


With the development of multimedia technology, the types and volumes of accessible media data have significantly increased. Inspired by human perception, the integration of various media data promotes the research and development of artificial intelligence in the field of computer vision, with wide applications in remote sensing image interpretation, biomedicine, and depth estimation. Despite the clear advantages of multimodal data in describing the characteristics of things, it still faces significant challenges. 1) Due to limitations of different imaging devices and sensors, it is difficult to collect large-scale, high-quality multimodal datasets; 2) Multimodal data needs to be matched in pairs for research, and the absence of any modality will reduce the available data; 3) Processing and annotating image and video data requires considerable time and human resources, making the current technology in this field still a work in progress. This article focuses on multimodal learning methods under data-limited conditions, categorizing methods in the field of computer vision into five directions: few-shot learning, lack of strong supervisory annotation information, active learning, data denoising, and data augmentation, detailing the characteristics of samples and the latest progress of model methods. It also introduces the datasets used in multimodal learning methods under data-limited conditions and their application directions (including human pose estimation, pedestrian re-identification, etc.), comparing and analyzing the advantages and disadvantages of existing algorithms and future development directions, which has positive significance for the development of this field.
http://www.cjig.cn/jig/ch/reader/view_abstract.aspx?file_no=20221002&flag=1
1
Introduction
1
Introduction
Modality is a form of expression of things, a description from a specific angle. Multimodality usually includes two or more modalities, referring to the description of things from multiple perspectives. When perceiving the world, multiple senses always receive external information simultaneously, such as seeing images, hearing sounds, smelling odors, and tactile perceptions. With the development of multimedia technology, the types and volumes of accessible media data have greatly increased. For example, sensors can not only generate images or videos but also include matching depth, temperature information, etc. To enable artificial intelligence technology to better interpret data, it must possess the ability for multimodal learning.
In the early research of artificial intelligence technology, scholars typically used data from a single modality. Inspired by human perception, research suggests that each modality independently describes things, and using complementary representations of multimodal data can present things more three-dimensionally and comprehensively (Baltrušaitis et al., 2019). In recent years, the processing and application of multimodal data have become key research directions, achieving significant breakthroughs in cutting-edge fields such as sentiment analysis, machine translation, natural language processing, and biomedicine. Computer vision is an important application area and hot research issue in deep learning, and this article focuses on the development of multimodality in the field of computer vision.
As shown in Figure 1, multimodal learning in the field of computer vision mainly involves analyzing multimodal data such as images and videos, learning and complementing information between different modalities, and performing tasks such as image detection recognition, semantic segmentation, and video action prediction (Liu and Wang, 2015; Eigen and Fergus, 2015). It is widely applied in areas such as autonomous driving, agricultural monitoring, biomedical applications, traffic management, and disaster prediction. For example, in the medical field, medical imaging serves as an important basis for medical diagnosis; compared to single-angle descriptions of lesion characteristics, multimodal medical imaging can effectively assist doctors in making joint judgments about lesions and surrounding areas from multiple perspectives, thereby speeding up diagnosis time; in the remote sensing field, single sensors describe geographic targets from a fixed angle based on equipment characteristics, and independent analysis may be limited by imaging principles. However, analyzing multimodal remote sensing images obtained from different imaging methods and sensors can effectively extract comprehensive information about ground targets.

Figure 1 Solutions and Applications for Limited Multimodal Data
Despite the clear advantages of multimodal data in describing the characteristics of things, it still faces significant challenges. 1) Although imaging technologies are emerging continuously, the processing and annotation tasks of the resulting image and video data involve considerable workload, requiring significant time and human resources. 2) Traditional deep learning models require multimodal data to be matched in pairs for research, and the absence of any modality will reduce the available data. 3) Since the purpose is to utilize the complementary characteristics of multimodal data, there are high requirements for the integrity of the data. However, due to limitations of different imaging devices and sensors, the data volume is small, quality is ambiguous, and missing phenomena are severe, all of which adversely affect subsequent research. Therefore, research on multimodal processing under data-limited conditions is of significant practical importance. In response to these challenges, the current methods for processing limited multimodal data can be categorized as follows:
1) Few-shot learning methods. In the case of insufficient multimodal data, few-shot learning methods can make correct judgments with only a small number of samples, effectively learning target features even when data is scarce.
