
Source: New Intelligence
Author: krish
This article is 5000 words long and is recommended for a reading time of 10+ minutes.
This article introduces some of the latest innovations from Kaiming He, Tsung-Yi Lin, and their team at FAIR in the field of computer vision, including Feature Pyramid Networks, RetinaNet, Mask R-CNN, and weakly supervised methods for instance segmentation.
Feature Pyramid Networks
Let’s start with the now-famous Feature Pyramid Networks (FPN) [1], a paper presented at CVPR 2017, authored by Tsung-Yi Lin, Kaiming He, and others. The FPN paper is truly excellent. Building a benchmark model that everyone can use across various tasks, sub-topics, and application domains is not easy. One point we need to understand before diving deeper is: FPN is an add-on component to general feature extraction networks like ResNet or DenseNet. You can obtain the desired pre-trained FPN model from your favorite DL library and use it just like other pre-trained models.
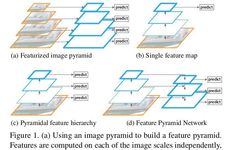
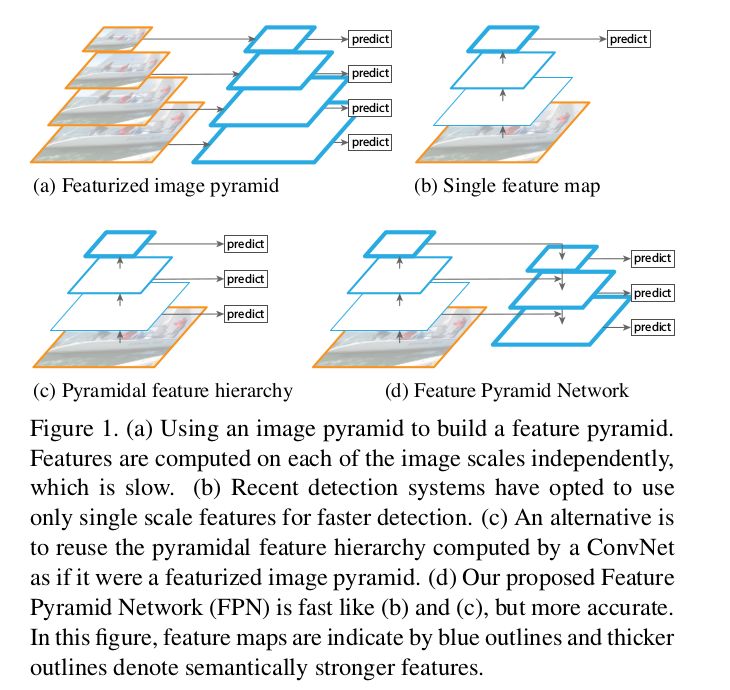
Objects appear at different scales and sizes. Datasets cannot capture all this data. Therefore, an image pyramid (multiple scaled-down versions of an image) can be used to make CNN processing easier. However, this is too slow. So, people only use a single scale prediction, and predictions can also be made from intermediate layers. This is somewhat similar to the previous method, but it’s done in the feature space. For example, placing a Deconv after several ResNet blocks to obtain segmentation output (classification can also be similar, using a 1×1 Conv and GlobalPool).
The authors of FPN found a clever way to improve upon the aforementioned method. Instead of merely having lateral connections, they also placed a top-down pathway above it. This makes a lot of sense! They use a simple MergeLayer (mode = ‘addition’) to combine the two. A key point of this idea is that the features from lower layers (like the initial conv layers) contain less semantic information, which is not enough for classification. However, deeper features can be used for understanding. Here, you can also leverage all top-down pathway FMaps (feature maps) to understand it, just like the deepest layers. This is formed by the combination of lateral connections and top-down connections.
Some details from the FPN paper:
-
Pyramid: refers to all outputs of the same size belonging to one stage. The output of the last layer is the reference FMaps of the pyramid. For example: ResNet – outputs from the 2nd, 3rd, 4th, and 5th blocks. Depending on memory availability and specific tasks, you can modify the pyramid as needed.
