can only fix the overall image layout. In contrast, SDG can generate more diverse poses while preserving the corresponding poses. For text-guided generation, the images generated are also more diverse.To summarize the strengths and weaknesses, SDG was undoubtedly impressive at the time. However, just ten days later, OpenAI released GLIDE, which utilized the implicit classifier-guided image generation mentioned below. Therefore, the technology behind this paper was thoroughly swept into the dust of history. This also illustrates how terrifying the progress in this field can be. Nevertheless, the insights and guidance generation methods in this paper are still worth learning from, and the biggest drawback of this technical solution remains the burden of additional model training required based on the classifier.
Blended Diffusion for Text-driven Editing of Natural Images
This paper shares a similar thought process with the aforementioned one. It also performs additional gradient guidance during DDPM generation, but it adds a MASK operation, allowing text guidance to change only specific regions.Specifically, the authors explored two approaches. The first is to use CLIP for text guidance in the masked area while using MSE and LPIPS losses to ensure the unmasked area remains unchanged (MSE is the pixel-to-pixel difference, while LPIPS is the perceptual loss between blocks). However, this method of ensuring background consistency often requires weighting the loss in the unmasked area to nearly ten thousand times to maintain a roughly unchanged background. Therefore, the authors simply kept the background unchanged, using only the CLIP guidance loss (cosine distance) to calculate the guiding gradient for the masked area at each step.The specific algorithm is illustrated in the above image. Notably, the authors did not train a CLIP based on noise input. Instead, at each step, they used the noise predicted from xt to estimate the clean image x0. Since the CLIP loss is computed using the estimated X0, its effectiveness may have declined, leading to less noticeable semantic update effects. Therefore, the authors employed an augmentation approach to compute the CLIP loss over the augmented set to reduce variance and enhance guidance effects.I believe the most interesting aspect of this paper lies not in its use of MASK but in its approach of not training a new CLIP and using the average gradient of augmented data for guidance.
DiffusionCLIP: Text-Guided Diffusion Models for Robust Image Manipulation
The above two papers’ methods are based on CLIP loss to guide the diffusion model generation, which does not require any fine-tuning or modification of the diffusion model. However, the interesting point of the Diffusion-CLIP paper is that instead of applying our gradients to the updates of the intermediate noisy outputs, we might try directly updating the underlying diffusion model to align its generation with CLIP’s expectations. The definition of the loss function is as follows, divided into two components.The second term id_loss is easy to understand; it primarily ensures that the clean image predicted from the noisy input xt should match the actual clean image. It is an L1 norm loss. However, the first term L-direction is more intriguing. As mentioned earlier, the cosine loss function has some drawbacks, such as low diversity in generated outputs and ineffective guidance (similar to adversarial attacks). The newly defined loss function, where delta_T is the encoding difference between the original and target text vectors, and delta_I is the encoding difference between the original and predicted image vectors, calculates the cosine distance between these two differences as our new loss function.This loss was proposed by the authors of CLIP, who are also the authors of the GPT series, Alec Radford. This loss uses the directional differences between the target texts to guide the directional differences between the encoded images, enhancing the diversity of the generated results. Additionally, it alleviates the issues of mode collapse and poor guidance performance mentioned earlier.Moreover, as mentioned at the beginning of this article, DDIM allows us to accurately restore the original image after diffusion and denoising. Diffusion-CLIP also employs similar techniques. However, to summarize, this paper requires retraining a new diffusion model for each new property guide (i.e., new target prompt y_tar), making its technical route relatively less advantageous than other controlled image generation methods.
