
Click on the above“Beginner’s Guide to Vision”, select to add “Bookmark” or “Pin”
Heavyweight content delivered at the first moment
This article is adapted from: Deep Learning Matters
void THPAutograd_initFunctions(){ THPObjectPtr module(PyModule_New("torch._C._functions")); ...... generated::initialize_autogenerated_functions(); auto c_module = THPObjectPtr(PyImport_ImportModule("torch._C"));}
static std::unordered_map<std::type_index, thpobjectptr=""> cpp_function_types
</std::type_index,>>>> gemfield = torch.empty([2,2],requires_grad=True)
>>> syszux = gemfield * gemfield
>>> syszux.grad_fn
<thmulbackward 0x7f111621c350="" at="" object="">
</thmulbackward>gemfield = torch.ones(2, 2, requires_grad=True)
syszux = gemfield + 2
civilnet = syszux * syszux * 3
gemfieldout = civilnet.mean()
gemfieldout.backward()
# Variable instance
gemfield --> grad_fn_ (Function instance) = None --> grad_accumulator_ (Function instance) = AccumulateGrad instance 0x55ca7f304500 --> output_nr_ = 0
# Function instance, 0x55ca7f872e90 AddBackward0 instance --> sequence_nr_ (uint64_t) = 0 --> next_edges_ (edge_list) --> std::vector<edge> = [(AccumulateGrad instance, 0), (0, 0)] --> input_metadata_ --> [(type, shape, device)...] = [(CPUFloatType, [2, 2], cpu)] --> alpha (Scalar) = 1 --> apply() --> uses AddBackward0's apply
# Variable instance syszux --> grad_fn_ (Function instance) = AddBackward0 instance 0x55ca7f872e90 --> output_nr_ = 0
# Function instance, 0x55ca7ebba2a0 MulBackward0 --> sequence_nr_ (uint64_t) = 1 --> next_edges_ (edge_list) = [(AddBackward0 instance 0x55ca7f872e90, 0), (AddBackward0 instance 0x55ca7f872e90, 0)] --> input_metadata_ --> [(type, shape, device)...] = [(CPUFloatType, [2, 2], cpu)] --> alpha (Scalar) = 1 --> apply() --> uses MulBackward0's apply
# Variable instance, syszux * syszux gets tmp --> grad_fn_ (Function instance) = MulBackward0 instance 0x55ca7ebba2a0 --> output_nr_ = 0
# Function instance, 0x55ca7fada2f0 MulBackward0 --> sequence_nr_ (uint64_t) = 2 (incremented within each thread) --> next_edges_ (edge_list) = [(MulBackward0 instance 0x55ca7ebba2a0, 0), (0, 0)] --> input_metadata_ --> [(type, shape, device)...] = [(CPUFloatType, [2, 2], cpu)] --> self_ (SavedVariable) = shallow copy of tmp --> other_ (SavedVariable) = shallow copy of 3 --> apply() --> uses MulBackward0's apply
# Variable instance civilnet --> grad_fn_ (Function instance) = MulBackward0 instance 0x55ca7fada2f0 -
# Function instance, 0x55ca7eb358b0 MeanBackward0 --> sequence_nr_ (uint64_t) = 3 (incremented within each thread) --> next_edges_ (edge_list) = [(MulBackward0 instance 0x55ca7fada2f0, 0)] --> input_metadata_ --> [(type, shape, device)...] = [(CPUFloatType|[]|cpu)] --> self_sizes (std::vector<int64_t>) = (2, 2) --> self_numel = 4 --> apply() --> uses MulBackward0's apply
# Variable instance gemfieldout --> grad_fn_ (Function instance) = MeanBackward0 instance 0x55ca7eb358b0 --> output_nr_ = 0
</int64_t></edge>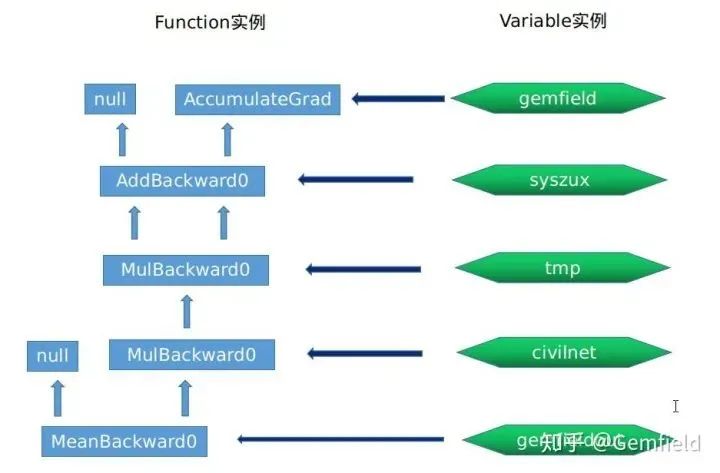
using edge_list = std::vector<edge>;
using variable_list = std::vector<variable>;
