

Author: Sabrina Göllner
Translator: Chen Zhiyan
Proofreader: zrx
This article is approximately 4800 words long and is recommended to be read in 10 minutes.
This article presents research by institutions such as Niantic and UCL, which has achieved high-quality depth estimation and 3D reconstruction using a carefully designed and trained 2D network.
Tags: CNN Training
High-performance neural networks do not necessarily need to be large.

Image by Uriel SC (Unsplash)
In recent years, research in the field of image recognition has mainly focused on deep learning techniques, achieving significant progress. Convolutional networks (CNNs) are very effective in perceiving image structures, as they can automatically extract unique features. However, large neural networks often require substantial computational power and long training times to achieve the highest possible accuracy.
This work will demonstrate three methods to ensure that the number of parameters in convolutional networks is as low as possible without affecting accuracy.
In this experiment, the “Modified National Institute of Standards and Technology (MNIST)” dataset will be used.
Note: To better understand this experiment, some foundational knowledge in machine learning is required. For example, concepts like pooling, normalization, regularization, and pruning will be discussed. It is advisable to familiarize yourself with these techniques before proceeding.
Motivation
Most effective methods for the MNIST dataset have high accuracy, but the model parameters typically range from 100,000 to 200,000 or more [1,2]. This is mainly because these methods usually have many convolutional layers with large feature maps as feature extractors, while fully connected layers are used for classification. Therefore, this architecture produces many parameters. A typical architecture for CNN classification is shown below:
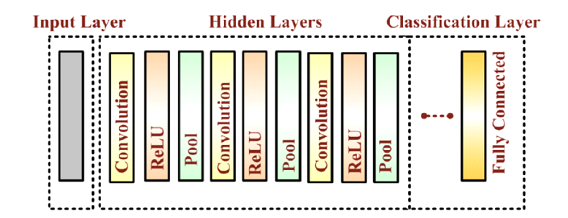
Figure 1: Typical CNN architecture, source [2]
Specifically, the challenge of this experiment is to reduce the number of model parameters to less than 10,000 (i.e., reducing to 10% of the original parameters) while maintaining accuracy above 99%.
Implementation
Preparing the Dataset
First, normalize the training data format, using one-hot encoding here. Then, load the dataset into memory for better performance. Shuffle the training data so that the same order of the dataset is not always obtained during each run of training. Finally, divide the data into equal-sized batches, so that each epoch can obtain data of the same batch size. The same process is applied to the test dataset, apart from data shuffling.
Methods
In this subsection, existing architectures will be used to train models on the MNIST dataset, measuring accuracy after each epoch and observing for 40 epochs in each method.
Different architectures will be created for each case to test their performance, ensuring that each architecture has less than 10,000 trainable parameters (trainable parameters in Keras are defined as parameters that can change during training, such as parameters in activation layers, max pooling, flattening, and dropout).
1. Method 1
This method uses a simplified variant of the “Typical CNN Architecture” (see Figure 1). Due to the limitation on the number of trainable parameters, only convolutional layers are used for feature extraction, with a single fully connected layer for classification. Thus, this model has only 7968 trainable parameters.
Architecture Details:
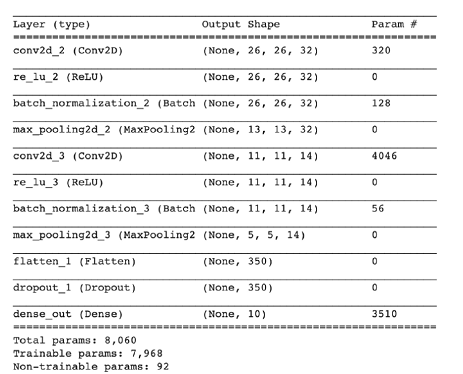
Figure 2: Keras model summary of Method 1, source: author’s own chart
The model consists of 11 layers in total. Since the images are 28×28 pixels with a color value on a grayscale channel, the data enters the input layer in the format of (28,28,1). Next are two consecutive blocks, each consisting of the following layers: a Conv2D layer with a ReLU activation function, followed by batch normalization, and finally a max pooling layer.
MaxPooling down-samples the input data, helping to reduce parameters. The convolutional layer in the first block has 32 different filters, with a small kernel size of 3×3; in the second block, the number of filters is reduced to 14. Since it is assumed that the essential parts of the image are located in the center rather than at the edges, padding is not used, and the stride is set to 1. The ReLU activation function is used as it is currently the state-of-the-art technology. Batch normalization provides a regularization method to prevent overfitting. The max pooling layer with a size of 2 reduces the output results of the previously applied filters by half. As a transition to the fully connected neural network, a flatten layer is currently used, which reduces the tensor to a vector of length 126 (14x3x3). Then, a 10% dropout is added. Finally, the last layer is a fully connected layer with a softmax activation. This model has a total of 8060 parameters, of which 7968 are trainable.
Configuration:
To avoid unnecessary training by the model, the early stopping method is used.
After observing the test accuracy after 10 epochs, the accuracy lower limit is set at 98%. If the test accuracy does not improve, the best weights will be restored (achieved by Keras’s “Restore Best Weights”). The learning rate will be reduced after 4 epochs on the plateau. After training for 4 epochs, the test accuracy steadily declines, causing the learning rate to be halved. The loss is calculated using categorical cross-entropy, and the optimizer is Adam. The batch size is set to 125 to evenly obtain batch data, with the initial learning rate set at 0.01. Using batch normalization speeds up the convergence of accuracy, accelerating the learning process without needing to reduce the learning rate.
Experimental Results:
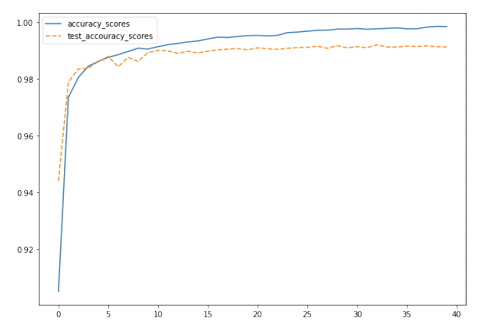
Figure 2: Training curve of Method 1, source: author’s own chart
On average, the test accuracy reached over 98% after the second phase, then converged to 99%. The training process was stabilized by reducing the learning rate on the plateau. Early in training, stopping was typically done between 30 to 40 epochs. The best test accuracy achieved by the network was 99.24%. Therefore, the experimental results indicate that the network has high generalization ability, even with fewer learning parameters, and exceeds the generalization ability of networks with fewer parameters.
2. Method 2
This method only uses convolutional layers for feature extraction, while the classification method adopts global average pooling. This pooling method replaces the fully connected layer to complete the classification task. This approach retains the large number of parameters generated by the fully connected layer. As mentioned in [4] and [5], narrow and deep networks have better generalization ability. To compare with Method 1, this architecture is designed with more layers.
Architecture Details:

