
1. Overview of Machine Learning
1) What is Machine Learning
Artificial Intelligence is a new technical science that studies and develops theories, methods, technologies, and application systems for simulating, extending, and enhancing human intelligence. It is a broad and vague concept, with the ultimate goal of artificial intelligence being to enable computers to mimic human thinking and behavior.
Artificial intelligence began to emerge around the 1950s, but its development was slow due to limitations in data and hardware.
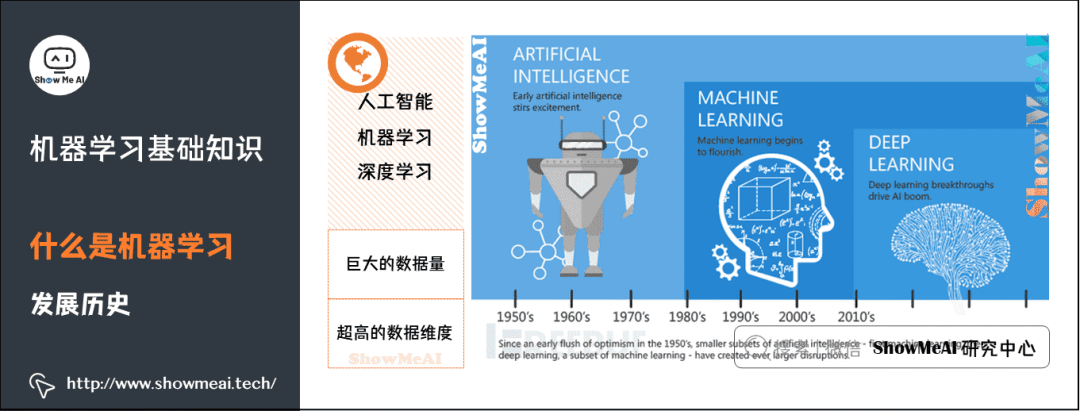
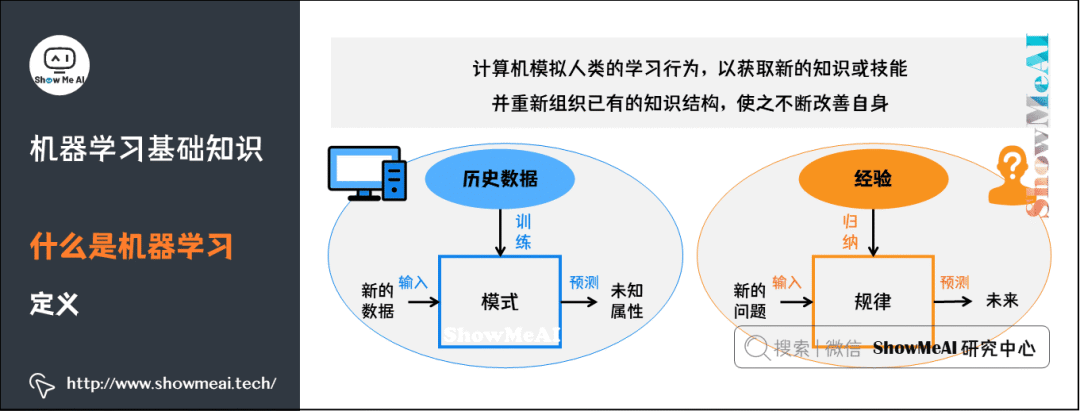
Machine Learning is a subset of artificial intelligence and a means of achieving artificial intelligence, but it is not the only way. It is a discipline that specifically studies how computers can simulate or realize human learning behaviors to acquire new knowledge or skills and reorganize existing knowledge structures to continuously improve their performance. It began to thrive around the 1980s, giving birth to a large number of mathematical statistics-related machine learning models.
Deep Learning is a subset of machine learning inspired by the human brain, consisting of artificial neural networks (ANNs) that mimic similar structures found in the human brain. In deep learning, learning occurs through a deep, multi-layered “network” of interconnected “neurons.” The term “deep” usually refers to the number of hidden layers in the neural network. It exploded in growth after 2012 and is widely used in many scenarios.
Let’s take a look at how well-known scholars abroad define machine learning:
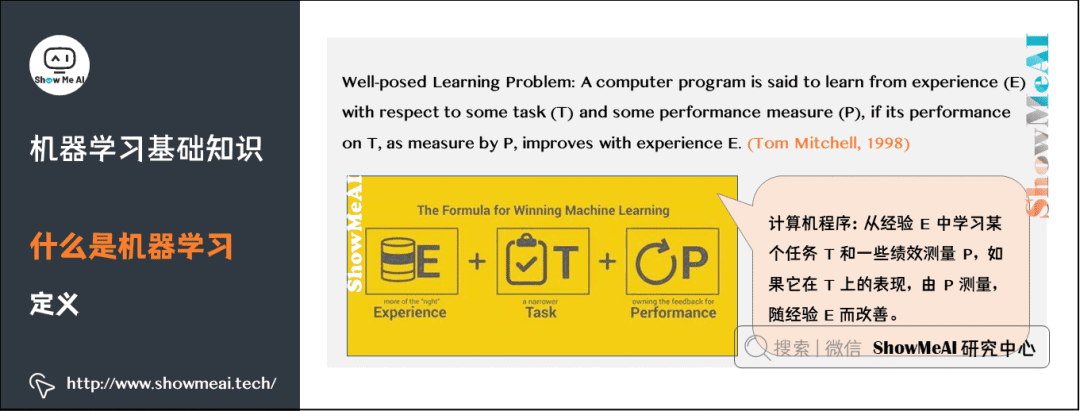
Machine learning studies how computers can simulate human learning behaviors to acquire new knowledge or skills and reorganize existing knowledge structures to continuously improve themselves.
From a practical perspective, machine learning is supported by big data, using various algorithms to allow machines to perform in-depth statistical analysis of data for “self-learning,” enabling artificial intelligence systems to gain inductive reasoning and decision-making capabilities.
