Recently, CCF-Talk held an online seminar themed “Night Talk on DeepSeek: Technical Principles and Future Directions”. Associate Professor Liu Zhiyuan from Tsinghua University and Chief Scientist of Benwall Intelligence was one of the speakers, delivering an exciting presentation on “Technical Principles of Large Model Reinforcement Learning and Insights on Large Model Technology Development“.
Liu Zhiyuan stated that the open-source release of DeepSeek R1 has made the world aware of the capabilities of deep thinking. This is akin to a new moment for the entire artificial intelligence field, reminiscent of the early 2023 ChatGPT, allowing everyone to feel that the capabilities of large models have made significant progress. However, we also need to reasonably assess the significance of DeepSeek itself.
Liu Zhiyuan analyzed the insights brought by DeepSeek’s successful breakout and the future development trends of large model technology. He believes that DeepSeek V3 demonstrates how to achieve capabilities comparable to GPT-4 and GPT-4o at a cost of one-tenth or even less. Furthermore, the breakout of DeepSeek R1 also proves that OpenAI committed the “sin of arrogance”—not open-sourcing, not disclosing technological details, and setting excessively high prices.
The following are the main points of Professor Liu Zhiyuan’s speech at this seminar:
Viewing the Development Trends of Large Model Technology through DeepSeek R1
Today, I will introduce the large-scale reinforcement learning technology represented by DeepSeek R1 from a macro perspective, along with its basic principles. At the same time, we will explore why DeepSeek R1 and OpenAI o1 have attracted so much attention, and conduct a rough assessment of the future development of large model technology based on the models recently released by DeepSeek.
First, let us look at the recently released R1 model by DeepSeek, which holds significant value. This value is primarily reflected in the fact that DeepSeek R1 can perfectly replicate the deep reasoning capabilities of OpenAI o1.
Because OpenAI o1 itself did not provide any information regarding its implementation details, OpenAI o1 is like detonating an atomic bomb without revealing the secret formula. We need to start from scratch to find ways to replicate this capability. DeepSeek may be the first team in the world capable of replicating the abilities of OpenAI o1 purely through reinforcement learning technology, and they have made significant contributions to the industry by open-sourcing and providing relatively detailed introductions.
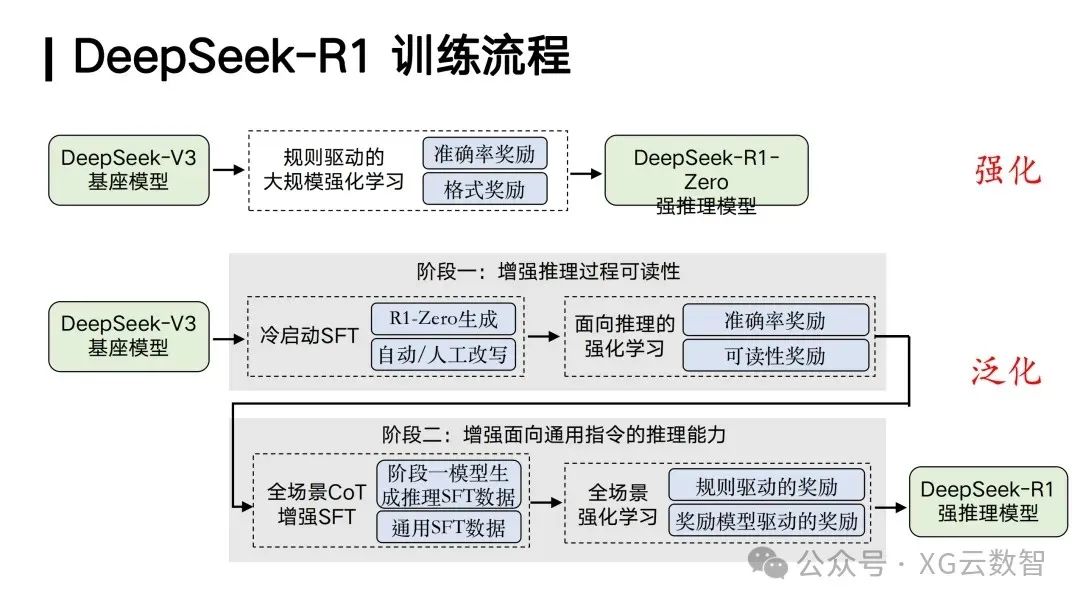
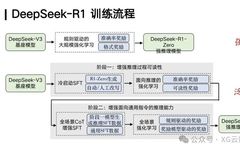
We can roughly summarize the entire training process of DeepSeek R1, which has two very important highlights or values. First, DeepSeek R1 creatively achieves a strong reasoning model purely enhanced by reinforcement learning, namely DeepSeek-R1-Zero, based on the DeepSeek V3 base model through large-scale reinforcement learning technology. This is of great importance because historically, very few teams have successfully applied reinforcement learning technology well to large-scale models and achieved large-scale training. One important technical characteristic that allows DeepSeek to achieve large-scale reinforcement learning is its use of a rule-based approach, ensuring that reinforcement learning can be scaled and achieving scaling for reinforcement learning, which is its first contribution.
