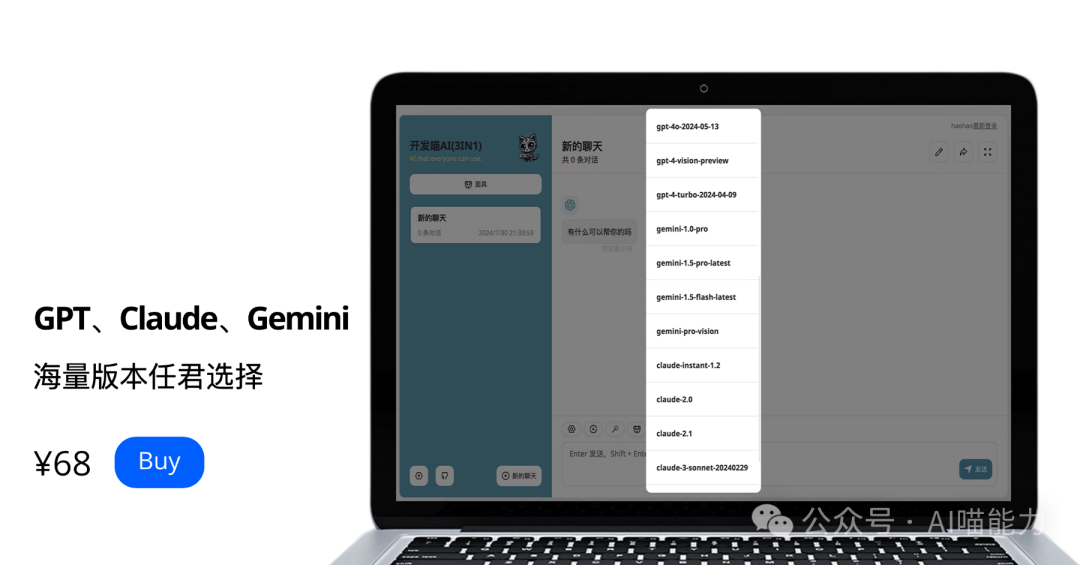
Are you still troubled by the uneven quality and poor performance of AI in China?
Then let’s take a look at Dev Cat AI (3in1).
This is an integrated AI assistant that combines GPT-4, Claude3, and Gemini.
It covers all models of the three AI tools.
Including GPT-4o and Gemini flash
You can own them now for only ¥68.
The official value is ¥420+.
Send “Dev Cat” in the backend to start using it.
Become a member now to enjoy one-on-one private services that ensure your usage is safeguarded.
In the rapidly evolving field of artificial intelligence and machine learning, developers are constantly seeking innovative tools to harness the full potential of large language models (LLMs). LlamaIndex is such a groundbreaking tool that has garnered widespread attention. In this first part of the series, we will delve into what LlamaIndex is, its significance in the AI ecosystem, how to set up the development environment, and guide you in creating your first LlamaIndex project.
What is LlamaIndex?
LlamaIndex is an advanced open-source data framework meticulously designed to connect large language models with external data sources. It provides a comprehensive set of tools for efficiently indexing, building, and retrieving data, allowing for seamless integration of various data types with LLMs.
The Origin of LlamaIndex
The emergence of LlamaIndex aims to address the inherent limitations of feeding large amounts of external data into LLMs, which often affect performance through imposed context constraints and ineffective data processing. Its innovative indexing and retrieval framework optimizes the interaction between LLMs and vast amounts of data, paving the way for developers to build higher-performing, more nuanced AI applications that can leverage contextual intelligence more effectively.
Main Features and Benefits
1. Efficient Data Indexing: LlamaIndex is designed to quickly organize massive data repositories, enabling LLMs to process information at a fraction of the query time elsewhere. This feature significantly enhances functionality and operational efficiency.
2. Extreme Adaptability to Various Data Formats: Unlike rigid indexing solutions, LlamaIndex’s uniqueness lies in its ability to seamlessly manage data in multiple formats—from simple text documents, PDF files, entire website content to custom data objects. With this flexibility, LlamaIndex can meet a wide range of standards encountered in various application scenarios.
3. Seamless LLM Integration: LlamaIndex easily accommodates mainstream LLMs, such as models from OpenAI (like the GPT family of large language models) and free resources like Llama3 and BERT engines. As a result, system developers can ensure continuity by simply inserting existing LLM infrastructure without modification, maintaining stability, efficiency, and cost-effectiveness.
4. Customizable Adjustments for Specific Needs: End-users can easily readjust performance attributes, such as indexing rules or the search algorithms used in index queries, to meet the requirements of custom applications. By tailoring highly adjustable processes to different industry fields (i.e., healthcare or business analytics), accuracy can be achieved while maintaining efficiency through dedicated custom settings.
5. Scalability: LlamaIndex is designed to be easily scalable, making it suitable for both small projects and large enterprise applications.
Use Cases and Applications
The adaptability of LlamaIndex paves the way for groundbreaking applications across multiple domains:
-
Enhanced Question-Answering Engine: Design complex response systems capable of delving into large archives to provide precise answers to intricate queries.
