
In previous articles, we have been using the <span>app.invoke(inputs)</span> method to execute workflows. The invoke method returns the final execution result of the entire stream to the caller all at once. If the workflow execution time is long, the waiting time for users will also be long, leading to a poor experience. Currently, mainstream large models provide SSE streaming output interfaces, and LangChain has done a great job of encapsulating streaming output. In this article, we will discuss how to use streaming output in LangGraph.
1. Ordinary Streaming Output
Write a simple workflow application with a large model node and a simple string return node.
from langgraph.graph import add_messages, StateGraph, START, END
from langchain_core.messages import ToolMessage, HumanMessage, AIMessage, BaseMessage
from typing import Type, TypedDict, Annotated, List
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(
model_name="qwen-turbo",
temperature=0.7,
max_tokens=1024,
top_p=1,
openai_api_key="sk-xxxx",
openai_api_base="https://dashscope.aliyuncs.com/compatible-mode/v1"
)
class State(TypedDict):
messages: Annotated[List[BaseMessage], add_messages]
class TestNode:
def __init__(self, msg: str):
self.msg = msg
def __call__(self, state: State):
return {"messages": self.msg}
def chatbot(state: State):
return {"messages": [llm.invoke(state["messages"])]}
graph_builder = StateGraph(State)
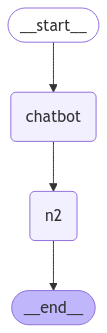
graph_builder.add_node("chatbot", chatbot)
graph_builder.add_node("n2", TestNode("Nice to meet you"))
graph_builder.add_edge(START, "chatbot")
graph_builder.add_edge("chatbot", "n2")
graph_builder.add_edge("n2", END)
app = graph_builder.compile()
app.get_graph().draw_mermaid_png(output_file_path="graph_tool.png")
inputs = {"messages": [HumanMessage(content="Hello")]}
result = app.invoke(inputs)
for i in result.get("messages"):
i.pretty_print()
result = app.invoke(inputs)
for i in result.get("messages"):
i.pretty_print()
The code uses <span>result = app.invoke(inputs)</span>, where result is the final result of the entire workflow, which is the <span>State</span> object defined above.
class State(TypedDict):
messages: Annotated[List[BaseMessage], add_messages]
The State object has a <span>messages</span> attribute, and we use a for loop to iterate through the elements in messages, resulting in the following output:
================================ Human Message =================================
Hello
================================== Ai Message ==================================
Hello! I'm glad to help you.
================================ Human Message =================================
Nice to meet you
<span>pretty_print()</span> is a method encapsulated in langchain that makes the messages from the large model print more nicely.
From the result of the above code, we can see that the final result is returned only after all nodes have completed execution. Next, let’s see how to use streaming output to print each node’s output step by step.
1.1 Using Stream for Streaming Calls
inputs = {"messages": [HumanMessage(content="Hello")]}
for i in app.stream(inputs):
print(i)
Change the above <span>result = app.invoke(inputs)</span> to <span>app.stream(inputs)</span>. This method returns an iterator, <span>Iterator[Union[dict[str, Any], Any]]</span>, and we can iterate through this iterator to print each node’s result output separately.
# AIMessage itself has many attributes, which are not used here, so we use ... instead
{'chatbot': {'messages': [AIMessage(content='Hello! I'm glad to help you.'...]}}
{'n2': {'messages': 'Nice to meet you'}}
From the returned results, we can see that the returned iterable object has each element as a dictionary object, where the dictionary key is the node’s name, and the value is the content returned by that node. Note that only the properties defined in State will be returned; if the node returns additional values, they will not be included, such as:
class TestNode:
def __init__(self, msg: str):
self.msg = msg
def __call__(self, state: State):
return {"messages": self.msg, "timestamp": time.time()}
If the TestNode returns a <span>timestamp</span>, the returned value from <span>app.stream(inputs)</span> will not include the timestamp value.
1.2 Meaning of Different Parameters in StreamMode
The stream method also has a <span>stream_mode</span> parameter, which has the following optional values:
-
‘values’: Emit all values of the state for each step. -
‘updates’: Emit only the node name(s) and updatesthat were returned by the node(s) after each step.- ‘debug’: Emit debug events for each step. -
‘messages’: Emit LLM messages token-by-token. -
‘custom’: Emit custom output <span>write: StreamWriter</span>kwarg of each node.
