Click the card below to follow the “LiteAI” public account
This article will introduce our work on efficiently extending the context length of large models with low resources:LongQLoRA. It will involve knowledge related to Position Interpolation and QLoRA, and we recommend combining it with previous articles to help understand this work:
-
Illustration of RoPE Rotational Position Encoding and Its Characteristics
-
Detailed Explanation of Length Extrapolation Method Based on Adjusting RoPE Rotation Angle
-
[QLoRA Practical] Efficiently Fine-Tuning bloom-7b1 on a Single Card, Stunning Results
Paper link:
https://arxiv.org/abs/2311.04879
Project link:
https://github.com/yangjianxin1/LongQLoRA
01
Abstract
Extending the context length of large models is crucial in various application scenarios such as long document question answering, long text summarization, and RAG, where the context length of large models has become a bottleneck.
We propose LongQLoRA, a low-resource and efficient method for extending the context length of large models. LongQLoRA combines the advantages of Position Interpolation, QLoRA, and Shift Short Attention, requiring only a single 32GB V100 GPU to extend the context length of LLaMA2-7B and 13B models from 4096 to 8192, and even to 12k, with just 1000 steps of fine-tuning.
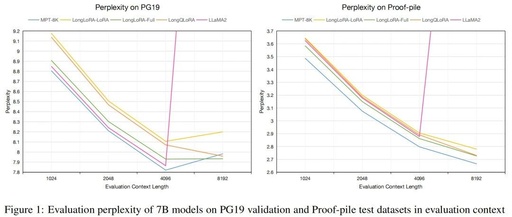
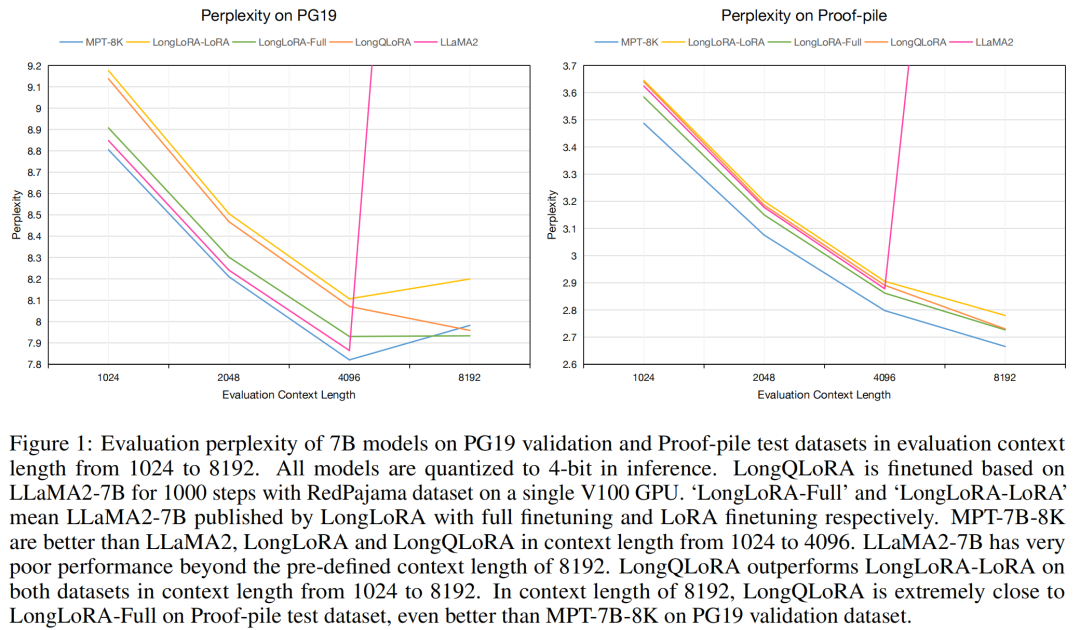
LongQLoRA shows competitive perplexity performance on the PG19 and Proof-pile datasets. In the above evaluation sets, our model outperforms LongLoRA, and its performance at the evaluation length of 8192 is close to that of MPT-7B-8K.
