This article summarizes the insights from Professor Xie Lei, head of the Audio, Speech, and Language Processing Laboratory (ASLP@NPU) at Northwestern Polytechnical University, during a public lecture at the Deep Blue Academy titled “New Developments and Trends in Intelligent Voice Technology – A NPU-ASLP Perspective.”

Hello everyone! Thank you for the invitation from the Deep Blue Academy! On behalf of the ASLP research group at Northwestern Polytechnical University, I would like to report some of our laboratory’s progress in intelligent voice technology, based on the research work of several students in our lab.
The study of human speech is a typical interdisciplinary field, involving numerous domains such as acoustics, auditory science, signal processing, phonetics, physiology, cognitive science, statistics, and machine learning. Speech processing primarily focuses on human speech as a research medium; in addition, the study of sound is very broad, including environmental sounds, music, etc., collectively referred to as auditory (audio) information processing. If we were to combine all individuals engaged in sound-related research, it would constitute a particularly large group, which I believe is no smaller than that in the computer vision (CV) field.
Regarding today’s topic—intelligent voice interaction—this mainly refers to the natural interaction between humans and machines through speech as a medium. From the speech interaction circle diagram, the core technologies involved include four main aspects: first, converting speech to text through Automatic Speech Recognition (ASR). If the quality of the speech signal is poor, there is a speech enhancement module at the front end; next is spoken language understanding, followed by dialogue management and spoken language generation, and finally, the generation of speech feedback to users through Text-to-Speech (TTS).
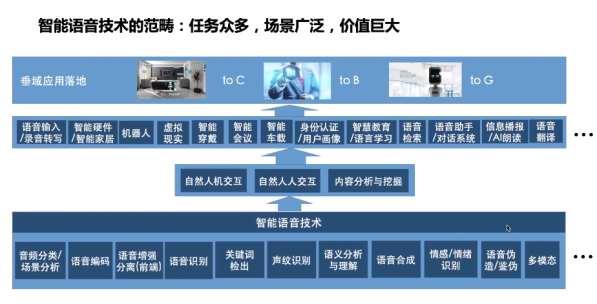
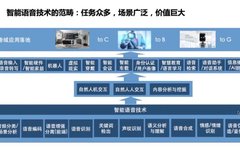
Scope of Intelligent Voice Technology
Looking back at the development of speech recognition, before 2000, there was a significant improvement in the error rate of speech recognition. However, between 2000 and 2010, it became increasingly difficult to further reduce the recognition error rate despite many efforts. After around 2010, driven by deep learning, the combination of big data, machine learning, and high computational power has led to another significant improvement in the accuracy of speech recognition, with the error rate dropping once again, achieving human-level accuracy on some datasets.
Speech recognition is a typical task within the realm of intelligent voice technology. In addition, intelligent voice tasks also include speech coding, speech enhancement, keyword detection, speaker recognition, and a series of other tasks. The directions that intelligent voice technology can serve mainly include three aspects: natural human-machine interaction, natural human-to-human interaction, and content analysis and mining. The vertical applications are numerous, with a wide range of scenarios and immense value.
There are many specific directions involved in intelligent voice technology, and next, I will introduce three key areas that our laboratory focuses on—speech enhancement, speech recognition, and speech synthesis.
Regarding speech enhancement, this is a very classic research topic, with the primary goal of reducing noise interference and improving speech quality. When picking up sound with a microphone, various issues arise, including attenuation due to distance, channel distortion, room reverberation, acoustic echoes, various noise interferences, and human voice interference. Traditional statistical signal processing-based speech enhancement can provide good steady noise suppression capabilities, while data-driven deep learning methods have made it possible to suppress non-stationary noise. The application of deep learning in speech enhancement can be roughly divided into three stages. The initial research focused on basic masking and regression paradigms, with relatively simple network structures aimed at modeling the amplitude spectrum, and the loss function primarily being Mean Squared Error (MSE).
In the second stage, researchers made bolder attempts, reflected in the diversification of network structures, including CRN, Tasnet, the use of Generative Adversarial Networks (GAN), and the recent Transformer structure; modeling also extended from the time-frequency domain to direct time-domain modeling; the loss functions became more diverse, including MSE, SI-SNR, and PESQ. Currently, AI noise reduction has begun to be applied in real-world scenarios, including TWS headphones and online meeting systems, where AI speech enhancement networks may have already been embedded in applications such as online meetings and live streaming backends. Furthermore, complex network forms and various more refined network structures have emerged. Additionally, there are personalized speech enhancement methods using speaker prior information, also known as target speaker extraction.
