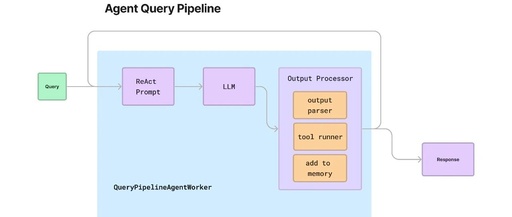
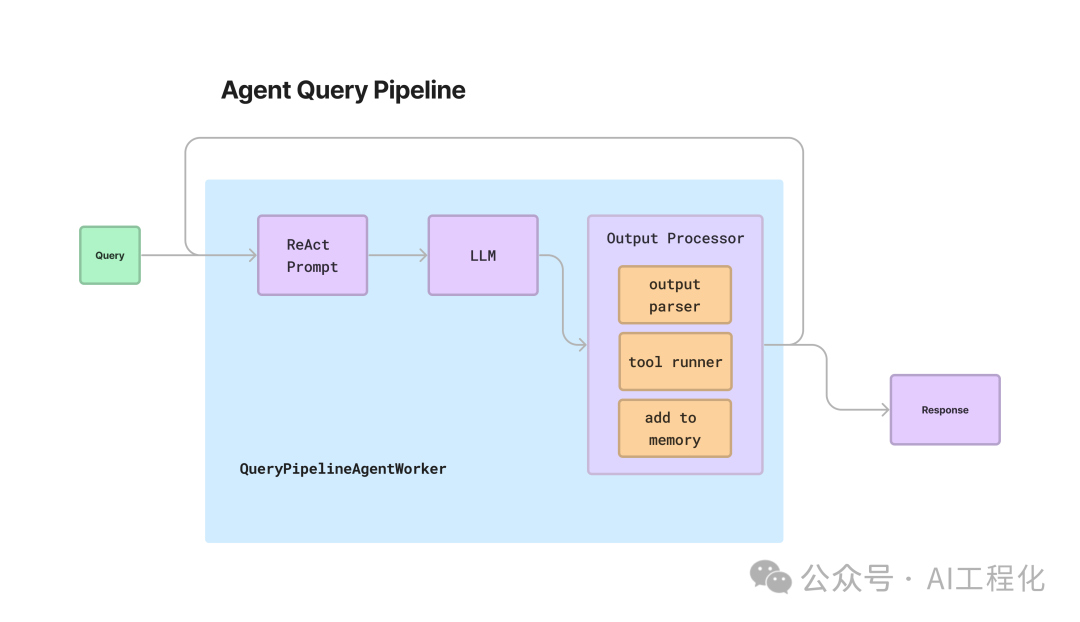
So, can Agent applications be implemented through Query Pipeline? If so, it will unify the entire application construction model and provide a consistent development experience for developers. The answer is yes; recently, the official team released an example of building a ReAct Agent through Query Pipeline. In fact, the implementation idea is straightforward: it defines an AgentWorker (similar to langchain’s AgentExecutor implementation, supporting the ReAct mode loop) and implements some Agent-specific components on top of it, thus creating the AgentPipeline. However, langchain has now discovered limitations in this design under production conditions and has launched langgraph.
Further reading: LangChain version 0.1.0 officially released, One More Thing will be a boon for the production of Agents.
This article uses the official provided “Text2SQL ReAct Agent” as an example to understand the basic development process.
1. Import data and build the database to be queried.
!curl "https://www.sqlitetutorial.net/wp-content/uploads/2018/03/chinook.zip" -O ./chinook.zip!unzip ./chinook.zip
% Total % Received % Xferd Average Speed Time Time Time Current Dload Upload Total Spent Left Speed100 298k 100 298k 0 0 2327k 0 --:--:-- --:--:-- --:--:-- 2387kcurl: (6) Could not resolve host: .Archive: ./chinook.zip inflating: chinook.db from llama_index import SQLDatabasefrom sqlalchemy import ( create_engine, MetaData, Table, Column, String, Integer, select, column,)
engine = create_engine("sqlite:///chinook.db")
sql_database = SQLDatabase(engine)2. Install observability tools; the official recommendation is to use Arize Phoenix.
