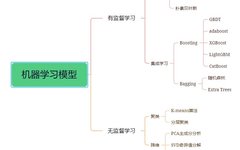
Machine learning can be divided into two main categories based on model types: supervised learning models and unsupervised learning models.
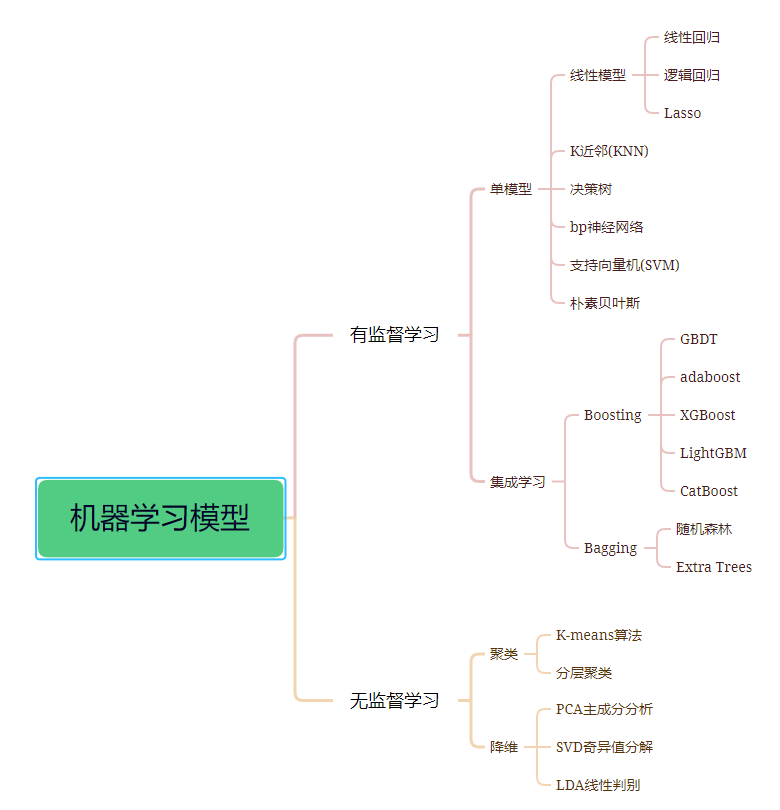
1. Supervised Learning
Supervised learning typically uses training data with expert-labeled tags to learn a function mapping from input variable X to output variable Y. Y = f(X), where the training data is usually in the form of (n×x, y), with n representing the size of the training sample, and x and y being the sample values of variables X and Y, respectively.
Supervised learning can be divided into two categories:
-
Classification problems: Predicting the category to which a sample belongs (discrete). For example, determining gender, health status, etc.
-
Regression problems: Predicting the corresponding real number output (continuous) of a sample. For example, predicting the average height of people in a certain area.
In addition, ensemble learning is also a type of supervised learning. It combines predictions from multiple relatively weak machine learning models to predict new samples.
1.1 Single Models
1.11 Linear Regression
Linear regression refers to regression models composed entirely of linear variables. In linear regression analysis, there is only one independent variable and one dependent variable, and their relationship can be approximated by a straight line; this is called univariate linear regression analysis. If the regression analysis includes two or more independent variables, and the relationship between the dependent variable and independent variables is linear, it is called multivariate linear regression analysis.
1.12 Logistic Regression
Used to study the relationship between X and Y when Y is categorical data. If Y has two classes, such as 0 and 1 (for example, 1 for willing and 0 for not willing, 1 for purchase and 0 for not purchase), this is called binary logistic regression; if Y has more than three classes, it is called multiclass logistic regression.
The independent variables do not necessarily need to be categorical; they can also be quantitative variables. If X is categorical data, dummy variable encoding is required.
1.13 Lasso
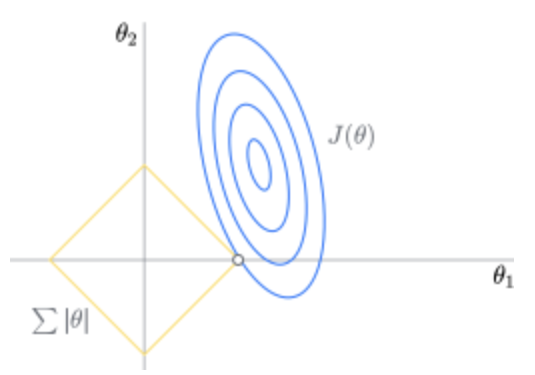
The Lasso method is a compression estimation method that serves as an alternative to ordinary least squares. The basic idea of Lasso is to establish an L1 regularization model, which compresses some coefficients and sets some coefficients to zero during the model establishment process. Once the model training is complete, parameters with weights equal to 0 can be discarded, making the model simpler and effectively preventing overfitting. It is widely used for fitting and variable selection in the presence of multicollinearity.