The second important contribution of DeepSeek R1 is that its reinforcement learning technology is not limited to areas where mathematical and algorithmic code can easily provide reward signals; it can creatively generalize the strong reasoning capabilities brought by reinforcement learning to other fields.This is also why users can feel its powerful deep thinking ability when using DeepSeek R1 for tasks such as writing.
The realization of this generalization ability occurs in two stages. First, based on the DeepSeek V3 base model, by enhancing the readability of the reasoning process, SFT (Supervised Fine-Tuning) data with deep reasoning capabilities is generated. This data combines deep reasoning capabilities with traditional general SFT data for fine-tuning the large model. Subsequently, further reinforcement learning training yields a strong reasoning model with powerful generalization capabilities, namely DeepSeek R1.
Therefore, the important contributions of DeepSeek R1 are reflected in two aspects: first, achieving large-scale reinforcement learning through a rule-driven approach; second, achieving cross-task generalization of reasoning capabilities through the mixed fine-tuning of deep reasoning SFT data and general SFT data. This enables DeepSeek R1 to successfully replicate the reasoning level of OpenAI o1.
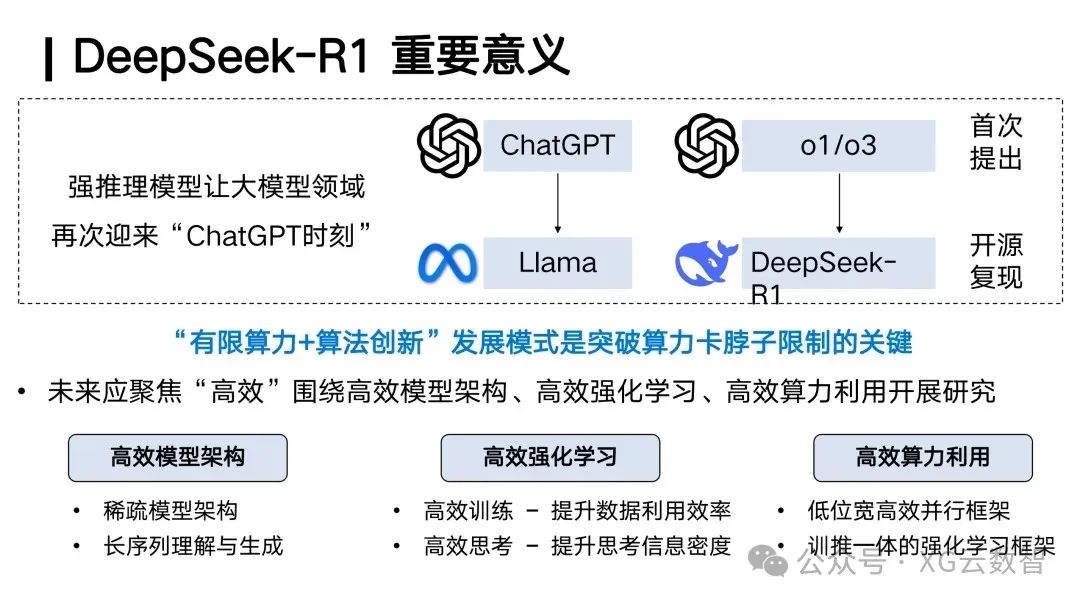
Thus, we should pay great attention to DeepSeek R1. Its open-source nature allows the world to realize the potential of deep thinking, akin to a new moment for the entire AI field, reminiscent of early 2023 ChatGPT, enabling everyone to feel that the capabilities of large models have made significant progress. However, we also need to reasonably assess the significance of DeepSeek itself.