Through the classic spam filtering application, we can further understand the principles of machine learning and what T, E, and P in the definition refer to:

2) Three Elements of Machine Learning
The three elements of machine learning include data, model, and algorithm. The relationship between these three elements can be represented by the following diagram:
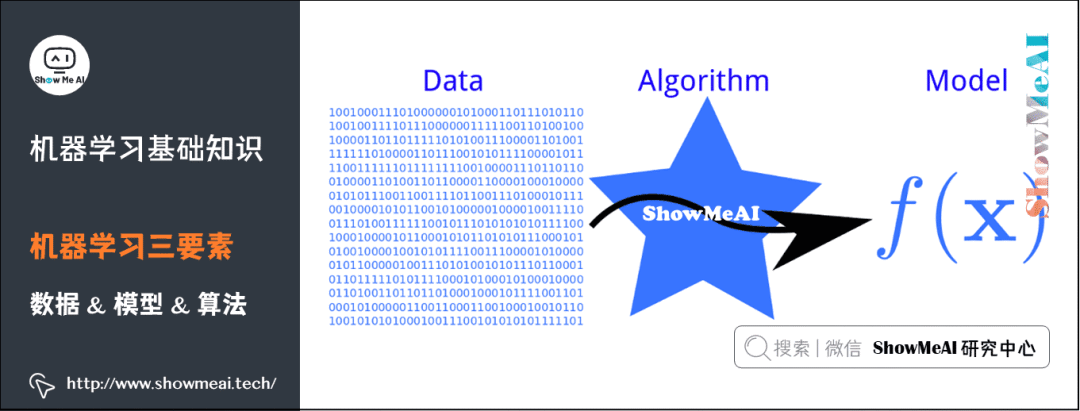
(1) Data
Data-Driven: Data-driven refers to our reliance on objective quantitative data, actively collecting and analyzing data to support decision-making. In contrast, experience-driven refers to the intuitive approach, often referred to as “going by gut feeling.”

(2) Model & Algorithm
Model: In the realm of AI data-driven approaches, a model refers to the hypothesis function that makes decisions Y based on data X, which can take various forms, including computational and rule-based.
Algorithm: Refers to the specific computational method used to learn the model. Statistical learning is based on the training dataset, selecting the optimal model from the hypothesis space based on learning strategies, and finally considering what computational methods to use to solve the optimal model. Typically, this is an optimization problem.

3) Development History of Machine Learning
The term artificial intelligence first appeared in 1956, used to explore effective solutions to certain problems. In 1960, the U.S. Department of Defense utilized the concept of “neural networks” to train computers to mimic human reasoning processes.
Before 2010, tech giants like Google and Microsoft improved machine learning algorithms, elevating the accuracy of queries to new heights. Subsequently, with the increase in data volume, advanced algorithms, and improvements in computing and storage capacities, machine learning has further developed.
4) Core Technologies of Machine Learning
Classification: Applies classification data to train models and accurately classify and predict new samples based on the model.
Clustering: Identifies similarities and differences within massive data sets and aggregates them into multiple categories based on maximum commonalities.
Anomaly Detection: Analyzes the distribution patterns of data points to identify outliers that differ significantly from normal data.
Regression: Finds the best-fitting parameters for the model based on training data with known attribute values to predict the output values of new samples.
5) Basic Workflow of Machine Learning
The machine learning workflow includes several steps: data preprocessing (Processing), model learning (Learning), model evaluation (Evaluation), and new sample prediction (Prediction).
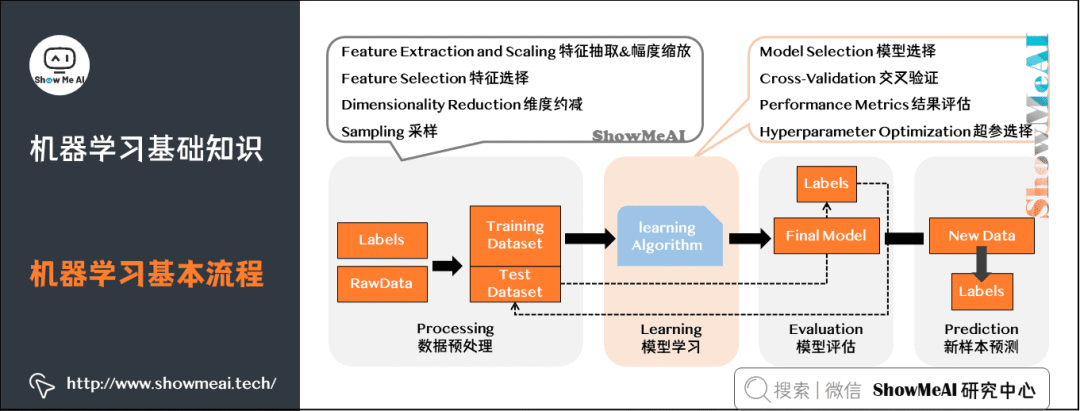
Data Preprocessing: Input (raw data + labels) → Processing (feature processing + amplitude scaling, feature selection, dimensionality reduction, sampling) → Output (test set + training set).
Model Learning: Model selection, cross-validation, result evaluation, hyperparameter selection.
Model Evaluation: Understand the model’s scores on the dataset test.
New Sample Prediction: Predict the test set.
6) Application Scenarios of Machine Learning
As a data-driven methodology, machine learning has been widely applied in fields such as data mining, computer vision, natural language processing, biometric recognition, search engines, medical diagnosis, credit card fraud detection, securities market analysis, DNA sequencing, speech and handwriting recognition, and robotics.

Smart Healthcare: Smart prosthetics, exoskeletons, healthcare robots, surgical robots, intelligent health management, etc.
Facial Recognition: Access control systems, attendance systems, facial recognition security doors, electronic passports and ID cards, and can also be used in conjunction with networks to capture fugitives nationwide.
Robotics Control: Industrial robots, robotic arms, multi-legged robots, vacuum cleaning robots, drones, etc.