# setup Arize Phoenix for logging/observability
import phoenix as px
import llama_index
px.launch_app()llama_index.set_global_handler("arize_phoenix")
🌍 To view the Phoenix app in your browser, visit http://127.0.0.1:6006/
📺 To view the Phoenix app in a notebook, run `px.active_session().view()`
📖 For more information on how to use Phoenix, check out https://docs.arize.com/phoenix3. Build the Text2SQL tool.
from llama_index.query_engine import NLSQLTableQueryEngine
from llama_index.tools.query_engine import QueryEngineTool
sql_query_engine = NLSQLTableQueryEngine( sql_database=sql_database, tables=["albums", "tracks", "artists"], verbose=True,)
sql_tool = QueryEngineTool.from_defaults( query_engine=sql_query_engine, name="sql_tool", description=( "Useful for translating a natural language query into a SQL query" ),)4. Construct the ReAct Agent Pipeline, which is the key to the entire construction process. The entire execution process is divided into four steps:
#Part of the implementation of QueryPipelineAgentWorker def _get_task_step_response( self, agent_response: AGENT_CHAT_RESPONSE_TYPE, step: TaskStep, is_done: bool ) -> TaskStepOutput: """Get task step response."""
if is_done: new_steps = [] else: new_steps = [ step.get_next_step( step_id=str(uuid.uuid4()), # NOTE: input is unused input=None, ) ]
return TaskStepOutput( output=agent_response, task_step=step, is_last=is_done, next_steps=new_steps, )-
AgentInputComponent allows converting Agent input (task, state dictionary) into a set of query pipeline inputs. -
AgentFnComponent: a generic processor that allows you to get the current task, state, and any arbitrary input, and return output. In this example, a function component is defined to format the ReAct prompt. Of course, it can be placed anywhere. -
CustomAgentComponent: similar to AgentFnComponent, can implement _run_component to define its own logic and access tasks and states. It is more complex than AgentFnComponent but more flexible (e.g., can define initialization variables, and callbacks are in the base class). Note that any function passed to AgentFnComponent and AgentInputComponent must include task and state as input variables, as these are the inputs passed by the Agent.
Moreover, the output of AgentQueryPipeline must be Tuple[AgentChatResponse, bool].
1) Define AgentInputComponent. Called at the start of each Agent step. In addition to passing inputs, it also executes initialization/state modification.
from llama_index.agent.react.types import ( ActionReasoningStep, ObservationReasoningStep, ResponseReasoningStep,)
from llama_index.agent import Task, AgentChatResponse
from llama_index.query_pipeline import ( AgentInputComponent, AgentFnComponent, CustomAgentComponent, ToolRunnerComponent, QueryComponent,)
from llama_index.llms import MessageRole
from typing import Dict, Any, Optional, Tuple, List, cast
## Agent Input Component## This is the component that produces agent inputs to the rest of the components## Can also put initialization logic here.def agent_input_fn(task: Task, state: Dict[str, Any]) -> Dict[str, Any]: """Agent input function.
Returns: A Dictionary of output keys and values. If you are specifying src_key when defining links between this component and other components, make sure the src_key matches the specified output_key.
""" # initialize current_reasoning if "current_reasoning" not in state: state["current_reasoning"] = [] reasoning_step = ObservationReasoningStep(observation=task.input) state["current_reasoning"].append(reasoning_step) return {"input": task.input}
agent_input_component = AgentInputComponent(fn=agent_input_fn)2) Define Agent Prompt. Define an Agent component that can generate ReAct prompts and parse them into structured objects after the LLM generates output.
from llama_index.agent.react.formatter import ReActChatFormatter
from llama_index.query_pipeline import InputComponent, Link
from llama_index.llms import ChatMessage
from llama_index.tools import BaseTool
## define prompt function
def react_prompt_fn( task: Task, state: Dict[str, Any], input: str, tools: List[BaseTool]) -> List[ChatMessage]: # Add input to reasoning chat_formatter = ReActChatFormatter() return chat_formatter.format( tools, chat_history=task.memory.get() + state["memory"].get_all(), current_reasoning=state["current_reasoning"], )
react_prompt_component = AgentFnComponent( fn=react_prompt_fn, partial_dict={"tools": [sql_tool]})3) Define Agent Output Parser and Tool Pipeline. The Agent Output Parser process can be summarized into two situations::
-
If the LLM provides the final answer, then only the output needs to be processed. -
If the LLM provides a tool operation, it needs to execute the specified tool using the specified parameters and then process the output.