If the early 2023 release of OpenAI’s ChatGPT allowed the world to see the important value of large models, then this time, the strong reasoning capability is actually the first to be realized by OpenAI in September 2024 with o1. We believe that DeepSeek R1 is historically more like Meta’s LLaMA in 2023. It can replicate through open-source and publicly share all of this with the world, allowing everyone to quickly build relevant capabilities. This is our accurate understanding of DeepSeek R1 and its important significance.
Of course, why is it said that DeepSeek R1 can achieve such global success?We believe this is largely related to some strategies adopted by OpenAI. After releasing o1, OpenAI first chose not to open-source, then hid the deep thinking process of o1, and thirdly, o1 itself adopted very high pricing. This prevented o1 from allowing as many people as possible worldwide to experience the shock brought by deep thinking.
In contrast, DeepSeek R1, like OpenAI’s ChatGPT in early 2023, truly allows everyone to feel this shock, which is a very important reason for DeepSeek R1’s breakout. If we further consider the R1 released by DeepSeek in conjunction with the previous V3, its significance lies in that under very limited computing resources, it has broken through the computing bottleneck through powerful algorithmic innovation, showing us that even with limited computing power, leading results of global significance can still be achieved.
This is of great significance for the development of AI in China. Of course, we should also see that if AI truly wants to empower all humanity, allowing everyone to use and afford large models and general artificial intelligence, then efficiency is obviously a very important proposition.
In this regard, we actually have many topics to discuss. In addition to the need for reinforcement learning itself to explore more efficient solutions in the future, we also need to research more efficient model architectures. For example, the MoE architecture adopted by V3 should also have many other related efficient architectural solutions in the future. Furthermore, topics such as efficient computing applications are also worth exploring and researching.
This is also another very important insight that DeepSeek V3 and R1 bring us. We believe that the pursuit of efficiency in the development of artificial intelligence is an inherent mission and need for us in the future.
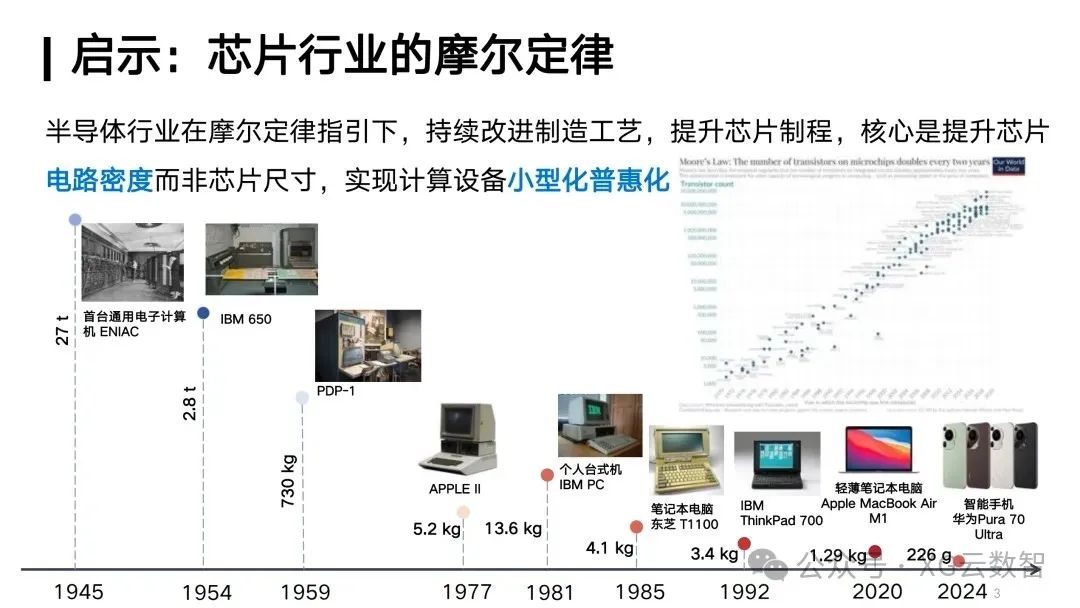
From this perspective, I would like to elaborate a bit. We see that the last so-called technological revolution, namely the information revolution, has a very important core, which is the development of computing chips. Over the past 80 years, computers have evolved from needing a room to accommodate them to now being available in everyone’s hands, such as mobile phones, PCs, and various computing devices, all capable of performing powerful computing capabilities in very small devices.
