Recently, OpenAI’s release of ChatGPT has injected a shot of adrenaline into the field of artificial intelligence, its powerful capabilities far exceeding the expectations of natural language processing researchers.
Users who have experienced ChatGPT naturally raise the question: How did the original GPT-3 evolve into ChatGPT? Where does GPT-3.5’s astonishing language ability come from?
Recently, researchers from the Allen Institute for Artificial Intelligence authored a paper attempting to dissect the emergent abilities of ChatGPT and trace the origins of these capabilities, providing a comprehensive technical roadmap to illustrate how the GPT-3.5 model series and related large language models have evolved into their current powerful forms.

Author Fu Yao is a Ph.D. student at the University of Edinburgh since 2020, having graduated with a master’s from Columbia University and a bachelor’s from Peking University. He is currently a research intern at the Allen Institute for Artificial Intelligence, focusing on large-scale probabilistic generation models of human language.
Author Peng Hao graduated with a bachelor’s from Peking University and obtained his Ph.D. from the University of Washington. He is currently a Young Investigator at the Allen Institute for Artificial Intelligence and will join the Department of Computer Science at the University of Illinois Urbana-Champaign as an assistant professor in August 2023. His main research focuses on making language AI more efficient and understandable, as well as building large-scale language models.
Author Tushar Khot received his Ph.D. from the University of Wisconsin-Madison and is currently a research scientist at the Allen Institute for Artificial Intelligence. His main research area is structured machine reasoning.
1. The Original GPT-3 of 2020 and Large-Scale Pre-Training
1. The Original GPT-3 of 2020 and Large-Scale Pre-Training
The original GPT-3 demonstrated three important capabilities:
-
Language Generation: Following prompts and generating sentences that complete the prompts. This is also the most common interaction method between humans and language models today.
-
In-Context Learning: Following several examples of a given task and then generating solutions for new test cases. Importantly, although GPT-3 is a language model, its paper hardly mentions “language modeling” — the authors devoted all their writing energy to the vision of in-context learning, which is the true focus of GPT-3.
-
World Knowledge: Including factual knowledge and commonsense.
-
The ability for language generation comes from the training objective of language modeling.
-
World knowledge comes from the 300 billion words of training corpus (where else could it come from?).
-
The model’s 175 billion parameters are to store knowledge, as further evidenced by Liang et al. (2022). Their conclusion is that the performance on knowledge-intensive tasks is closely related to the model size.
-
The sources of the ability for in-context learning and why it can generalize remain difficult to trace. Intuitively, this ability may arise from data points of the same task being sequentially arranged in the same batch during training. However, few have investigated why pre-training language models promotes in-context learning and why the behavior of in-context learning is so different from fine-tuning.
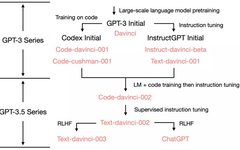
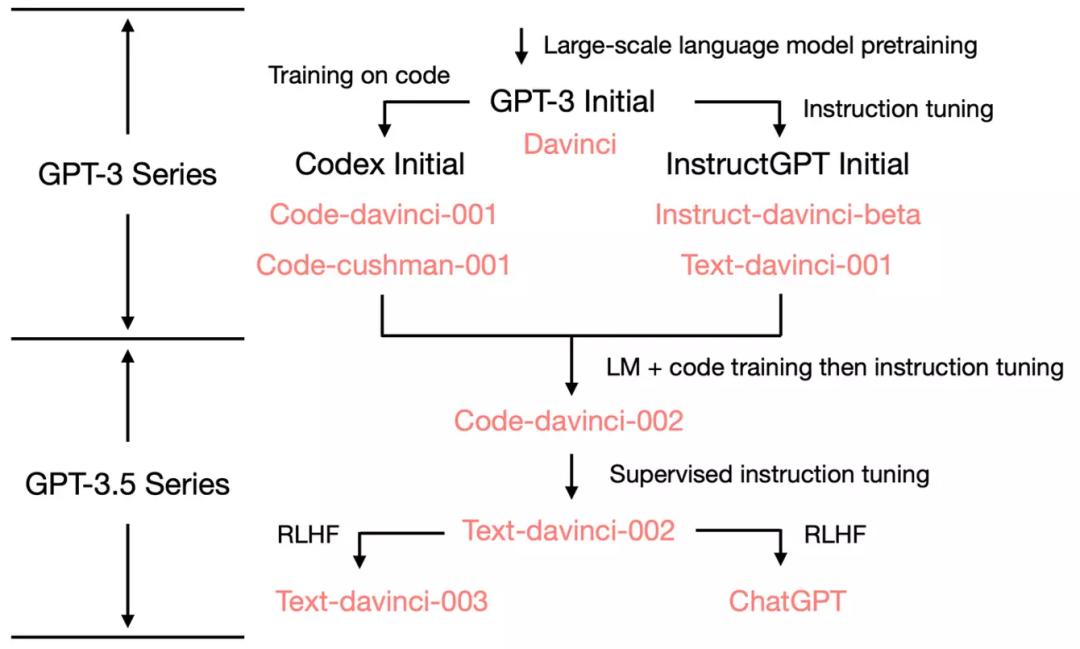
2. From GPT-3 of 2020 to ChatGPT of 2022
2. From GPT-3 of 2020 to ChatGPT of 2022
-
Instruction tuning does not inject new capabilities into the model — all capabilities already existed. The role of instruction tuning is to unlock/stimulate these capabilities. This is mainly because the amount of data for instruction tuning is several orders of magnitude smaller than that of pre-training (the foundational capabilities are injected through pre-training).
