Skip to content
Learn Excel techniques, follow the WeChat public account:
Tags:Machine Learning,Python
This article will discuss several key concepts of machine learning in a beginner-friendly manner, hoping to give you a basic understanding of machine learning without delving into technical details.
What is Machine Learning (ML)
Traditional software consists of explicit instructions and rules written by programmers. For example, if condition 1 is met, do this; if condition 2 is met, do that, and so on. However, for complex problems, human programmers cannot capture all scenarios and write every rule into code.
Machine learning is a field that combines computer science and statistics. Machine learning models can infer conclusions from data using statistical methods and learn from examples instead of sending thousands of manually coded instructions to the computer. In other words, ML algorithms can make inferences from known examples. In layman’s terms, ML algorithms can examine known data, find patterns, and then apply the learned patterns to unknown data to make predictions.
Do you unlock your smartphone with your fingerprint or face? That’s a machine learning project. Our smartphones do not need to take thousands of photos of us from various angles or different settings; it only needs a few pictures and can recognize our face in most cases.
Do you ask Siri for the weather, time, or search results? This is also machine learning that can recognize human speech. Everyone has different voices, accents, tones, etc. However, in most cases, these devices can understand human language.
Do you often shop on Taobao or Pinduoduo? Why do we always find other items of interest after shopping? Thanks to recommendation systems (also a type of ML algorithm), which know what items we are most interested in.
Types of Machine Learning Methods
There are two main types of machine learning methods: supervised and unsupervised.
Our goal is to predict some output variable related to each input variable. For example, whether a credit card transaction is fraudulent or the price of a house in a neighborhood.
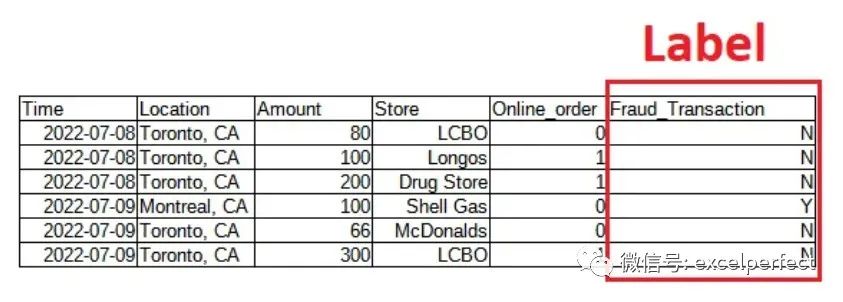
Supervised learning requires a labeled dataset, where labels refer to the output variable. In the credit card example shown below, the input data is time, location, amount, store, and whether it is an online order, while the output or label indicates whether the transaction is fraudulent.
For classification problems, the output is a category (usually a limited number of possible outcomes). For example, whether a credit card transaction is fraudulent (an example of binary classification), or whether a fruit is an apple, orange, or peach. The function that solves this problem is called a classifier (classifier).
For regression, the output is typically a value or number, such as the price of a house in Shanghai or the temperature tomorrow. The function that solves this problem is called a regression function (regression function).
Next, let’s look at some common terms used when describing data with the sample dataset mentioned above.
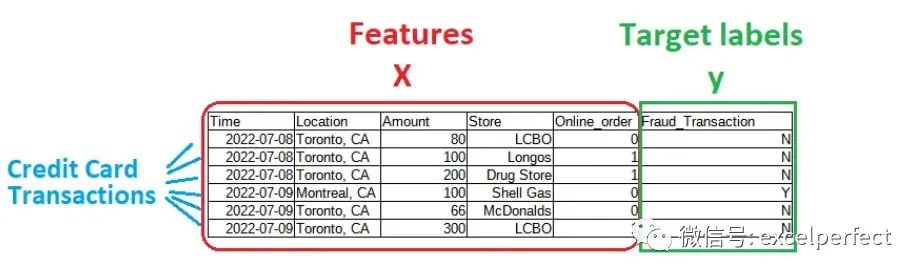
Input (Input)/Independent (Independent)/Features (Features) variable
Typically, input variables are also called independent variables or features. In our code, we usually use the variable name X to represent input variables, which is usually a table of data points. Each column is a feature of the dataset, and each row is a data sample or observation.