All of this actually stems from the chip industry’s continuous advancement in chip processes under the guidance of Moore’s Law, improving circuit density in chips, thus achieving the miniaturization and popularization of computing devices, driving the proliferation of computing power. This is evidently a very important intrinsic demand for our future pursuit of efficiency.
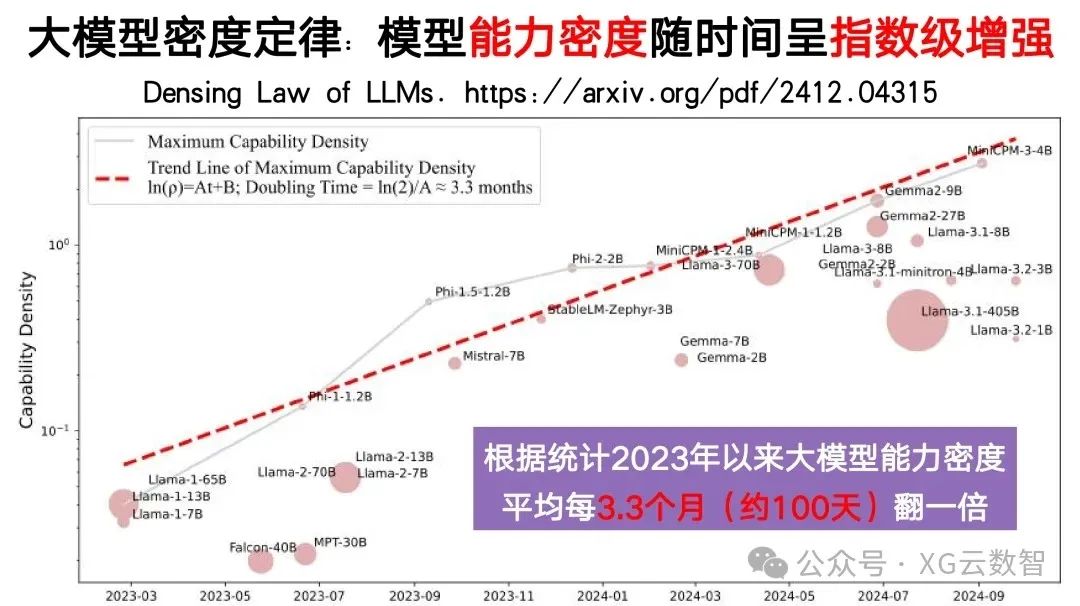
This is why we emphasized the need to develop the capability density of large models last year. In fact, over the past few years, we have seen a phenomenon similar to Moore’s Law: the capability density of large models is increasing exponentially over time. Since 2023, the capability density of large models has roughly doubled every 100 days, meaning that every 100 days, we only need half the computing power and half the parameters to achieve the same capability.
Therefore, we believe that looking ahead, we should continuously pursue higher capability density, striving to achieve the efficient development of large models at lower costs—including training costs and computing costs. From this perspective, we can clearly see that according to the trend of capability density development, we can achieve the same model capability with half the computing power and half the parameters every 100 days. Promoting this should be our mission for future development.