-
Instruction tuning differentiates GPT-3.5 into different skill trees. Some are better at in-context learning, like text-davinci-003, while others are better at conversation, like ChatGPT.
-
Instruction tuning aligns performance with human expectations at the expense of performance (alignment tax). OpenAI’s authors referred to this as “alignment tax” in their instruction tuning paper. Many papers have reported that code-davinci-002 achieved the best performance in benchmark tests (but the model may not necessarily align with human expectations). After instruction tuning on code-davinci-002, the model can generate feedback that is more aligned with human expectations (or say, aligned with human), such as zero-shot question answering, generating safe and fair dialogue responses, and refusing questions beyond the model’s knowledge range.
3. Code-Davinci-002 and Text-Davinci-002, Trained on Code and Fine-Tuned on Instructions
3. Code-Davinci-002 and Text-Davinci-002, Trained on Code and Fine-Tuned on Instructions
3.1 Sources of Complex Reasoning Abilities and Generalization to New Tasks
-
Responding to Human Instructions: Previously, GPT-3’s outputs were mainly common sentences found in the training set. Now, the models generate more reasonable answers for instructions/prompts (rather than relevant but useless sentences).
-
Generalization to Unseen Tasks: When the number of instructions used to adjust the model exceeds a certain scale, the model can automatically generate valid responses to new instructions it has never seen. This capability is crucial for deployment, as users will always pose new questions, and the model must be able to answer them.
-
Code Generation and Understanding: This ability is obvious because the model has been trained on code.
-
Using Chain-of-Thought for Complex Reasoning: The original GPT-3 had weak or no abilities for chain-of-thought reasoning. Code-davinci-002 and text-davinci-002 are two models with sufficiently strong chain-of-thought reasoning capabilities. -
Chain-of-thought reasoning is important because it may be the key to unlocking emergent abilities and surpassing scaling laws.
-
The ability to respond to human instructions is a direct product of instruction tuning.
-
The generalization ability to unseen instructions emerges automatically after the number of instructions exceeds a certain threshold, as further demonstrated by the T0, Flan, and FlanPaLM papers.
-
The ability to perform complex reasoning using chain-of-thought is likely a magical byproduct of code training. For this, we have the following facts as some support:
-
The original GPT-3 had no code training; it could not perform chain-of-thought reasoning.
-
The text-davinci-001 model, although fine-tuned with instructions, had very weak chain-of-thought reasoning abilities as reported in the first chain-of-thought paper — thus, instruction tuning may not be the reason for the existence of chain-of-thought, and code training is the most likely reason for the model’s ability to perform chain-of-thought reasoning.
-
PaLM has 5% of its training data as code and can perform chain-of-thought.
-
The Codex paper stated that the code data volume was 159G, about 28% of the 570 billion training data of the original GPT-3. Code-davinci-002 and its subsequent variants can perform chain-of-thought reasoning.
-
In the HELM tests, Liang et al. (2022) conducted large-scale evaluations of different models. They found that models trained on code had strong language reasoning abilities, including the 12 billion parameter code-cushman-001.
-
Our work at AI2 also shows that when equipped with complex chain-of-thought, code-davinci-002 performs best on important mathematical benchmarks like GSM8K.