Diffusion Models Already Have a Semantic Latent Space
This paper is a submission to the 2023 ICLR conference and is still under review. The title is very eye-catching. The core idea of the entire text continues from Diffusion-CLIP, still using CLIP’s loss to fine-tune the diffusion model. However, the authors believe that it is unnecessary to fine-tune the entire diffusion model; rather, only the middle layer of the UNet architecture within the diffusion model needs to be fine-tuned. The authors refer to this layer as h-space, which is the semantic latent space mentioned in the title. Additionally, the paper’s highlights include breaking down the overall diffusion guidance process during DDIM sampling into three parts. The first part is guided, the second part is unconditioned with no variance in DDIM sampling, and the third part is using DDPM sampling. We know that the generation quality of DDIM is actually lower than that of DDPM (or that while SDE sampling is slower, it generates better results than ODE; this phenomenon was only recently resolved. Interested readers can compare my understanding with the explanation in Appendix [2] and discuss it with me). Thus, this paper addresses this phenomenon by segmenting the guidance into three parts corresponding to several issues: first, the overall semantic layout of the image is decided early during the denoising process, so guidance can be applied only in the early stages. Secondly, we can balance sampling speed by switching back to DDPM only when generating the final high-frequency information. Lastly, if DDPM generation takes too long due to its variance or the randomness of SDE, the length of the third stage may alter the semantic information of the image. Therefore, the authors empirically set this stage to one-quarter of the global denoising length.This paper presents stunning image generation effects. However, it still has several defects. First, the most important theoretical theorem 1 is derived based on an erroneous premise, leading to incorrect derivations. Second, there is insufficient explanation of why h-space is effective and why it is the middle layer of UNet. Third, the paper’s approach still requires retraining a new model for each property, even if this model has good transferability and lower training costs, it remains unacceptable.This note is generally written in chronological order of time and technical system evolution. All the papers mentioned above are directly based on unconditional semantic guidance generation. With the emergence of newer, more powerful, and convenient models like Stable-Diffusion and Imagen, the above works may only serve as references.
5
“Large Models for Text-to-Image Generation Based on Implicit Classifiers”
Classifier-Free Diffusion Guidance
As mentioned earlier, explicit classifiers require additional training of a classifier and often lead to decreased diversity. The major contribution of this paper is a profound insight: we can decompose the gradient guidance of explicit classifiers using Bayes into two parts, one being the gradient estimation model for unconditional generation (e.g., conventional DDPM), and the other being the gradient estimation model for conditional generation (conditional generation can be modeled as UNet + cross-attention). We can even use the same model to represent both, with the difference being whether the condition vector is set to zero during generation (specific mathematical derivations can be found in Appendix [4]).On one hand, this greatly reduces the training cost of conditional generation (no need to train an additional classifier, just perform random dropout during training to train both objectives simultaneously). On the other hand, this conditional generation does not occur in a manner similar to adversarial attacks. Moreover, if we carefully observe the sampling formula above, it is actually the difference between two gradients forming it. Readers who have used stable-diffusion-webui may have noticed that one feature is the negative prompt, which allows users to specify unwanted prompts, preventing their inclusion in the generation. This is actually implemented using the classifier-free guidance formula above, converting unconditional generation into conditional generation with prompts that you want to avoid.Classifier-free guidance can be considered one of the direct foundational works for GLIDE/Stable-Diffusion/Imagen. Previously, to achieve multimodal or text-to-image guided generation, people typically used the CLIP model to calculate a loss difference based on the distance between the generated image and text, using this difference to guide multimodal generation. However, with the classifier-free paper, both text-to-image and image-to-image generation can be achieved using one model, guided by cross-attention, leading to better and more precise generation effects. This also renders much of the previous work largely obsolete.Due to space limitations, I will not provide a detailed analysis of the technologies behind Stable-Diffusion/Imagen/Glide in this section; interested readers can refer to Appendix [6].
6
“Controlling Generation in the Guiding Process of Implicit Classifiers”
After reviewing the numerous papers above, we have finally caught up with the latest text-to-image era (November 2022). Below, I will introduce some directly based on this era’s text-to-image models, such as Stable-Diffusion/Imagen, that guide generation. I will roughly categorize them into two types: those that require fine-tuning and those that do not. Each has its merits. First, I will introduce some guiding generation work based on the Imagen model from Google, which all require fine-tuning and share very similar core ideas. Note that many of these approaches can also be transferred to SD.In the previous papers, we introduced several guiding generation methods. The first is based on the iterative denoising characteristics of diffusion models; we continue generating on the low-frequency details of the model. Although this method retains most geometric features, it also cannot control geometric features. For example, if the original image used for iterative denoising is a standing portrait, we cannot change its pose through blurring and regeneration. We can adjust the noise strength to randomly transform it into a new image, but even with prompt guidance, we cannot retain the original target’s features (such as the appearance of the portrait).From a traditional perspective, achieving control over target objects may involve semantic segmentation, then adjusting various properties of the segmented objects based on conditional guidance. However, starting from this paper, the following four papers share a core idea: by fine-tuning the generation model, we can bind the visual information of the corresponding object to a specific character (just as the visual appearance of a tree is bound to the character tree), and then use it as a normal language character to add control information. For instance, once a tree with a specific image is represented by the character x, the user can specify “burning x” or “glowing x” to modify the specified image of the tree.