2. Basic Terminology of Machine Learning
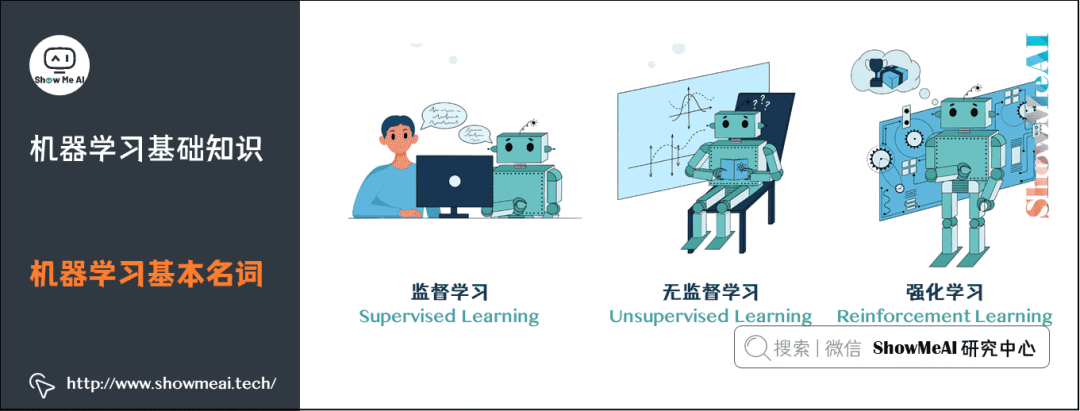
Supervised Learning: (Supervised Learning): The training set has labeled information, with learning methods including classification and regression.
Unsupervised Learning: (Unsupervised Learning): The training set has no labeled information, with learning methods including clustering and dimensionality reduction.
Reinforcement Learning: (Reinforcement Learning): A learning method with delayed and sparse feedback labels.
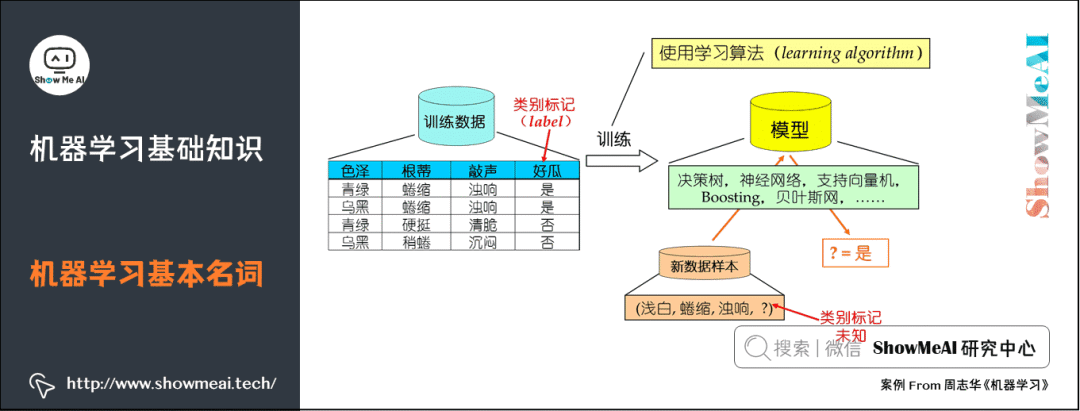
Sample: A single data point from the dataset.
Attributes/Features: Such as “color” and “root structure”.
Attribute space/sample space/input space X: The space formed by all attributes.
Feature Vector: A coordinate vector corresponding to each point in the space.
Label: Information about the outcome of a sample, such as (color=green, root structure=curled, sound=dull), good melon, where “good melon” is referred to as the label.
Classification: If the prediction is for discrete values, such as “good melon” or “bad melon,” this type of learning task is called classification.
Hypothesis: The learned model corresponds to some underlying patterns in the data.
Truth: The underlying patterns themselves.
Learning Process: Aims to discover or approximate the truth.
Generalization Ability: The ability of the learned model to apply to new samples. Generally, the larger the training sample, the more likely it is to obtain a model with strong generalization ability through learning.
3. Classification of Machine Learning Algorithms
1) Problem Scenarios of Machine Learning Algorithms
Machine learning has developed into a multidisciplinary field over the past 30 years, involving probability theory, statistics, approximation theory, convex analysis, computational complexity theory, and other disciplines. The theory of machine learning mainly focuses on designing and analyzing algorithms that allow computers to automatically “learn”.
Machine learning algorithms automatically analyze data to identify patterns and use these patterns to predict unknown data.
The theory of machine learning focuses on feasible and effective learning algorithms. Many inference problems are difficult to solve algorithmically, so part of machine learning research involves developing easily manageable approximate algorithms.

The main categories of machine learning include: supervised learning, unsupervised learning, and reinforcement learning.
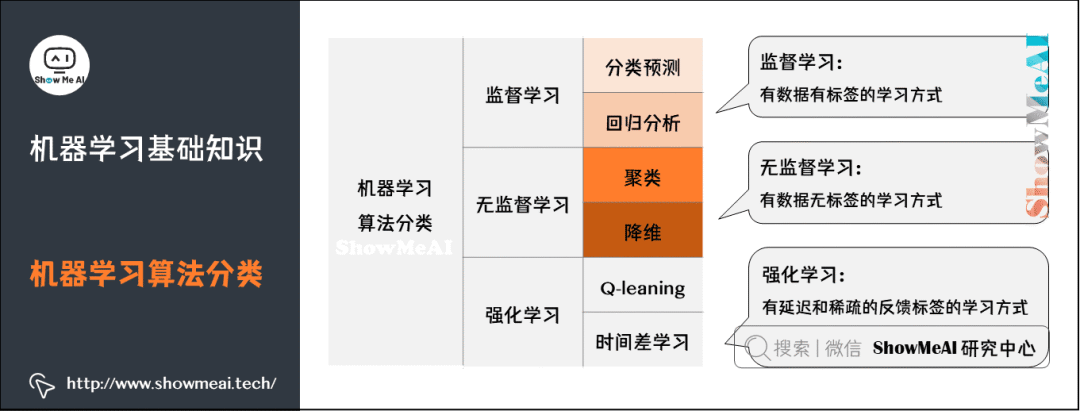
Supervised Learning: Learns a function from the provided training dataset, allowing predictions based on this function when new data arrives. The training set for supervised learning must include both inputs and outputs, or features and targets. The targets in the training set are labeled by humans. Common supervised learning algorithms include regression analysis and statistical classification.
For more summaries of supervised learning algorithm models, please refer to ShowMeAI’s article AI Knowledge Skills Quick Reference | Machine Learning – Supervised Learning (the public account cannot be redirected, the link to this article is at the end).
Unsupervised Learning: In contrast to supervised learning, the training set does not have human-labeled results. Common unsupervised learning algorithms include Generative Adversarial Networks (GANs) and clustering.