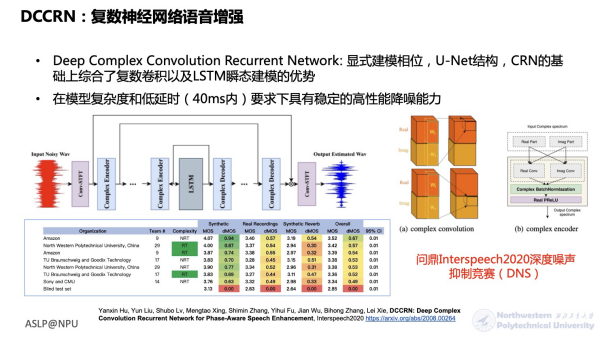
Speech Enhancement Based on DCCRN Complex Neural Network
Regarding speech enhancement, our laboratory’s team published the work on Deep Complex Convolution Recurrent Network (DCCRN) at last year’s Interspeech. DCCRN adopts the classic U-Net structure and integrates the advantages of complex convolution and LSTM transient modeling. It has high-performance noise reduction capabilities while meeting the requirements of model complexity and low latency (40ms). In last year’s Interspeech Deep Noise Suppression (DNS) competition, it achieved first place in the real-time track, and this paper has already been cited 100 times on Google Scholar. One issue with deep learning-based speech enhancement is the need to balance noise reduction and spectral fidelity.
This year, based on DCCRN, we proposed a complex enhancement network DCCRN+ that balances listening experience and noise reduction, achieving high noise reduction while enhancing speech fidelity. Its contributions mainly include: 1. a “learnable” subband division and merging to reduce model size and computational complexity; 2. simultaneous modeling of frequency domain and time domain sequences; 3. obtaining richer information from each layer of the encoder through “convolution channels”; 4. using signal-to-noise ratio estimation as an auxiliary task to enhance listening experience while reducing noise; 5. removing residual noise in post-processing.
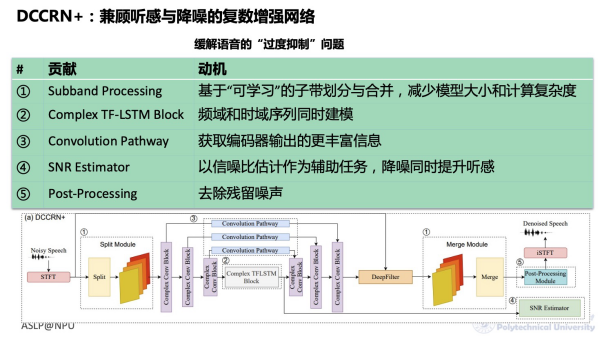
DCCRN+: A Complex Enhancement Network Balancing Speech Fidelity and Noise Reduction
People’s expectations for voice call experiences are increasing, such as higher sampling rates and even immersive meeting experiences with spatial awareness. Recently, based on DCCRN, we proposed an ultra-wideband speech enhancement model S-DCCRN to enhance noisy speech with a sampling rate of 32KHz. Its main contributions include:
1. First, using subband DCCRN to finely learn high and low-frequency information, then the full-band DCCRN combines high and low-frequency information to smooth the transition;
2. Simultaneously, the network learns to dynamically adjust the energy of different frequency bands;
3. While maintaining the same low-frequency resolution as the 16K noise reduction model, more information is obtained spectrally through complex feature encoding.
Since the launch of DCCRN last year, there have already been many extensions on this basis, including our own DCCRN+, S-DCCRN, and DesNet, which simultaneously performs demixing, noise reduction, and separation. Organizations like Alibaba and NTNU have also made multi-channel extensions. Notably, Microsoft has recently used DCCRN for personalized speech enhancement, namely target speaker enhancement, launching the pDCCRN scheme. In addition to the DCCRN series, we have recently introduced Uformer, based on complex and real Unet and convolution kernel dilation dual-path Conformer, which has even more powerful capabilities.
Next, we will discuss the development of deep learning speech enhancement. Currently, although AI-based noise reduction has seen some applications, in many scenarios, traditional signal processing solutions are still being used. When “AI noise reduction” is actually implemented, many finely designed models cannot leverage their advantages due to resource considerations. How to organically combine signal processing and deep learning is also worth deep exploration.