Imagic: Text-Based Real Image Editing with Diffusion Models
Specifically, Imagic breaks down the concept binding into three steps for the input image x and the target description text_target:1: First, we freeze the entire model and fine-tune the text representation of text_target to be close to the image representation using the generation target during model training.2: Next, we unlock the weight updates of the entire model, still using the training generation target, but this time fine-tuning the entire model. The model’s input is the image x and the fine-tuned text representation. This step is necessary because even if we make the target text representation close to the original image’s representation, we cannot guarantee that the input will generate our original image using the fine-tuned target text representation, so we need to train these two concepts together again to ensure we can generate our original image using the fine-tuned target text representation.3: Since we have now bound the original image and the fine-tuned new text representation, we can now apply influence on the original image by interpolating between the original target text representation and the fine-tuned text representation.These three steps are somewhat convoluted, but simply put, we can approximate the fine-tuned target text representation as the native text representation of the original image, making the final step of applying the target representation’s influence on the native representation very natural.Note that in the above image, SDEdit cannot change the spatial layout, while Imagic can alter the dog’s pose and actions without affecting the background.Of course, this article also has some details to note, such as ensuring that the fine-tuning in the first step does not go on for too long, as this would cause the new text representation to drift too far from the original target text representation, which would invalidate the linear interpolation.
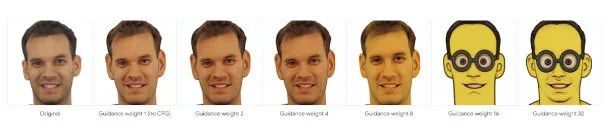
UniTune: Text-Driven Image Editing by Fine Tuning an Image Generation Model on a Single Image
Compared to Imagic’s approach, the author of this paper adopts a more engineering-oriented tuning method that lacks generalizability. Specifically, it still involves concept binding. The author divides it into two steps:1: The first step is to select a low-frequency word or simply a randomly combined character like “beikkpic”, minimizing the influence of its original meaning. Next, fine-tune the entire model with the combination of this low-frequency word and the original image.2: In the second step, the fine-tuned model generates using “[low-frequency word]+ target guiding description” such as “beikkpic a monster”.The author found that simply using a simple text-to-image strategy led to ineffective target guidance. Therefore, the author employed some techniques: using the previously mentioned classifier-free guidance along with a certain weight to amplify the influence of the target guidance. We can see that as the weight increases, the effect of influence gradually strengthens. Additionally, to ensure that the generated result is as close to the original image as possible, the author also used a method similar to the previously mentioned SDEdit approach, reconstructing from the intermediate noisy results of the original image rather than starting from pure noise to enhance consistency. The most engineering aspect is that the original author also experimented with pixel interpolation between the generated image and the original image to improve the quality of the generated images.The drawbacks of this paper are evident from two aspects: on one hand, while the approach allows for additional property control through concept binding, it also means that all results retain the geometric composition of the original image, unable to achieve pose changes like Imagic. The second drawback is that the paper’s approach is too empirical, requiring constant tuning, and its generalizability is questionable.