Let’s look at the effects of each value:
Values
Values are the updated values of the State object after each node execution, as defined in the State above.
class State(TypedDict):
messages: Annotated[List[BaseMessage], add_messages]
The State has a messages attribute, and the update method for this attribute is <span>add_messages</span>. If you are unclear about the principle, please refer to the previous article, “Learn LangGraph From Scratch – (1) Introduction to LangGraph”. When the <span>__START__</span> node finishes execution, it can be understood that after calling <span>app.stream(inputs)</span> for the first time, the State object will be updated after the add_messages method. At this point, the State object is:
{'messages': [HumanMessage(content='Hello', additional_kwargs={}, response_metadata={}, id='20122092-434c-42c5-a127-145a2c0540a6')]}
Then, when executing the chatbot node, this node calls the large model,
def chatbot(state: State):
return {"messages": [llm.invoke(state["messages"])]}
Returning the response from the large model, after add_messages, the content of the large model’s response is appended to the messages in the State object. At this point, the State object is (omitting printing and formatting):
{'messages':
[
HumanMessage(content='Hello', additional_kwargs={}, ...),
AIMessage(content='Hello! How can I help you?', ...})
]
}
This object now contains two elements in its messages attribute:
-
<span>__START__</span>The user’s input content<span>HumanMessage(content='Hello', ...)</span> -
<span>chatbot</span>The content returned by the large model<span>AIMessage(content='Hello! How can I help you?', ...)</span>
Similarly, after passing through the third node <span>n2</span>, the messages in the State object are now:
-
<span>__START__</span>The user’s input content<span>HumanMessage(content='Hello', ...)</span> -
<span>chatbot</span>The content returned by the large model<span>AIMessage(content='Hello! How can I help you?', ...)</span> -
<span>n2</span>The content returned by the node<span>HumanMessage(content='Nice to meet you', ...)</span>
The entire graph’s running result is (simplified):
{'messages': [
HumanMessage(content='Hello', ...)
]}
{'messages': [
HumanMessage(content='Hello', ...),
AIMessage(content='Hello! How can I help you?', ...)
]}
{'messages': [
HumanMessage(content='Hello', ...),
AIMessage(content='Hello! How can I help you?', ...),
HumanMessage(content='Nice to meet you', ...)
]}
Updates
Updates show which node updated what content. In this mode, it will display which node updated what content, but will not return all values of the State, only the content that needs to be updated.
{'chatbot': {'messages': [AIMessage(content='Hello! I'm glad to help you.'...)]}}
{'n2': {'messages': 'Nice to meet you'}}
When passing through the <span>__START__</span> node for the first time, there are no update operations, so after executing the <span>__START__</span> node, there will be no output.
After executing the chatbot node,<span>return {"messages": [llm.invoke(state["messages"])]}</span>, the output from the large model is returned, and this requires updating the messages in the State. The content to be updated is <span>{'messages': [AIMessage(content='Hello! I'm glad to help you.'...)]}</span>, which is the content returned by the chatbot node.
Similarly, after executing the n2 node, it returns <span>{'messages': 'Nice to meet you'}</span>.
In the updates mode, it can be understood that what is returned is the content that needs to update the State or the content returned by the node, but only includes the properties defined in the State.
In practical applications, the main modes used are values and updates. Let’s take a quick look at a few other modes:
Debug
Debug mode returns the input and output of each node during execution, as well as some runtime information, making it easier for us to debug.
{
'type': 'task',
'timestamp': '2024-12-24T03:37:21.438331+00:00',
'step': 1,
'payload': {
'id': '76b98a43-0d50-f270-b5c5-c09296f0b1ea',
'name': 'chatbot',
'input': {
'messages': [
HumanMessage(content='Hello', ...)
]
},
'triggers': ['start:chatbot']
}
}
{
'type': 'task_result',
'timestamp': '2024-12-24T03:37:22.169144+00:00',
'step': 1,
'payload': {
'id': '76b98a43-0d50-f270-b5c5-c09296f0b1ea',
'name': 'chatbot',
'error': None,
'result': [
('messages', [
AIMessage(content='Hello! I'm glad to help you.', ...)