struct TORCH_API Function {... virtual variable_list apply(variable_list&& inputs) = 0;... const uint64_t sequence_nr_; edge_list next_edges_; PyObject* pyobj_ = nullptr; // weak reference std::unique_ptr<anomalymetadata> anomaly_metadata_ = nullptr; std::vector<std::unique_ptr<functionprehook>> pre_hooks_; std::vector<std::unique_ptr<functionposthook>> post_hooks_; at::SmallVector<inputmetadata, 2=""> input_metadata_;};
</inputmetadata,></std::unique_ptr<functionposthook></std::unique_ptr<functionprehook></anomalymetadata></variable></edge>variable_list operator()(variable_list&& inputs) {
return apply(std::move(inputs));
}
struct InputMetadata {... const at::Type* type_ = nullptr; at::DimVector shape_; at::Device device_ = at::kCPU;};
struct Edge {... std::shared_ptr<function> function; uint32_t input_nr;};
</function>CopySlices : public Function
DelayedError : public Function
Error : public Function
Gather : public Function
GraphRoot : public Function
Scatter : public Function
AccumulateGrad : public Function
AliasBackward : public Function
AsStridedBackward : public Function
CopyBackwards : public Function
DiagonalBackward : public Function
ExpandBackward : public Function
IndicesBackward0 : public Function
IndicesBackward1 : public Function
PermuteBackward : public Function
SelectBackward : public Function
SliceBackward : public Function
SqueezeBackward0 : public Function
SqueezeBackward1 : public Function
TBackward : public Function
TransposeBackward0 : public Function
UnbindBackward : public Function
UnfoldBackward : public Function
UnsqueezeBackward0 : public Function
ValuesBackward0 : public Function
ValuesBackward1 : public Function
ViewBackward : public Function
struct AccumulateGrad : public Function { explicit AccumulateGrad(Variable variable_); variable_list apply(variable_list&& grads) override; Variable variable;};
struct GraphRoot : public Function { GraphRoot(edge_list functions, variable_list inputs) : Function(std::move(functions)), outputs(std::move(inputs)) {} variable_list apply(variable_list&& inputs) override { return outputs; } variable_list outputs;};
struct TraceableFunction : public Function {
using Function::Function;
bool is_traceable() final {
return true;
}
};
AbsBackward : public TraceableFunction
AcosBackward : public TraceableFunction
AdaptiveAvgPool2DBackward : public TraceableFunction
AdaptiveAvgPool2DBackward : public TraceableFunction
AdaptiveAvgPool3DBackward : public TraceableFunction
AdaptiveAvgPool3DBackward : public TraceableFunction
AdaptiveMaxPool2DBackward : public TraceableFunction
AdaptiveMaxPool2DBackward : public TraceableFunction
AdaptiveMaxPool3DBackward : public TraceableFunction
AdaptiveMaxPool3DBackward : public TraceableFunction
AddBackward0 : public TraceableFunction
AddBackward1 : public TraceableFunction
AddbmmBackward : public TraceableFunction
AddcdivBackward : public TraceableFunction
AddcmulBackward : public TraceableFunction
AddmmBackward : public TraceableFunction
AddmvBackward : public TraceableFunction
AddrBackward : public TraceableFunction
......
