
Highlights: Multimodal recognition makes further progress, Sogou collaborates with Tsinghua University to integrate audio and visual information, enhancing the effectiveness of voice recognition, with the paper included in ICASSP 2019.

There is a virtual assistant (girlfriend) like in the sci-fi movie “Her”, which reflects people’s beautiful vision of artificial intelligence, even though that day may still be far away.
To achieve this technological breakthrough, the industry focused more on various challenges of voice interaction in the past few years. However, in the past two years, some technological pioneers have begun to explore ways to combine voice, visual, and textual information (i.e., multimodal) to promote the upgrade of human-computer interaction technology. Multimodal interaction has also become a hot topic in academia and industry.
Sogou is also a pioneer in multimodal interaction technology. It began exploring lip-reading technology in 2017, launched a synthetic virtual anchor in 2018, and recently, Sogou and Tsinghua University’s Tian Gong Research Institute jointly published a paper titled “End-to-End Audio-Visual Speech Recognition Based on Modal Attention”, making another step forward in the field of multimodal recognition by integrating audio and visual information to enhance voice recognition effectiveness, which was included in the world’s top conference on acoustics, speech, and signal processing, ICASSP 2019.
From the initial voice interaction to lip-reading, then to machine translation and Sogou’s avatar (synthetic anchor), and now to audio-visual recognition, Sogou’s technological progress can be described as steady and cautious. Behind this is Sogou’s commitment to tackling technical challenges under the concept of “natural interaction + knowledge computing”, making human-computer interaction more efficient and natural.

Another Path for Voice Recognition in Noisy Environments
With the development of AI and the promotion of smart speakers, voice interaction has gradually become standard for smart hardware. As a key part of voice interaction, voice recognition has rapidly developed in recent years, with many companies achieving over 98% recognition rates in quiet environments. However, once entering noisy scenarios, the accuracy of voice recognition significantly decreases.
In smart hardware, the mainstream method in the industry is to use microphone arrays for signal processing, employing hardware solutions for noise cancellation. However, in complex and noisy environments, voice recognition still faces significant bottlenecks.
Can visual AI methods solve this problem, especially in noisy environments? Will visual information become an effective supplement to the accuracy of voice recognition? Since visual recognition methods are not affected by environmental noise, even if people cannot clearly hear the speaker, they can generally understand the speaker’s meaning by observing lip movements.
It is with this consideration that Sogou and Tsinghua University’s Tian Gong Research Institute began exploring the combination of audio and visual information last year, namely audio-visual multimodal recognition, to enhance the effectiveness of voice recognition.
According to Sogou, this research project took only about 4-5 months from initiation to paper submission, and the rapid progress is closely related to Sogou’s accumulation in the fields of voice recognition and visual recognition.
In 2016, Sogou began focusing on voice-based human-computer interaction, accumulating a full chain of voice technologies including voice recognition, semantic understanding, machine translation, and voice synthesis.
By the end of 2017, Sogou launched a “black technology” lip-reading recognition technology, which was leading in the industry at that time. Lip-reading recognition could achieve an accuracy rate of 50%-60% for daily language and 85%-90% for command words, laying an early technical foundation for lip-reading recognition.
The phased results of Sogou’s audio-visual multimodal recognition technology are based on the two key technologies of voice recognition and lip-reading recognition. “By effectively combining the two, we can improve voice recognition accuracy by over 30% in noisy environments,” said Chen Wei, technical director of Sogou’s voice interaction center.