We constructed a dataset containing 39k long instructions and extended the context length of Vicuna-13B from 4096 to 8192, achieving good performance in both long context and short context generation tasks.
We also conducted several ablation experiments, including LoRA Rank, fine-tuning steps, and inference attention mechanisms, to identify better training configurations.
02
Introduction
With the emergence of the LLaMA series models, a series of open-source works based on LLaMA have emerged, such as Vicuna, Gunaco, WizardLM, etc. After instruction fine-tuning and RLHF, these open-source works have achieved excellent performance on many tasks and can even rival or surpass ChatGPT in some tasks.
The LLaMA series models are trained with a predetermined context length, for example, LLaMA has 2048, and LLaMA2 has 4096. Due to the use of RoPE rotational position encoding, the LLaMA series models have weak length extrapolation capability, and when the input length exceeds the predetermined length, the model’s perplexity will rise sharply, and performance will drop dramatically. For some long text tasks, such as multi-document question answering, long text summarization, and long historical dialogues, the limited context length restricts the application scenarios of the model.
To increase the model’s context length, the most straightforward method is to train the model with longer input texts. However, this method consumes a lot of training resources and converges slowly, resulting in poor training effects. To address this issue, Meta proposed Position Interpolation, using 32 A100 GPUs to extend LLaMA’s context length from 2048 to 8192, achieving good results with only 1000 steps of fine-tuning. Focused Transformer (FOT) open-sourced LongLLaMA, extending the model length to 256k. FOT is a plug-and-play extension method, allowing the model to easily extrapolate to longer sequences; for example, a model trained on 8K tokens can easily extrapolate to a 256K window size. LongLLaMA also used 128 TPUs for training. LongLoRA proposed Shift Short Attention and combined Position Interpolation and LoRA to achieve a more efficient length extension method, extending the LLaMA model’s length to 100k on 8 A100.
However, the methods mentioned above, including Position Interpolation and FOT, require a large amount of training resources. In contrast, LongLoRA saves many training resources, but it is still difficult for most ordinary researchers to afford. Is there another method that can further save training resources while ensuring training effectiveness?
We believe that QLoRA is a great choice. QLoRA is an efficient fine-tuning method that quantizes the weights of pre-trained models to 4-bit to reduce model memory usage, then inserts learnable LoRA adapters. This method can fine-tune a 65B model on a 48GB GPU and achieve results very close to full parameter fine-tuning.
In this paper, we propose LongQLoRA, a low-resource and efficient method for extending the context length of large models, allowing us to extend the context length of LLaMA2-7B from 4096 to 8192 using only a single V100. LongQLoRA mainly combines the advantages of QLoRA, Position Interpolation, and Shift Short Attention. In terms of training details, LongQLoRA differs from LongLoRA.
In LongQLoRA, adapters are inserted in all layers, the LoRA Rank is increased to 64, and the embeddings and normalization layers are not trained.
Additionally, we constructed a dataset containing 39k long instructions, primarily including instruction data from Book Sum, Alpaca, WizardLM, Natural Questions, etc. We used this data to extend the context length of Vicuna-13B to 8196 and achieved good results.
Our work can be summarized as follows:
1. We propose LongQLoRA, which combines QLoRA, Position Interpolation, and Shift Short Attention to save training resources and achieve excellent performance. Using only a single V100, we can extend LLaMA2-7B and Vicuna-13B to 8192.
2. We evaluated LongQLoRA on the PG19 and Proof-pile datasets, demonstrating its effectiveness, outperforming LongLoRA and approaching MPT-7B-8K.
3. We collected and constructed 5.4k long text pre-training data and 3.9k long instruction data, and we will open-source our data, training code, and model weights.
03
Method Introduction
Background
Position Interpolation is a method proposed by Meta for extending the context length of large models, allowing the context length of LLaMA to be extended to 32768 with just 1000 steps of long text fine-tuning. Position Interpolation achieves context extension by reducing the RoPE rotational angle.
After linear interpolation of positions, only a small amount of long text data is needed for about 1000 steps of fine-tuning to achieve excellent perplexity performance on the PG19 dataset.