For more summaries of unsupervised learning algorithm models, please refer to ShowMeAI’s article AI Knowledge Skills Quick Reference | Machine Learning – Unsupervised Learning.
Reinforcement Learning: Learns how to take actions through observation. Each action impacts the environment, and the learning subject makes judgments based on feedback from the observed surrounding environment.
2) Classification Problems
Classification problems are a crucial component of machine learning. Their goal is to determine which known sample class a new sample belongs to based on certain features of known samples. Classification problems can be subdivided as follows:
Binary Classification Problems: Indicate that there are two categories in the classification task to which the new sample belongs.
Multiclass Classification Problems: Indicate that there are multiple categories in the classification task.
Multilabel Classification Problems: Assign a series of target labels to each sample.
For more information on machine learning classification algorithms: KNN algorithm, logistic regression algorithm, naive Bayes algorithm, decision tree model, random forest classification model, GBDT model, XGBoost model, support vector machine model, etc. (the public account cannot be redirected, the link to this article is at the end).
3) Regression Problems
For more information on machine learning regression algorithms: decision tree model, random forest classification model, GBDT model, regression tree model, support vector machine model, etc.
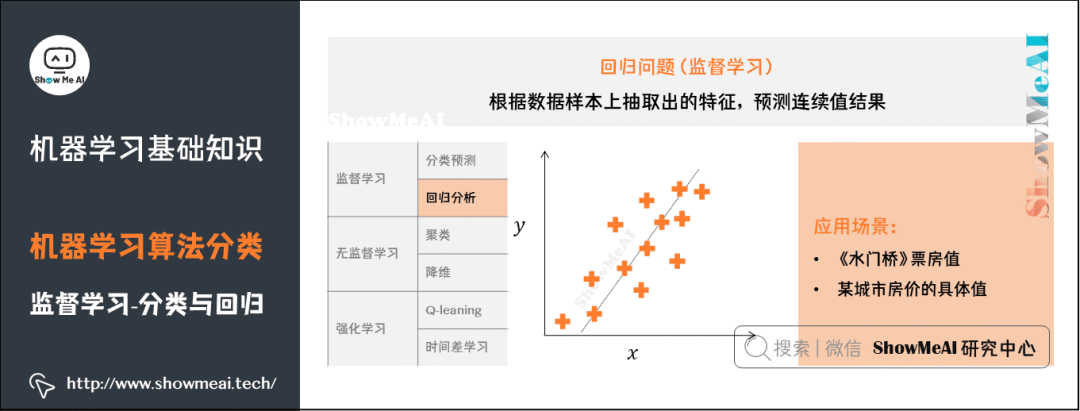
4) Clustering Problems
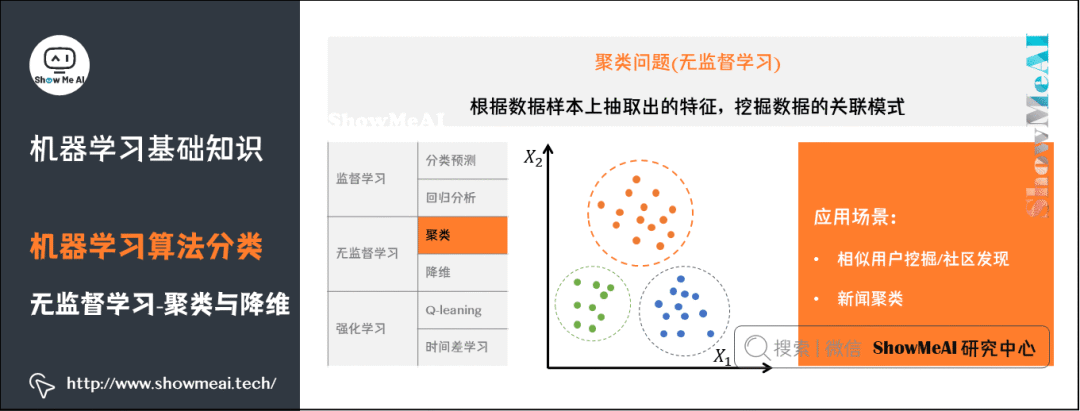
For more information on machine learning clustering algorithms: clustering algorithms.
5) Dimensionality Reduction Problems

For more information on machine learning dimensionality reduction algorithms: PCA dimensionality reduction algorithm.
4. Evaluation and Selection of Machine Learning Models
1) Machine Learning and Data Fitting
The most typical supervised learning in machine learning includes classification and regression problems. In classification problems, we learn a “decision boundary” to distinguish data; in regression problems, we learn to fit a curve that describes the distribution of samples.
2) Training Set and Dataset
Using house price estimation as an example, we will discuss the concepts involved.
Training Set: (Training Set): Helps train the model, simply put, it is the data used to determine the parameters of the fitted curve.
Test Set: (Test Set): Used to test the accuracy of the trained model.
Of course, the test set does not guarantee the correctness of the model; it merely indicates that similar data will yield similar results with this model. Since the parameters during model training are adjusted and fitted based on the data in the existing training set, overfitting may occur, meaning that the parameters fit the training data accurately but may perform poorly when predicting new data.
3) Empirical Error
The error of the model on the training set data is called “empirical error”. However, empirical error is not necessarily better when smaller, as we want good predictive results on new, unseen data.
4) Overfitting
Overfitting refers to a model that performs well on the training set but performs poorly on the cross-validation and test sets, indicating that the model’s predictions on unseen samples are not satisfactory, and its generalization ability is poor.
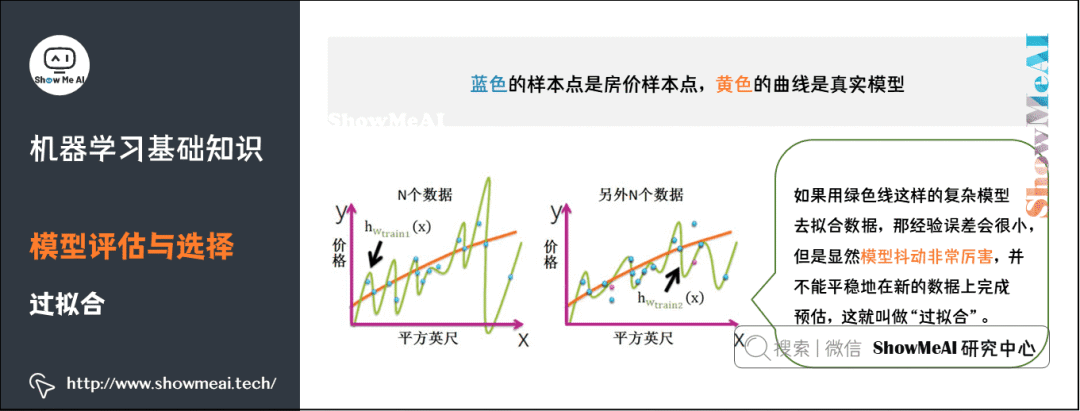
How to Prevent Overfitting? Common methods include Early Stopping, Data Augmentation, Regularization, and Dropout.
