
Since the advent of ChatGPT, various GPTs have emerged.
Recently, Microsoft launched HuggingGPT and open-sourced the corresponding project on GitHub – Jarvis. Just these two points are enough to pique the public’s interest.
Today’s article will simply interpret HuggingGPT, specifically the paper – HuggingGPT: Solving AI Tasks with ChatGPT and its Friends in Hugging Face[1].
Click the bottom 【Read Original】 to access the original paper.
Key Points
-
The main purpose of HuggingGPT is to utilize various models to solve complex tasks (tasks involving multiple steps and various capabilities) -
HuggingGPT consists of a large language model (ChatGPT) and expert models (the rich AI models on Hugging Face) -
The large language model (LLM) serves as a general interface for task planning, model selection, and response generation -
The expert models are primarily responsible for task execution -
Currently, the main limitations are threefold: execution efficiency, context length, and system stability
Introduction
Large language models (LLMs) have recently made significant progress, demonstrating powerful capabilities.
LLMs mainly interact with text, but real-world tasks involve multiple modalities—including but not limited to speech, images, and text.
Moreover, a complex task can be decomposed into multiple sub-tasks, and these sub-tasks typically require domain-specific models to achieve better results.
Therefore, a natural idea is to use both LLMs and domain-specific models simultaneously to solve complex problems in the real world.
Specifically for HuggingGPT, it chooses ChatGPT as the LLM, using ChatGPT for task planning, model selection, and response generation; and selects the rich AI models on Hugging Face as domain-specific models to be responsible for task execution.
Workflow of HuggingGPT
The workflow of HuggingGPT consists of four parts: task planning, model selection, task execution, and response generation.
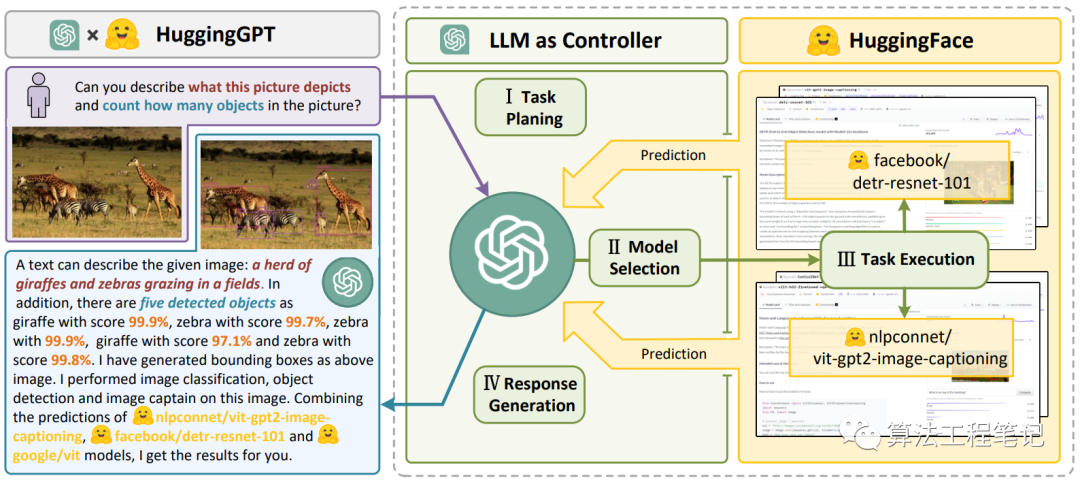
Task Planning
In this step, the main role of the LLM is to complete task decomposition and determine the dependencies and execution order between sub-tasks. The basic form is to construct a basic prompt. The design principles for prompts mainly include the following two points:
Based on Standard Instructions
The standard here is to define a sub-task in four parts:
-
Task ID -
Predefined task type -
Dependencies between tasks -
Parameter list required for task execution
A sub-task can be represented as the following JSON string:
{
"id": 0,
"task": "image-to-text",
"dep": [-1],
"args": {"image": "/examples/boy.jpg"}
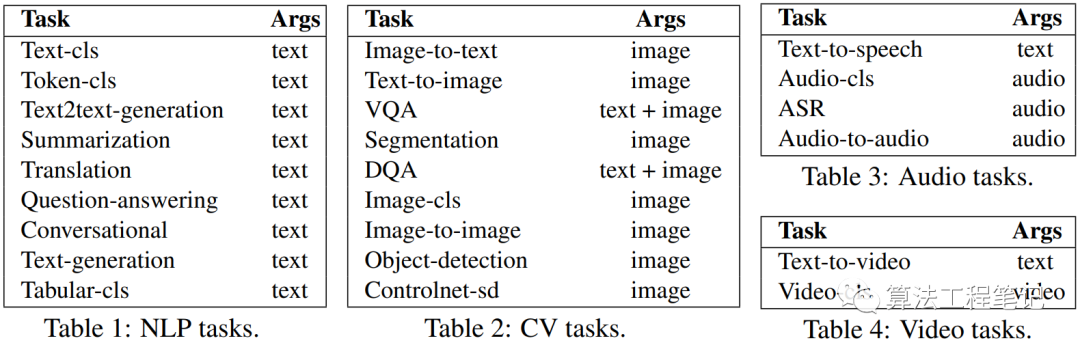
}The predefined task types are shown in the following figure:
Based on Demonstration Parsing
The demonstration examples here are akin to few-shot learning, where by inputting examples, the model’s ability to analyze the task is stimulated. A specific example is as follows:
Given an image /exp3.jpg, first generate a hed image, then based on the hed image and a prompt: a girl is reading a book, you need to reply with a new image.[
{“task”: “image-to-text”, “id”: 0, “dep”: [-1], “args”: {“image”: “/examples/boy.jpg”}},
{“task”: “openpose-control”, “id”: 1, “dep”: [-1], “args”: {“image”: “/examples/boy.jpg”}},