Shift Short Attention is a local attention mechanism proposed by LongLoRA, which significantly reduces memory usage compared to global attention. Shift Short Attention divides the input into multiple groups, and self-attention only operates within each group. Assuming there are groups, the computational complexity is reduced from to .
To compensate for the shortcomings of local attention, Shift Short Attention also performs attention calculations between groups. Experiments have shown that this optimization can achieve performance close to that of global attention.
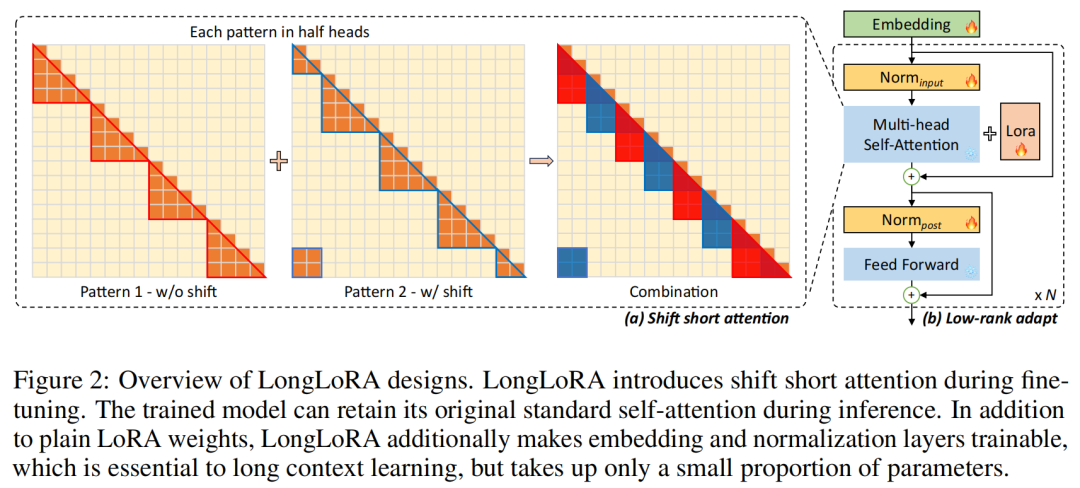
QLoRA is an efficient fine-tuning method for large models proposed by the University of Washington, which can fine-tune LLaMA-65B on a single A100. QLoRA fine-tuned LLaMA-65B can achieve 99.3% of ChatGPT’s performance level (evaluated by GPT-4), and experiments show that QLoRA’s performance can approach full parameter fine-tuning.
QLoRA quantizes the weights of pre-trained models to 4-bit to save memory, then inserts learnable adapters to train the model. QLoRA proposes 4-bit NormalFloat, Double Quantization, and Paged Optimizers.
-
4-bit NormalFloat: A theoretically optimal 4-bit quantization data type, superior to the commonly used FP4 and Int4.
-
Double Quantization: Compared to current model quantization methods, it saves more memory space. Each parameter saves an average of 0.37 bits, which can save about 3GB of memory space for LLaMA-65B.
-
Paged Optimizers: Use NVIDIA unified memory to avoid memory spikes during gradient checkpointing when processing small batches of long sequences.
Based on the above optimizations, QLoRA can fine-tune large models with very little training resources and achieve results close to full parameter fine-tuning.
LongQLoRA
LongQLoRA combines the advantages of Position Interpolation, QLoRA, and Shift Short Attention. We first use Position Interpolation to extend the context length of LLaMA2 to the target length. During training, we first use QLoRA technology to quantize the weights of the pre-trained model to 4-bit to save memory. To further save memory usage during training, we adopt Shift Short Attention.
To compensate for the accuracy loss caused by quantization, we insert adapters in all layers and increase the LoRA Rank to 64. Unlike LongLoRA, we do not need to train the embeddings and normalization layers to achieve good results, which is related to the settings of LoRA Layer and LoRA Rank.
During inference, we found that using global attention performs better than Shift Short Attention, so we uniformly adopt global attention during the inference phase. This also means that during inference, our model can seamlessly integrate with existing technologies such as Flash Attention and vLLM without additional adaptation costs.