Thus, if we benchmark against the previous technological revolution—the information revolution, it is clear that it provides very important insights for the upcoming intelligent revolution. In fact, at the beginning of the information revolution, IBM’s founder Watson believed that the world did not need more than five mainframes to meet the computing needs of the entire world. But today, we can see that there are billions and tens of billions of computing devices serving humanity.
Therefore, we believe that the intelligent revolution must also go through a stage similar to the information revolution, continuously improving capability density, reducing computing costs, and making large models more accessible. Thus, I believe that the core engines of the AI era, including power, computing power, and the intelligence represented by large models, should universally exist according to this density law. We need to continuously achieve the popularization of large models in a high-quality and sustainable way, which should be our future development direction.
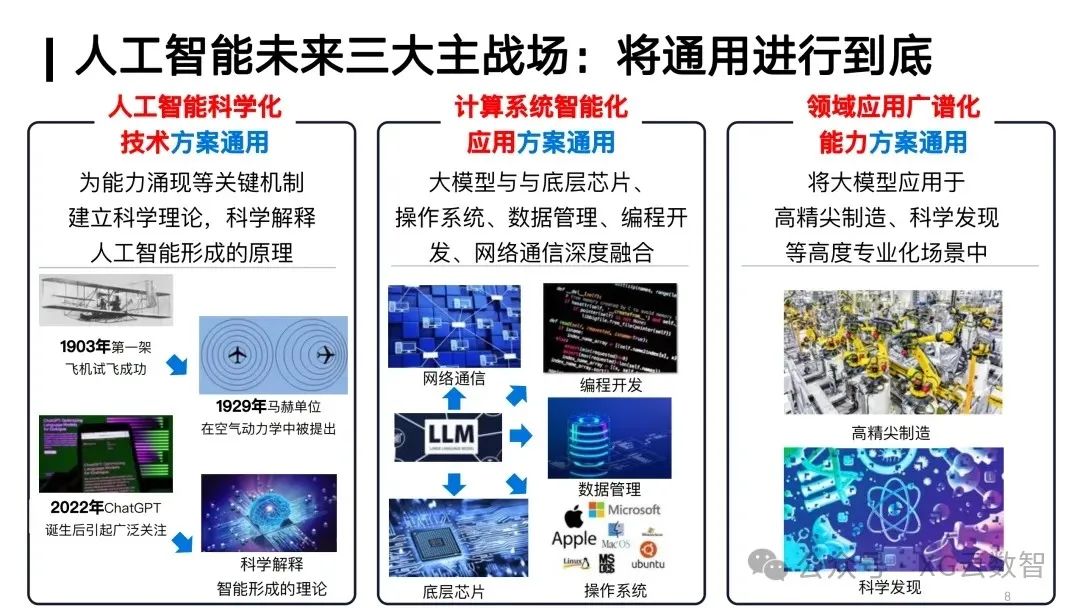
Looking to the future, we believe there are three major battlefields for artificial intelligence, all aimed at achieving top-level general artificial intelligence. First, we need to explore scientific technological solutions for artificial intelligence to realize more scientific and efficient ways of implementing AI. Secondly, we need to achieve the intelligentization of computing systems, enabling the application of large models across various fields at a lower cost and more universally. Finally, we also need to explore the broad-spectrum applications of artificial intelligence in various fields.
Finally, I want to emphasize that DeepSeek brings us a very important insight: It shows us that even with limited resources, we can still achieve vast victories. We are about to enter a very important and far-reaching era of intelligent revolution, and its climax is approaching, which is both hopeful and attainable.
DeepSeek’s success has attracted more attention to this direction and field, and I hope we can develop in the right direction, focusing not only on computing power but also on algorithmic innovation and the cultivation of high-level talent. Let us work together to carve out a truly high-quality development path for artificial intelligence.
Questions Most Concerned About DeepSeek
Q: What is the most notable technology in the success factors of DeepSeek?
