
Phidata is a framework designed for building AI agents with memory, knowledge, and tools.
https://github.com/phidatahq/phidata
https://docs.phidata.com/introduction

Three Aspects of Phidata Enhancing LLM Functionality:
-
Memory: Phidata stores chat history in a database, allowing large language models to support longer conversations, thereby better understanding and tracking the context of dialogues. -
Knowledge: By storing business-relevant information in a vector database, Phidata provides the model with rich contextual knowledge, enhancing its understanding and response capabilities regarding specialized content. -
Tools: Phidata enables large language models to perform specific tasks, such as fetching data from APIs, sending emails, or executing database queries, thus expanding the model’s utility and application range.
Phidata Workflow
-
Create an assistant.
-
Add tools (various functions), knowledge bases (vectordb), and data storage (database).
-
Deploy and serve your AI application using tools like Streamlit, FastAPI, or Django.
Note:
The vector database (vectordb) is primarily used for storing and retrieving vectorized data. In AI applications, vector databases are often employed to enhance the model’s contextual understanding by storing key information in a vectorized manner, supporting complex queries and dynamic content recommendations. For example, they are very useful in recommendation systems or semantic searches.
Data storage (database) is used to store various forms of data, including text, numbers, records, etc. Databases in AI applications are mainly used for persistent storage of user data, interaction history, and application states. This information can be utilized for subsequent data analysis, report generation, or providing historical context for ongoing dialogues.
Official Phidata Demonstration
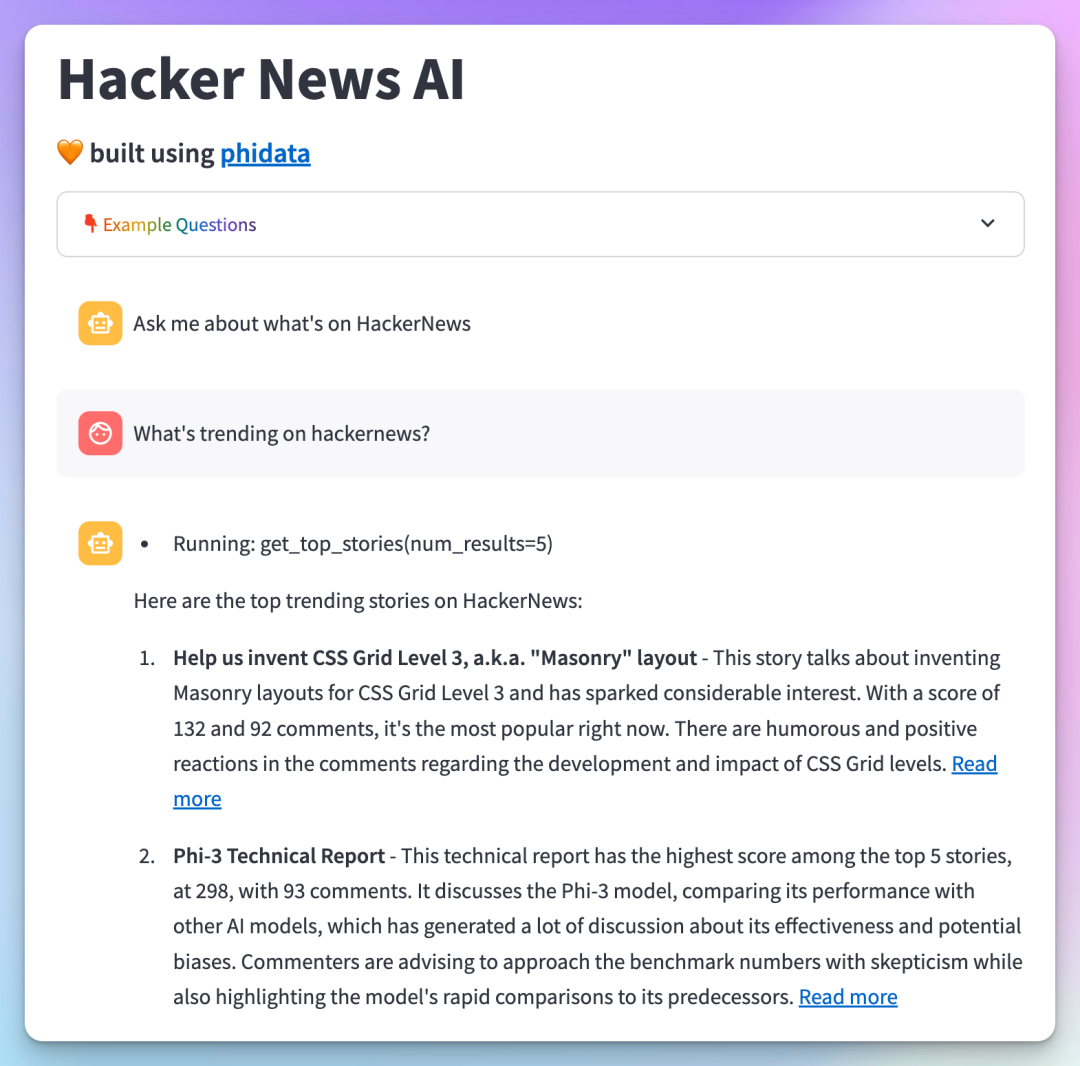
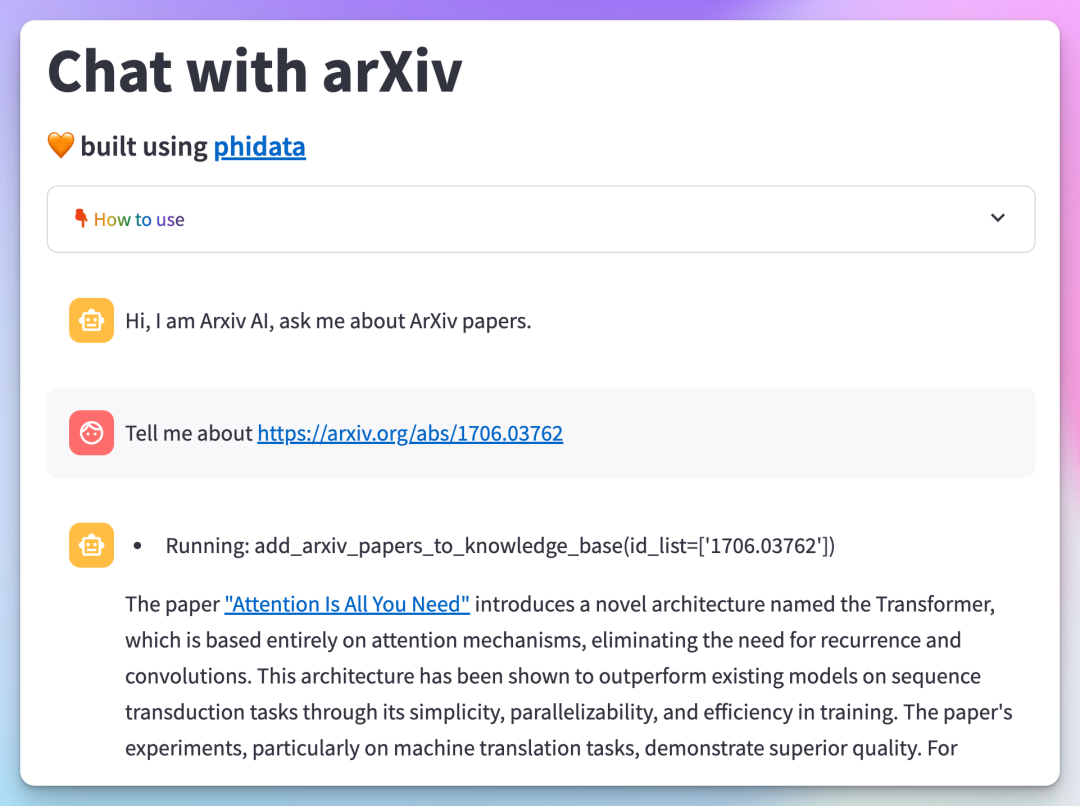
A major reason to recommend Phidata is its rapid updates and support for various large language models (LLM).
https://github.com/phidatahq/phidata/tree/main/cookbook/llms
Installing Phidata
pip install -U phidata
Using Llama3 on Groq to Implement RAG
https://github.com/phidatahq/phidata/tree/main/cookbook/llms/groq/rag
For embeddings, choose to use either Ollama or OpenAI.