-
Intuitively, procedure-oriented programming is quite similar to the human process of solving tasks step-by-step, while object-oriented programming resembles the human process of breaking down complex tasks into simpler ones.
-
All of the above observations are correlations between code and reasoning abilities/chain-of-thought, but they do not necessarily imply causation. This correlation is interesting, yet remains an open question for further research. Currently, we do not have very conclusive evidence to prove that code is the reason for chain-of-thought and complex reasoning.
-
Additionally, another possible byproduct of code training is long-distance dependencies, as Peter Liu pointed out: “Next word prediction in language is often very local, whereas code often requires longer dependencies to do things, like matching parentheses or referencing distant function definitions.”
I would like to further add that due to class inheritance in object-oriented programming, code may also help the model build encoding hierarchies. We will leave the testing of this hypothesis for future work.
-
Text-davinci-002 vs. Code-davinci-002
-
Code-davinci-002 is the base model, while text-davinci-002 is the product of instruction tuning code-davinci-002 (see OpenAI’s documentation). It was fine-tuned on the following data: (1) human-annotated instructions and expected outputs; (2) model outputs selected by human annotators.
-
When there are in-context examples, Code-davinci-002 is better at in-context learning; when there are no in-context examples/zero-shot, text-davinci-002 performs better on zero-shot tasks. In this sense, text-davinci-002 aligns more with human expectations (as writing in-context examples for a task can be cumbersome).
-
OpenAI is unlikely to have intentionally sacrificed in-context learning abilities for zero-shot capabilities — the reduction in in-context learning ability is more a side effect of instruction learning, which OpenAI refers to as alignment tax.
-
Model 001 (code-cushman-001 and text-davinci-001) vs. Model 002 (code-davinci-002 and text-davinci-002)
-
Model 001 was primarily designed for pure code/pure text tasks; Model 002 deeply integrates code training and instruction tuning, capable of handling both code and text.
-
Code-davinci-002 may be the first model to deeply integrate code training and instruction tuning. Evidence includes: code-cushman-001 can perform reasoning but does poorly on pure text, while text-davinci-001 performs well on pure text but struggles with reasoning. Code-davinci-002 can achieve both.
3.2 Do These Abilities Exist After Pre-Training or Are They Injected Later Through Fine-Tuning?
-
The base model of code-davinci-002 may not be the original GPT-3 davinci model.
-
The original GPT-3 was trained on the C4 dataset from 2016 to 2019, while the training set for code-davinci-002 was extended until 2021. Therefore, code-davinci-002 may have been trained on the 2019-2021 version of C4.
-
The original GPT-3 had a context window size of 2048 tokens. The context window of code-davinci-002 is 8192. The GPT series uses absolute positional embedding, and extrapolating absolute positional embeddings without training is quite difficult and would severely impair the model’s performance (refer to Press et al., 2022). If code-davinci-002 is based on the original GPT-3, how did OpenAI extend the context window?
-
On the other hand, whether the base model is the original GPT-3 or a later-trained model, the abilities to follow instructions and zero-shot generalization may have existed in the base model and were later unlocked through instruction tuning (rather than injected).
-
This is mainly because OpenAI’s papers report that the size of instruction data is only 77K, several orders of magnitude smaller than pre-training data.
-
Other instruction tuning papers further demonstrate the performance comparison of dataset sizes, for example, in the work of Chung et al. (2022), Flan-PaLM’s instruction tuning was only 0.4% of pre-training computation. Generally, instruction data is significantly less than pre-training data.
-
However, the model’s complex reasoning abilities may have been injected during the pre-training stage through code data.
-
The scale of the code dataset differs from the aforementioned instruction tuning situation. Here, the volume of code data is sufficiently large to constitute a significant portion of the training data (e.g., PaLM has 8% of its training data as code).
-
As mentioned, the previous model, text-davinci-001, likely did not undergo fine-tuning on code data, which is why its reasoning/chain-of-thought abilities were very poor, as reported in the first chain-of-thought paper, sometimes even worse than the smaller code-cushman-001.
-
The best method to distinguish the effects of code training and instruction tuning may be to compare code-cushman-001, T5, and FlanT5.
-
Because they have similar model sizes (11 billion and 12 billion), similar training datasets (C4), their biggest difference is whether they have been trained on code/done instruction tuning.