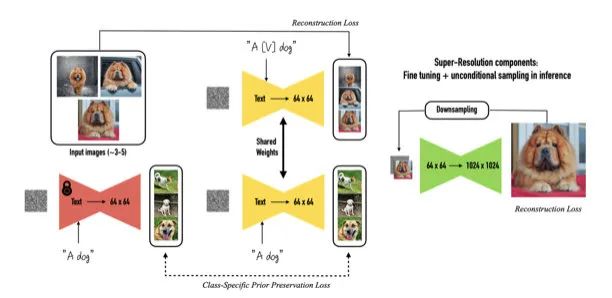
DreamBooth: Fine Tuning Text-to-Image Diffusion Models for Subject-Driven Generation
Compared to the previous two papers, this paper excels in both elegance and popularity.Specifically, the authors propose using a combination of rare words and category words like “beikkpic dog” to fine-tune a set of photos and bind them to this text. However, merely using a small number of photos to fine-tune a model with a large number of parameters obviously leads to severe overfitting problems. It also brings about a common issue in language models—catastrophic forgetting. The manifestations of these two problems are that the binding word’s form becomes difficult to change, just like in the previous UniTune paper. The second problem is that the generated diversity and variability in the category words will quickly diminish. To address this issue, the authors propose a loss function called the preservation loss of the prior of its own category.The design of this function is that when the user provides a specified category and a set of images of that category (such as multiple photos of their pet dog), the model uses both the training with the “special word + category” and the training with the “category” and the generated images of that category. This approach allows the model to learn the relationship between specific photos and the special words while continuously reinforcing the category information to counteract the impact of user photo information. The authors specifically trained these two losses in a 1:1 ratio for about 200 epochs.We can see that the generated results are quite good, maintaining both diversity and controllability. Although it is still not a real-time algorithm, the training cost is relatively low, taking about 10-15 minutes of GPU single-card time. There are many publicly trained DreamBooth-StableDiffusion models available on Huggingface, and all the code is open-sourced.Finally, I will introduce two works that do not require fine-tuning. They can also be transferred to Imagen/SD and share a characteristic of not needing an explicit mask, using only text to generate masks to find the corresponding modification locations based on the text, supplemented by text-controlled generation methods.
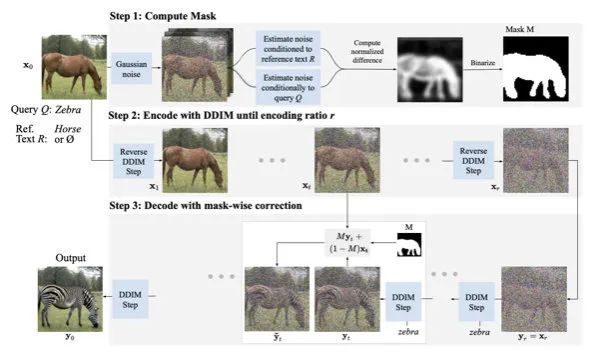
DiffEdit: Diffusion-based Semantic Image Editing with Mask Guidance
The reason I understand why DiffEdit is named this is that it can be split into two parts: Diff + Edit. Here, Diff not only refers to diffusion but also to Difference. In fact, the way this paper generates masks relies on the differences from two diffusions.The above flowchart clearly reveals the entire algorithm process. First, we add random noise to the original image until it reaches a level close to pure noise (around 50-60%, this ratio is derived from experiments). Then, we use the pixel difference between the results of denoising the original image’s description text and the target text to obtain a mask (for example, the horse-shaped mask in the above image). After that, we use the deterministic noise addition method of DDIM, adding noise to the image to a certain degree, and then applying the previously mentioned methods to process the masked and background areas separately.Of course, in the generation process, to obtain stable masks, methods similar to the data augmentation mentioned earlier are essential, such as averaging the results of multiple calculations after removing extreme values, then mapping the results to the [0, 1] interval for binarization. Meanwhile, the forward noise addition ratio in the second step actually controls how long we can influence the generation steps. For instance, if the deterministic noise addition reaches 100%, the time taken for generation will be longer, but the deviation in the generated results will also increase. The trend can be clearly seen in the image below.This paper, while requiring more forward and denoising processes, has the significant advantage of not needing additional training. Furthermore, although most text-image tools on the market are equipped with mask generation brush tools that can easily obtain image masks, text control remains advantageous in some complex scenarios, such as changing the flowers of an entire tree compared to manual masking.