1. Create a Virtual Environment
python3 -m venv ~/.venvs/aienv
source ~/.venvs/aienv/bin/activate
2. Export Your Groq API Key
export GROQ_API_KEY=***
3. Generate Embeddings Using Ollama or OpenAI
To generate embeddings using Ollama, first install Ollama and then run the nomic-embed-text model:
ollama run nomic-embed-text
To generate embeddings using OpenAI, export your OpenAI API key:
export OPENAI_API_KEY=sk-***
4. Install Dependencies
pip install -r cookbook/llms/groq/rag/requirements.txt
5. Run PgVector
First, install Docker Desktop. Then run using the helper script:
./cookbook/run_pgvector.sh
Or run directly using the docker run command:
docker run -d \
-e POSTGRES_DB=ai \
-e POSTGRES_USER=ai [app.py](..%2Fapp.py) \
-e POSTGRES_PASSWORD=ai \
-e PGDATA=/var/lib/postgresql/data/pgdata \
-v pgvolume:/var/lib/postgresql/data \
-p 5532:5432 \
--name pgvector \
phidata/pgvector:16
6. Run RAG Application
streamlit run cookbook/llms/groq/rag/app.py
Open localhost:8501 to view your RAG application.
Add website links or PDF files, then ask questions.
Practical Experience
When running streamlit run cookbook/llms/groq/rag/app.py, if the system prompts that psycopg or pgvector is missing, you can install these missing libraries by executing pip install psycopg and pip install pgvector.
I uploaded a 2MB PDF file of the Phi-3 technical report into the program, and the model completed the embedding process within seconds.