-
Currently, there is no such comparison. We leave this for future research.
4. Text-Davinci-003 and ChatGPT, The Power of Reinforcement Learning from Human Feedback (RLHF)
4. Text-Davinci-003 and ChatGPT, The Power of Reinforcement Learning from Human Feedback (RLHF)
-
Text-davinci-003 and ChatGPT were released less than a month before this article was written.
-
ChatGPT cannot be called through the OpenAI API, so testing it on standard benchmarks is quite troublesome.
-
All three models underwent instruction tuning.
-
Text-davinci-002 is a model that has undergone supervised instruction tuning.
-
Text-davinci-003 and ChatGPT are instruction-tuned models based on reinforcement learning from human feedback (RLHF). This is the most significant difference between them.
-
Detailed Responses: The outputs of text-davinci-003 are generally longer than those of text-davinci-002. ChatGPT’s responses are even more verbose, to the point where users must explicitly ask, “Answer me in one sentence,” to receive a more concise answer. This is a direct product of RLHF.
-
Fair Responses: ChatGPT typically provides very balanced answers to events involving multiple entities’ interests (e.g., political events). This is also a product of RLHF.
-
Refusal of Inappropriate Questions: This combines content filters and the model’s own abilities triggered by RLHF, where the filter eliminates some, and then the model refuses some.
-
Refusal of Questions Beyond Its Knowledge Range: For example, it refuses questions about new events that occurred after June 2021 (because it was not trained on data after that). This is the most remarkable part of RLHF, as it enables the model to implicitly distinguish which questions are within its knowledge range and which are not.
-
All abilities are inherent to the model and not injected through RLHF. The role of RLHF is to trigger/unlock emergent abilities. This argument mainly stems from the comparison of dataset sizes: because compared to the volume of pre-training data, RLHF occupies much less computational/data volume.
-
The model knows what it does not know not through rule-writing but through RLHF unlocking. This is a very surprising finding because the original goal of RLHF was to make the model generate responses that meet human expectations, which is more about generating safe sentences rather than making the model aware of what it does not know.
-
ChatGPT: Sacrificing in-context learning ability in exchange for the ability to model conversational history. This is an empirically observed result, as ChatGPT does not seem to be strongly influenced by contextual demonstrations like text-davinci-003.
-
Text-davinci-003: Restoring some of the in-context learning abilities sacrificed in text-davinci-002, improving zero-shot capabilities. According to the instructGPT paper, this comes from mixing language modeling goals during the reinforcement learning tuning phase (rather than RLHF itself).
5. Summary of the Evolution of GPT-3.5 to Date
5. Summary of the Evolution of GPT-3.5 to Date

-
The abilities of language generation + foundational world knowledge + in-context learning all stem from pre-training (davinci).
-
The ability to store vast amounts of knowledge comes from the 175 billion parameter count.
-
The ability to follow instructions and generalize to new tasks comes from expanding the number of instructions in instruction learning (Davinci-instruct-beta).
-
The ability to perform complex reasoning likely comes from code training (code-davinci-002).
-
The ability to generate neutral, objective responses, safe and detailed answers comes from alignment with humans. Specifically:
-
If it is a supervised learning version, the resulting model is text-davinci-002.
-
If it is a reinforcement learning version (RLHF), the resulting model is text-davinci-003.
-
Regardless of whether it is supervised or RLHF, the model’s performance on many tasks cannot exceed that of code-davinci-002, a phenomenon called alignment tax caused by alignment. -
The conversational ability also comes from RLHF (ChatGPT), specifically sacrificing in-context learning abilities in exchange for:
-
Modeling conversational history.
-
Increasing the amount of conversational information.
-
Refusing questions beyond the model’s knowledge range.
6. What GPT-3.5 Cannot Do
6. What GPT-3.5 Cannot Do
-
Real-Time Revision of Model Beliefs: When a model expresses a belief about something, if that belief is incorrect, it can be challenging to correct it:
-
A recent example I encountered is: ChatGPT insists that 3599 is a prime number, despite acknowledging that 3599 = 59 * 61. Also, see the example on Reddit about the fastest marine mammal.