Regularization: Refers to adding a regularization term to the objective function, typically using L1 and L2 regularization. L1 regularization is based on the L1 norm, meaning adding the sum of the absolute values of the parameters and the product of the parameters to the objective function.
Data Augmentation: Refers to acquiring more data that meets the requirements, either from the same distribution as the existing data or approximately so. Common methods include: collecting more data from the source, duplicating existing data with random noise, resampling, estimating data distribution parameters based on the current dataset, and generating more data using that distribution.
DropOut: Achieved by modifying the structure of the neural network itself.
5) Bias
Bias refers to the degree of deviation in model fitting. Given numerous training sets, the expected model is the average model. Bias is the difference between the true model and the average model.
Simple models are represented by a set of straight lines, and the average model obtained after averaging is a straight dashed line, which differs significantly from the true model curve (the gray shaded area is large). Therefore, simple models typically have high bias.
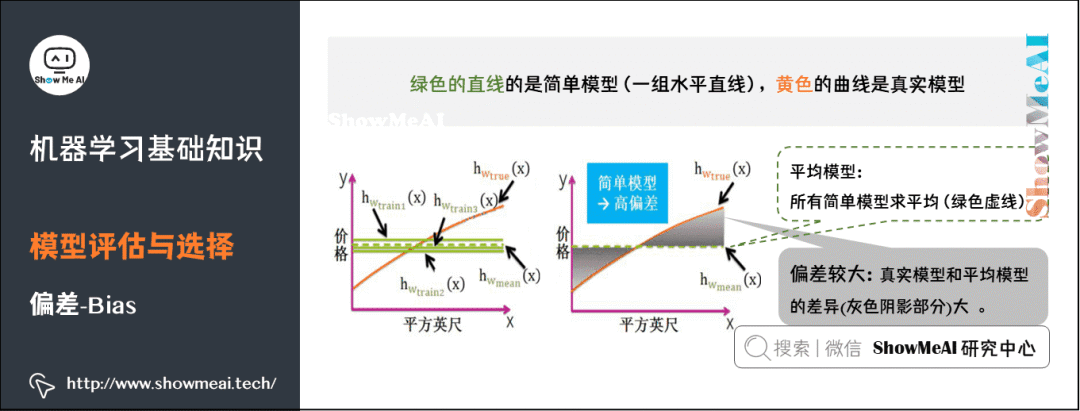
Complex models are represented by a set of highly variable wave-like lines, and after averaging, the maximum and minimum values will cancel each other out, resulting in a small difference from the true model curve, thus complex models typically have low bias (as seen, the yellow curve and green dashed line almost overlap).
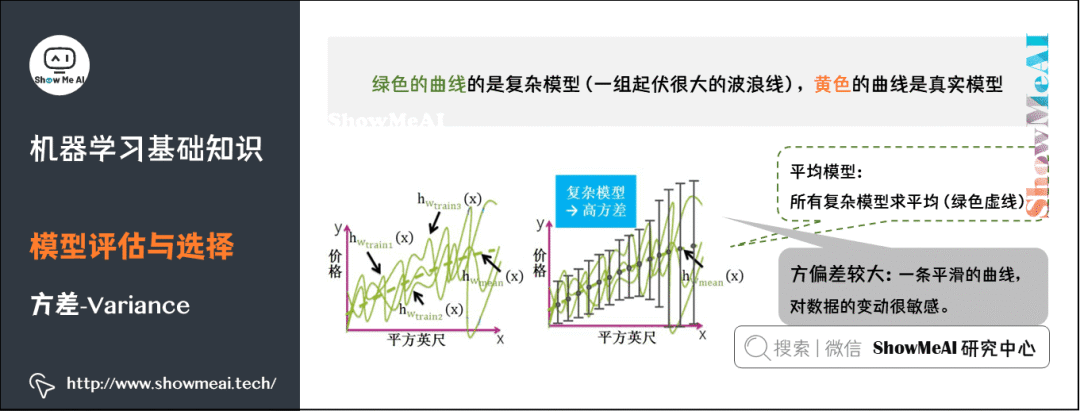
6) Variance
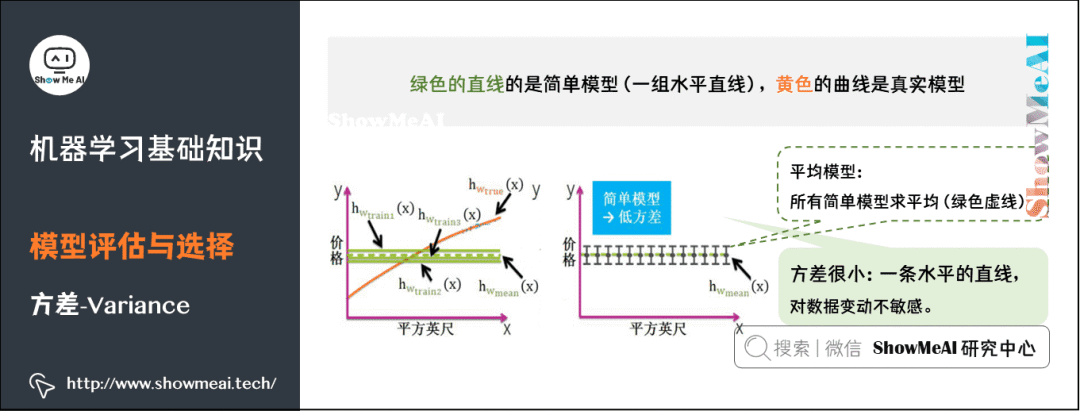
Variance typically refers to the stability of the model (simplicity). Simple models correspond to functions that are identical and horizontal lines, and the average model’s function is also a horizontal line; therefore, simple models have low variance and are insensitive to changes in data.