A:I think there are mainly two insights:
The important insight that DeepSeek V3 brings us is that it demonstrates how to achieve capabilities comparable to GPT-4 and GPT-4o at a cost of one-tenth or even less.As mentioned by teachers Zhai Jidong and Dai Guohao, DeepSeek V3 has done a lot of work on underlying computing acceleration. But more importantly, Teacher Zhai particularly emphasized that DeepSeek V3 achieved collaborative optimization of algorithms and underlying software and hardware. This integrated optimization mechanism shows that even if costs are already low, further optimization can still reduce costs. Although the cost of V3 is still in the millions or even tens of millions of dollars, it is much lower compared to internationally recognized levels. This is also an important reason for Nvidia’s stock price decline.
Additionally, the success of DeepSeek R1 also reveals that OpenAI committed the “sin of arrogance”—not open-sourcing, not disclosing technical details, and setting excessively high prices, which prevented its breakout.In contrast, DeepSeek R1 is open-source and free, allowing global users to utilize it and disclosing all technical details. This has allowed DeepSeek to occupy a position that historically should have belonged to OpenAI, just like ChatGPT did back in the day. DeepSeek has successfully caught up with the most advanced international models through extreme optimization of limited resources, and I think they have done a remarkable job, making the innovation capabilities of the Chinese team recognized worldwide.
Q: Why did the DeepSeek R1 model appear at this time? Were there previous attempts to directly apply reinforcement learning based on foundational models? Have there been similar works on thinking chains before, and why did DeepSeek R1 stand out so much?
A:I think this matter has a certain inevitability.Around 2024, many investors, even those not engaged in the AI field, would ask me: Compared to American AI, has the gap with Chinese AI widened or narrowed? I clearly stated at that time that we believe China is catching up very quickly, and the gap with the most advanced technologies in the United States is gradually narrowing. Despite facing some restrictions, this catch-up is evident.
An important phenomenon that can verify this is that after the release of ChatGPT and GPT-4 in early 2023, domestic teams took about a year to replicate these two versions of model capabilities. By the end of 2023, domestic teams had replicated the capabilities of ChatGPT level models; by April or May 2024, frontline teams had replicated capabilities at the GPT-4 level. However, you will find that models like Sora and GPT-4o have been replicated by domestic teams in about six months. This means that for models like o1, it is predictable that domestic teams can replicate them in about six months.
DeepSeek itself is very outstanding, and its value lies not only in its ability to replicate but also in achieving this at an extremely low cost. This is its uniqueness and the reason for its standout performance: DeepSeek can complete this work faster, at a lower cost, and more efficiently, which is its huge contribution. From this perspective, I believe there is a certain inevitability.
Of course, the breakout effect of DeepSeek also relies on the long-term accumulation of its own team, as mentioned by Teacher Qiu Xipeng.
Q: (Comment section question) How is the concept of capability density defined? What are its underlying reasons?
A:This concept of “capability density” was proposed by us in the past six months. For effective and accurate measurement of capability density, you can refer to our paper published on arxiv, titled “Densing law of LLMs”(paper link: https://arxiv.org/pdf/2412.04315v2).
Capability density can be understood as the model’s performance across various evaluation sets divided by its parameter scale, or the scale of activated parameters. We have observed representative models released over the past year and a half and found that their capability density approximately doubles every 100 days. This means that every 100 days, we can achieve the same capability with half the parameters. Several factors influence this phenomenon:
(1) Data Quality: Higher data quality depends on data governance. High-quality data can enhance the training effectiveness of the model.
(2) Model Architecture: Adopting a more sparse activation model architecture can enable more capabilities to be carried with fewer activated parameters.
(3) Learning Methods: All leading teams, including OpenAI, are conducting what is called “scaling prediction.” Before truly training the model, we conduct numerous wind tunnel experiments, accumulating various predictive data to determine what kind of data ratios and hyperparameter configurations the model requires for optimal performance.
By integrating these factors, models can carry more capabilities with fewer parameters. We draw an analogy to Moore’s Law in the chip industry. Moore’s Law tells us that every 18 months, the circuit density on chips doubles. This process is achieved through continuous technological development.
Further combining the underlying computing optimization mentioned by teachers Zhai Jidong and Dai Guohao, we can map this optimization to the model training phase, significantly reducing costs. Of course, we are not saying that DeepSeek’s computing power can achieve the same capabilities as foreign models at 1/10 of the cost, but this overlaps with the Densing law (capability density law) to some extent.
