
When building AI applications, understanding the system’s operational status, performance bottlenecks, and potential issues is crucial. This article will introduce how to add observability to LlamaIndex applications using Phoenix, helping you better monitor and optimize your system.
What Is Observability?
Observability refers to the ability to understand the internal state of a system from its external outputs. In AI applications, good observability can help us:
-
Monitor system performance -
Trace request flows -
Diagnose potential issues -
Optimize system performance
Integration of Phoenix and LlamaIndex
Phoenix is an observability platform designed specifically for LLM applications that can be seamlessly integrated into LlamaIndex applications. Let’s see how to implement this:
1. Basic Configuration
First, we need to visit https://llamatrace.com/ to obtain an API key.
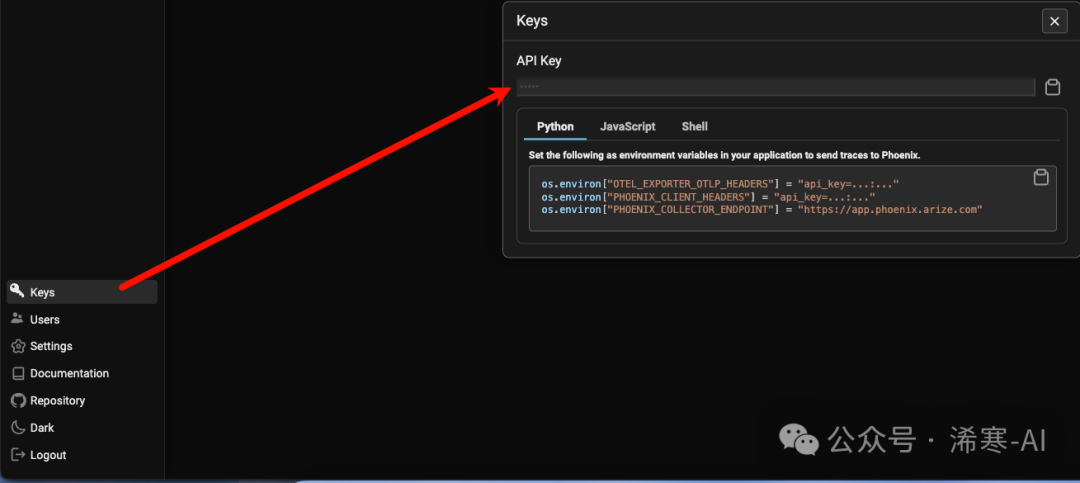
Then set it up in the .env file:
OPENAI_API_KEY=sk-xxx (Fill in your own Key)
PHOENIX_API_KEY=fcxxxx (Fill in your own Key)
Finally, configure the Phoenix observability tool in your code.
import os
from dotenv import load_dotenv
import llama_index.core
# Load environment variables
load_dotenv()
# Configure Phoenix observability tool
# Get Phoenix API key from environment variables
PHOENIX_API_KEY = os.getenv("PHOENIX_API_KEY")
# Set OTEL (OpenTelemetry) exporter request headers, including the API key
os.environ["OTEL_EXPORTER_OTLP_HEADERS"] = f"api_key={PHOENIX_API_KEY}"
# Set global handler, configure Phoenix endpoint for trace data collection
llama_index.core.set_global_handler(
"arize_phoenix",
endpoint="https://llamatrace.com/v1/traces"
)
2. Document Indexing and Persistence
Next, we implement document loading and index creation:
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader, StorageContext, load_index_from_storage
# Read all PDF documents from the pdf directory
documents = SimpleDirectoryReader("pdf/").load_data()
# Implement persistent storage and loading of the index
if os.path.exists("storage"):
print("Loading index from storage")
storage_context = StorageContext.from_defaults(persist_dir="storage")
index = load_index_from_storage(storage_context)
else:
print("Creating new index")
index = VectorStoreIndex.from_documents(documents)
index.storage_context.persist(persist_dir="storage")
This part of the code achieves:
-
Loading documents from the PDF directory -
Checking for the existence of a persistent index -
Selecting to load or create an index based on the situation -
Saving the index to the storage directory
3. Query Execution
Then, we create a query engine and execute queries:
# Create query engine
query_engine = index.as_query_engine()
# Execute query
response = query_engine.query("What are the design objectives, please elaborate.")
print(response)
Finally, you can visit the official website to see the execution process of LlamaIndex!
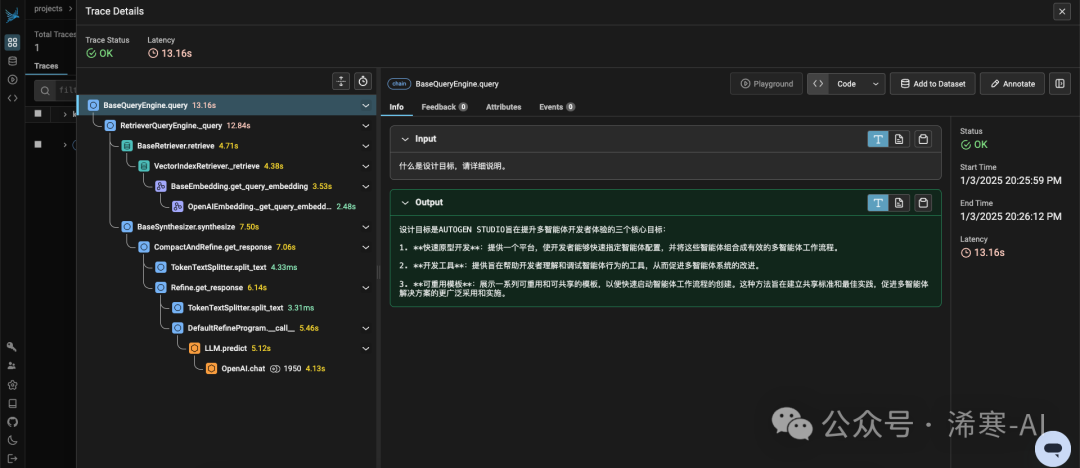
I hope this article helps you better monitor and optimize your LlamaIndex application! In the next article, we will explore how to use LlamaIndex to build AI agents for more complex interactive functions.