04
Experimental Setup & Datasets
We mainly conducted experiments on 7B and 13B models, using only a single 32GB V100 GPU throughout the experiment. We extended the context length of LLaMA2-7B and Vicuna-13B from 4096 to 8192.
We first used Position Interpolation technology to reduce the RoPE rotational angle and extend the model’s context length from 4096 to 8192.
For QLoRA, we quantized the weights of the pre-trained model to 4-bit NormalFloat, set the LoRA Rank to 64, and inserted LoRA adapters in all layers. The training parameter amounts for the 7B and 13B models are approximately 1.5M and 2.5M, respectively. Using Paged Optimizers, we set the learning rates to 2e-4 and 1e-4 for the 7B and 13B models, respectively, with a warmup step of 20, batch size of 1, and gradient accumulation steps of 16. We adopted the Deepspeed Zero2 strategy. For LLaMA2-7B, we trained for 1000 steps, while for Vicuna-13B, we trained for one epoch.
When fine-tuning LLaMA2-7B, we used the next token prediction task, while for fine-tuning Vicuna-13B, we only calculated the loss for the target part.
For Shift Short Attention, we set the group size to 1/4 of the target length and only used Shift Short Attention during training, employing the standard global attention mechanism during inference.
When extending the context length of LLaMA2-7B, we sampled about 54k data from the Redpajama dataset, with token lengths ranging from 4096 to 32768.
We evaluated the model’s perplexity on the PG19 and Proof-pile datasets. When the evaluation length is 8192, we quantized the model weights to 4-bit, while using 16-bit for other evaluation lengths. During evaluation, the sliding window step length is the same as the evaluation length.
Additionally, we constructed a Long Context instruction dataset for supervised fine-tuning of chat models. This dataset contains 39k instruction data, primarily including Book Sum, LongQA, WizardLM, Natural Questions, etc. To accommodate the target length of 8192, the maximum token length in this dataset is 8192. The data distribution is shown in the figure below:
05
Experimental Results
Main Results
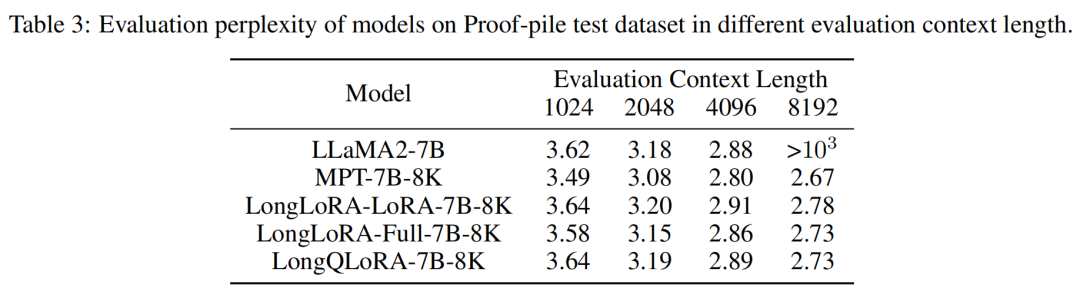
The model’s perplexity performance on the PG19 validation set is shown in the table below. When the evaluation length is 8192, LongQLoRA outperforms LongLoRA-LoRA and MPT-7B-8K, and is very close to LongLoRA-Full, with a perplexity only 0.03 higher. For evaluation lengths from 1024 to 4096, LongQLoRA also slightly outperforms LongLoRA-LoRA and is close to LongLoRA-Full.
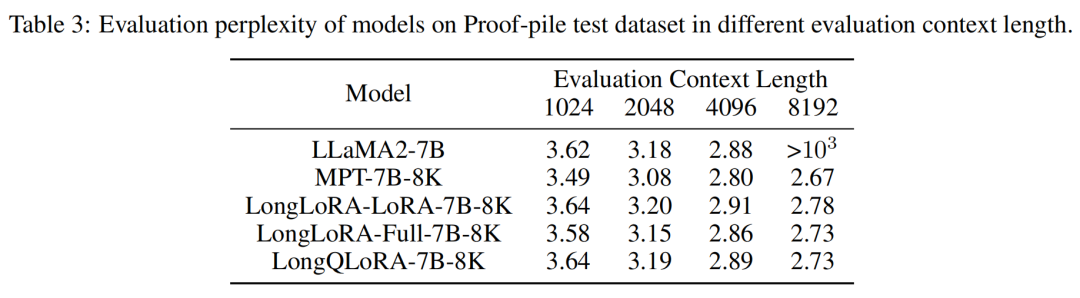
In the table below, we present the evaluation results of the model on the Proof-pile test set. LongQLoRA slightly outperforms LongLoRA-LoRA across evaluation lengths from 1024 to 8192 and is also very close to LongLoRA-Full, nearly identical to LongLoRA-Full at the evaluation length of 8192.