2) Methods lacking strong supervisory annotation information. Due to the high costs associated with the data annotation process, it is challenging to obtain complete ground truth labels for all modalities for strong supervised learning. Common semi-supervised methods include weak supervision, unsupervised, semi-supervised, and self-supervised learning methods, which can effectively address the issue of lack of annotation information across modalities and significantly reduce manual labeling costs.
3) Active learning methods. This category of methods involves designing models with autonomous learning capabilities that fully integrate human experience and learning rules, focusing on how to use as few labeled samples as possible to achieve the best possible outcomes. By selecting the most useful samples, it is possible to maintain performance while effectively reducing labeling costs.
4) Data denoising methods. During the acquisition and processing of multimodal data, external environmental factors and internal device factors can introduce noise. Any modality’s data affected by noise pollution may influence the results of multimodal data processing. Multimodal data denoising refers to reducing noise in the data, recovering the original data, and extracting the information of interest.
5) Data augmentation. Under the premise of having few samples, to fully utilize limited multimodal data, data augmentation methods expand the usability of data through a series of transformation operations on the original dataset.
This article primarily reviews multimodal data processing methods under data-limited conditions. Previous researchers have conducted studies in related fields, deeply exploring multimodal learning, few-shot learning, weakly supervised learning, active learning, data denoising, and augmentation. Baltrušaitis et al. (2019) discussed the progress of multimodal machine learning from a holistic perspective and categorized multimodal machine learning methods, but did not introduce specific application scenarios. Wang et al. (2020b) introduced multimodal models from the perspective of network architecture but did not discuss the characteristics of multimodal data itself. Ramachandram and Taylor (2017) summarized the current state of multimodal deep learning and proposed that the design of network architectures should consider fusion modes, modality information, and handling of missing data or modalities, but did not provide a detailed review of current methods for handling missing data to improve model robustness. Gao et al. (2020) summarized representative deep learning network architectures for processing heterogeneous data, noting that some deep learning models focus only on single-modal noisy data, indicating an urgent need to address deep learning models for low-quality multimodal data. The above reviews lack detailed introductions to the development of multimodal data under data-limited conditions. Wang et al. (2021c) reviewed recent advances in few-shot learning methods and provided a unified classification. Zhou et al. (2019) reviewed some research advances in weakly supervised learning. Settles (2011) reviewed the challenges faced when applying active learning in practice and introduced the work done to address these challenges. However, the aforementioned literature has only summarized based on single-modal data, without addressing the background issues of multimodal data.
In response to the various challenges and difficulties faced in the processing of multimodal data under data-limited conditions, some researchers have provided solutions, but relevant review literature has yet to be formed. Therefore, this article summarizes the research methods and advancements in multimodal analysis and processing under data-limited conditions, as well as the application status of multimodal data in different fields. First, it discusses the research status and challenges of multimodal data in the field of computer vision under data-limited conditions, introducing methods for handling different data-limited situations and presenting the background and objectives of this research. Then, it categorizes and clarifies the current status and research methods of different data-limited processing methods, distinguishing the difficulties and challenges faced by different limited situations. Finally, it introduces typical datasets in various application fields of multimodal data, summarizes current research achievements, which can inspire future applications of multimodality and outline the next research directions.
2
Applications of Multimodal Data
2
Applications of Multimodal Data
This section first introduces methods for multimodal data fusion, followed by common application scenarios of multimodal data in the field of computer vision.
