
Selected from Medium
Translated by Machine Heart
Contributors: Lu Xue, Li Zenan
Not long ago, Andrew Ng’s fourth course on Convolutional Neural Networks was released on Coursera. This article is a reflection written by Ryan Shrott, Chief Analyst at the National Bank of Canada, after completing the course, which helps everyone intuitively understand and learn about computer vision.

I recently completed Professor Andrew Ng’s course on computer vision on Coursera. Andrew Ng accurately explains many complex concepts that need to be understood to optimize computer vision tasks. My favorite part is the neural style transfer section (Lesson 11), where you can combine Monet’s painting style with any image you like to create your own artwork. An example is shown below:

In this article, I will discuss the 11 important lessons learned from the course. Note: This is the fourth lesson of the deep learning specialization released by deeplearning.ai. If you want to learn from the first three lessons, I recommend the following articles:
-
Getting Started | Insights from Andrew Ng’s Deeplearning.ai Course
-
Complete Experience of Andrew Ng’s Deeplearning.ai Course: Essential Courses for Deep Learning (Certificate Obtained)
Lesson 1: Why Computer Vision is Developing Rapidly
The development of big data and algorithms has caused the testing error of intelligent systems to converge to Bayesian optimal error. This allows AI to surpass human levels in many fields, including natural perception tasks. The open-source software TensorFlow allows you to implement object detection systems using transfer learning, enabling quick detection of any object. With transfer learning, you only need 100-500 samples to get the system to perform well. Manually labeling 100 samples is not a big workload, so you can quickly obtain a minimum viable product.
Lesson 2: How Convolution Works
Andrew Ng explains how to implement convolution operators and demonstrates how they detect edges in images. He also introduces other filters, such as the Sobel filter, which gives more weight to the center pixel of the edge. Andrew also mentions that the weights of filters should not be manually designed but should be learned using hill-climbing algorithms (like gradient descent).
Lesson 3: Why Use Convolutional Networks?
Regarding why convolutional networks perform so well in image recognition tasks, Andrew Ng provides several philosophical reasons. He introduces two specific reasons. First, parameter sharing: an effective feature detector in one part of the image may also be effective in another part. For example, an edge detector may be useful for many parts of an image. Parameter sharing requires fewer parameters and provides more robust translational invariance.
The second reason is the sparsity of connections: each output layer is just a function of a small number of inputs (specifically, the size of the filter). This greatly reduces the number of parameters in the network and speeds up training.
Lesson 4: Why Use Padding?
Padding is often used to ensure that the dimensions of the input and output tensors are the same during the convolution process. It also allows the frames near the edges of the image to contribute to the output as much as the frames near the center of the image.
Lesson 5: Why Use Max Pooling?
Empirical studies show that max pooling is very effective in convolutional neural networks. By downsampling the image, we can reduce the number of parameters and keep features invariant to changes in scale or direction.
Lesson 6: Classic Network Architectures
Andrew Ng presents three classic network architectures: LeNet-5, AlexNet, and VGG-16. His main idea is that the channel size of the layers in an efficient network continuously expands while the width and height decrease.
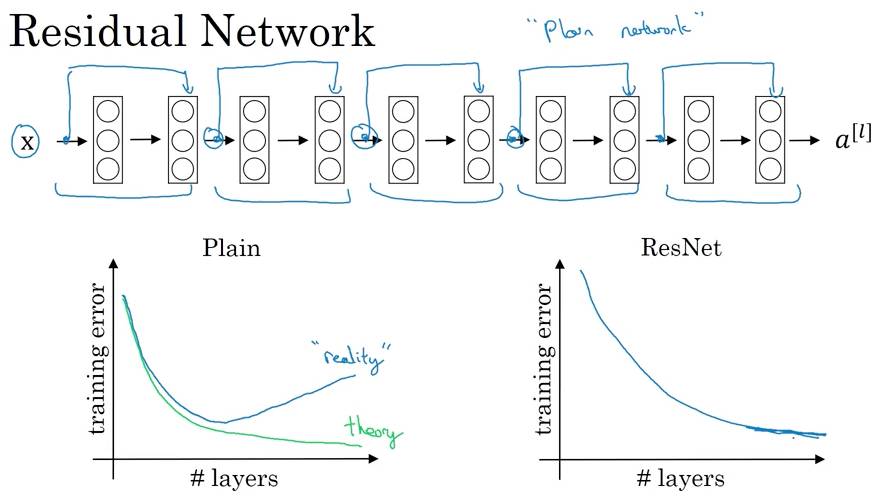
Lesson 7: Why are ResNets Effective?
For ordinary networks, due to gradient vanishing or explosion, the training error does not monotonically decrease as the number of layers increases. These networks have feed-forward skipped connections, allowing the training of large networks without performance degradation.
Lesson 8: How to Win in Computer Vision Competitions
Andrew Ng believes we should independently train several networks and average their output results to achieve better performance. Data augmentation techniques—such as random cropping of images, horizontal flipping, and vertical axis symmetry swapping—can also enhance model performance. Finally, you need to start with open-source implementations and pre-trained models, gradually tuning parameters for the target application.
Lesson 9: How to Implement Object Detection
Andrew Ng first explains how to perform keypoint detection in images. Essentially, these keypoints are far from the training output examples. Through some clever convolution operations, you will get some outputs showing the probability of the object in a specific area and the location of the object. He also explains how to use the Intersection-over-Union (IoU) formula to evaluate the effectiveness of object detection algorithms. Finally, Andrew Ng integrates all this content and introduces the well-known YOLO algorithm.