-
However, the strength of the model’s beliefs seems to exist at different levels. An example is that even if I tell it that Darth Vader (a character from the Star Wars movie) won the 2020 election, the model will still believe that the current president of the United States is Biden. But if I change the election year to 2024, it will think that Darth Vader is the president in 2026. -
Formal Reasoning: The GPT-3.5 series cannot reason in strictly formal systems like mathematics or first-order logic:
-
In the literature of natural language processing, the definition of “reasoning” is often ambiguous. But if we look at it from the perspective of ambiguity, for example, some questions (a) are very ambiguous, with no reasoning; (b) have some logic in them, but some parts can also be vague; (c) are very rigorous and cannot tolerate any ambiguity.
-
The model can perform well on (b) type reasoning with ambiguity, examples include:
-
Generating how to make tofu pudding. When making tofu pudding, many steps can be slightly vague, such as whether to make it salty or sweet. As long as the overall steps are roughly correct, the resulting tofu pudding can be eaten.
-
Proof ideas for mathematical theorems. Proof ideas are informal step-by-step solutions expressed in language, where each step’s strict derivation can be less specific. Proof ideas are often used in math teaching: as long as the teacher provides a roughly correct overall step, students can understand it. Then the teacher assigns the specific proof details as homework, leaving the answers vague.
-
GPT-3.5 cannot perform type (c) reasoning (reasoning that cannot tolerate ambiguity).
-
An example is strict mathematical proofs, which require no jumps, no vagueness, and no errors in intermediate steps.
-
But whether strict reasoning should be done by language models or by symbolic systems is still up for debate. An example is that rather than trying to make GPT do three-digit addition, it might be better to just adjust Python.
-
Searching the Internet: The GPT-3.5 series (temporarily) cannot directly search the internet.
-
However, a WebGPT paper was published in December 2021, which allowed GPT to call search engines. Thus, the ability to search has already been tested internally at OpenAI.
-
Here, it is essential to distinguish that the two significant but different abilities of GPT-3.5 are knowledge and reasoning. Generally, if we can offload the knowledge part to an external retrieval system and let the language model focus solely on reasoning, that would be excellent because:
-
The model’s internal knowledge is always cut off at some point in time. The model always needs the latest knowledge to answer the latest questions.
-
Recall that we have discussed that 175 billion parameters are largely used to store knowledge. If we can offload knowledge externally, the model parameters could significantly reduce, and ultimately it could even run on a mobile phone (a crazy idea, but ChatGPT is already sufficiently sci-fi, who knows what the future holds).
7. Conclusion
7. Conclusion
In this blog post, we carefully examined the range of capabilities of the GPT-3.5 series and traced all the sources of its emergent abilities.
The original GPT-3 model obtained generation capabilities, world knowledge, and in-context learning through pre-training. Then, the instruction-tuned model branches gained the ability to follow instructions and generalize to unseen tasks. The code-trained branch model gained the ability to understand code, potentially acquiring complex reasoning abilities as a byproduct of code training.
Combining these two branches, code-davinci-002 seems to be the strongest GPT-3.5 model with all powerful capabilities. Subsequently, through supervised instruction tuning and RLHF, the model sacrifices capabilities to align with humans, known as alignment tax. RLHF enables the model to generate more detailed and fair answers while refusing questions beyond its knowledge range.
We hope this article provides a clear assessment map for GPT and sparks some discussions about language models, instruction tuning, and code tuning. Most importantly, we hope this article can serve as a roadmap for reproducing GPT-3.5 within the open-source community.
Frequently Asked Questions
Frequently Asked Questions
-
Are the statements in this article more like hypotheses or conclusions?
-
The ability for complex reasoning to come from code training is a hypothesis we tend to believe.
-
The ability to generalize to unseen tasks comes from large-scale instruction learning is the conclusion of at least four papers.
-
The idea that GPT-3.5 comes from other large foundational models rather than the 175 billion parameter GPT-3 is a well-founded guess.
-
It is a strong hypothesis that all these abilities already existed and were unlocked through instruction tuning, whether supervised learning or reinforcement learning, rather than injected. This is strong enough that one would dare not disbelieve it. This is mainly because the amount of instruction tuning data is several orders of magnitude smaller than that of pre-training.
-
Conclusion = Many pieces of evidence support the correctness of these statements; hypothesis = positive evidence but not strong enough; well-founded guess = no conclusive evidence, but some factors point in that direction.
-
Why are other models (like OPT and BLOOM) not as powerful?
-
OPT is probably due to an unstable training process.
-
The situation with BLOOM is unknown.




Point
Here, “Read the Original” to reach the Electronic Technology Application Official Website