Prompt-to-Prompt Image Editing with Cross-Attention Control
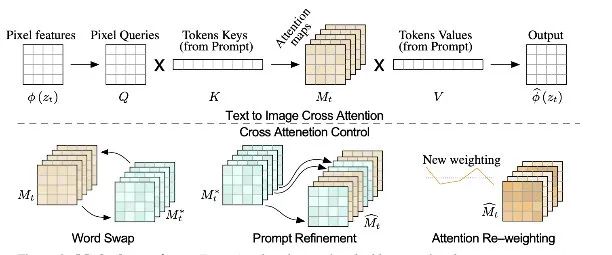
This paper is also a submission to the 2023 ICLR conference. Unlike the previous paper, which has many issues, this paper received consistently high scores of 8-8-8 on OpenReview. This paper takes a different approach to obtain masks for fine-tuning control. The insight of this paper stems from an important consideration: how does text in multimodal text-to-image affect the generation process? As mentioned earlier, implicit classifier-based text-image models achieve this through training a model that can perform both unconditional and conditional generation gradient estimation. The interaction method for this conditional generation in Imagen and Stable-Diffusion is achieved through cross-attention for information fusion. Hence, it is evident that our focus should also be on cross-attention. The authors’ insight is that there exists a spatial correspondence between the input text and pixels. By adjusting the attention and mapping between pixels, we can implement precise guidance for different regions of the image. This insight is easy to understand; we know that the essence of the attention mechanism is weighting, which is a process of obtaining a set of weights by calculating the distances between vectors (in this scenario, the embedding vectors of multimodal inputs). Specifically, the scaled-attention computation formula used in transformers is as follows:Where M is our two-dimensional weight matrix. M_ij represents the weight of the j-th token on the i-th pixel. The authors refer to this matrix as the cross-attention map. Observing the above formula, it can be seen that the image’s spatial layout, geometric shapes, and other information heavily rely on this attention mapping matrix. Moreover, there exists an obvious correspondence between the spatial information composed of text and pixels (as shown in the above image, the word bear highly overlaps with the outline of a bear).With this insight, guiding image generation becomes very intuitive. The authors categorize it into three main scenarios: word replacement (for example, replacing bear with cat by swapping the bear’s map with the cat’s map), word addition (adding new word maps to the existing maps), and attention re-weighting (to amplify or reduce a specific word’s guiding effect on the original image, such as lowering the effect of snow while increasing the degree of flowers).Some noteworthy aspects include that for objects with vastly different sizes, such as a bear and a cat, the authors relax the constraints on the map by controlling the number of steps of injection and the timing of injecting different words. For local modifications, to ensure absolute background consistency, the authors also derive a mask by calculating the difference between two different cross-attention maps and guide separately. The method is very similar to the DiffEdit mentioned earlier.
7
“Conclusion”
This note has outlined the core points of more than a dozen recent papers at once. Although it is extremely cumbersome, I have found that many problems encountered in my practice of semantic-guided generation with text-to-image models have already been faced by predecessors. Their thoughts and insights have provided me with much inspiration. I believe readers will also find that many of the papers among these have absorbed ideas and practices from earlier works. However, reading more papers ultimately requires hands-on practice. The open-source community is very active and open; I joined the open-source army earlier and have been practicing semantic guidance through some projects. I welcome more exchanges.References
How DDIM Accelerates Sampling and Performs Deterministic Sampling: https://zhuanlan.zhihu.com/p/578948889
The Relationship Between Diffusion Models and Energy Models, Stochastic Differential Equations, and Ordinary Differential Equations: https://zhuanlan.zhihu.com/p/576779879
Explicit and Implicit Classifier Guidance in Diffusion Models: https://zhuanlan.zhihu.com/p/582880086
Applications of Diffusion Models in Text Generation: https://zhuanlan.zhihu.com/p/561233665
Detailed Analysis of Stable-Diffusion and Related Papers: https://zhuanlan.zhihu.com/p/572156692
Technical Community Invitation
△ Long press to add the assistant
Scan the QR code to add the assistant’s WeChat
Please note: Name – School/Company – Research Direction(e.g., Xiao Zhang – Harbin Institute of Technology – Dialogue Systems)to apply for joining the Natural Language Processing/Pytorch and other technical communities
About Us
MLNLP Community is a grassroots academic community jointly built by scholars in machine learning and natural language processing both domestically and internationally. It has developed into a well-known community in machine learning and natural language processing, aimed at promoting progress between academia, industry, and enthusiasts in machine learning and natural language processing.The community can provide an open communication platform for related practitioners in further education, employment, and research. Everyone is welcome to follow and join us.