])
],
'interrupts': []
}
}
...
Messages
In messages mode, only the large model’s output is returned token-by-token.
(
AIMessageChunk(content='', ...),
{
'langgraph_step': 1,
'langgraph_node': 'chatbot',
'langgraph_triggers': ['start:chatbot'],
'langgraph_path': ('__pregel_pull', 'chatbot'),
'langgraph_checkpoint_ns': 'chatbot:64c7c860-f07b-e943-95ca-e576e3984f88',
'checkpoint_ns': 'chatbot:64c7c860-f07b-e943-95ca-e576e3984f88',
'ls_provider': 'openai',
'ls_model_name':
'qwen-turbo',
'ls_model_type':
'chat',
'ls_temperature': 0.7,
'ls_max_tokens': 1024
}
)
(
AIMessageChunk(content='Hello', ...),
{...}
)
(
AIMessageChunk(content='!', ...),
{...}
)
(
AIMessageChunk(content='Nice to meet', ...),
{...}
)
...
Custom
Custom refers to custom message events, which we will explain in detail later.
StreamMode Summary
-
Values are the updated values of the State object after each node execution. -
Updates are the content that needs to be updated after each node execution, or can be understood as the node’s returned content, but only includes the properties defined in the State. -
Debug mode returns the input and output of the node’s execution. -
Messages mode only returns the large model’s streaming output.
The commonly used modes are updates and values. If we only care about the values of the State after each node execution, we need to use the values mode. If we want to get each node’s return value, we need to use updates.
Additionally, the stream_mode can also be in list form. For example, if you care about both the node’s return and the updated values of the State,
for i in app.stream(inputs, stream_mode=["updates", "values"]):
print(i, "\n\n")
('values', {'messages': [HumanMessage(content='Hello', ...)]})
('updates', {'chatbot': {'messages': [AIMessage(content='Hello! I'm glad to help you.'...)]}})
...
In this mode, each streaming data is a tuple:
-
The first element is the event (mode) name, such as the updates or values above. -
The second element is the event data, which is the same as the data introduced above.
The default stream_mode is <span>updates</span>, although the source code comments mention that the default is values, the execution results show that the default behavior is updates.
2. Streaming Output of Large Models
The above introduced using the stream method for node streaming output and controlling the streaming output mode through stream_mode. As a large model application development framework, we will use LangGraph to develop many LLM-based applications, which will inevitably use large models. To enhance user experience, large models generally provide streaming output.
Through the above sections, when the stream_mode is messages, although it can output the large model token-by-token, it cannot output updates or State’s values simultaneously. Of course, we can use <span>stream_mode=["updates", "messages"]</span> to output both at the same time.
inputs = {"messages": [HumanMessage(content="Hello")]}
for i in app.stream(inputs, stream_mode=["updates", "messages"]):
if event == "messages":
message_data, graph_data = data
print(event, {graph_data.get("langgraph_node"): message_data.to_json()})
else:
print(event, data)
print("\n")
messages {'chatbot': {'lc': 1, 'type': 'constructor', 'id': ['langchain', 'schema', 'messages', 'AIMessageChunk'], 'kwargs': {'content': '', 'type': 'AIMessageChunk', 'id': ['run-b70f5aa4-46b9-4470-a485-c3230437ffe7', 'tool_calls': [], 'invalid_tool_calls': []}}}
messages {'chatbot': {'lc': 1, 'type': 'constructor', 'id': ['langchain', 'schema', 'messages', 'AIMessageChunk'], 'kwargs': {'content': 'Hello', 'type': 'AIMessageChunk', 'id': ['run-b70f5aa4-46b9-4470-a485-c3230437ffe7', 'tool_calls': [], 'invalid_tool_calls': []}}}
...
