Preface
Happy holidays, everyone.
During the New Year, I believe many of you have been inundated with the domestic AI large model DeepSeek. With the rapid development of artificial intelligence, DeepSeek has become a hot large language model (LLM). However, many students still view it as just a “chatbot” or mistakenly believe it to be “all-knowing.” Is DeepSeek really that magical? How should university students correctly understand and use it? If one wants to engage in LLM research, how should they get started?
Today, we will discuss these topics!
1. What Exactly Is DeepSeek?
DeepSeek is an AI model developed by Hangzhou DeepSeek AI Technology Research Co., Ltd. Its English name “DeepSeek” can be interpreted as “deep” (Deep) and “exploration” (Seek), symbolizing the exploration of unknown fields through deep learning technology. This AI assistant, based on the Transformer architecture, possesses core capabilities including natural language understanding and generation, multi-turn dialogue management, cross-domain knowledge integration, and code processing. Relying on large-scale pre-training and continuous learning mechanisms, it supports interactions in languages such as Chinese and English and can assist in information retrieval, research, and creative generation scenarios. The first open-source model of DeepSeek was released in November 2023, and the recently popular DeepSeek-v3 and DeepSeek-R1 are the latest large models from DeepSeek. Over the past year, DeepSeek has continuously released new products, as shown in the figure below:
✦
•
✦
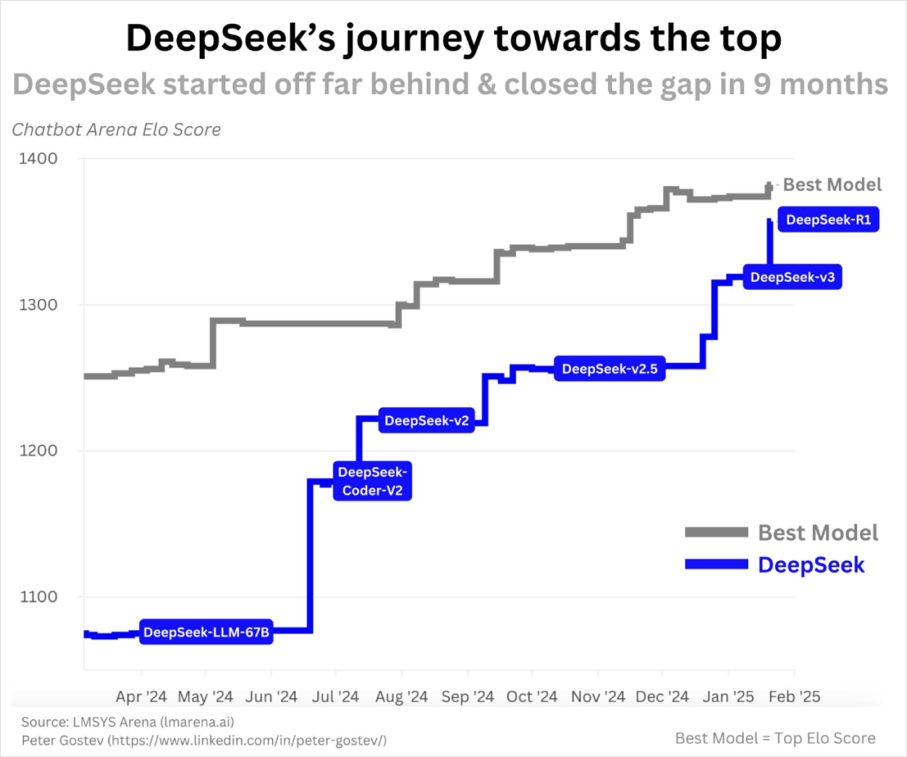
Figure 1 DeepSeek Model Progress
✦
✦
✦
Core Technologies of DeepSeek:
✅ Transformer Structure: A revolutionary model in deep learning that supports long text understanding and generation.
✅ Mixture of Experts (MoE): Adopts the principle of “specialization” by allowing several suitable experts to collaborate to complete specific tasks, resulting in faster inference speed.
✅ Autoregressive Language Modeling: Predicts the next word based on previous text to achieve coherent dialogue.