Densing Law emphasizes the continuous improvement of model density, which is reflected not only in the reduction of training phase costs but also in the inference phase. Models can achieve the same capabilities with lower inference costs and faster inference speeds. We believe that the future development of AI will definitely follow this path. The developments over the past few years have continually verified this. An intuitive experience is that companies like OpenAI have seen their API model prices (for example, models at ChatGPT level and GPT-4 level) rapidly decline in the past few years. This is not merely due to price wars but also because they can achieve the same capabilities with fewer resources, thus providing services at lower costs.
We believe that efficiency is an important direction for the future development of AI and a crucial prerequisite for the arrival of the intelligent revolution.
Q: Will the MoE architecture be the optimal solution on the road to AGI?
A:My personal feeling is that no one is right forever.
In early 2023, when OpenAI released ChatGPT, it was right; when it released GPT-4, it was also right. But when it released o1, it was wrong—it did not open-source, and its pricing strategy also had errors. This instead led to the success of DeepSeek. I do not believe that DeepSeek’s choice of MoE architecture means that MoE is always correct. There is no evidence proving that MoE is the optimal model architecture.
From an academic perspective and the future development of AI, I believe this is an open question. How to achieve efficiency in the future? I believe it must be modular and sparse activation, but how exactly to achieve sparse activation and modularity? I think this should be a flourishing field of exploration. We should maintain openness and encourage students and practitioners to innovate like DeepSeek.
Thus, I personally do not think MoE has any absolute barriers or that it is necessarily the optimal method.
Q: What insights does the explosion of DeepSeek technology bring to the future development of large models in China?
A:First, I think the technical idealism of the DeepSeek team is particularly admirable.Because whether viewing their interviews or other materials, you will find that those interviews were conducted long before DeepSeek became popular, and the content is very genuine, reflecting their underlying logic. From this point, we can feel that DeepSeek is a team with very strong technical idealism, formed with the dream of achieving AGI. I find this very commendable.
I also see that Liang Wenfeng from DeepSeek previously engaged in quantitative investment, personally investing funds to carry out projects without financial worries. Therefore, I believe that China should support such technically idealistic teams, allowing them to explore without worries, even if they do not have sufficient funds. I think China has reached a stage where more teams like DeepSeek are needed, but perhaps they do not have the financial resources like DeepSeek. Whether we can enable them to do some original innovations and produce outstanding work is something worth considering.
The second point is their execution power. The rapid rise of DeepSeek in the past two months may seem impressive, but in fact, it is the result of years of sustained accumulation.We see their continuous progress, where quantitative changes ultimately lead to qualitative changes. I can tell everyone that a few years ago, Huanshuo attracted our students with free computing power and established connections with them. Of course, some students later graduated and joined DeepSeek. So, this is the result of their years of hard work. I believe this is also a long-term result driven by technical idealism. I think there should be more teams domestically that can endure hardships, focus more, and continuously work on important issues to produce meaningful work.
DeepSeek has come to where it is today, and I believe their work may also involve “feeling their way across the river with OpenAI” as a model, exploring the path to achieving AGI and striving to do what they believe is right.This process is very difficult, especially as OpenAI becomes increasingly closed, making the replication of o1 more challenging than that of ChatGPT back in the day. However, we will see that as long as there is idealism and execution power, they can achieve it. Therefore, in my view, there should be more teams domestically that can learn from this. The specific technology is certainly part of what we should learn, but I think we should avoid assuming that because DeepSeek succeeded, everything they did is correct. I believe that not everything they used is the most advanced, and it is unnecessary to think that because DeepSeek succeeded with certain technologies, they are all correct; this would limit our innovation. What we should learn is their ideals, their persistence, and their methodology.
This article is an observational or commentary piece published by a third-party self-media author. All text and images are copyrighted by the author and only represent the author’s personal views, unrelated to Beijing Internet of Things Intelligent Technology Application Association. The article is for reference only, and readers are advised to verify the related content themselves.