-
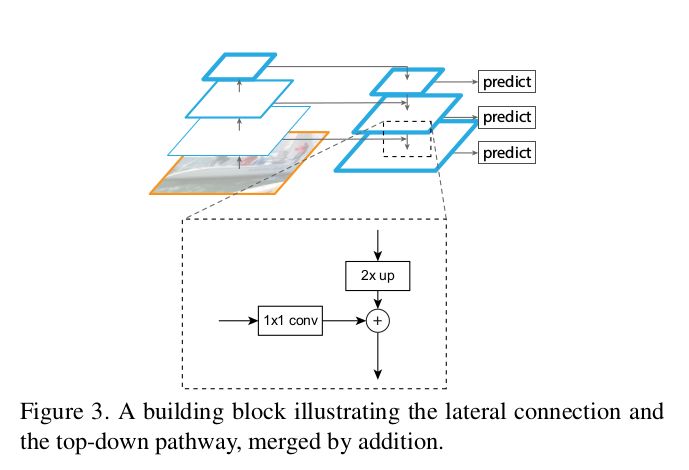
Lateral connection: 1×1 Conv and Top-Down pathway are 2x upsampling. This idea comes from the top features while producing coarse features downwards, and lateral connections add finer details from the bottom-up path. As shown in the figure below.
-
This paper only describes a simple demo. It merely showcases that this idea performs very well in simple design choices, and you can make it larger and more complex.
As I mentioned earlier, this is a foundational network that can be used for any task, including object detection, segmentation, pose estimation, face detection, and more. Within months of the paper’s release, it had already received over 100 citations! The paper is titled FPNs for Object Detection, so the authors continued to use FPN as the baseline for RPN (Region Proposal Network) and Faster-RCNN networks. More key details are comprehensively explained in the paper, here we only list a part.
Some key points from the experiments:
-
FPN for RPN: Replace single-scale FMaps with FPN. They have a single-scale anchor for each level (no need for multi-level as its FPN). They also show that all levels of the pyramid have similar semantic hierarchies.
-
Faster RCNN: They observe the pyramid in a way similar to the image pyramid output. Therefore, the following formula is used to assign RoI to a specific level.
-
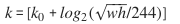
-
Where w and h represent width and height respectively. k is the level assigned to RoI.
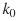 is the level mapped when w,h=224,224.
is the level mapped when w,h=224,224. -
They conducted ablation experiments on each module to verify the claims made at the beginning of the paper.
-
They also demonstrated how to use FPN for segmentation proposal generation based on the papers DeepMask and SharpMask.
Code:
-
Official:Caffe2
https://github.com/facebookresearch/Detectron/tree/master/configs/12_2017_baselines
-
Caffe
https://github.com/unsky/FPN
-
PyTorch
https://github.com/kuangliu/pytorch-fpn (just the network)
-
MXNet
https://github.com/unsky/FPN-mxnet
-
Tensorflow
https://github.com/yangxue0827/FPN_Tensorflow
RetinaNet – Focal Loss Function for Dense Object Detection
RetinaNet comes from the same team as FPN, and the first author is also Tsung-Yi Lin. This paper was published at ICCV 2017 and won the Best Student Paper that year.
This paper has two key ideas – the loss function called Focal Loss (FL) and a single-stage object detection network called RetinaNet. This network performs exceptionally well on the COCO object detection task, also surpassing the previous FPN benchmark.
Focal Loss:
Focal Loss is a clever and simple idea! If you are already familiar with weighted loss, this is essentially the same as weighted loss but with smarter weights that focus more attention on classifying difficult samples. The formula is as follows:
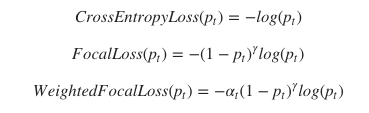
Where γ is a tunable hyperparameter.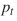 is the probability of a sample from the classifier. If γ is greater than 0, it reduces the weight of samples in the classification number.
is the probability of a sample from the classifier. If γ is greater than 0, it reduces the weight of samples in the classification number.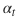 is the class weight in the normal weighted loss function. In the paper, it is represented as α-balanced loss. It is important to note that this is the classification loss and is combined with the smooth L1 loss in the object detection task of RetinaNet.
is the class weight in the normal weighted loss function. In the paper, it is represented as α-balanced loss. It is important to note that this is the classification loss and is combined with the smooth L1 loss in the object detection task of RetinaNet.
RetinaNet:
FAIR’s release of this single-stage detection network is quite surprising. Until now, the dominant single-stage object detectors are still YOLOv2 and SSD. However, as the authors point out, neither of these networks has been able to get very close to the SOTA methods. RetinaNet has achieved this while being one-stage and fast. The authors believe the best results are due to the new loss rather than a simple network (which has an FPN as its backend). The one-stage detector faces a lot of imbalance between the background and positive classes (rather than within positive classes). They argue that weighted loss functions only address balance, but FL addresses simple/difficult samples while also indicating that both can be combined.