-
Adaptive Text Conciseness: Synthesize meaningful, concise versions of large text or article groupings while preserving thematic importance.
-
Semantic-Driven Search Mechanism: Cultivate a search experience that grasps the potential intent and nuances of input messages, leading to optimized results.
-
Context-Aware Automated Chat Systems: Design conversational partners that intelligently interact with vast databases to generate contextually aware dialogues.
-
Knowledge Base Management and Optimization: Develop management tools aimed at simplifying complex corporate data storage or academic compilations for easy access and association.
-
Semi-Automated Personalized Content Suggestions: Architect recommendation platforms adept at inferring subtle distinctions and taste preferences between users and relevant discoveries.
-
Virtual Assistants Tailored for Academic Research: Design AI-driven virtual research assistants that sift through extensive bibliographic indexes to provide scholars with convenient exploration routes for finding background works and datasets.
Setting Up Your Development Environment
Before diving into the complexities of LlamaIndex, let’s ensure your development environment is correctly set up for optimal performance and compatibility.
Creating a Virtual Environment
Using a virtual environment for your project is a best practice. This approach ensures that your LlamaIndex installation and its dependencies do not interfere with other Python projects on the system. Here’s how to create and activate a virtual environment:
# Create a new virtual environment
python -m venv llamaindex-env
# Activate the virtual environment
# On Unix or MacOS:
source llamaindex-env/bin/activate
# On Windows:
llamaindex-env\Scripts\activateInstalling Required Libraries
After activating the virtual environment, use pip to install LlamaIndex and its dependencies:
pip install llama-index llama-index-llms-ollama llama-index-embeddings-ollamaUnderstanding Core Concepts
Before starting to code, it’s crucial to familiarize yourself with some basic concepts within LlamaIndex. Understanding these concepts will lay a solid foundation for building robust applications.
Documents and Nodes
In the LlamaIndex ecosystem, a document represents a unit of data, such as a text file, webpage, or even a database entry. Documents are the raw inputs that LlamaIndex processes and indexes.
Documents are broken down into smaller units called nodes. Nodes are the fundamental building blocks for indexing and retrieval within LlamaIndex. They typically represent semantic information chunks, such as paragraphs or sentences, depending on the granularity you choose.
The relationship between documents and nodes is hierarchical:
-
A document can contain multiple nodes.
-
Nodes retain the context of their parent document while allowing for finer-grained retrieval.
Indexes
Indexes in LlamaIndex are complex data structures used to organize and store information extracted from documents for efficient retrieval. They are the backbone of LlamaIndex’s fast and accurate information retrieval capabilities.
LlamaIndex offers various types of indexes, each optimized for different use cases:
-
Vector Store Index: Utilizes vector embeddings to represent texts, allowing for semantic similarity searches.
-
List Index: A simple index that stores nodes in a list, suitable for smaller datasets or situations where order is crucial.
-
Tree Index: Organizes nodes hierarchically to represent nested relationships in data.
-
Keyword Table Index: Indexes nodes based on keywords for fast keyword-based searches.
Choosing which type of index to use depends on the unique needs of your application, the nature of the data, and performance specifications.
Query Engine
The query engine is an intelligent component responsible for handling user queries and retrieving relevant information from the index. It acts as a bridge between the user’s natural language questions and the structured data in the index.
The query engine in LlamaIndex employs sophisticated algorithms to:
-
Analyze and understand user queries.
-
Determine the most appropriate search index.
-
Retrieve relevant nodes from the selected index.
-
Use the retrieved information and the capabilities of the underlying LLM to synthesize coherent responses.
There are different types of query engines available, each with its advantages:
-
Vector Store Query Engine: Suitable for semantic similarity searches.
-
Summary Query Engine: Used to generate concise summaries of large documents.
-
Tree Query Engine: Effectively navigates hierarchical data structures.
Mastering how to select and customize the right query engine is crucial for creating successful LlamaIndex applications.
Your First LlamaIndex Project
Setting Up Project Structure
Create a new directory for your project and navigate to that directory:
mkdir llamaindex_demo
cd llamaindex_demoCreate a new Python script named llamaindex_demo.py and open it in your favorite text editor.
Importing Required Modules
Add the following imports at the top of your llamaindex_demo.py file:
import os
from llama_index.core import SimpleDirectoryReader, VectorStoreIndex, ServiceContext
from llama_index.llms.ollama import Ollama
from llama_index.core import Settings
from llama_index.embeddings.ollama import OllamaEmbeddingThese imports provide us with the components necessary to build a LlamaIndex application.
Configuring LlamaIndex
In this example, we will use the open-source LLM Ollama as our language model. Use the following code to set up the LLM and embedding model:
# Set up Ollama
llm = Ollama(model="phi3")
Settings.llm = llm
embed_model = OllamaEmbedding(model_name="snowflake-arctic-embed")
Settings.embed_model = embed_modelThis configuration tells LlamaIndex to use the “phi3” model for text generation and the “snowflake-arctic-embed” model for creating embeddings.