Lesson 10: How to Implement Face Recognition
Face recognition is a one-shot learning problem; usually, you only have one image to recognize a person. The solution is to learn a similarity function that gives the degree of difference between two images. So, if the images are of the same person, the function’s output value is small, while for different people, it is the opposite.
The first solution provided by Andrew Ng is called the Siamese network. This method inputs the images of two people into the same network and then compares their outputs. If the outputs are similar, they are the same person. The training goal of this neural network is to keep the encoding distance relatively small if the input images are of the same person.
The second solution he provides is the triplet loss method. The core idea is that the three dimensions of the images (Anchor (A), Positive (P), and Negative (N)) should have an output distance after training where A and P’s output distance is much smaller than A and N’s output distance.
Lesson 11: How to Create Artwork Using Neural Style Transfer
Andrew Ng explains in the course how to combine image content and style to generate new images. As shown below:

The key to neural style transfer is understanding the visual representations learned at each layer of the convolutional neural network. The earlier layers learn simple features like edges, while the later features learn complex objects like faces, feet, and cars.
To construct a neural style transfer image, you simply define a cost function that combines the similarities between the content image and the style image into a convex function. Specifically, this cost function can be expressed as:
J(G) = alpha * J_content(C,G) + beta * J_style(S,G)where G is the generated image, C is the content image, and S is the style image. The learning algorithm simply uses gradient descent to minimize the cost function related to the generated image G.
The steps are as follows:
1. Randomly generate G.
2. Use gradient descent to minimize J(G), that is, G := G-dG(J(G)).
3. Repeat step 2.
Conclusion
By completing this course, you will have an intuitive understanding of a large amount of literature on computer vision. The assignments in the course will also allow you to implement these methods hands-on. Although completing this course will not directly make you an expert in the field of computer vision, it may serve as a stepping stone for you to open up a new perspective or career in the field of computer vision. My GitHub link: https://github.com/ryanshrott.
Original link: https://towardsdatascience.com/computer-vision-by-andrew-ng-11-lessons-learned-7d05c18a6999
This article is translated by Machine Heart, please contact this public account for authorization.
✄————————————————
Join Machine Heart (Full-time Reporter/Intern): [email protected]
Submissions or Reporting Inquiries: [email protected]
Advertising & Business Cooperation: [email protected]