Code:
-
Official Caffe2
https://github.com/facebookresearch/Detectron/tree/master/configs/12_2017_baselines
-
PyTorch
https://github.com/kuangliu/pytorch-retinanet
-
Keras
https://github.com/fizyr/keras-retinanet
-
MXNet
https://github.com/unsky/RetinaNet
Mask R-CNN
Again, Mask R-CNN also comes from Kaiming He’s team at FAIR, with the paper published at ICCV 2017. Mask R-CNN is used for instance segmentation. Simply put, instance segmentation is basically object detection, but instead of using bounding boxes, its task is to provide an accurate segmentation map of the objects!
TL;DR: If you are already familiar with Faster R-CNN, then Mask R-CNN is easy to understand; it simply adds another head (branch) for segmentation. So it has three branches, for classification, bounding box regression, and segmentation.
The following explanation assumes you have some knowledge of Faster R-CNN:
-
Mask R-CNN is similar to Faster R-CNN, which is two-stage, where the first stage is RPN.
-
Add a parallel branch that predicts segmentation masks – this is an FCN.
-
The loss is
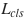 ,
, 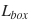 and
and 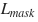 .
. -
Use ROIPool instead of ROIPool. This will not round the (x / spatial_scale) scores to integers like ROIPool does; instead, it performs bilinear interpolation to find pixels at those floating-point values.
-
For example: imagine an ROI with height and width of 54, 167. The spatial scale is essentially the image size / FMap size (H / h), in this case also referred to as stride. Typically 224/14 = 16 (H = 224, h = 14).
◦ ROIPool: 54/16, 167/16 = 3,10
◦ ROIAlign: 54/16, 167/16 = 3.375, 10.4375
◦ Now we can use bilinear interpolation for upsampling.
◦ Depending on the ROIAlign output shape (e.g., 7×7), similar logic will divide the corresponding area into appropriate bins.
◦ If interested, you can check out the python implementation of ROIPooling in Chainer and try to implement ROIAlign yourself.
◦ ROIAlign code is available in various libraries, please check the code repositories provided below.
-
Its backbone is ResNet-FPN
Code:
-
Official Caffe2
https://github.com/facebookresearch/Detectron/tree/master/configs/12_2017_baselines
-
Keras
https://github.com/matterport/Mask_RCNN/
-
PyTorch
https://github.com/soeaver/Pytorch_Mask_RCNN/
-
MXNet
https://github.com/TuSimple/mx-maskrcnn
Learning to Segment Everything
As the name suggests, this paper is about segmentation. More specifically, it is about instance segmentation. The standard datasets used for segmentation in computer vision are very limited and insufficient for real-world problems. Even by 2018, the COCO dataset created in 2015 remains the most popular and richest dataset, despite having only 80 object categories.
In contrast, datasets for object recognition and detection (e.g., OpenImages [8]) have 6000 categories for classification tasks and 545 categories for detection. That said, Stanford University also has another dataset called Visual Genome, which contains 3000 object categories! So, why not use this dataset? Because the number of images per category is too small, DNNs do not really work well on this dataset, so even though it is richer, people do not use it. Moreover, this dataset has no segmentation annotations, only bounding box labels for object detection across 3000 categories.
Now, back to the paper Learning to Segment Everything. In fact, bounding boxes and segmentation annotations do not differ much for the domain; the latter is just more precise than the former. Therefore, since the Visual Genome dataset has 3000 classes, why not leverage this dataset for instance segmentation? The FAIR team led by Kaiming He did just that. This can be referred to as weak supervision (or weak semi-supervision?), meaning you cannot fully supervise the task you want to achieve. It can also be associated with semi-supervision since they both use the COCO + Visual Genome dataset. This paper is the coolest so far.
-
It is built upon Mask-RCNN
-
Trained simultaneously on inputs with and without mask annotations
-
Add a weight transfer function between the mask and bbox mask
-
When inputs without mask annotations pass through, the wseg prediction will multiply with the weights of the features; when inputs with mask annotations pass through, this function is not used, instead, a simple MLP is employed.
-
As shown in the figure below. A is the COCO dataset, B is VG. Note the two different paths for different inputs.