✅ Large-scale Training: Uses publicly available internet data for training, covering a wide range of knowledge domains.
✅ Reinforcement Learning from Human Feedback (RLHF): Combines human feedback to make the model’s responses more aligned with human expectations.
Although the DeepSeek model is still based on the Transformer architecture and does not represent a disruptive theoretical innovation, it has many innovations in the design of language models and their training methods.
✦
✦
✦
Main Innovations and Contributions of DeepSeek:
1. Multi-latent Attention — Typically, LLMs are based on the multi-head attention mechanism (MHA) of the Transformer architecture. The DeepSeek team developed a variant of the MHA mechanism called multi-head latent attention, significantly reducing computational and storage costs, lowering memory usage to 5%-13% of other large models, greatly enhancing model operational efficiency.
2. GRPO and Verifiable Rewards — Since the release of OpenAI’s o1, the AI community has been trying to replicate its effects. Due to OpenAI’s high level of secrecy about its workings, the community has had to explore various methods to achieve results similar to o1. Many researchers have attempted different methods to reach o1’s performance, but these methods have ultimately proven to be less promising than initially expected. On the other hand, DeepSeek demonstrated that a very simple reinforcement learning (RL) process can actually achieve results similar to o1. More importantly, they developed their version of the PPORL algorithm called GRPO, which is more efficient and performs better.
3. DualPipe — DeepSeek uses FP8 mixed precision to accelerate training and reduce GPU memory usage, employing the DualPipe algorithm (which overlaps forward and backward computations with communication phases to minimize idle computational resources) to enhance training efficiency and achieve extreme memory optimization. They developed a complete data processing workflow focused on minimizing data redundancy while preserving data diversity.
4. “Pure” Reinforcement Learning — DeepSeek is the first in the world to successfully replicate the capabilities of o1 through pure reinforcement learning technology. Prior to this, very few teams had successfully applied reinforcement learning to the training of large-scale language models. Notably, DeepSeek-R1 is not limited to rule-driven mathematical models or algorithms but has successfully generalized the strong reasoning capabilities brought by reinforcement learning to other fields, allowing users to experience its outstanding performance in tasks such as writing. The training process diagram of DeepSeek-R1 is shown below:
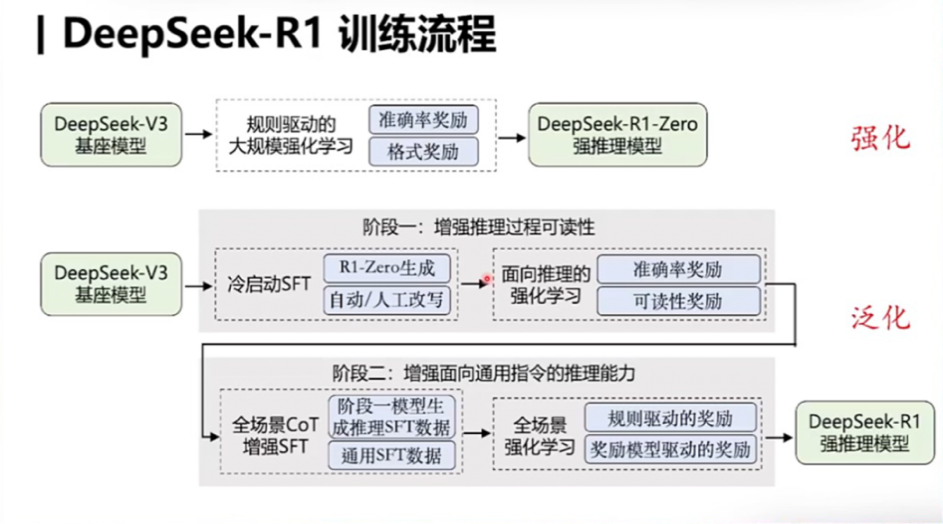
Figure 2 DeepSeek-R1 Training Process Diagram (Source: Tsinghua University – Liu Zhiyuan)
5. Model Distillation — The popularity of DeepSeek has once again pushed model distillation technology to the forefront of technical discussions. In simple terms, “model distillation” involves having a smaller model imitate the results of a larger model in answering questions to enhance its own capabilities. For example, when classifying an article, if the large model predicts that the article belongs to positive, negative, and neutral sentiment categories with probabilities of 85%, 10%, and 5% respectively, the small model carefully considers the results output by the large model, continuously adjusting its parameters in hopes of inheriting the large model’s capabilities to produce similar results.