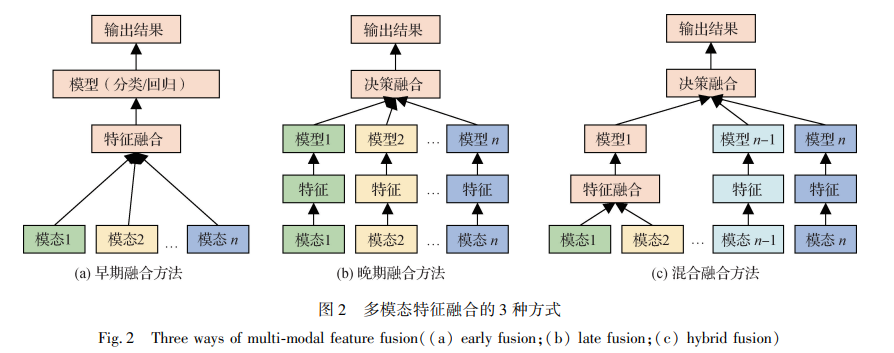
Multimodal Data Detection and Recognition
Image classification refers to the ability of a computer to recognize the “category” to which an image belongs. Essentially, it assigns a label to the image, such as “car,” “animal,” and “building.” Based on classification technology, object detection technology has been developed, allowing computers to identify and locate objects within an image or video. Through this identification and localization, object detection can be used to calculate the number of objects in a scene, determine and track their precise locations, while accurately labeling them. Detection and recognition technologies are important technologies in computer vision and have been applied to tasks in multimodal data scenarios such as pedestrian re-identification, scene recognition, and human action recognition.
Multimodal Image Semantic Segmentation
Image semantic segmentation refers to assigning category labels to each pixel of an image based on its semantics. Specifically, during the process of image segmentation, each pixel is classified under a certain label, with pixels belonging to the same label sharing certain visual characteristics. Similarly, this technology has been widely applied in multimodal data scenarios such as road scene segmentation, medical image segmentation, and remote sensing image segmentation.
Multimodal Data Prediction and Estimation
In the field of deep learning, prediction and estimation is an important application direction, where trained deep learning models can estimate or predict certain states or parameters based on input data. In the field of multimodal data prediction and estimation, technologies such as monocular depth estimation, 3D human pose estimation, and path planning have been widely applied.
3
Processing Methods for Limited Multimodal Data
3
Processing Methods for Limited Multimodal Data
This article categorizes the current methods for processing limited multimodal data based on different dimensions such as the number of multimodal samples, annotation information, and sample quality into few-shot learning methods, methods lacking strong supervisory information, active learning methods, data denoising, and data augmentation methods.
Multimodal Datasets
Currently, there are numerous types and quantities of multimodal datasets corresponding to application scenarios in various fields mentioned in Section 1. This article summarizes and organizes commonly used datasets in these fields according to their application areas, dataset names, included modalities, proposed years, and corresponding application scenarios, as shown in Table 5.
4
Conclusion
4
Conclusion
The processing and application of multimodal data have become key research directions, achieving significant breakthroughs in cutting-edge fields such as sentiment analysis, machine translation, natural language processing, and biomedicine. Researchers both domestically and internationally have conducted extensive studies on multimodal learning under data-limited conditions. This article delves into different forms of data limitation and summarizes the development status of multimodal data processing under data-limited conditions in the field of computer vision. Furthermore, based on the above analysis, this article briefly introduces directions for further research needed in the field of multimodal data processing.
1) Lightweight multimodal data processing methods. Multimodal learning under data-limited conditions still faces challenges when applying models to mobile devices. Current methods generally require the use of two or more networks for feature extraction when fusing information from multiple modalities, resulting in large parameter volumes and complex model structures that limit their application to mobile devices. Future work should further explore lightweight models.
2) General multimodal intelligent processing models. Existing multimodal data processing methods are often different algorithms developed for different tasks, requiring training on specific tasks. This task-specific training approach significantly increases the cost of model development and is difficult to meet the rapidly growing demand in application scenarios. Therefore, suitable general perception models need to be proposed for different modalities of data to learn general representations of multimodal data, enabling the sharing of model parameters and features across different application scenarios.
3) Knowledge and data hybrid-driven models. Different modalities of data often contain different characteristics. This article suggests that in processing multimodal data, in addition to using multimodal data itself, one can consider incorporating data characteristics and knowledge to establish knowledge and data hybrid-driven models, enhancing the performance and interpretability of the models.
Scan the QR code to add the assistant WeChat
About Us