updates {'chatbot': {'messages': [AIMessage(content='Hello! How can I help you?', additional_kwargs={}, response_metadata={'finish_reason': 'stop', 'model_name': 'qwen-turbo'}, id='run-b70f5aa4-46b9-4470-a485-c3230437ffe7')]}},
updates {'n2': {'messages': 'Nice to meet you'}}
Using stream_mode as <span>["updates", "messages"]</span> allows for simultaneous return of the large model’s token-by-token output and the updates needed after the node execution. Although this method temporarily solves the simultaneous output of large model streaming and node streaming, its limitations are also apparent. Here, we recommend using another method, <span>astream_events</span>, which is oddly asynchronous, but LangChain has not defined the <span>stream_events</span> method. Typically, LangChain defines both synchronous and asynchronous methods, such as <span>invoke</span> and <span>ainvoke</span>, <span>stream</span> and <span>astream</span>, but this method only has <span>astream_events</span>. The official documentation mentions that it is usually unnecessary when working with LangGraph,
❝
Use the
<span>astream_events</span>API to access custom data and intermediate outputs from LLM applications built entirely with LCEL. While this API is available for use with LangGraph as well, it is usually not necessary when working with LangGraph, as the<span>stream</span>and<span>astream</span>methods provide comprehensive streaming capabilities for LangGraph graphs.
However, I think this method is still very flexible, so I will briefly introduce its usage here.
astream_events
We can understand the updates of State and the execution of the large model as “events”. Each operation is an event, such as when a node starts executing, when a node finishes executing, receiving streaming output from the large model, invoking tools, etc. These can be understood as events, and LangChain internally defines many events. For details, please refer to the LangChain official documentation here.
When using <span>astream_events</span>, many outputs will be obtained. Here we should only focus on the events we want, such as the node execution end and the large model streaming output. Modify the original code to make an asynchronous call:
async def main():
inputs = {"messages": [HumanMessage(content="Hello")]}
async for event in app.astream_events(inputs, version="v2"):
kind = event.get("event")
data = event.get("data")
name = event.get("name")
if name == "_write":
continue
if kind == "on_chain_end":
ydata = {
"kind": kind,
"name": name,
"data": data
}
elif kind == "on_chat_model_stream":
ydata = {
"kind": kind,
"name": name,
"node": event.get("metadata").get("langgraph_node"),
"data": event["data"]["chunk"].content
}
else:
continue
print(ydata)
At this point, we can greatly customize the output of the data.
{'kind': 'on_chain_end', 'name': '__start__', 'data': {'output': {'messages': [HumanMessage(content='Hello', additional_kwargs={}, response_metadata={})]}, 'input': {'messages': [HumanMessage(content='Hello', additional_kwargs={}, response_metadata={})]}}}
{'kind': 'on_chat_model_stream', 'name': 'ChatOpenAI', 'node': 'chatbot', 'data': ''}
{'kind': 'on_chat_model_stream', 'name': 'ChatOpenAI', 'node': 'chatbot', 'data': 'Hello'}
{'kind': 'on_chat_model_stream', 'name': 'ChatOpenAI', 'node': 'chatbot', 'data': '!'}
...
{'kind': 'on_chain_end', 'name': 'chatbot', 'data': {'output': {'messages': [AIMessage(content='Hello! How can I help you?', ...)]}}}
{'kind': 'on_chain_end', 'name': 'n2', 'data': {'output': {'messages': 'Nice to meet you'}, 'input': .....}}
3. Precautions
You need to use python >= 3.11. In python versions below 3.11, the stream method will not provide streaming output from the large model.
❝
When using python 3.8, 3.9, or 3.10, please ensure you manually pass the RunnableConfig through to the llm when invoking it like so:
<span>llm.ainvoke(..., config)</span>. The stream method collects all events from your nested code using a streaming tracer passed as a callback. In 3.11 and above, this is automatically handled via contextvar‘s; prior to 3.11, asyncio’s tasks lacked proper contextvar support, meaning that the callbacks will only propagate if you manually pass the config through. We do this in the<span>call_model</span>method below.
4. Summary
This article contains a lot of content, mainly focusing on the topic of LangGraph streaming output.
-
Using the stream method for streaming output of each node’s execution result. -
Detailed introduction to the parameters of stream_mode in the stream method and their streaming output effects. -
Using the astream_events method to handle multiple events simultaneously, achieving both streaming output of node results and streaming output of the large model call. -
Note that to use streaming, python >= 3.11 is required.
Next Issue Preview
We will use the points introduced so far to build a travel assistant application.