1.14 K-Nearest Neighbors (KNN)
The main difference between KNN for regression and classification lies in the decision-making method during the prediction phase. For classification prediction, KNN generally uses a majority voting method, where the K closest samples to the predicted sample in the training set are chosen, and the prediction is made based on the most frequent category among those samples. For regression, KNN typically uses the average method, where the average output of the K closest samples is used as the regression prediction value. However, their underlying theory is the same.
1.15 Decision Trees
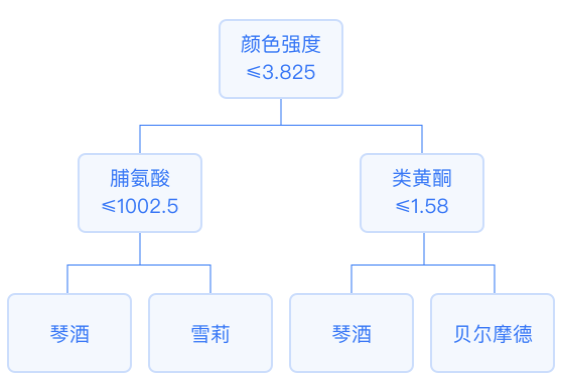
In a decision tree, each internal node represents a split problem: it specifies a test on a certain attribute of the instances, splitting the samples that reach that node according to a specific attribute, with each subsequent branch corresponding to a possible value of that attribute. The output variable’s mode in the leaf nodes of a classification tree is the classification result. The output variable’s mean in the leaf nodes of a regression tree is the prediction result.
1.16 BP Neural Network
BP neural networks are a type of multilayer feedforward network trained by the error backpropagation algorithm and are one of the most widely used neural network models today. The learning rule of the BP neural network uses the steepest descent method, continually adjusting the network’s weights and thresholds through backpropagation to minimize the classification error rate (minimizing the sum of squared errors).
The BP neural network is a multilayer feedforward neural network characterized by forward signal propagation and backward error propagation. Specifically, for the following neural network model with only one hidden layer:
The process of the BP neural network is mainly divided into two phases: the first phase is the forward propagation of signals from the input layer through the hidden layer to the output layer; the second phase is the backward propagation of errors from the output layer to the hidden layer and finally to the input layer, sequentially adjusting the weights and biases from the hidden layer to the output layer and from the input layer to the hidden layer.
1.17 Support Vector Machine (SVM)
Support Vector Machine Regression (SVR) maps data to a high-dimensional feature space using nonlinear mapping, such that the independent and dependent variables have good linear regression characteristics in the high-dimensional feature space. After fitting in that feature space, the results are returned to the original space.
Support Vector Machine Classification (SVM) is a type of generalized linear classifier that performs binary classification of data in a supervised learning manner, with its decision boundary being the maximum margin hyperplane determined from the training samples.
1.18 Naive Bayes
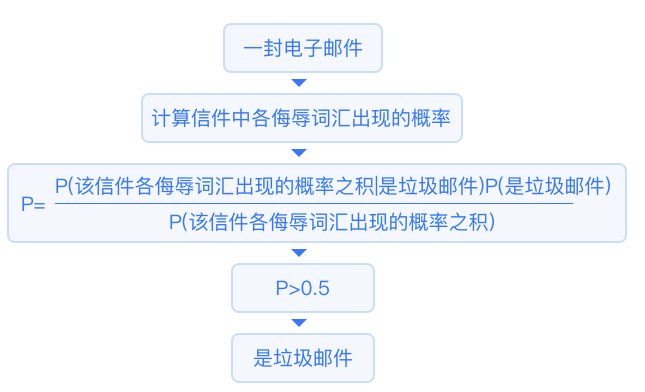
Given the premise of one event occurring, we calculate the probability of another event occurring using Bayes’ theorem. Assuming prior knowledge as d, to calculate the probability that our hypothesis h is true, we will use the following Bayes’ theorem:
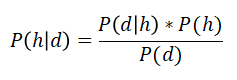
This algorithm assumes that all variables are independent of each other.
1.2 Ensemble Learning
Ensemble learning is a method that combines results from different learning models (such as classifiers) to improve accuracy through voting or averaging. Generally, voting is used for classification problems, while averaging is used for regression problems. This approach is based on the idea of “many hands make light work.”
Ensemble algorithms can be mainly classified into three types: Bagging, Boosting, and Stacking. This article will not cover stacking.

-
Boosting
1.21 GBDT
GBDT is a Boosting algorithm that uses CART regression trees as base learners. It is an additive model that trains a series of CART regression trees serially, ultimately summing the predictions from all regression trees to obtain a strong learner. Each new tree fits the negative gradient direction of the current loss function. The final output is the sum of this series of regression trees, directly yielding regression results or applying the sigmoid or softmax function for binary or multi-class results.
1.22 AdaBoost
AdaBoost assigns a high weight to learners with low error rates and a low weight to learners with high error rates, combining weak learners with their corresponding weights to generate a strong learner. The difference in algorithms for regression and classification problems lies in how error rates are calculated; classification problems typically use a 0/1 loss function, while regression problems usually employ squared loss functions or linear loss functions.
1.23 XGBoost
XGBoost stands for