Today, I will share the improved model GER-UNet, which is based on the 2020 paper “Beyond CNNs: Exploiting Further Inherent Symmetries in Medical Images for Segmentation.” By understanding the ideas behind this model, similar improvements can be made based on VNet.
1. Limitations of Conventional Convolutional Networks
1. Conventional convolutional neural networks can only utilize varying translations while ignoring other inherent symmetries present in medical images, such as rotation and reflection. To mitigate this drawback, this paper proposes a novel group-invariant segmentation framework that learns more accurate representations by encoding those inherent symmetries. First, kernel-based invariant operations are designed in every direction to effectively address the problem of learning symmetry in existing methods. Then, to maintain global equivalence in the segmentation network, a unique group layer with hierarchical symmetry constraints is designed. By leveraging more symmetry, the novel segmentation CNN can significantly reduce sample complexity and filter redundancy (about 2/3) compared to conventional CNNs.
2. To endow conventional CNNs with more symmetric properties, there are three common strategies. The first is data augmentation, a well-known effective method. Although data augmentation allows CNNs to learn different transformation features, the size of the learned CNN feature parameters increases, leading to excessive redundancy and a higher risk of overfitting. Additionally, such soft constraints cannot guarantee the invariance of the trained CNN model on test or training data. The second is to maintain multiple rotation feature maps at each layer in existing rotation-invariant networks, which is easy to implement. However, rotating and repeating the original feature output at each layer significantly increases storage requirements. The third is through the rotational equivariance acting on the filters, which has become a promising direction. Although rotating convolutional kernels can achieve local symmetry in different directions at each convolutional layer, these solutions limit the depth of the network and global rotational invariance due to the explosion of dimensions and increased noise caused by directional pooling operations.
3. The inspiration for this paper comes from group-invariant CNNs in conventional image classification. By combining translation, rotation, and reflection to establish a symmetry group, the utilization of each kernel can be significantly improved while reducing the number of filters. Powerful hierarchical constraints are designed to ensure equality for each network with strict mathematical proofs. Equivariant transformations are performed on filters rather than feature maps to reduce memory requirements. Group-invariant layers and modules can make the network globally invariant in an end-to-end manner. Furthermore, they can be stacked into deeper architectures for various visual segmentation tasks, while the computational overhead of counterparts based on conventional CNNs can be negligible.
2. GER-Unet Network
1. Core Module of the Group-Invariant Segmentation Framework
All network operations are based on the same symmetry group, which consists of translations, 90-degree rotations, and reflections, resulting in a total of eight groups: four pure rotations and their corresponding reflections.
Group Input Layer: The first layer input is the original input image. The input image is convolved with eight convolution kernels that correspond to the same kernel for rotation and reflection. Initially, there is one convolution kernel parameter, which generates eight directional convolution kernels through 90-degree rotations and reflections, as shown in the figure below.
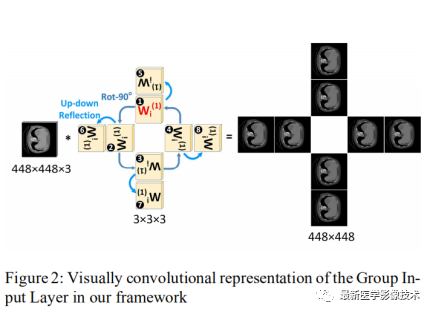
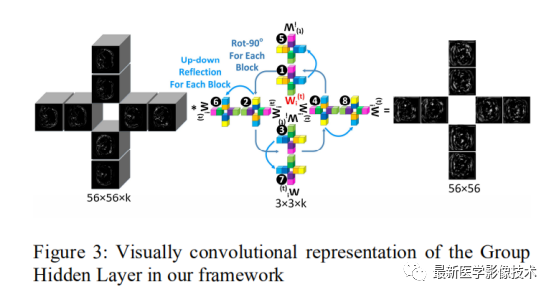
Group Hidden Layer: The input consists of feature maps from different directions. Each directional feature map is convolved with the eight rotation and reflection symmetry groups, as illustrated.
Group Upsampling Layer: Similar to upsampling operations in conventional CNNs, upsampling can be performed using nearest neighbors and bilinear interpolation. However, unlike conventional methods, group upsampling is performed simultaneously in eight directions, while traditional methods operate in one direction. In practice, upsampling can be performed separately on the group feature maps in eight directions or by concatenating the group feature maps from eight directions before separating them into eight directional group feature maps.
Group Skip Connection Layer: Conventional skip connections act on two independent feature output modules, while group skip connections operate in all directions to connect the group convolution outputs in encoding and decoding. The group skip connection can obtain more details from each symmetric property, resulting in more accurate segmentation results.
Group Output Layer: The segmentation results from different directions are aggregated. To ensure the invariance of different rotations and reflections, global average pooling operations are used in each direction to obtain invariant results. Then, the results from the group output layer in all directions are transformed into a single-channel binary prediction map. Since pooling operations reduce the resolution of feature maps, which is detrimental to segmentation, different strides are used in the group hidden layer to replace pooling.
2. GER-Unet Network
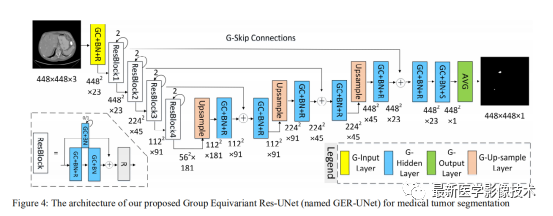
The entire structure consists of convolutions, batch normalization, and activation functions, comprising one group input layer, eight residual modules, which consist of many group hidden layers, three group upsampling layers, one group output layer, and other modules for pixel-level segmentation.
3. Experimental Details and Results
1. Training Data: 131 cases of enhanced CT data.
2. Evaluation Metrics: To compare the results of different segmentation methods, metrics such as Dice, Hausdorff distance, Jaccard, precision (also known as positive predictive value), recall (also known as sensitivity or true positive rate), specificity (also known as true negative rate), and F1 score are used.
3. Parameter Settings: The ratio of training data to testing data is 4:1. Training is performed on a Tesla V100 (16GB memory) with a batch size of 4, a learning rate of 0.0002, for 300 epochs, employing early stopping, using the cross-entropy function, and the Adam optimizer.
4. Result Comparison
Compared to other network models, GER-Unet exhibits better robustness, with all metrics outperforming those of other network models. The convergence speed is also faster than that of other network models.