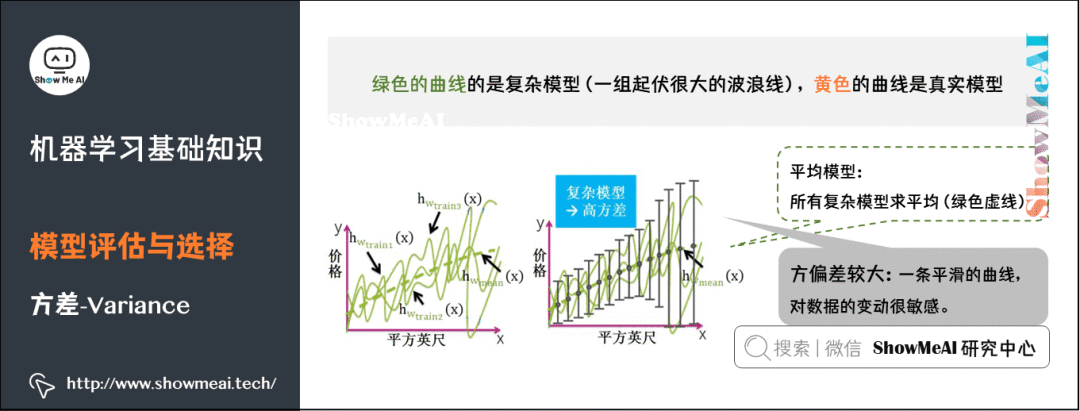
Complex models correspond to functions that are highly variable and lack any rules, while the average model’s function is a smooth curve. Therefore, complex models have high variance and are sensitive to changes in data.
7) Balance Between Bias and Variance
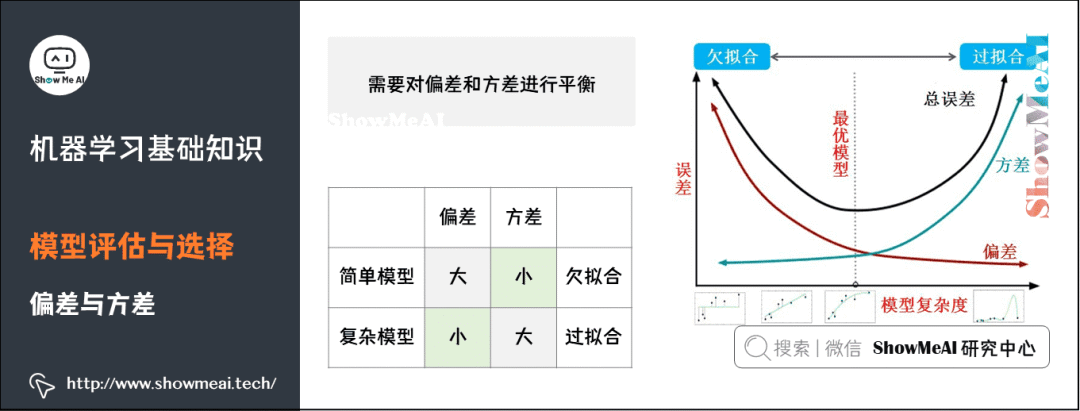
8) Performance Metrics
Performance metrics are numerical evaluation standards that measure a model’s generalization ability, reflecting the current problem (task requirements). Using different performance metrics may lead to different evaluation results. More detailed content can be found in the model evaluation methods and criteria (link at the end).
(1) Regression Problems
Judging the “quality” of a model depends not only on the algorithm and data but also on the current task requirements. Common performance metrics for regression problems include: Mean Absolute Error, Mean Square Error, Root Mean Square Error, R-squared, etc.
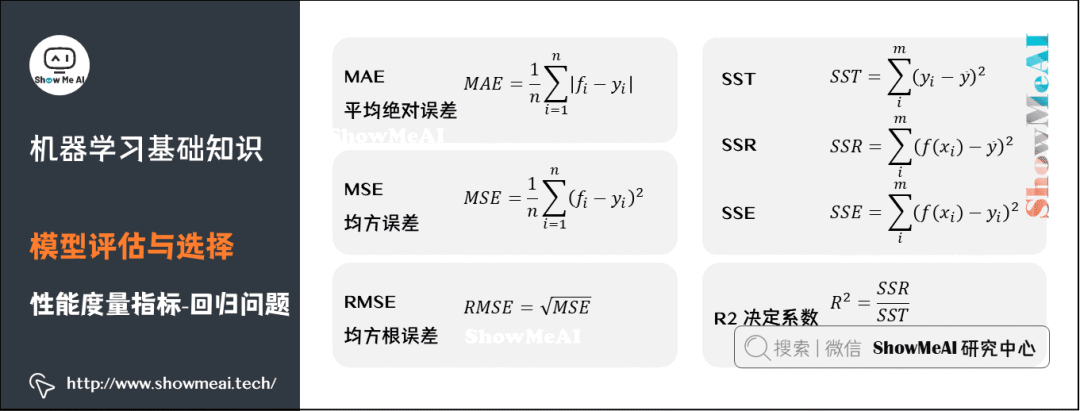
Mean Absolute Error: (Mean Absolute Error, MAE), also known as average absolute deviation, is the average of the absolute deviations of all label values from the predicted values of the regression model.
Mean Absolute Percentage Error: (Mean Absolute Percentage Error, MAPE) is an improvement on MAE that considers the absolute error relative to the true value.
Mean Square Error: (Mean Square Error, MSE) is the average of the squares of the deviations of all label values from the predicted values of the regression model.
Root Mean Square Error: (Root-Mean-Square Error, RMSE), also known as standard error, is calculated by taking the square root of the Mean Square Error. RMSE is used to measure the deviation between observed values and true values.
R-squared: The coefficient of determination reflects the proportion of total variation in the dependent variable that can be explained by the independent variables in the regression model. The closer the proportion is to 1, the better the current regression model explains the data and accurately describes the true distribution of the data.
(2) Classification Problems
Common performance metrics for classification problems include Error Rate, Accuracy, Precision, Recall, F1, ROC Curve, AUC Curve, and R-squared, etc. More detailed content can be found in the model evaluation methods and criteria (link at the end).