Subsequently, you can ask questions and receive instant answers.
This is thanks to Groq’s high-speed generation capability, with a generation speed of up to 280 Tokens/s under the llama3-70b-8192 model. In practical use, I found that asking questions in English yielded better results than in Chinese.


Asking Questions about Web Content
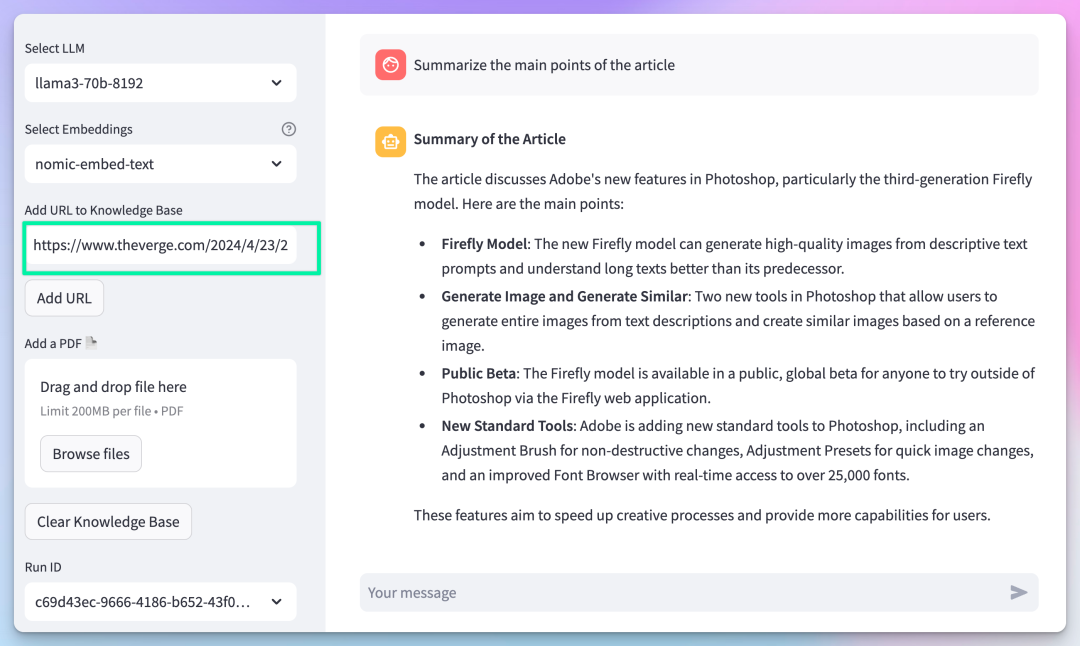
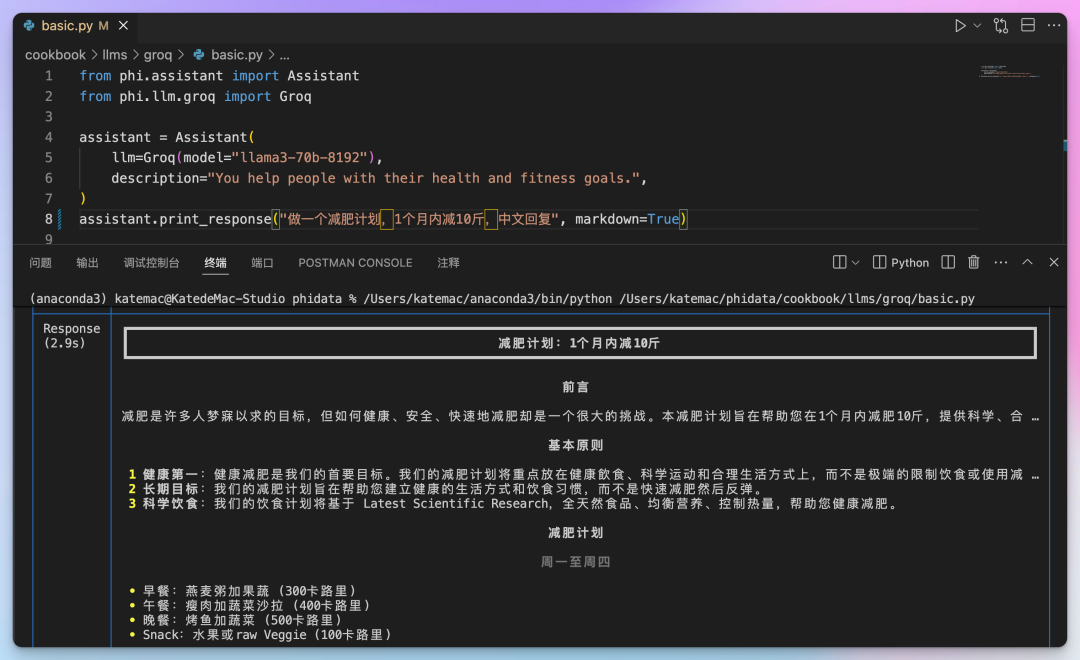
I am satisfied with Phidata; the example code it provides is concise and easy to understand.
Additionally, it optimizes the output format, allowing for visually appealing results even when running simple Python files in the terminal.
Conclusion
Overall, Phidata provides a powerful and flexible framework that can significantly enhance the capabilities of large language models.
By integrating memory, knowledge, and tools, Phidata not only optimizes data processing and interaction efficiency but also greatly expands application scenarios.
I recommend everyone to try it out.
For selected historical articles, please check here:
Groq API User Guide: Experience without Application, From Rate Limits to Model Parameter Analysis
RAG Interaction for Mac Users: Conversing with Data through Chat-with-MLX
Practical testing of using Ollama to converse with AI on Mac – Model selection, installation, integration use notes, from Mixtral8x7b to Yi-34B-Chat
Llama 3 Debuts: 70B Version Surpasses Claude 3 Sonnet, Exploring 8 Major Usage Channels