struct AddBackward0 : public TraceableFunction { using TraceableFunction::TraceableFunction; variable_list apply(variable_list&& grads) override; Scalar alpha;};
gemfield = torch.ones(2, 2, requires_grad=True)
syszux = gemfield + 2
civilnet = syszux * syszux * 3
gemfieldout = civilnet.mean()
gemfieldout.backward()
struct Engine { using ready_queue_type = std::deque<std::pair<std::shared_ptr<function>, InputBuffer>>; using dependencies_type = std::unordered_map<function*, int="">; virtual variable_list execute(const edge_list&& roots,const variable_list&& inputs,...const edge_list&& outputs = {}); void queue_callback(std::function<void()> callback);protected: void compute_dependencies(Function* root, GraphTask& task); void evaluate_function(FunctionTask& task); void start_threads(); virtual void thread_init(int device); virtual void thread_main(GraphTask *graph_task); std::vector<std::shared_ptr<readyqueue>> ready_queues;};
</std::shared_ptr<readyqueue></void()></function*,></std::pair<std::shared_ptr<function>struct PythonEngine : public Engine
#torch/tensor.py,self is gemfieldout
def backward(self, gradient=None, retain_graph=None, create_graph=False)|V#torch.autograd.backward(self, gradient, retain_graph, create_graph)
#torch/autograd/__init__.py
def backward(tensors, grad_tensors=None, retain_graph=None, create_graph=False, grad_variables=None)|VVariable._execution_engine.run_backward(tensors, grad_tensors, retain_graph, create_graph,allow_unreachable=True)
#transform to Variable._execution_engine.run_backward((gemfieldout,), (tensor(1.),), False, False,True)|V#torch/csrc/autograd/python_engine.cpp
PyObject *THPEngine_run_backward(THPEngine *self, PyObject *args, PyObject *kwargs)|V#torch/csrc/autograd/python_engine.cpp
variable_list PythonEngine::execute(const edge_list&& roots, const variable_list&& inputs, bool keep_graph, bool create_graph, const edge_list&& outputs)|V#torch/csrc/autograd/engine.cpp
Conclusion
Good news!
Beginner's Guide to Vision Knowledge Planet
is now open to the public👇👇👇
Download 1: OpenCV-Contrib Extension Module Chinese Version Tutorial
Reply "Extension Module Chinese Tutorial" in the background of the "Beginner's Guide to Vision" WeChat public account to download the first OpenCV extension module tutorial in Chinese available online, covering installation of extension modules, SFM algorithms, stereo vision, object tracking, biological vision, super-resolution processing, and more than twenty chapters.
Download 2: Python Vision Practical Project 52 Lectures
Reply "Python Vision Practical Project" in the background of the "Beginner's Guide to Vision" WeChat public account to download 31 practical vision projects, including image segmentation, mask detection, lane line detection, vehicle counting, eye line addition, license plate recognition, character recognition, emotion detection, text content extraction, facial recognition, etc., to assist in quickly learning computer vision.
Download 3: OpenCV Practical Project 20 Lectures
Reply "OpenCV Practical Project 20 Lectures" in the background of the "Beginner's Guide to Vision" WeChat public account to download 20 practical projects based on OpenCV, achieving advanced learning of OpenCV.
Discussion Group
You are welcome to join the reader group of the public account to communicate with peers. Currently, there are WeChat groups for SLAM, 3D vision, sensors, autonomous driving, computational photography, detection, segmentation, recognition, medical imaging, GAN, algorithm competitions, etc. (these will gradually be subdivided). Please scan the WeChat ID below to join the group, and note: "Nickname + School/Company + Research Direction", for example: "Zhang San + Shanghai Jiao Tong University + Vision SLAM". Please follow the format, otherwise, you will not be approved. After successful addition, you will be invited into relevant WeChat groups based on research direction. Please do not send advertisements in the group, or you will be removed. Thank you for your understanding~