Figure 2: Keras summary of Method 2, source: author’s own chart
As previously mentioned, this method selects an architecture of a deep network consisting of 5 “convolutional blocks,” where each convolutional block consists of the following consecutive layers: convolutional layer, ReLU, batch normalization. The number of filters in the convolutional layer is defined as 4-8-16-10, with a kernel size of 3×3. No padding is used, and the stride is set to 1. Max pooling is performed after the second block, helping to reduce parameters. Due to the large number of filters, the parameters in the subsequent two blocks are maximized. These factors are critical for the model’s feature extraction and the accuracy of the results. The last block has only 10 filters, and testing has shown that this number of filters is sufficient. The last three blocks in the final layer have 10% dropout for regularization. This model has a total of 5490 parameters, of which 5382 are trainable.
Configuration:
The network is set for early stopping, with the learning rate, loss, optimizer, batch size, and learning rate configurations on the plateau being the same as those in Method 1.
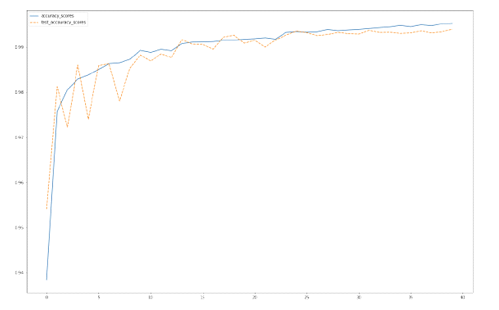
Training curve of Method 2, source: author’s own chart
Observation:
After initial fluctuations, the test accuracy slowly converged to 99% after 10 epochs, with the best test accuracy of this network reaching 99.47%.
3. Method 3
This architecture is essentially similar to Method 2, also using only convolutional layers for feature extraction and global average pooling for classification. However, it consists of fewer layers and has no dropout, with the configuration remaining unchanged.
Architecture Details:

Keras screenshot of Method 3, source: author’s own chart
This architecture is also a deep network consisting of 5 blocks, with each block consisting of a convolutional layer with ReLU activation followed by batch normalization. In this architecture, the filters are defined as follows: the filter sizes are defined in ascending order as 2-4-8-16-10. Thus, the number of filters in the first three convolutional layers is halved, while the last two layers remain the same as in Method 2. The main difference from Method 2 is the removal of Dropouts, as it was found that Dropouts significantly decreased training and testing accuracy. It can be concluded that using Dropouts too frequently in small networks leads to excessive regularization. This model has a total of 3170 parameters, of which 3090 are trainable.
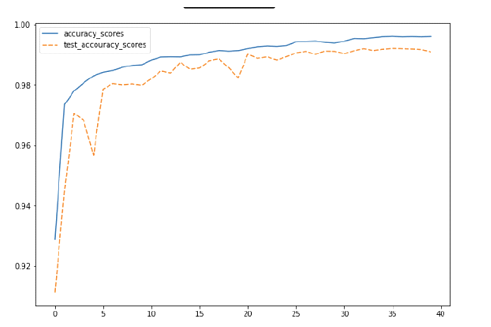
Figure 2: Training curve of Method 3, source: author’s own chart
Observation:
The reduction of filter sizes in the first three convolutional layers did not have as significant an impact on accuracy as expected, and the accuracy of this network still exceeded 99%.

Comparison of methods, source: author’s own chart
Conclusion:
In this subsection, three different architectures of learning models were tested, with the best accuracy of the model with approximately 5000 parameters reaching 99.47%. Furthermore, a sufficient number of filters are needed to effectively extract features. The use of regularization and normalization ensures the stability of the training process.
Implementing Pruning with the “Lottery Ticket Hypothesis”
The purpose of this subsection is to conduct a brief experiment using the “Lottery Ticket Hypothesis” to evaluate its results. This hypothesis is based on the assumption that sub-networks exist within the original network, which are responsible for most of the output results. This means that accuracy is primarily determined by these sub-networks. The network will be tested using Method 2 to see if a “winning lottery ticket” exists.
This can also be referred to as the “global pruning” method, applied to deep convolutional networks. Deep network pruning is achieved by removing the smallest weights across all convolutional layers, where some layers have more parameters than others. When the parameters of all layers are reduced at the same rate, those layers with fewer parameters become bottlenecks, making it impossible to identify the minimum probability of recognizing the “winning lottery ticket.” Global pruning can avoid this pitfall. In this experiment, the number of parameters in different layers of the network varies greatly, so this method is adopted.
Iterative Pruning:
The network in Method 2 is trained with randomly initialized weights. As described by Frankle & Carbin [3] in their paper, after training, the best accuracy is achieved. Then, n rounds of pruning are performed. In each round of pruning, p 1/n % of the remaining weights are pruned, and the remaining weights are reset to their initial values and retrained.
This experiment was conducted over two iterations. Here, both “early stopping” and “reducing learning rate” configurations on the plateau were used, consistent with previous experimental conditions. During training, the number of weights reduced in each iteration was compared to the original network (see Table 2). Only the weights of the convolutional layers were affected by the pruning process (parameters that can be pruned). The parameters listed in the table refer to the “parameters,” while the term “reduction” refers to the number of parameters reduced in this iteration.