Moreover, the purpose of speech enhancement is not only for human listening but also to better serve downstream tasks, including speech recognition. However, the current situation is that deep learning speech enhancement provides limited improvements for speech recognition, and in some cases, it may even have adverse effects. This is because speech recognition has already considered the impact of noise through multi-scenario training strategies, and the end-to-end speech recognition model is very powerful. The speech recognition model trained on spectrally enhanced speech has not encountered the processed data before.
We can attempt to incorporate both enhanced and original data during the training process for joint training, or even perform joint modeling of the front and back ends. However, in practical use, we often wish to completely decouple the front and back ends and do not want joint training. Additionally, more detailed, comprehensive, and rapid data simulation schemes may also enhance the model’s post-training performance. Meanwhile, effectively utilizing prior information such as visual and speaker characteristics is also an important avenue for improving speech enhancement model performance. Recently, we have seen many beneficial explorations in this direction, with some starting to be implemented.
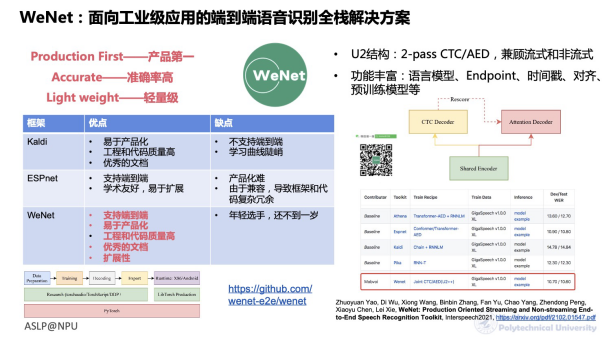
WeNet Speech Recognition Toolkit
Regarding speech recognition, end-to-end solutions have gained broader recognition in recent years. You can pay attention to our Cascade RNNT solution for addressing domain adaptation or poor recognition of proprietary terms, as well as our simplified Conformer computational complexity solution. Moreover, we released WeNet as a lightweight end-to-end speech recognition full-stack solution, with continuously enriched functionalities, including support for language models, endpoint detection, timestamp alignment, and support for pre-trained models, etc. Many peers from academia and industry are also expanding around it. Although speech recognition has already been implemented in various application fields, it cannot be said to be a completely solved problem, as practical application scenarios face various challenges. In summary, the challenges mainly include robustness, low resources, and complex scenarios. Typical robustness issues include accents, dialects, mixed languages or multilingualism, and domain adaptation; low resources refer to scenarios where the deployed system has limited resources and lacks labeled data. The former is typically seen in AIoT scenarios where various edge devices are deployed with constraints on model size and computational power, while the lack of labeled data is also a key factor limiting speech recognition’s expansion into various vertical domains and languages, as there are too many vertical domains and many minority languages lack labeled data; the scenarios faced during speech recognition deployment can be very complex, such as multi-person meetings, natural conversations, and various complex noise interferences. To address these issues, unsupervised self-learning, front-and-back-end integration, and speech-semantics integration provide possibilities.
Next, I will share our relevant work on command recognition deployed on the edge. One of the biggest issues encountered during edge deployment for command recognition is command confusion, such as controlling the air conditioning to “twenty-one degrees” may be misrecognized as “eleven degrees,” as the two commands sound very similar, and a faster speaking rate may lead to misrecognition. In response, we recently proposed the Minimize Sequential Confusion Error (MSCE) training criterion for the discriminative training of command recognition models. MSCE alleviates confusion word errors by increasing the distinguishability between commands. Although speech tasks themselves are sequence labeling tasks, command words can be considered as single classification tasks. For classification tasks, the MCE criterion can be used for discriminative training to increase inter-class distinguishability. Additionally, using the CTC criterion as a bridge from sequence to categories, we increase the distinguishability between commands based on this. Interested students can follow our subsequent published papers. Experiments show that MSCE reduces confusion errors by 14-18% in air conditioning command recognition tasks. The second work is about multi-speaker speech recognition, where we proposed a non-autoregressive multi-speaker speech recognition scheme based on speaker-conditioned chains, iteratively predicting each speaker’s output and modeling the dependencies between each output through speaker-conditioned chains. Each iteration uses Conformer-CTC for non-autoregressive parallel decoding. This scheme can handle different numbers of mixed speakers in speech. In dialogue speech recognition, effectively utilizing contextual information is a very intuitive idea. We attempted to model cross-sentence attention mechanisms by introducing residual attention encoders and conditional attention decoders into the Transformer, incorporating additional historical information, thus achieving better recognition results on datasets such as HKUST and Switchboard. Another working idea is to use semantics to “feedback” to speech by considering the uniqueness of dialogue speech, such as local coherence, role preferences, and speaker turn-taking, learning feature information in dialogues, with results on multiple representative datasets indicating the effectiveness of this approach.