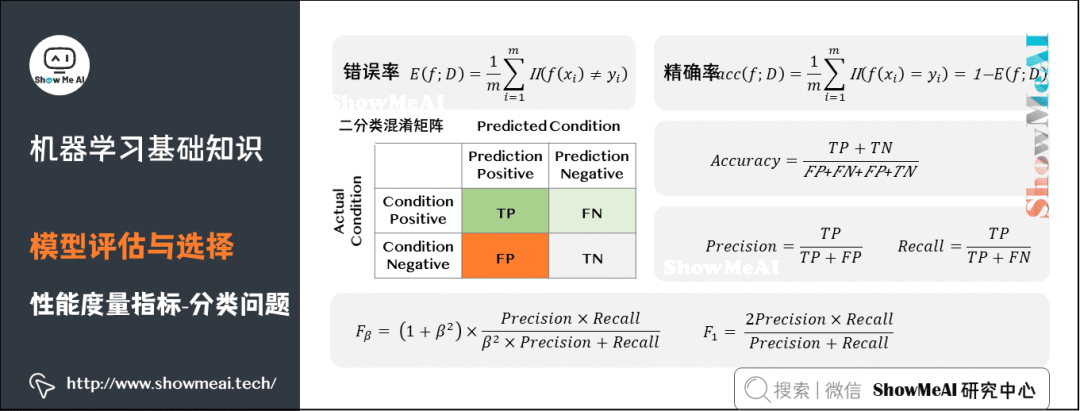
Error Rate: The proportion of misclassified samples to the total number of samples.
Accuracy: The proportion of correctly classified samples to the total number of samples.
Precision: The proportion of truly correct samples in the results returned after retrieval to the total number of samples considered correct.
Recall: The proportion of truly correct samples in the retrieval results to the total number of truly correct samples in the entire dataset (both retrieved and not retrieved).
F1: A measure that considers both precision and recall, defined based on the harmonic mean of precision and recall: F1 is a general form of Fβ that allows us to express different preferences for precision and recall.
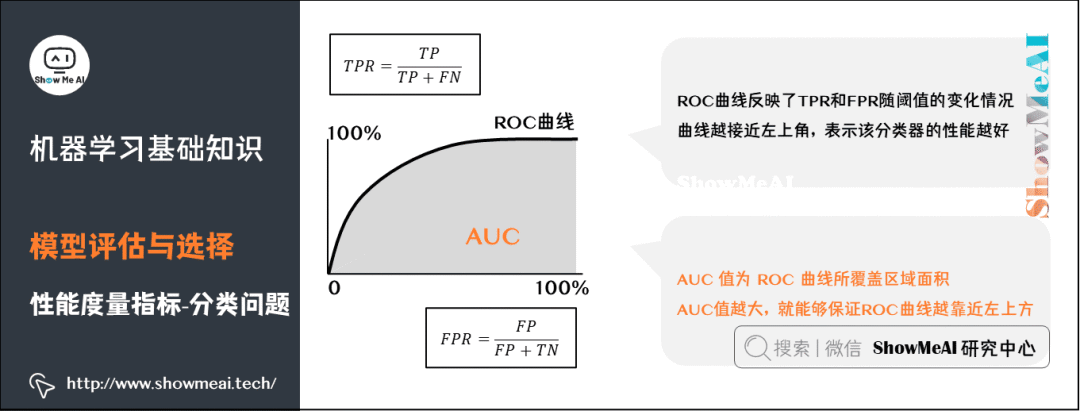
ROC Curve: (Receiver Operating Characteristic Curve) comprehensively considers the quality of probability prediction sorting and reflects the “expected generalization performance” of the learner under different tasks. The vertical axis of the ROC curve is the “True Positive Rate” (TPR), and the horizontal axis is the “False Positive Rate” (FPR).
AUC: (Area Under ROC Curve) represents the area under the ROC curve, indicating the quality of sample prediction sorting.
Understanding AUC from a higher perspective: Taking the identification of anomalous users as an example, a high AUC value means that the model can identify as many anomalous users as possible while maintaining a low false positive rate for normal users (not misclassifying a large number of normal users as anomalies in order to identify anomalous users).
9) Evaluation Methods
When we do not have unknown samples, how can we reliably evaluate? The key is to obtain reliable “test set data” (Test Set), meaning the test set (for evaluation) should be “mutually exclusive” from the training set (for model learning).
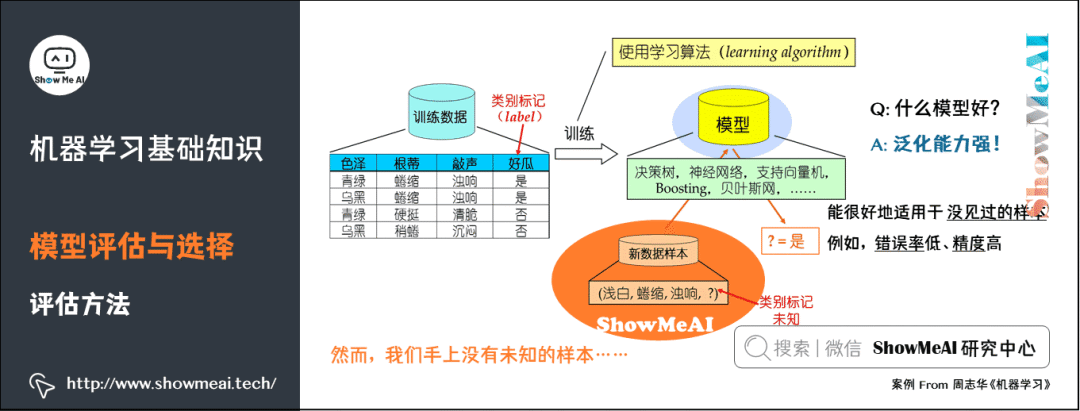
Common evaluation methods include Hold-out, Cross Validation, and Bootstrap. More detailed content can be found in the model evaluation methods and criteria (link at the end).
Hold-out: is one of the most common evaluation methods in machine learning, where a validation sample set is reserved from the training data; this portion of the data is not used for training but for model evaluation.