Source: author’s own chart
Observation:
After each iteration, the accuracy drops by about 0.1%. As shown in the figure below, during the initial training of the first iteration (20% pruning), greater fluctuations were observed compared to the original, but stabilized after 15 epochs. During the second iteration (55.77% pruning), higher fluctuations in test accuracy were observed at the beginning, but stabilized in subsequent processes. Early stopping was initiated after 31 epochs during this iterative process. Overall, the expected test accuracy for each iteration reached 99%. The paper mentions that the pruned network learns faster and improves accuracy [3, page 5]. In contrast, the accuracy of the pruned network does not increase rapidly. The impact of pruning large networks is significantly greater, although this situation occurs only within a small range.
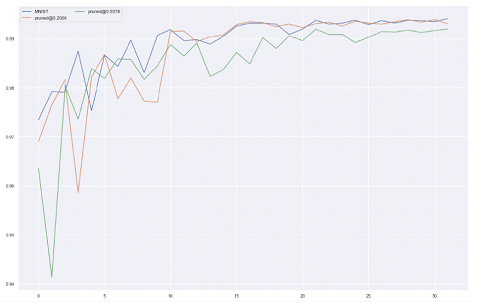
Comparison of all learning curves (blue=initial, orange=20%, green=55.78%), source: author’s own chart
Results:
Starting with 5220 parameters available for pruning, it was reduced to 2309 prunable parameters. After pruning, the final model achieved 2471 trainable parameters (using Keras to compute the sum difference of the 5380 “trainable parameters”; pruning reduced the parameter weights to 2309), with the final test accuracy of the pruned model reaching 99.2%.
Summary and Outlook
In practical training, neural networks tend to be over-parameterized. The number of parameters used in the MNIST dataset in this experiment is fewer than most architectures. This significantly saves training time and computational power. As demonstrated in this work, an appropriate architecture can extract sufficient information while not sacrificing accuracy. Moreover, methods such as pruning can help limit the remaining weights, leaving only the important parts of the network, known as the “winning lottery ticket.”
Original Title:
How to reduce training parameters in CNNs while keeping accuracy >99%
Original Link:
https://towardsdatascience.com/how-to-reduce-training-parameters-in-cnns-while-keeping-accuracy-99-a213034a9777
Editor: Wang Jing
Translator’s Profile

Chen Zhiyan, graduated from Beijing Jiaotong University with a master’s degree in Communication and Control Engineering. He has worked as an engineer at Great Wall Computer Software and System Co., Ltd., and at Datang Microelectronics Technology Co., Ltd. He currently serves as technical support at Beijing Wuyi Chaokun Technology Co., Ltd. He is engaged in the operation and maintenance of intelligent translation teaching systems and has accumulated certain experience in artificial intelligence deep learning and natural language processing (NLP). In his spare time, he enjoys translation and creative writing, with translated works including: IEC-ISO 7816, Iraq Oil Engineering Project, New Fiscal and Taxism Declaration, etc. His Chinese-to-English work “New Fiscal and Taxism Declaration” was officially published in GLOBAL TIMES. He hopes to join the translation volunteer group on the THU Datapi platform during his spare time to communicate, share, and progress together with everyone.
Recruitment Information for Translation Group
Job Description: Requires a meticulous heart to translate selected foreign articles into fluent Chinese. If you are a data science/statistics/computer major studying abroad, or working in related fields overseas, or confident in your foreign language skills, you are welcome to join the translation group.
What You Can Gain: Regular translation training to improve volunteers’ translation skills, enhance awareness of cutting-edge data science, and overseas friends can keep in touch with domestic technological application development. The THU Datapi’s industry-academia-research background provides good development opportunities for volunteers.
Other Benefits: Data science practitioners from well-known companies, students from prestigious universities such as Peking University and Tsinghua University, and overseas students will all become your partners in the translation group.
Click on the end of the article “Read the original text” to join the Datapi team~
Reprinting Notice
If you need to reprint, please prominently indicate the author and source at the beginning of the article (reprinted from: Datapi ID: DatapiTHU), and place a prominent QR code of Datapi at the end of the article. For articles with original identification, please send [Article Name – Public Account Name and ID to be authorized] to the contact email to apply for whitelist authorization and edit according to requirements.
After publication, please feedback the link to the contact email (see below). Unauthorized reprints and adaptations will be pursued legally.

Click“Read the original text” to embrace the organization