Loading Documents
Next, we will load documents. Create a directory named data in your project folder and place some text files in it. Then, add the following code to load these documents:
# Define the path to your document directory
directory_path = 'data'
# Load documents
documents = SimpleDirectoryReader(directory_path).load_data()The SimpleDirectoryReader class allows you to easily load multiple documents from a directory.
Creating an Index
Now, let’s create a vector store index from the loaded documents:
# Create index
index = VectorStoreIndex.from_documents(documents, show_progress=True)At this stage, we refine the document data, generate their embeddings, and classify them for easy searching within an organized index.
Executing Queries
Finally, let’s set up a query engine and execute a simple query:
# Create query engine
query_engine = index.as_query_engine(llm=llm)
# Perform a query
response = query_engine.query("What is LlamaIndex?")
print(response)This code creates a query engine from our index and uses it to answer the question, “What is LlamaIndex?”
Complete Code
Here is the complete code for our first LlamaIndex project:
import os
from llama_index.core import SimpleDirectoryReader, VectorStoreIndex, ServiceContext
from llama_index.llms.ollama import Ollama
from llama_index.core import Settings
from llama_index.embeddings.ollama import OllamaEmbedding
# Set up Ollama
llm = Ollama(model="phi3")
Settings.llm = llm
embed_model = OllamaEmbedding(model_name="snowflake-arctic-embed")
Settings.embed_model = embed_model
# Define the path to your document directory
directory_path = 'data'
# Load documents
documents = SimpleDirectoryReader(directory_path).load_data()
# Create index
index = VectorStoreIndex.from_documents(documents, show_progress=True)
# Create query engine
query_engine = index.as_query_engine(llm=llm)
# Perform a query
response = query_engine.query("What is LlamaIndex?")
print(response)Code Walkthrough
-
Importing and Configuring: We first import the necessary modules and set up our LLM and embedding model. This configuration tells LlamaIndex which models to use for text generation and creating embeddings.
-
Loading Documents: The
SimpleDirectoryReaderclass is used to load all documents from the specified directory. This versatile loader can handle various file formats, making it easy to fetch data from diverse sources. -
Creating an Index: We use
VectorStoreIndex.from_documents()to create the index. This method processes each document, generates embeddings, and organizes them into a searchable structure. Theshow_progress=Trueparameter provides us with a visual indication of the indexing progress. -
Setting Up the Query Engine: The
as_query_engine()method creates a query engine based on our index. This engine is responsible for handling queries and retrieving relevant information. -
Executing Queries: We use the query engine to ask questions about LlamaIndex. The engine processes the query, searches for relevant information in the index, and generates a response using the configured LLM.
This basic example demonstrates the core workflow of a LlamaIndex application: loading data, creating an index, and querying that index to retrieve information. As you become more familiar with the library, you can explore more advanced features and customize the indexing and querying processes to meet your specific needs.
Advanced Concepts and Best Practices
While our example provides a solid foundation, several advanced concepts and best practices should be considered when developing more complex LlamaIndex applications:
1. Index Persistence
For larger datasets or applications that do not require frequent re-indexing, consider saving the index to disk:
# Save the index
index.storage_context.persist("path/to/save")
# Load a previously saved index
from llama_index.core import StorageContext, load_index_from_storage
storage_context = StorageContext.from_defaults(persist_dir="path/to/save")
loaded_index = load_index_from_storage(storage_context)2. Custom Node Parsers
To better control how documents are split into nodes, you can create custom node parsers:
from llama_index.core import Document
from llama_index.node_parser import SimpleNodeParser
parser = SimpleNodeParser.from_defaults(chunk_size=1024, chunk_overlap=20)
nodes = parser.get_nodes_from_documents([Document.from_text("Your text here")])3. Query Transformations
Enhance query processing through transformations:
from llama_index.core.query_engine import RetrieverQueryEngine
from llama_index.core.retrievers import VectorIndexRetriever
from llama_index.core.postprocessor import SimilarityPostprocessor
retriever = VectorIndexRetriever(index=index)
query_engine = RetrieverQueryEngine(
retriever=retriever,
node_postprocessors=[SimilarityPostprocessor(similarity_cutoff=0.7)]
)4. Handling Different Data Types
LlamaIndex supports various data loaders for different file types:
from llama_index.core import download_loader
PDFReader = download_loader("PDFReader")
loader = PDFReader()
documents = loader.load_data(file="path/to/your.pdf")5. Customizing LLMs
You can fine-tune LLM parameters for better performance:
from llama_index.llms import OpenAI
llm = OpenAI(model="gpt-3.5-turbo", temperature=0.2)
Settings.llm = llmConclusion and Next Steps
In this first part of the series, we provided a comprehensive overview of the basic concepts of LlamaIndex, its significance in the AI ecosystem, how to set up the development environment, and how to create a basic LlamaIndex project. We also introduced core concepts such as documents, nodes, indexes, and query engines, laying a solid foundation for you to build powerful AI applications.
Please stay tuned for the subsequent parts of this series, where we will delve deeper into these advanced topics and provide practical examples to further enhance your expertise with LlamaIndex.

If you found this helpful, don’t rush to leave😝 click “Share to read later🫦