Tool calls can utilize the ToolRunnerComponent module to complete. It receives a list of tools and can “execute” using the specified tool name (each tool has a name) and tool operation. It is essentially a specific implementation of CustomAgentComponent. It also implements sub_query_components to pass higher-level callback managers to the tool runner submodule.
from typing import Set, Optional
from llama_index.agent.react.output_parser import ReActOutputParser
## Agent Output Component## Process reasoning step/tool outputs, and return agent responsedef finalize_fn( task: Task, state: Dict[str, Any], reasoning_step: Any, is_done: bool = False, tool_output: Optional[Any] = None,) -> Tuple[AgentChatResponse, bool]: """Finalize function.
Here we take the latest reasoning step, and a tool output (if provided), and return the agent output (and decide if agent is done).
This function returns an `AgentChatResponse` and `is_done` tuple. and is the last component of the query pipeline. This is the expected return type for any query pipeline passed to `QueryPipelineAgentWorker`.
""" current_reasoning = state["current_reasoning"] current_reasoning.append(reasoning_step) # if tool_output is not None, add to current reasoning if tool_output is not None: observation_step = ObservationReasoningStep( observation=str(tool_output) ) current_reasoning.append(observation_step) if isinstance(current_reasoning[-1], ResponseReasoningStep): response_step = cast(ResponseReasoningStep, current_reasoning[-1]) response_str = response_step.response else: response_str = current_reasoning[-1].get_content()
# if is_done, add to memory # NOTE: memory is a reserved keyword in `state`, but you can add your own too if is_done: state["memory"].put( ChatMessage(content=task.input, role=MessageRole.USER) ) state["memory"].put( ChatMessage(content=response_str, role=MessageRole.ASSISTANT) )
return AgentChatResponse(response=response_str), is_done
class OutputAgentComponent(CustomAgentComponent): """Output agent component."""
tool_runner_component: ToolRunnerComponent output_parser: ReActOutputParser
def __init__(self, tools, **kwargs): tool_runner_component = ToolRunnerComponent(tools) super().__init__( tool_runner_component=tool_runner_component, output_parser=ReActOutputParser(), **kwargs )
def _run_component(self, **kwargs: Any) -> Any: """Run component.""" chat_response = kwargs["chat_response"] task = kwargs["task"] state = kwargs["state"] reasoning_step = self.output_parser.parse( chat_response.message.content ) if reasoning_step.is_done: return { "output": finalize_fn( task, state, reasoning_step, is_done=True ) } else: tool_output = self.tool_runner_component.run_component( tool_name=reasoning_step.action, tool_input=reasoning_step.action_input, ) return { "output": finalize_fn( task, state, reasoning_step, is_done=False, tool_output=tool_output, ) }
@property def _input_keys(self) -> Set[str]: return {"chat_response"}
@property def _optional_input_keys(self) -> Set[str]: return {"is_done", "tool_output"}
@property def _output_keys(self) -> Set[str]: return {"output"}
@property def sub_query_components(self) -> List[QueryComponent]: return [self.tool_runner_component]
react_output_component = OutputAgentComponent([sql_tool])4) Build the Pipeline process, forming agent_input -> react_prompt -> llm -> react_output execution flow. Note: For simple sequential flows, they can be directly written in the QueryPipeline as a Chain form.
from llama_index.query_pipeline import QueryPipeline as QP
from llama_index.llms import OpenAI
qp = QP( modules={ "agent_input": agent_input_component, "react_prompt": react_prompt_component, "llm": OpenAI(model="gpt-4-1106-preview"), "react_output": react_output_component, }, verbose=True,)
qp.add_chain(["agent_input", "react_prompt", "llm", "react_output"])You can also use pyvis to visualize the Pipeline topology.
rom pyvis.network import Network
net = Network(notebook=True, cdn_resources="in_line", directed=True)net.from_nx(qp.dag)net.show("agent_dag.html")5) Load the pipeline.
from llama_index.agent import QueryPipelineAgentWorker, AgentRunner
from llama_index.callbacks import CallbackManager
agent_worker = QueryPipelineAgentWorker(qp)
agent = AgentRunner(agent_worker, callback_manager=CallbackManager([]))6) Run the Pipeline.
# start task
task = agent.create_task( "What are some tracks from the artist AC/DC? Limit it to 3")
step_output = agent.run_step(task.task_id) # single step output
step_output.is_last # check if complete
response = agent.finalize_response(task.task_id)print(str(response))
The top 3 tracks by AC/DC are "For Those About To Rock (We Salute You)", "Put The Finger On You", and "Let's Get It Up."Additionally, the official team provided a simplified implementation that does not require selecting tools; it directly executes text2sql and supports multiple retries based on correctness for the generated Agent Pipeline.
