Case Background
Sentiment analysis is an application area of natural language processing (NLP) that aims to understand and analyze the emotions expressed by people in text. This is very useful in areas such as product reviews, social media monitoring, and brand reputation management.
Algorithm Principle: Naive Bayes Classifier
The Naive Bayes classifier is a simple probabilistic classifier based on Bayes’ theorem, assuming the features are independent of each other.

Dataset: IMDb Movie Reviews
Using the IMDb movie review dataset, which contains positive and negative reviews. This is a publicly available dataset commonly used for sentiment analysis tasks.
Computation Steps
1 Data Preprocessing: This includes text cleaning (removing punctuation, numbers, etc.), tokenization, and converting to lowercase.
2 Feature Extraction: Using the bag-of-words model to convert text into feature vectors.
3 Model Training: Using the Naive Bayes classifier to learn from the features.
4 Testing and Evaluation: Evaluating model performance on the test set.
Coding Process
Data Loading: Using the movie review dataset provided by NLTK.
Preprocessing: Converting text to lowercase, removing irrelevant characters, and extracting feature words.
Feature Extraction: Using the bag-of-words model to convert text into numerical vectors.
Model Training: Using the Naive Bayes classifier to learn from the training data.
Model Evaluation: Calculating the accuracy of the model on the test set.
Confusion Matrix: Using the seaborn library to plot a heatmap. Each cell shows the match count between actual labels and predicted labels. This helps us visually see how well the model performs in which categories and where it might have issues.
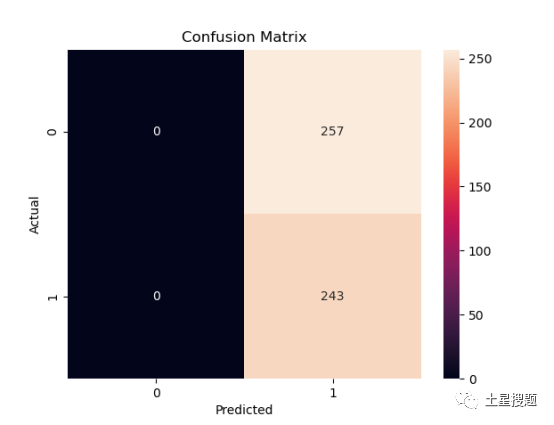
Running Results
Python Code (available for paid reading if needed, or you can practice on your own with the above content!)