It is noteworthy that MPT-7B-8K is derived from MPT-7B through incremental pre-training, extending the sequence length to 8K and using 500B tokens for full parameter incremental pre-training, resulting in a very high training cost. While LongLoRA saves many training resources, it still consumes 8 A100 GPUs. LongQLoRA is even more efficient, requiring only a single V100 for 1000 steps of fine-tuning to achieve results comparable to or even surpassing other models.
LongQLoRA-Vicuna-13B-8K is fine-tuned based on Vicuna-13B, extending its context length from 4096 to 8192. This model also achieved good performance in Long Context generation and avoided degradation in short instruction-following capabilities. The following figures show examples of the model’s generation.
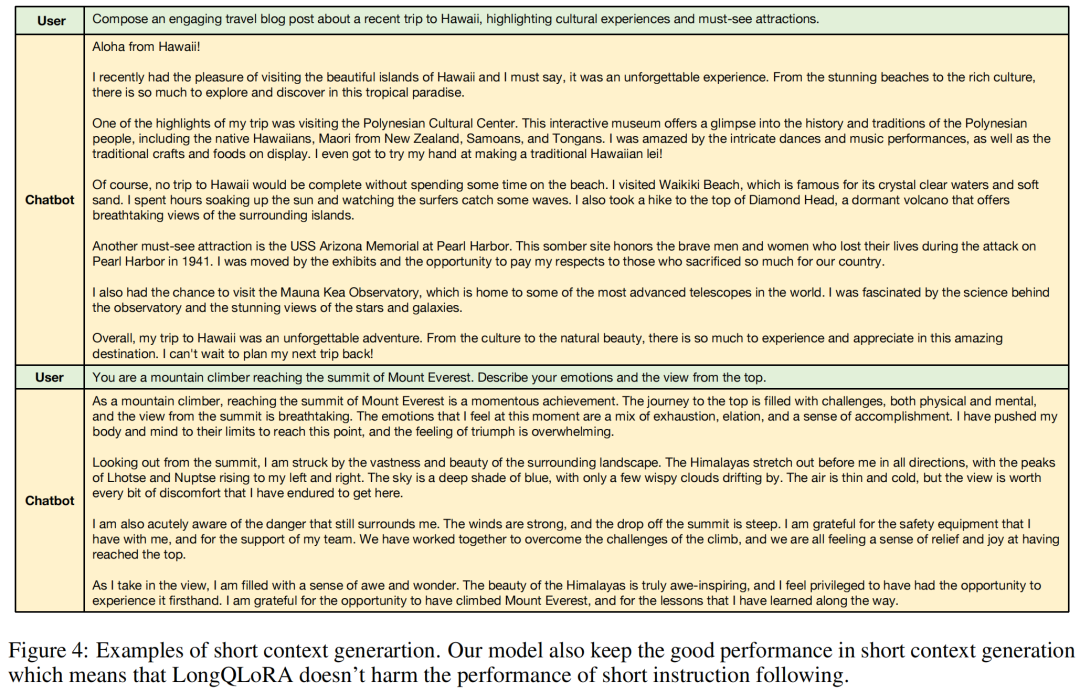
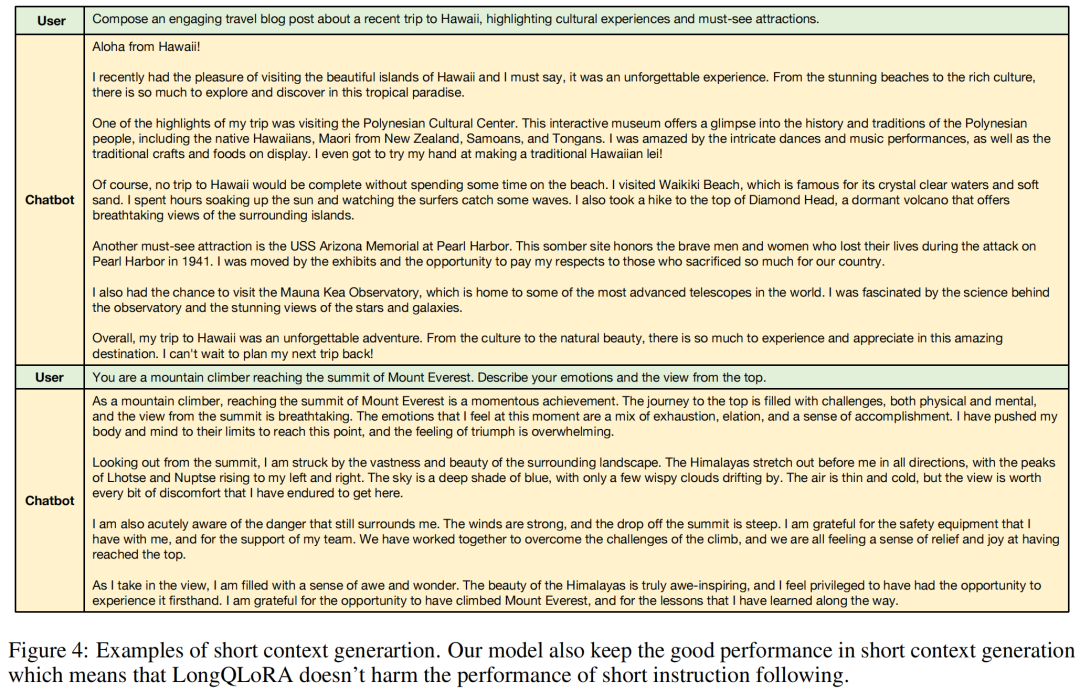
Ablation Experiments
To study the impact of LoRA Rank, we fine-tuned LLaMA2-7B for 1000 steps with different LoRA Ranks. As shown in the table below, as the LoRA Rank increases, the perplexity gradually decreases. When the LoRA Rank is set to 64, LongQLoRA achieves performance nearly identical to LongLoRA-Full, and even slightly better than MPT-7B-8K. Therefore, 64 is a suitable LoRA Rank for LongQLoRA. Perhaps as the LoRA Rank further increases, the perplexity will decrease further.

We also conducted ablation experiments on fine-tuning steps. Fixing the evaluation length at 8192, as the fine-tuning steps increase from 0 to 1000, the model’s perplexity performance on the PG19 validation set is shown in the table below. When the fine-tuning steps are 0, the perplexity is very high; just after 100 steps of fine-tuning, the perplexity significantly decreases. As the fine-tuning steps further increase, the perplexity continuously decreases, and at around 1000 steps, the model basically converges and achieves good performance. This ablation experiment further validates the efficiency of LongQLoRA, requiring only a small amount of long text fine-tuning for 1000 steps to achieve excellent performance.

We conducted ablation experiments using different attention mechanisms during the inference phase. As shown in the table below, Shift Short Attention is not suitable for the inference phase, and the standard global attention mechanism achieves better performance. This also indicates that using Shift Short Attention during training and the standard global attention mechanism during inference is feasible and can perfectly integrate with existing inference technologies and frameworks.

06
Conclusion
We proposed LongQLoRA, a low-resource and efficient method for extending the context length of large models. We validated the effectiveness of this method on LLaMA2-7B and Vicuna-13B, and this method can seamlessly integrate with existing inference technologies and frameworks.
Due to limitations in training resources, we only conducted experiments at a length of 8192 and did not further explore larger context lengths. If future training resources permit, we will attempt to explore the feasibility of the method in larger context lengths.
Scan to add me, or add WeChat (ID: LiteAI01) for technical, career, and professional planning discussions, please note “Research Direction + School/Region + Name”