6. Open Source! Open Source! Open Source! — Unlike OpenAI’s ChatGPT in the United States, DeepSeek selflessly shares its research and innovations with the AI community. The open sourcing of DeepSeek allows researchers worldwide to quickly build related capabilities. If ChatGPT has revealed the importance of large models to the world, then DeepSeek’s open-source model provides global researchers the opportunity to participate in the development of powerful reasoning capabilities. Now, everyone can benefit from these advancements and improve their AI model training.
2. How to Correctly Understand DeepSeek?
DeepSeek is Not Omniscient
DeepSeek is not all-powerful; it only provides answers based on probabilistic predictions. Therefore, its responses may be incorrect or even fabricate information (i.e., hallucination phenomenon).
DeepSeek is Not a Knowledge Base
DeepSeek’s information updates may lag and cannot directly access certain restricted data (such as paper databases, patent systems, etc.).
DeepSeek Also Has Bias
Since its training data comes from the internet, it may carry certain social biases; thus, critical thinking should be maintained when using it, and one should not blindly trust its conclusions.
Correct Mindset:
View DeepSeek as an auxiliary tool rather than the sole authoritative source of answers.
Maintain skepticism and validation of AI outputs, especially when it comes to academic, research, or important decisions.
DeepSeek excels at summarization and inspiration, but the ultimate learning outcomes still depend on one’s own thinking and practice.
3. How to Correctly Use DeepSeek?
Cognitive Warning Zones: 1️ Not a search engine → outputs may have “hallucinations”.
2️ Not a problem-solving tool → mathematical proofs still require manual verification.
3️ Not a programming assistant → generated code requires rigorous testing.
Correct Approach: Treat it as “smart scratch paper” to inspire ideas, as a “24-hour TA” to assist in understanding concepts, and as a “pair programming partner” to learn coding standards.
Learning Scenarios✏️:
Describe algorithm requirements in natural language → generate pseudo-code templates.
Input error messages → get debugging suggestions.
Upload paper abstracts → generate literature review frameworks.

1. Clarify Your Needs
Example: “Please explain the principles of the Transformer model in simple terms.”
Avoid: “Tell me what a Transformer is?” (Description is too vague)
2. Provide Clear Context
Example: “I am a sophomore in the computer science department and would like to learn PyTorch. Can you provide me with a 3-month study plan?”
Avoid: “How to learn PyTorch?” (DeepSeek cannot determine your foundation)
3. Learn to Optimize Prompts (Prompt Engineering)
Role Setting: “Assume you are a computer vision expert, please introduce CNN.”
Format Requirements: “List the comparison between DeepSeek and BERT in a table.”
Iterative Improvement: “Please answer in a more academic manner.”
4. Combine Other Tools to Enhance Effectiveness
Paper Retrieval: Google Scholar, Arxiv.
Code Debugging: GitHub Copilot, Hugging Face, Colab.
Data Analysis: Pandas, Matplotlib.
Video Tutorials: Bilibili.
Make Good Use of DeepSeek = Efficient Learning + Twice the Result with Half the Effort!
4. How to Get Started in Large Language Model Research?
If you are interested in large language models (LLMs) and wish to engage in related research, here is a recommended learning path:

Basic Stage (Suitable for Freshmen, Sophomores)
Linear Algebra, Probability Theory, Calculus.
Python Programming (Master NumPy, Pandas, Matplotlib).
Basic Machine Learning (Supervised Learning, Unsupervised Learning).

Advanced Stage (Suitable for Sophomores, Juniors)
Deep Learning (PyTorch, TensorFlow).
Transformer Models (BERT, GPT).
Natural Language Processing (NLP) Techniques (Tokenization, Attention Mechanism, etc.).