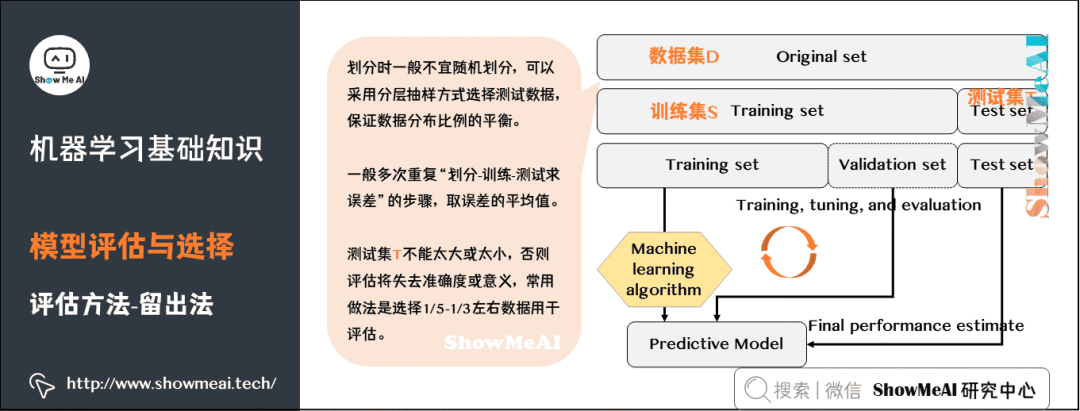
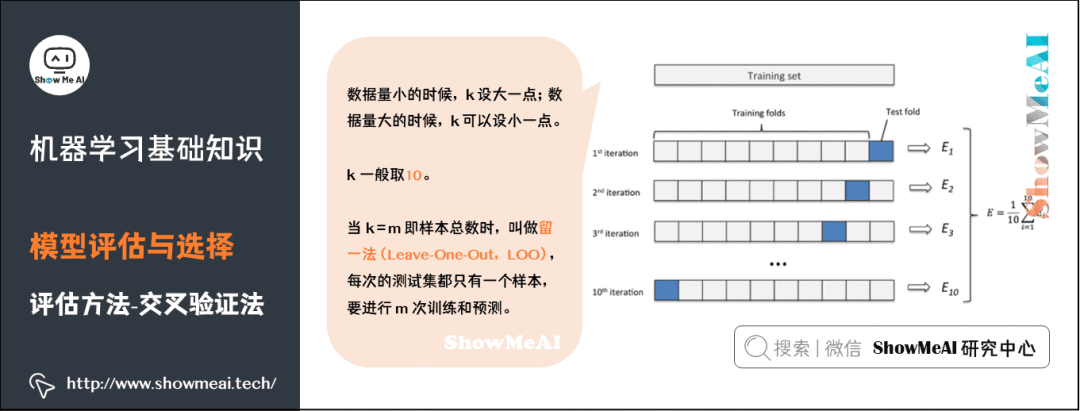
Another common evaluation method in machine learning is Cross Validation. K-fold cross-validation averages the results of k different training groups to reduce variance, making the model’s performance less sensitive to data partitioning and utilizing data more fully, resulting in more stable evaluation results.
Bootstrap: is a non-parametric method used to estimate population values from small samples, widely used in evolutionary and ecological studies.
Bootstrap generates a large number of pseudo-samples through resampling with replacement, and computes statistics on these pseudo-samples to estimate the overall distribution of the data.

10) Model Tuning and Selection Criteria
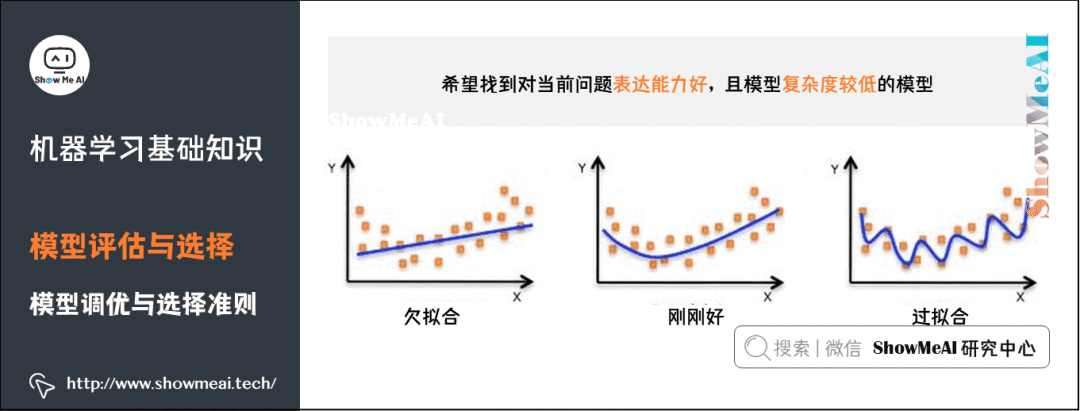
We hope to find a model that expresses the current problem well while also having low complexity:
-
A model with good expressiveness can learn the patterns and rules in the training data effectively;
-
A model with low complexity has low variance, is less prone to overfitting, and has good generalization ability.
11) How to Choose the Optimal Model
(1) Validation Set Evaluation Selection
- Split data into training and validation sets.
- For the prepared candidate hyperparameters, train the model on the training set and evaluate on the validation set.
(2) Grid Search/Random Search Cross Validation
- Generate candidate hyperparameter sets through grid search/random search.
- Evaluate each set of hyperparameters using cross-validation.
- Select the set of hyperparameters with the best performance.
(3) Bayesian Optimization
-
Hyperparameter tuning based on Bayesian optimization.
Initial Review: Zhang Yanling Re-review: Song Qifan Final Review: Jin Jun

Previous Recommendations
Information
○ Doctoral Dissertation Results Display in Journal of Surveying and Mapping | Journal of Surveying and Mapping 2023 Vol. 52 Issue 5
○ Recruitment | Fujian Provincial Public Institution Open Recruitment of 349 Staff! Surveying, Geoinformation, and Remote Sensing Related Majors Can Apply
○ Recruitment | Nanjing University College of Geography and Ocean Science 2023 Annual Recruitment Announcement for Tenured Positions
○ Ministry of Natural Resources Announces Results of Key Laboratory Assessments!
○ Dynamic Monitoring of the Yellow River Delta Wetlands Based on Multi-source Remote Sensing