Output (Output)/Target (Target) variable
Output variables (or labels) are typically referred to as dependent variables or target variables. In our code, we usually use the variable y to represent the target variable. Labels usually come from manual input. As you can see, in some cases, generating these labels can be a labor-intensive task. For example, Tesla uses humans to label images and videos of cars — roads, lane markings, pedestrians, cars, stop signs, etc. This is how humans provide labels to “supervise” the learning algorithm.
The machine learning model will examine the relationship between input variables X and target variable y. Our goal is to learn a function that can map each row in the input variables X (features) to a label in the target variable y. Once we learn that function, we can give the program a different set of X to predict y.
Here are some beginner-friendly (supervised) machine learning algorithm examples: linear regression, k-nearest neighbors, decision trees, etc. These algorithms can be for regression or classification.
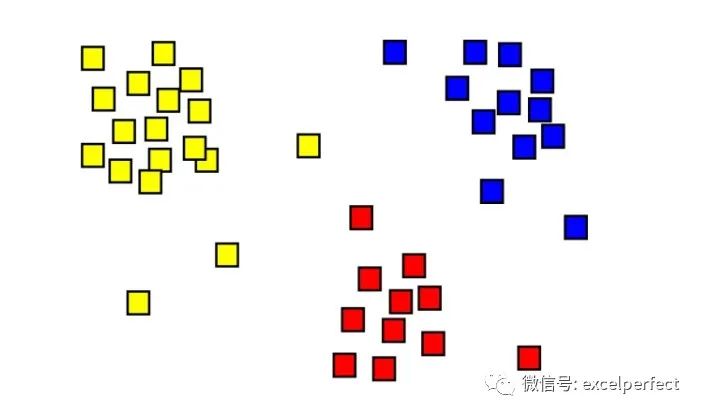
For unsupervised learning, we typically only have input data X, with no labels. For this type of problem, we usually want to examine the input data and try to find useful clusters or groupings.
For example, the YouTube algorithm might group users based on viewing activity — people who like to watch financial news, people who like to watch programming tutorials, or people who enjoy funny videos, etc. Once the YouTube algorithm places us into a cluster, it will continue to recommend relevant videos. That’s why we often find the recommended videos on YouTube very much to our taste.
Everything we discussed in supervised learning also applies to unsupervised learning, except unsupervised learning problems usually do not have a target variable.
Some beginner-friendly (unsupervised) machine learning algorithm examples include k-means clustering, principal component analysis, etc.
Advanced Machine Learning Workflow for Beginners
The advanced machine learning workflow outlined below will start with defining the problem we want to solve.
1.What problem do we want to solve? Is it regression or classification? What algorithm is suitable?
2.Do we have enough data? If not, can we obtain data from other sources or existing data? This is called feature engineering (feature engineering).
3.Split the dataset into two parts, usually a 75%/25% split. One subset is called the training set (75%), and the other subset is called the test set (25%).
4.We will use the training set (training set) to learn the relationship (function) between features and target variables by building a model with some initial parameters.
5.Then use the test set (test set) to measure the model’s prediction performance. Remember, in the test set, we also have labels, so we can measure how many predictions are correct.
6.Typically, the performance of the first model (e.g., accuracy) is not good. Now, we need to consider whether the algorithm we chose in step 1 is appropriate. If we need to use a different algorithm, we must repeat steps 2-5.
7.Once we are satisfied with the algorithm, we need to fine-tune parameters to improve performance. Repeat steps 4-5 with a different set of parameters until we are satisfied with the prediction performance.
Note: This article is compiled from pythoninoffice.com for interested friends to learn and reference.
Welcome to the Knowledge Planet: PerfectExcelCommunity for technical exchanges and questions, to obtain more electronic materials, and to join a dedicated WeChat discussion group through the community for easier communication.