Next, I will share several datasets we have open-sourced. The first is AISHELL-4, a Chinese conference scene corpus for speech enhancement, separation, recognition, and speaker logging, with approximately 120 hours of duration. Another is the AiMeeting 120-hour conference speech dataset. Both are multi-channel speech data recorded in real conference scenarios, particularly suitable for related research in meeting contexts. Based on these two corpora, we also initiated the M2MeT conference scene speech challenge at ICASSP2022, including speaker logging and multi-speaker speech recognition tasks, while providing corresponding baseline systems. Another recently open-sourced dataset is WenetSpeech, which is the world’s largest multi-domain Chinese speech recognition dataset. It was created by crawling rich Chinese speech data from the internet, with automated labeling and confidence filtering, ultimately obtaining over 10,000 hours of high-quality labeled data. The end-to-end speech recognition model trained using this data and the WeNet toolkit achieved industry-leading performance on the SpeechIO leaderboard.
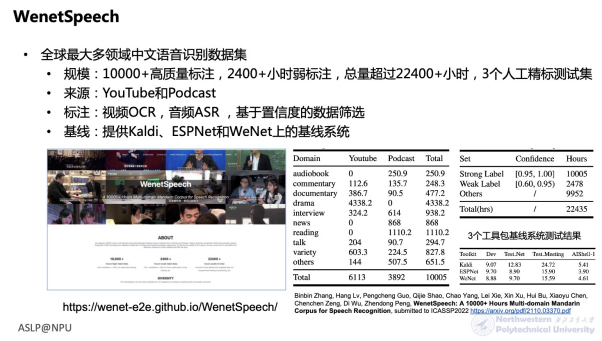
WenetSpeech: The World’s Largest Multi-Domain Chinese Speech Recognition Dataset
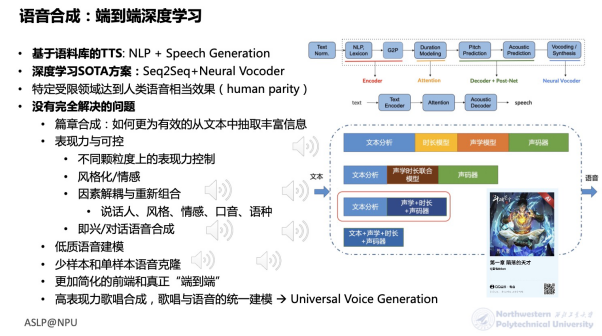
Finally, I would like to report on some of our explorations in the field of speech synthesis. Currently, solutions based on sequence-to-sequence models and neural vocoders have been widely cited, and even in some limited domains, they have achieved effects comparable to real human speech. However, we still have a long way to go to truly “replicate” human speech. For instance, challenges include paragraph synthesis, expressiveness and controllability, low-quality data modeling, few-shot and single-shot timbre cloning, fully end-to-end modeling, high-expressiveness singing synthesis, and how to unify speaking and singing into a single pronunciation model. In these aspects, our laboratory’s recent typical explorations are as follows. Controllable dialogue TTS—achieving human-like dialogue speech synthesis, even controlling the fluency of synthesized spoken dialogue.
MsEmoTTS is a multi-level emotional speech synthesis scheme we proposed recently, which can achieve emotional transfer, prediction, and control within a single model framework. Our “one person, a thousand faces” scheme effectively realizes style decoupling and crossover under the condition that each speaker has only one style of recording, for example, a reading-style speaker can read Tang poetry or serve as customer service. Finally, we made multiple improvements based on the VITS end-to-end TTS and proposed an end-to-end singing synthesis scheme, VISinger. Additionally, we will collaborate with companies like NetEase Fuxi to open-source a Chinese singing synthesis database in the Wenet open-source community, including around 100 Chinese pop songs from a professional singer with high-quality annotations, so stay tuned.
End-to-End Deep Learning-Based Speech Synthesis: Challenging Issues
Thank you all for your attention to the relevant papers published by our laboratory. This concludes my presentation today. Thank you! Click “Read the Original” for direct access to this public lecture.
Click “Read the Original” for direct access to this public lecture.