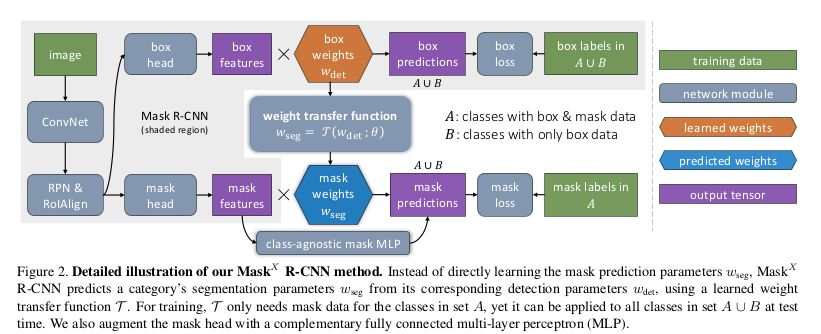
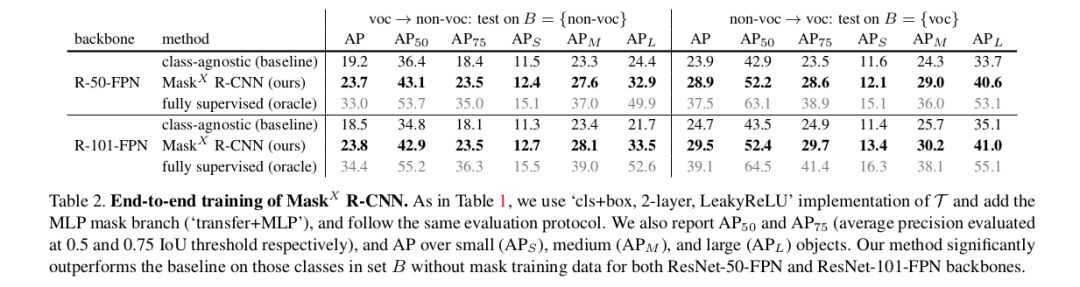
Due to the lack of annotations available, the authors could not show accuracy on the VG dataset, so they applied this idea to datasets where results can be proven. PASCAL-VOC has 20 categories, and these categories are very common in COCO. Therefore, they trained using VOC classification labels and only used bbox labels from COCO for these 20 categories. The results are shown in the instance segmentation task on 20 classes in the COCO dataset. Conversely, since both datasets have ground truth. The results are shown in the table below:
References:
[1] Lin, Tsung-Yi, Piotr Dollár, Ross B. Girshick, Kaiming He, Bharath Hariharan, and Serge J. Belongie. “Feature Pyramid Networks for Object Detection.” *2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR)* (2017): 936-944.
[2] Lin, Tsung-Yi, Priya Goyal, Ross B. Girshick, Kaiming He, and Piotr Dollár. “Focal Loss for Dense Object Detection.” *2017 IEEE International Conference on Computer Vision (ICCV)* (2017): 2999-3007.
[3] He, Kaiming, Georgia Gkioxari, Piotr Dollár, and Ross B. Girshick. “Mask R-CNN.” *2017 IEEE International Conference on Computer Vision (ICCV)* (2017): 2980-2988.
[4] Hu, Ronghang, Piotr Dollár, Kaiming He, Trevor Darrell, and Ross B. Girshick. “Learning to Segment Every Thing.” *CoRR* abs/1711.10370 (2017): n. pag.
[5] Ren, Shaoqing, Kaiming He, Ross B. Girshick, and Jian Sun. “Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks.” *IEEE Transactions on Pattern Analysis and Machine Intelligence* 39 (2015): 1137-1149.
[6] Chollet, François. “Xception: Deep Learning with Depthwise Separable Convolutions.” 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2017): 1800-1807.
[7] Lin, Tsung-Yi, Michael Maire, Serge J. Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C. Lawrence Zitnick. “Microsoft COCO: Common Objects in Context.” ECCV (2014).
[8] Krasin, Ivan, Duerig, Tom, Alldrin, Neil, Ferrari, Vittorio et al. OpenImages: A public dataset for large-scale multi-label and multi-class image classification. Dataset available from https://github.com/openimages
[9] Krishna, Ranjay, Congcong Li, Oliver Groth, Justin Johnson, Kenji Hata, Joshua Kravitz, Stephanie Chen, Yannis Kalantidis, David A. Shamma, Michael S. Bernstein, and Li Fei-Fei. “Visual Genome: Connecting Language and Vision Using Crowdsourced Dense Image Annotations.” International Journal of Computer Vision 123 (2016): 32-73.
Original text:
https://skrish13.github.io/articles/2018-03/fair-cv-saga