Recommended Learning Resources:
Courses: Coursera “Deep Learning Specialization”.
Books: “Deep Learning” (Ian Goodfellow), “Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow”.
Paper: “Attention Is All You Need” (Classic Transformer Paper).
Research Stage (Suitable for Seniors and Above)
Read Cutting-edge Papers (NeurIPS, ICLR, ACL, ICML).
Research Large Model Training and Optimization (Distributed Training, Mixed Precision Training, etc.).
Explore LLM Applications in Industry (e.g., Automated Code Generation, Intelligent Q&A).
Tip: Do More Projects + Write More Code + Read More Papers!
5. Limitations and Improvement Directions of Large Language Models
Despite the strong performance of DeepSeek and other large language models, the following issues still exist:
1. Huge Computational Resource Consumption
Training models with hundreds of billions of parameters requires hundreds of GPUs, which ordinary universities and individuals find difficult to afford.
2. Hallucination Problems in Generated Content
May fabricate non-existent facts, reducing information credibility.
3. Poor Interpretability
Currently, the reasoning process of LLMs remains a “black box,” making it difficult to track their decision-making processes.
4. Bias and Ethical Issues
Training data comes from a wide range of sources and may contain biases related to race, gender, etc., affecting fairness.
Future Improvement Directions:
-
More Efficient Model Architectures (e.g., Sparse Activation Models to Reduce Computational Costs).
-
Combine Knowledge Graphs (Enhance Factuality and Improve Answer Credibility).
-
Strengthen Research on Interpretability (Make Model Decisions More Transparent).
-
Develop Safer AI Ethical Mechanisms (Reduce Social Biases and Improve Safety).
6. Conclusion
DeepSeek is a powerful AI assistant, but it is not perfect and requires rational use (the user’s cognitive range determines the upper limit of DeepSeek’s capabilities).
Correctly Using DeepSeek can enhance learning efficiency and improve programming, writing, and research abilities.
If you want to engage in large model research, solidify your foundation + delve into Transformers + practice more projects!
Follow the trends in LLM development, understand its limitations, and explore more efficient and fair large model technologies.
In the process of AI development, American giants like OpenAI, Google, and Meta have also made significant efforts or taken on greater responsibilities. While we celebrate the success of DeepSeek, we must also acknowledge all efforts to advance AI development; every individual’s contribution is invaluable. In this era where large models are reshaping the world, students of computer science should not only adeptly use tools but also understand their essence.
Remember: AI will not replace humans, but those who use AI will replace those who do not!

Related References
https://arxiv.org/html/2412.14135v1
https://arxiv.org/pdf/2408.15664
DeepSeek-V3/DeepSeek_V3.pdf at main · deepseek-ai/DeepSeek-V3 · GitHub
https://developer.download.nvidia.cn/compute/cuda/docs/CUDA_Architecture_Overview.pdf
In-depth Analysis of DeepSeek-R1! — WeChat Official Account: AI Large Model Frontier
DeepSeek: Towards Universal Intelligence Shared by Society — Wenhui. Shangguan
✦
•
✦

【Author Introduction】
1. Personal Resume
Party Jiachen, graduating in 2024 from the University of Chinese Academy of Sciences, majoring in Computer Software and Theory, PhD. Member of the “Image Processing and Parallel Computing Research Center” (IPPC) team, mainly engaged in research in computer vision, image processing, and multimodal fields. In recent years, he has published 7 papers in SCI and CCF recommended journals and conferences, participated in multiple projects such as the Chinese Academy of Sciences STS program and the National Key R&D Program, and served as a reviewer for journals and conferences such as ICIP and CVIU. He has received honors such as the National Scholarship for Doctoral Students, University of Chinese Academy of Sciences Scholarship, Top 50 in Tencent Algorithm Competition, and Top 20 in Digital Sichuan Innovation Competition.
2. Main Research Directions
Computer Vision, Image Processing, Multimodal

Source: School of Computer Science and Software
Text and Images: Party Jiachen
Layout: Shi Wenwen
Editor: He Zhaoyu
Review: Wang Xin