1. Construct the Pipeline.
from llama_index.llms import OpenAI
# llm = OpenAI(model="gpt-3.5-turbo")llm = OpenAI(model="gpt-4-1106-preview")
from llama_index.agent import Task, AgentChatResponse
from typing import Dict, Any
from llama_index.query_pipeline import AgentInputComponent, AgentFnComponent
def agent_input_fn(task: Task, state: Dict[str, Any]) -> Dict: """Agent input function."""
# initialize current_reasoning if "convo_history" not in state: state["convo_history"] = [] state["count"] = 0 state["convo_history"].append(f"User: {task.input}") convo_history_str = "\n".join(state["convo_history"]) or "None" return {"input": task.input, "convo_history": convo_history_str}
agent_input_component = AgentInputComponent(fn=agent_input_fn)from llama_index.prompts import PromptTemplate
retry_prompt_str = """
You are trying to generate a proper natural language query given a user input.
This query will then be interpreted by a downstream text-to-SQL agent which will convert the query to a SQL statement. If the agent triggers an error, then that will be reflected in the current conversation history (see below).
If the conversation history is None, use the user input. If it's not None, generate a new SQL query that avoids the problems of the previous SQL query.
Input: {input}
Convo history (failed attempts): {convo_history}
New input: """retry_prompt = PromptTemplate(retry_prompt_str)
from llama_index.response import Response
from typing import Tuple
validate_prompt_str = """
Given the user query, validate whether the inferred SQL query and response from executing the query is correct and answers the query.
Answer with YES or NO.
Query: {input}
Inferred SQL query: {sql_query}
SQL Response: {sql_response}
Result: """validate_prompt = PromptTemplate(validate_prompt_str)
MAX_ITER = 3
def agent_output_fn( task: Task, state: Dict[str, Any], output: Response) -> Tuple[AgentChatResponse, bool]: """Agent output component."""
print(f"> Inferred SQL Query: {output.metadata["sql_query"]}") print(f"> SQL Response: {str(output)}") state["convo_history"].append( f"Assistant (inferred SQL query): {output.metadata["sql_query"]}" ) state["convo_history"].append(f"Assistant (response): {str(output)}")
# run a mini chain to get response validate_prompt_partial = validate_prompt.as_query_component( partial={ "sql_query": output.metadata["sql_query"], "sql_response": str(output), } ) qp = QP(chain=[validate_prompt_partial, llm]) validate_output = qp.run(input=task.input)
state["count"] += 1 is_done = False if state["count"] >= MAX_ITER: is_done = True if "YES" in validate_output.message.content: is_done = True
return AgentChatResponse(response=str(output)), is_done
agent_output_component = AgentFnComponent(fn=agent_output_fn)from llama_index.query_pipeline import ( QueryPipeline as QP, Link, InputComponent,)
qp = QP( modules={ "input": agent_input_component, "retry_prompt": retry_prompt, "llm": llm, "sql_query_engine": sql_query_engine, "output_component": agent_output_component, }, verbose=True,)
qp.add_link("input", "retry_prompt", src_key="input", dest_key="input")qp.add_link( "input", "retry_prompt", src_key="convo_history", dest_key="convo_history")qp.add_chain(["retry_prompt", "llm", "sql_query_engine", "output_component"])2. Load and execute:
from llama_index.agent import QueryPipelineAgentWorker, AgentRunner
from llama_index.callbacks import CallbackManager
agent_worker = QueryPipelineAgentWorker(qp)
agent = AgentRunner(agent_worker, callback_manager=CallbackManager([]))
response = agent.chat( "How many albums did the artist who wrote 'Restless and Wild' release? (answer should be non-zero)?")
print(str(response))As this feature is still in the development preview stage, there is no official detailed interpretation. From the case alone, there are still certain limitations in the current implementation of custom process Agents, which will be the direction for improvement to achieve complex Agent application modes. On the other hand, due to the design of AgentWorker, the mixing of Agent and RAG may also be a direction worth improving in the future.
Reference:https://github.com/run-llama/llama_index/blob/main/docs/examples/agent/agent_runner/query_pipeline_agent.ipynb