{“task”: “openpose-text-to-image”, “id”: 2, “dep”: [1], “args”: {“text”: “a girl is reading a book”, “image”: “-1″}}]
Model Selection
The main function of model selection is to assign a specific model to handle the sub-task based on the results of task decomposition.
The specific approach involves two steps:
-
Filter models based on the task type of the sub-task and sort the models according to their download counts on Hugging Face -
Provide the descriptions of the top-K filtered models to ChatGPT, allowing the large language model to be responsible for the final selection
This step is called In-Context Task-Model Assignment.
Task Execution
This step doesn’t require much explanation; the paper mentions two concepts—Hybrid Endpoint and Resource Dependency.
Hybrid Endpoint means that the selected model interface can be on Hugging Face (endpoints on Hugging Face) or deployed locally (local inference endpoints), both types of interfaces are included, hence the term Hybrid.
Resource Dependency is a method proposed in the paper to solve the dependencies between sub-tasks. The specific approach is quite simple, equivalent to assigning the resources used to a task reference rather than specific resources. The expression is
Response Generation
This step mainly integrates all the information from the previous three stages (task planning, model selection, and task execution) to generate a concise response, including the planned task list, the selected models for the tasks, and the inference results of the models.
The inference results actually have a fixed format and can be generated through well-designed prompts and the results of the previous three stages.
An example of a prompt provided in the paper is as follows:
With the input and the inference results, the AI assistant needs to describe the process and results. The previous stages can be formed as – User Input: {{ User Input }}, Task Planning: {{ Tasks }}, Model Selection: {{ Model Assignment }}, Task Execution: {{ Predictions }}. You must first answer the user’s request in a straightforward manner. Then describe the task process and show your analysis and model inference results to the user in the first person. If inference results contain a file path, must tell the user the complete file path. If there is nothing in the results, please tell me you can’t make it.
Others
The remainder of the article consists of specific results and analyses, which can be referenced in Chapter 4 of the article—Experiments.
The article concludes by mentioning some current limitations, mainly including execution efficiency, context length, and system stability.
Overall, I believe the innovation of this article lies in providing a formal definition of tasks, allowing us to fill in the formal definitions of tasks using LLMs by constructing specific prompts. The rest of the article is more like an assembly, lacking much novelty.
However, the open-sourced Jarvis on GitHub has a great name, and those with relevant resources can deploy it themselves to see the results. The recommended configuration is as follows:
Ubuntu 16.04 LTS
VRAM >= 12GB
RAM > 12GB (minimal), 16GB (standard), 42GB (full)
Disk > 78G (with 42G for damo-vilab/text-to-video-ms-1.7b)References
HuggingGPT: Solving AI Tasks with ChatGPT and its Friends in Hugging Face: https://arxiv.org/abs/2303.17580