Using Modal Attention to Enhance Recognition Effectiveness
Integrating different modalities of audio and visual recognition is not an easy task due to the significant differences in their features. Simply concatenating the two modalities can lead to information loss, and the visual information’s enhancement of auditory information is quite limited. Sogou proposes a modal attention method that dynamically adjusts the integration based on the importance of different modal information to obtain more robust fused information.
According to Zhou Pan from Tsinghua University’s Tian Gong Research Institute, two issues need to be addressed in the process of audio-visual information fusion: the first is the unequal length of audio and visual information, and the second is the unequal contribution issue.
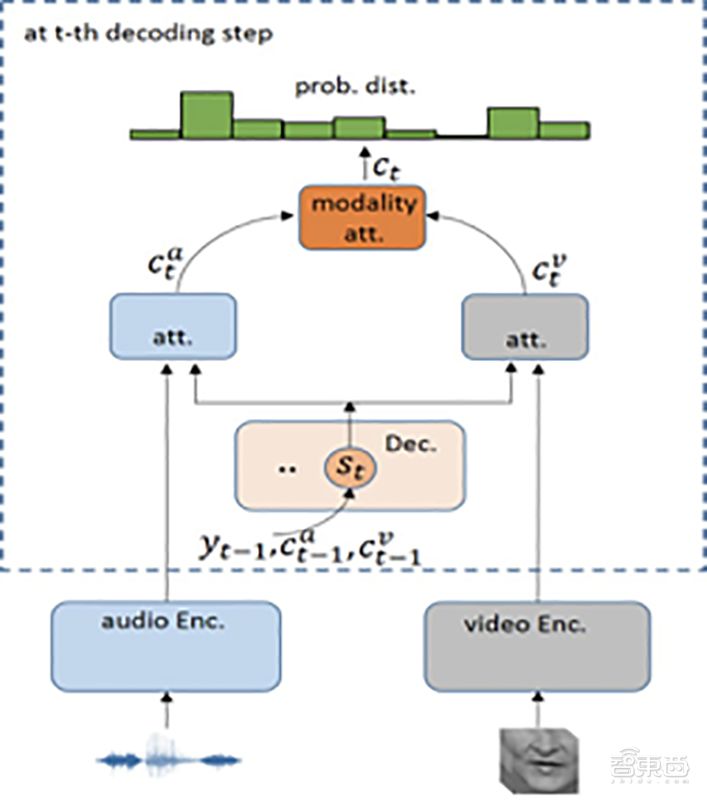
Specifically, the sampling frequencies of audio and visual data differ in time series; generally, audio is sampled at 100 frames per second, while video is at 24 frames per second. Audio-visual recognition first needs to align these 100 frames and 24 frames to fuse their information for a joint decision. For synchronized audio and visual signals, although they can be roughly aligned according to the ratio of their frame rates or upsampled/downsampled to achieve the same frame rate for fusion, there is still some information loss. For unsynchronized audio and visual signals, alignment becomes even more challenging.
The other issue is the unequal contribution. For audio-visual speech recognition, in quiet environments, audio should dominate, while in noisy environments, the contribution of visual information should be enhanced compared to quiet environments. Therefore, the contribution ratio of audio and video needs to be dynamically adjusted based on the environment.
Sogou’s proposed modal attention end-to-end audio-visual model effectively integrates audio and visual information, then dynamically adjusts to choose either audio or video as the main recognition object based on the specific environment, thereby achieving better recognition results. Specifically, through the first layer of conventional attention (also known as content attention), the corresponding auditory and visual context vectors are obtained at each decoding moment. These two context vectors are aligned in content, solving the aforementioned issue of unequal length alignment. For the issue of different contributions, as illustrated above, a second layer of attention, namely modal attention, is employed to dynamically determine the fusion weights of the two modalities based on their contributions to recognition, resulting in a fused context vector containing both audio and visual information.
In a demo, Sogou simulated environments such as quiet, subway, and hall, providing three modes: voice recognition, lip-reading recognition, and hybrid recognition.
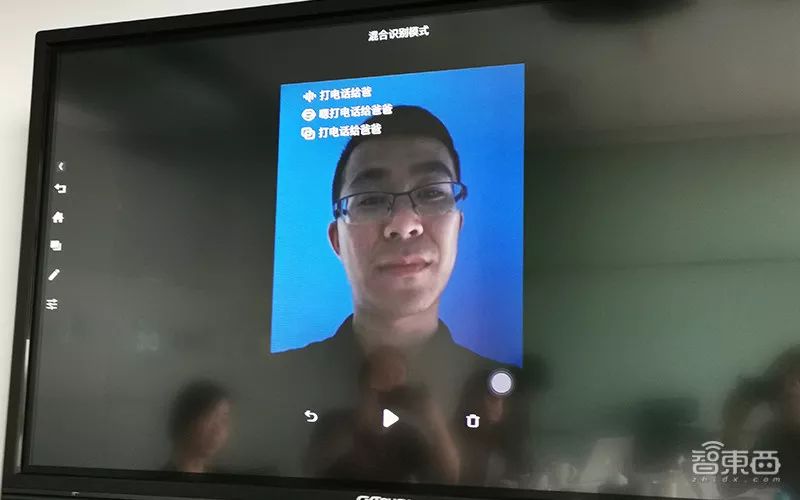
It can be observed that in a quiet environment, the accuracy of voice recognition is higher than that of lip-reading recognition; while in a noisy environment (subway), the accuracy of lip-reading recognition is significantly higher than that of voice recognition. In hybrid recognition mode, the recognition effect can be maximized.
For example, Sogou researcher Yang Wenwen demonstrated in a noisy scenario using the hybrid recognition mode, saying “Call Dad”. It can be seen that both voice recognition and lip-reading recognition have errors, but through their organic integration, an accurate recognition result was achieved.

Promising Future for Commercialization
Regarding commercialization, Chen Wei stated that Sogou may first try to implement audio-visual recognition technology in Sogou Input Method, and some results may be seen this year. Additionally, Sogou is also collaborating with several car manufacturers to actively promote the implementation of audio-visual recognition technology.
Looking at the current application scenarios, whether in smart hardware or smart home IoT fields, the pure voice effect is not ideal. In complex environments, relying solely on hardware to improve voice recognition also faces certain bottlenecks. At this time, employing audio-visual multimodal recognition technology may elevate the existing AI effects to a new level, thereby creating greater commercial value.
This account is a contracted account of NetEase News·NetEase Number “Each Has Its Attitude”.
